- The paper introduces a GRPO-based RL framework that uses BLEU rewards to improve Spoken Question Answering and Automatic Speech Translation in SALLMs.
- It demonstrates significant BLEU score improvements, with GRPO outperforming supervised fine-tuning by up to 151% on SQA and enhancing scalability on larger models.
- The study reveals task-dependent effects of mixed-policy sampling, highlighting the need for tailored RL strategies when incorporating off-policy samples.
Advancing Speech Understanding in Speech-Aware LLMs with GRPO
Introduction
This paper presents a reinforcement learning (RL) framework for training Speech-Aware LLMs (SALLMs) on open-format speech understanding tasks, specifically Spoken Question Answering (SQA) and Automatic Speech Translation (AST). The proposed method leverages Group Relative Policy Optimization (GRPO) with BLEU as the reward signal, aiming to surpass the performance of standard supervised fine-tuning (SFT) and previous RL approaches that primarily focused on multiple-choice tasks. The work also investigates the integration of off-policy samples within GRPO, termed Mixed-Policy GRPO (MP-GRPO), to further enhance model performance.
Background and Motivation
SALLMs are designed to process both speech and text inputs, generating text outputs for tasks such as ASR, AST, and SQA. While prior RL methods for SALLMs have shown promise, they often rely on binary rewards or unsupervised reward estimation, limiting their effectiveness for open-ended generative tasks. GRPO, an on-policy RL algorithm, has demonstrated state-of-the-art results in reasoning tasks for LLMs, but its application to open-format speech tasks remains underexplored.
The motivation for this work is to address the limitations of existing RL approaches by employing GRPO with verifiable, task-relevant reward functions (e.g., BLEU), and to assess the impact of incorporating off-policy samples (ground-truth references) into the training process.
Methodology
Group Relative Policy Optimization (GRPO)
GRPO operates by sampling multiple responses for each prompt, computing rewards for each sample, and normalizing the advantages within the group:
A^i=std(R)ri−mean(R)
The policy is updated using a clipped surrogate loss, with importance sampling weights and KL regularization:
LDAPO(θ)=−∣G∣1i=1∑Gt=1∑∣oi∣(li,t−βDKL[πθ∣∣πref])
where li,t is the clipped advantage-weighted importance ratio.
Mixed-Policy GRPO (MP-GRPO)
MP-GRPO extends GRPO by including off-policy samples (e.g., ground-truth references) in the group. Off-policy samples use a modified importance sampling weight, typically set to 1, and disable clipping. This approach aims to anchor the policy towards high-quality generations, especially in early training.
Reward Functions
BLEU is used as the primary reward function due to its suitability for open-ended generative tasks with multiple valid outputs. The paper also evaluates alternative metrics (ROUGE, METEOR, BERTScore) to assess their impact on model performance.
Experimental Setup
Experiments are conducted on two tasks:
- SQA: LibriSQA dataset, open-ended spoken QA with 107K training samples.
- AST: CoVoST2 English-to-German, direct speech-to-text translation.
Models used are Granite Speech 2B and 8B, with a CTC speech encoder and Window Q-Former projector. Training is performed with AdamW, with extensive hyperparameter searches for both SFT and GRPO. GRPO training uses a group size of 8 and β=0.02, with temperature-based sampling during training and evaluation. All experiments are run on 4 H100 GPUs.
Results
Spoken Question Answering (SQA)
GRPO yields substantial improvements over both the base and SFT models on LibriSQA. For Granite Speech 2B, GRPO achieves a BLEU score of 44.90, compared to 40.88 for SFT and 27.74 for the base model. For 8B, GRPO reaches 46.40 BLEU, outperforming SFT (42.34) and the base (17.85). These results indicate that GRPO is highly effective for open-ended SQA, with gains of up to 151% over the base model.
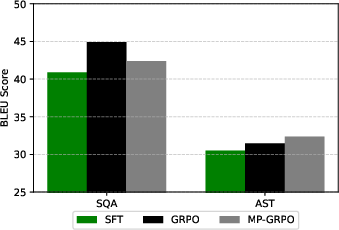
Figure 1: BLEU score progression for SFT, GRPO, and MP-GRPO on SQA and AST, demonstrating GRPO's superior performance and the nuanced effect of mixed-policy training.
Automatic Speech Translation (AST)
On CoVoST2, GRPO also outperforms SFT and the base model. For 2B, GRPO achieves 31.47 BLEU (+8.2% over base, +3.2% over SFT). For 8B, GRPO reaches 35.08 BLEU (+8% over base, +10.9% over SFT), while SFT degrades performance for the larger model. This demonstrates GRPO's scalability and robustness across model sizes.
Mixed-Policy GRPO
MP-GRPO shows task-dependent effects. For AST, adding the reference as an off-policy sample improves BLEU scores over standard GRPO. For SQA, however, MP-GRPO degrades performance, likely due to instability when the model has more to learn and the off-policy samples are less aligned with the current policy. This highlights the importance of task and model initialization in mixed-policy RL.
Reward Function Ablation
Optimizing for BLEU yields the highest average performance across metrics, confirming its suitability as a reward for open-ended speech tasks. Other metrics (ROUGE, METEOR) lead to improvements on their respective scores but at the expense of BLEU and overall performance.
Implementation Considerations
- Computational Requirements: GRPO training is significantly more resource-intensive than SFT, requiring multiple samples per prompt and longer training times (up to 24h on 4 H100 GPUs for 2B models).
- Scalability: The approach scales to larger models (8B), with consistent performance gains.
- Reward Selection: BLEU is empirically validated as the most effective reward for open-ended speech tasks; alternative metrics may be considered for specific applications.
- Mixed-Policy Stability: Incorporating off-policy samples can be beneficial for tasks where the base model is already well-aligned, but may introduce instability otherwise.
- Deployment: The method is applicable to any SALLM architecture with support for sampling-based RL and can be integrated into existing training pipelines for speech understanding tasks.
Implications and Future Directions
The demonstrated effectiveness of GRPO for open-format speech tasks suggests that RL with verifiable, task-relevant rewards can substantially improve SALLM generative capabilities. The nuanced findings regarding mixed-policy training indicate that further research is needed to understand the interplay between on-policy and off-policy samples, especially in low-resource or poorly-initialized settings.
Future work may explore:
- More sophisticated reward functions, including neural-based metrics or composite rewards.
- Extension to other speech understanding tasks (e.g., ASR, spoken dialogue).
- Improved stability and sample efficiency for mixed-policy RL.
- Application to multilingual and cross-modal speech tasks.
Conclusion
This paper introduces a GRPO-based RL framework for training SALLMs on open-ended speech understanding tasks, demonstrating consistent improvements over SFT and baseline models across multiple metrics and model sizes. The integration of BLEU as a reward is empirically validated, and the exploration of mixed-policy training provides insights into its task-dependent efficacy. The results underscore the potential of RL with verifiable rewards for advancing speech understanding in LLMs and motivate further research into scalable, robust RL methods for multimodal generative tasks.