Motif-2-12.7B-Reasoning: A Practitioner's Guide to RL Training Recipes
Abstract: We introduce Motif-2-12.7B-Reasoning, a 12.7B parameter LLM designed to bridge the gap between open-weight systems and proprietary frontier models in complex reasoning and long-context understanding. Addressing the common challenges of model collapse and training instability in reasoning adaptation, we propose a comprehensive, reproducible training recipe spanning system, data, and algorithmic optimizations. Our approach combines memory-efficient infrastructure for 64K-token contexts using hybrid parallelism and kernel-level optimizations with a two-stage Supervised Fine-Tuning (SFT) curriculum that mitigates distribution mismatch through verified, aligned synthetic data. Furthermore, we detail a robust Reinforcement Learning Fine-Tuning (RLFT) pipeline that stabilizes training via difficulty-aware data filtering and mixed-policy trajectory reuse. Empirical results demonstrate that Motif-2-12.7B-Reasoning achieves performance comparable to models with significantly larger parameter counts across mathematics, coding, and agentic benchmarks, offering the community a competitive open model and a practical blueprint for scaling reasoning capabilities under realistic compute constraints.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
1) What is this paper about?
This paper explains how the authors built a smart LLM called Motif-2-12.7B-Reasoning. Even though it’s not huge, it can think through hard problems (like math, coding, and planning) and handle very long inputs (like big documents). The paper’s goal is twofold:
- Share a step-by-step recipe others can copy to train strong “reasoning” models on a reasonable budget.
- Show that careful training can make a mid-sized model perform like much larger, expensive models.
2) What questions were they trying to answer?
In simple terms, they asked:
- How can we teach a medium-sized model to reason well without it getting confused or “breaking” during training?
- What kind of training data and schedule helps the model think in clear, step-by-step ways?
- How can we safely use reinforcement learning (letting the model try answers and rewarding good ones) without the model forgetting skills or collapsing?
- How do we make the model read and use very long inputs (up to 64,000 tokens—think many pages) efficiently?
(“Tokens” are small chunks of text. 64K tokens is roughly a long chapter or multiple articles.)
3) How did they do it?
They combined three big pieces: system efficiency, teaching with examples (SFT), and teaching with rewards (RL). Here is the approach, with plain-language analogies:
- System engineering: make long reading possible
- Hybrid parallelism: Imagine a team project split smartly among many classmates so everyone works in parallel with minimal overlap. They split the model’s work across different GPUs in multiple ways to fit very long inputs into memory.
- Fine-grained activation checkpointing: Like only re-reading the important parts of a book during study, they selectively re-compute just the pieces that save the most memory instead of redoing everything.
- Liger loss kernel: When calculating the loss (the “how wrong was I?” score), they chop a huge calculation into smaller slices to reduce memory spikes—like cutting a big pizza into slices that are easier to hold.
- Supervised Fine-Tuning (SFT): teaching with examples, in the right order
- Two-stage curriculum: Start with solid basics, then move to harder problems and longer texts—like learning algebra before calculus.
- Stage 1: Build a base in math, code, tools, and step-by-step reasoning using high-quality, verified examples.
- Stage 2: Add deeper, more detailed “chain-of-thought” examples and extend the reading window from 32K to 64K tokens.
- Distribution alignment: Use training examples whose “thinking style” matches the student model’s level. If a super-advanced teacher writes in a way the student can’t follow, the student can actually get worse. So they generate and verify synthetic data that fits the student’s capacity and style.
- Reinforcement Learning Fine-Tuning (RLFT): learning by trying and rewarding
- Core idea: For each question, the model tries several answers (“rollouts”). Answers that do better than the group average get rewarded. This is like grading on a curve to encourage improvement.
- Key stability tricks:
- Difficulty filtering (“Goldilocks” zone): Keep training problems that are neither too easy nor impossible—so the model can learn from differences between good and bad attempts. They use the model itself to estimate which problems fall in this sweet spot.
- Mixed-policy trajectory reuse: Reuse the same batch of attempts for several learning steps to save compute—like studying the same set of practice problems more thoroughly instead of constantly printing new ones.
- No length penalty: Don’t punish long answers, because deep reasoning often needs more steps. Short answers can be worse for logic-heavy tasks.
- Slightly wider “trust zone”: Allow the model to move a bit more boldly toward better answers (a wider clipping range), but still keep it safe from wild swings.
- Multi-task RL: Train math, code, and instruction-following together so the model improves across the board and doesn’t forget other skills.
4) What did they find, and why is it important?
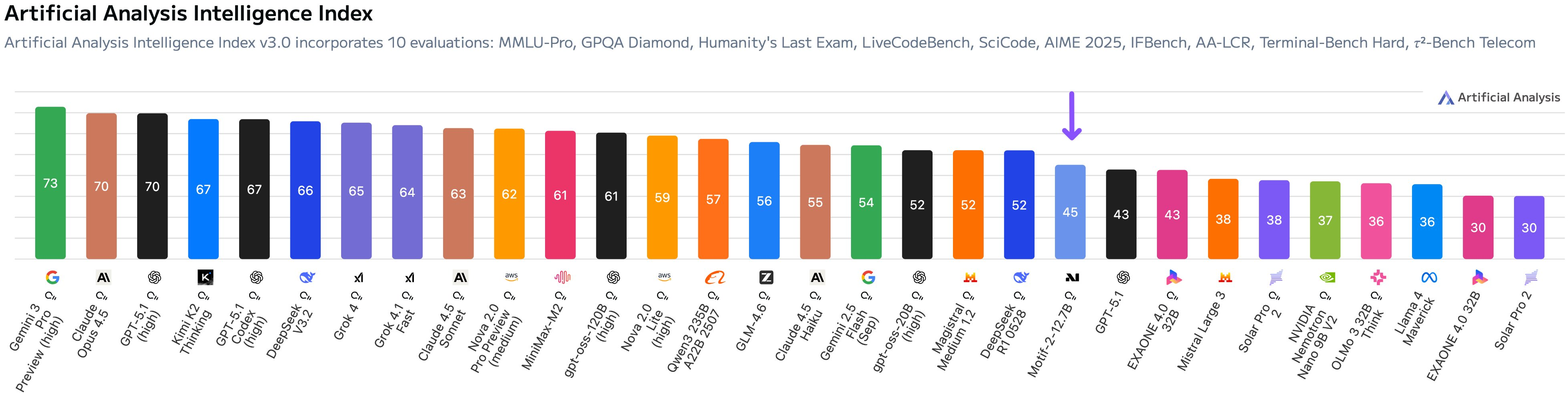
- Strong performance for its size: Their 12.7B-parameter model performs as well as, or better than, some much larger models (30–40B) on math, coding, and agent-style tasks. That means smart training can beat sheer size.
- Stable training without collapse: With the careful SFT curriculum and the RL stability tricks, the model didn’t “collapse” (start giving nonsense or forget skills) and kept improving.
- Long context actually works: The system tricks let the model successfully handle up to 64K tokens, helping it reason over long instructions and documents.
- Better “thinking” with test-time scaling: Letting the model think longer (generate longer reasoning) at answer time improves results, especially after their RL recipe.
This matters because it shows smaller, open models can compete with closed, big-name models when trained well—making powerful AI more accessible.
5) Why does this work matter?
- Practical blueprint: They give a clear, reproducible recipe others can copy—covering system setup, training data, and RL tricks—so the community doesn’t have to guess.
- Lower cost, wider access: Good reasoning doesn’t have to require giant, expensive models. This opens the door for startups, labs, and students to build capable systems.
- Better real-world tools: Stronger, stable reasoning helps in tutors, coding assistants, research helpers, and long-document analysis tools.
- Encourages open progress: By sharing not just the model but also the lessons and failure modes, the paper supports transparent, community-driven improvements.
In short, the authors show that smart training beats brute force, and they hand the community the playbook to do it.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper, framed to be actionable for future research.
- Compute and cost disclosure: Absent details on total GPU hours, number of H100s, training time per stage, tokens processed, and energy/cost footprint; without these, reproducibility and cost–benefit analysis are hindered.
- Full hyperparameter specifications: Missing RLFT and SFT hyperparameters (learning rates, batch/microbatch sizes, optimizer settings, gradient clip, warmup, decay schedules, group size G, rollout count per prompt during RL, entropy/KL regularization, sampling temperature).
- Reward formulations per domain: Exact reward functions for math (binary vs partial credit, step-wise scoring), code (test harness design, language coverage, sandboxing, timeouts), and instruction following (parsing rules, correctness metrics) are not defined or ablated.
- Verification pipeline rigor: The math checker type (symbolic CAS vs numeric tolerance), code execution environment (languages, isolation, resource limits), and “structural validity” criteria are underspecified; false-positive/negative rates and their impact on training are unmeasured.
- Difficulty filtering parameters: The
top-kused in is unspecified; choice of thresholds (e.g., for math/code, for instruction) lacks justification and sensitivity analysis; stability vs performance trade-offs are unexplored. - Selection bias from LLM-as-filter: Filtering with the target model risks feedback loops and reduced diversity; effects on generalization (especially tails of difficulty) and mitigation strategies remain open.
- Mixed-policy trajectory reuse: Off-policy bias from reusing trajectories across S gradient steps is not quantified; guidelines for choosing S, safeguards (e.g., importance sampling corrections), and convergence guarantees are absent.
- Expanded clipping range: Epsilon in [0.28, 0.40] is proposed without ablations to identify safe/stable ranges, adaptive schedules, or interactions with KL constraints; failure modes when over-expanding remain uncharacterized.
- Long-trace verbosity vs correctness: Removing length penalties can induce reward hacking via excessively verbose outputs; criteria to bound or normalize reasoning trace length and its effect on accuracy/time are not investigated.
- GRPO/GSPO specifics: Group size, advantage standardization details, and variance control are missing; impacts of group size G on stability and sample efficiency are not ablated.
- Reference model regularization: No KL-to-reference or supervised anchor is reported; whether such regularization would further stabilize RLFT is an open question.
- Multi-task RL details: Task mixing ratios, per-task reward scales/normalization, and curriculum across tasks are not specified; quantitative evidence of reduced catastrophic forgetting and cross-task trade-offs is missing.
- SFT curriculum schedule: Stage durations, token counts per 16K→32K→64K stage, dataset mixture proportions, and criteria for stage transitions are not provided; necessity and sufficiency of the curriculum are not ablated.
- Data composition and size: Total SFT sample counts per domain, synthetic vs human ratios, average CoT length/depth, and domain balance (beyond the GURU stratification) are not disclosed.
- Teacher–student “reasoning style” alignment: The paper hypothesizes distribution mismatch but lacks a quantitative metric of reasoning granularity/structure and a systematic procedure to select compatible teachers; measuring alignment remains open.
- Contamination controls: Aside from LiveCodeBench, contamination checks for other benchmarks are not described; dataset deduplication against evaluation sets and AAII’s anti-leak safeguards remain unverified.
- AAII reporting: The 10 constituent benchmarks, weighting, seeds, decoding settings, contamination controls, and confidence intervals are missing; a per-task breakdown and variance analysis are needed.
- Benchmark comparability: Claims of parity with 30–40B frontier models lack standardized evaluation settings (sampling temperature, decoding, test-time scaling) and error bars; per-domain scores and calibration are absent.
- Test-time scaling policy: No systematic study of the number of samples, self-consistency voting, allowed “thinking” token budgets, or optimal inference compute allocation; generalizable guidance is missing.
- Long-context engineering details: Positional encoding scheme (e.g., RoPE scaling/YaRN), attention variants, and stability mitigations at 64K are unspecified; long-context robustness benchmarks and failure modes are not reported.
- System performance metrics: Memory/throughput gains from the Liger loss and hybrid parallelism are not quantified; communication overhead, scaling efficiency, and microbatch configurations across nodes/devices are missing.
- Hardware heterogeneity: The recipe targets H100; portability and performance on A100/consumer GPUs, Triton/driver/version sensitivities, and kernel compatibility issues are undeclared.
- Optimizer choice and ablation: Parallel Muon is used without comparisons to AdamW or other optimizers or exploration of optimizer hyperparameters on stability/performance.
- Interplay of SFT vs RLFT gains: Controlled ablations to quantify how much improvement arises from SFT vs RLFT (and from each RL ingredient: difficulty filtering, trajectory reuse, clip expansion) are missing.
- Collapse detection and monitoring: Quantitative early-warning metrics (e.g., divergence in win rate, KL to base, entropy trends) and intervention protocols are not described.
- Tool-use and agentic evaluation: Although tool-calling is mentioned, RL reward modeling and evaluation for tool use/agents (latency, reliability, error handling) are not defined; extending the recipe to real tools is open.
- Safety and bias: Effects of RLFT on safety alignment (toxicity, hallucinations, jailbreak robustness), especially under long contexts, are not evaluated; procedures to balance reasoning gains with safety are absent.
- Generalization beyond target domains: Applicability to multimodal tasks, non-English languages, or knowledge-intensive QA remains untested; domain transfer after reasoning training is unknown.
- Scalability beyond 64K: Whether the system and training recipe scale to 128K or ≥1M contexts (memory, attention quality, positional encoding limits) is not explored.
- Code/test harness reproducibility: Exact test suites, coverage, randomness, environment configuration, and reproducible containers for code rewards are not released; cross-language support is unclear.
- Data licensing and ethics: Licenses for synthetic/generated data (seed-oss, gpt-oss), redistribution rights, and policy for potentially restricted content are not detailed.
- Model and artifact release: Availability of weights, training scripts, configs, seeds, and pipeline code is not specified in the paper; versioning and reproducibility documentation are needed.
- Theoretical grounding: No formal analysis explains why difficulty alignment and trajectory reuse stabilize GRPO/GSPO; deriving conditions for monotonic improvement or bounded off-policy bias is an open direction.
Practical Applications
Below is an overview of practical, real-world applications enabled by the paper’s findings, methods, and innovations. Items are grouped by deployability and tagged with relevant sectors. For each item, we outline concrete use cases, potential tools/products/workflows, and key assumptions/dependencies that affect feasibility.
Immediate Applications
- Open-weight, long-context reasoning assistant for regulated enterprises (Healthcare, Finance, Legal, Government)
- Use cases: Analyze and synthesize insights from 1,000+ page reports (e.g., SEC filings, clinical guidelines, contracts), maintain long-horizon consistency in case files, produce audit-ready rationales internally.
- Tools/products/workflows: 64K-context “document brain” deployed on-prem; templated prompts that hide internal chain-of-thought while exposing final answers; chunk-index + long-context summarization pipelines.
- Dependencies/assumptions: Adequate on-prem GPUs (A100/H100-class) or high-memory cloud; governance for sensitive data; prompt engineering to avoid exposing chain-of-thought in end-user outputs; latency acceptance for long input windows.
- Competitive coding and large-repo assistants with execution-verified reasoning (Software)
- Use cases: Patch generation with unit tests, debugging via multi-step plans, code review with reproducible reasoning, solving competitive coding tasks; integration into CI/CD for automated checks.
- Tools/products/workflows: Sandboxed execution-based verification harnesses; “reasoning-aware” code assistants that run test suites before suggesting patches; task routing based on difficulty bands to optimize developer time.
- Dependencies/assumptions: Secure sandboxing; high-quality tests; acceptance of longer generation traces to retain performance; policy for CoT handling.
- Long-document search, synthesis, and compliance traceability (Enterprise Knowledge Management)
- Use cases: Summarize cross-document evidence; compliance trace generation showing where claims originate; compare versions of policies or contracts over long histories.
- Tools/products/workflows: 64K-context QA workflows; retrieval-lite pipelines that exploit long context rather than heavy RAG; structured “supporting evidence” sections linked to source spans.
- Dependencies/assumptions: Document normalization and de-duplication; storage for large prompt/response logs; human-in-the-loop validation in regulated settings.
- Step-by-step tutoring for math and programming with verifiable checks (Education)
- Use cases: Guided problem-solving with explicit reasoning steps; graded hints; automated feedback on code correctness and math results.
- Tools/products/workflows: Tutor UIs that verify final answers (math) and run code tests; curriculum-aligned difficulty bands; optional CoT hiding with post-hoc explanations.
- Dependencies/assumptions: Age-appropriate guardrails; content filters; licensing of datasets for educational use.
- Reproducible SFT+RLFT recipe for smaller labs and MLOps teams (Academia, AI/ML Platforms)
- Use cases: Build reasoning-optimized LLMs under tight budgets; replicate or adapt the two-stage SFT curriculum and stabilized RLFT pipeline for domain-specific models.
- Tools/products/workflows: Configuration templates for (1) curriculum-based SFT (16K→32K→64K), (2) distribution-aligned synthetic data generation and verification, (3) GRPO/GSPO with masked unparsable outputs, expanded clipping, multi-task RLFT, mixed-policy trajectory reuse.
- Dependencies/assumptions: Access to open corpora or in-house data with proper licenses; familiarity with reward design; compute for rollouts.
- LLM-as-a-data-filtering pipeline for difficulty-aligned training sets (Academia, Software, Education)
- Use cases: Curate datasets that match current model capability to avoid gradient vanishing; maintain training efficiency by filtering to a target pass-rate band.
- Tools/products/workflows: A data curation service that samples n rollouts per item with the target model, computes pass@k, and keeps items with α≤p̂(x)≤β; dashboards for difficulty distribution monitoring.
- Dependencies/assumptions: Rollout budget for filtering; task-specific correctness signals (e.g., execution tests, math checkers); proper model checkpoint selection for filtering.
- Memory- and throughput-optimized training stack (AI Infrastructure, Model Providers)
- Use cases: Train/fine-tune 64K context models or run RLFT within limited VRAM budgets.
- Tools/products/workflows: Hybrid parallelism (DeepSpeed-Ulysses SP + DP shard/replicate + TP), fine-grained activation checkpointing, Liger Kernel loss with context-sharded logits; SkyPilot-based orchestration.
- Dependencies/assumptions: Compatibility with chosen framework stack (DeepSpeed, Triton, vLLM); engineering effort for parallel meshes and checkpointing policies; H100s preferable for 64K contexts.
- Multi-task RLFT to prevent capability regression across domains (Software, Education, Enterprise AI)
- Use cases: Improve instruction following without degrading math/code, or vice versa; maintain balanced capabilities during RL optimization.
- Tools/products/workflows: RLFT loops that mix Math, Code, IF tasks per minibatch with task-specific rewards; automatic monitoring of cross-task metrics; trajectory reuse to stabilize training and reduce cost.
- Dependencies/assumptions: Clear reward definitions per task; schedulers for mixed batches; acceptance of expanded PPO clipping ranges.
- Agentic workflows with reliable long-horizon context retention (Customer Support, RPA, IT Ops)
- Use cases: Maintain multi-session memory for tickets; tool-calling agents that track long-running tasks; write multi-step SOPs and audit trails.
- Tools/products/workflows: vLLM-based serving with maximal generation lengths; tool-call verification; structured logs that tie tool outputs to decisions.
- Dependencies/assumptions: Tool integration surface; monitoring to detect format errors; safety/risk review for autonomous actions.
- Training governance exemplars for reproducibility and efficiency (Policy, Academia)
- Use cases: Teaching and benchmarking RLFT; demonstrating compute-efficient training in courses or community labs; transparency templates for model cards detailing SFT/RLFT choices.
- Tools/products/workflows: Open documentation plus configs for data filtering, curriculum, and RLFT; reproducible SkyPilot scripts for multi-node runs.
- Dependencies/assumptions: Institutional willingness to publish procedures; community standards for logging and disclosure.
Long-Term Applications
- Continual, self-improving enterprise models via safe RLFT loops (Enterprise AI, MLOps)
- Use cases: Periodically harvest feedback (ratings, passes/fails), filter by difficulty bands, and run stable RLFT updates without catastrophic forgetting.
- Tools/products/workflows: “RLFT-as-a-cycle” platform with LLM-as-a-data-filtering, trajectory reuse, and multi-task reward packs; offline evaluation gates before deployment.
- Dependencies/assumptions: Reliable user feedback signals; legal/ethical frameworks for using customer data; robust reward models to avoid reward hacking.
- Domain-grade decision support from multi-document evidence synthesis (Healthcare, Legal, Finance)
- Use cases: Produce traceable clinical summaries across patient histories and guidelines; legal argument scaffolding across case law; risk memos spanning filings and news.
- Tools/products/workflows: Evidence-attribution pipelines tying outputs to document spans; domain-specific reward functions (e.g., clinically valid reasoning); long-context evaluation harnesses.
- Dependencies/assumptions: Expert-in-the-loop validation; regulatory clearance; high-precision verification tools beyond math/code (e.g., medical fact checkers).
- Autonomous repository-scale coding agents with long-horizon planning (Software, DevOps)
- Use cases: Plan and implement multi-file refactors; maintain dependency graphs; long-running tasks across PRs with consistent memory of changes.
- Tools/products/workflows: Agents that exploit 64K context for repo state; RLFT objectives combining compile/test success and style adherence; mixed-policy reuse to stabilize policy updates.
- Dependencies/assumptions: More robust sandboxes; broader test coverage; better reward shaping for security and maintainability.
- Standardized “reasoning distribution alignment” toolkits (AI/ML Tooling)
- Use cases: Match teacher trace complexity to student capacity to avoid distribution mismatch during SFT; automated estimation of trace granularity and structural alignment.
- Tools/products/workflows: Teacher-student trace profiling, similarity scoring, and adjustable trace generation; curriculum schedulers that adapt trace length and complexity.
- Dependencies/assumptions: Research on metrics for reasoning-style compatibility; availability of teachers that can modulate trace complexity.
- Managed RLFT services with domain reward libraries (AI Platforms)
- Use cases: Offer turnkey RL training with pre-built reward functions for math, code, IF, compliance reasoning; SLAs on stability and regression mitigation.
- Tools/products/workflows: Hosted GRPO/GSPO backends with difficulty-filtered queues; trajectory caches for reuse; model monitoring for off-policy drift.
- Dependencies/assumptions: Productization of reward libraries; safety guardrails; customer-specific data connectors.
- “Green” training standards and policy guidance grounded in compute-efficient recipes (Policy, Standards Bodies)
- Use cases: Encourage adoption of memory-efficient kernels, hybrid parallelism, and trajectory reuse to reduce energy per quality point; disclosure norms for RLFT stability choices.
- Tools/products/workflows: Benchmarking suites tracking energy/throughput vs. quality; best-practice checklists based on this recipe; procurement guidelines for public-sector AI.
- Dependencies/assumptions: Agreement on common efficiency metrics; willingness to audit training pipelines.
- Safety-grade verified reasoning pipelines for high-stakes domains (Healthcare, Aviation, Law)
- Use cases: Require structural validity and domain-specific verification before accepting model outputs; maintain verifiable audit trails of reasoning.
- Tools/products/workflows: Expanded verification beyond code/math (e.g., medical ontologies, formal logic checks); gated deployment where unparsable outputs are masked and retried.
- Dependencies/assumptions: Mature verification tooling; acceptance criteria co-developed with regulators; latency budgets for multi-stage checks.
- Edge or on-device long-context reasoning through distillation and quantization (Robotics, Mobile, IoT)
- Use cases: Long-horizon task planning in robotics; device-resident private assistants that preserve session context.
- Tools/products/workflows: Student models distilled from the 12.7B teacher with aligned reasoning style; mixed-precision/quantized kernels; intermittent offloading for heavy steps.
- Dependencies/assumptions: Further research on long-context distillation; hardware accelerators with sufficient memory bandwidth; acceptable performance/latency trade-offs.
- Multimodal long-context reasoning (Docs + Tables + Images + Code) (Enterprise, Education)
- Use cases: Joint reasoning over PDFs, charts, and embedded code snippets; course materials synthesis from text and figures.
- Tools/products/workflows: Extend curriculum and RLFT to multimodal data; verification that combines OCR, table parsers, and code execution.
- Dependencies/assumptions: Pretrained multimodal encoders; scalable memory and attention schemes for multimodal 64K contexts; new reward signals.
- Data governance frameworks that include difficulty calibration and verification (Policy, Academia, Industry Consortia)
- Use cases: Standardize practices that minimize over-optimization, reduce contamination, and ensure fair evaluation for reasoning models.
- Tools/products/workflows: Dataset cards that report pass-rate bands, verification gates, and trace policies; third-party audits of training data and RL signals.
- Dependencies/assumptions: Broad industry buy-in; tooling for reproducible audits; alignment with legal requirements for data use.
These applications are enabled by the paper’s specific contributions: scalable 64K-context training via hybrid parallelism and kernel optimizations; a two-stage, distribution-aligned SFT curriculum; a stabilized RLFT pipeline (difficulty filtering, mixed-policy trajectory reuse, multi-task training, format-error masking, expanded clipping); and an emphasis on verifiable reasoning. Their feasibility hinges on compute availability, domain-appropriate verification signals and rewards, data licensing, safety practices for chain-of-thought handling, and organizational readiness to adopt reproducible training workflows.
Glossary
- Activation checkpointing: A memory-saving technique that trades extra compute for lower peak memory by selectively recomputing activations during backpropagation. "we applied fine-grained activation checkpointing rather than uniformly recomputing every decoder block."
- Actor-critic methods: A class of RL algorithms that learn both a policy (actor) and a value function (critic). "Unlike standard actor-critic methods that rely on a separate value function, GRPO estimates the baseline directly from the group statistics of sampled outputs."
- Agentic benchmarks: Evaluations targeting autonomous, tool-using, or decision-making behaviors beyond simple instruction following. "across mathematics, coding, and agentic benchmarks,"
- Artificial Analysis Intelligence Index (AAII): A composite leaderboard metric aggregating performance across diverse benchmarks. "The Artificial Analysis Intelligence Index (AAII) is a composite metric derived from the average scores of 10 diverse benchmarks."
- Catastrophic forgetting: The degradation of previously learned capabilities when training on new data without safeguards. "preventing the model from scaling its reasoning capabilities and risking catastrophic forgetting."
- Chain-of-Thought (CoT): Explicit intermediate reasoning traces used to guide models through multi-step reasoning. "including Chain-of-Thought (CoT) intensive and failure-driven correction sets."
- Clipping range: The allowable deviation bound for policy updates in PPO-style objectives to stabilize learning. "we employ a larger cliping range in our training setup:."
- Curriculum learning: A training strategy that gradually increases task difficulty or sequence length to improve stability. "Strategy 2: Curriculum Learning (Progressive Context Extension)"
- Data parallelism with parameter replication (DP-replicate): A distributed training approach that replicates parameters across nodes while splitting data. "while across nodes (inter-node) we use data parallelism with parameter replication (DP-replicate)."
- Data parallelism with parameter sharding (DP-shard): A scheme that splits parameters across data-parallel workers to reduce memory per device. "we adopt DeepSpeed-Ulysses sequence parallelism (SP) together with data parallelism with parameter sharding (DP-shard)"
- DeepSpeed-Ulysses: A system for efficient training of extremely long-sequence transformers via specialized parallelism. "we adopt DeepSpeed-Ulysses~\cite{jacobs2023deepspeedulyssesoptimizationsenabling} sequence parallelism (SP)"
- Difficulty-aware data filtering: Selecting training samples whose difficulty matches model capability to ensure useful learning signals. "stabilizes training via difficulty-aware data filtering and mixed-policy trajectory reuse."
- Distribution-aligned SFT: Supervised fine-tuning whose data distribution is matched to the target RL or inference distribution. "via an additional stage of distribution-aligned SFT"
- Distribution mismatch: A harmful divergence between the supervision/teacher distribution and the student model’s capacity or style. "This discrepancy creates a distribution mismatch, where the imposed reasoning patterns conflict with the model's learning process rather than reinforcing it."
- Feed-forward networks (FFNs): The MLP sublayers in transformers, typically following attention, used for non-linear transformation of hidden states. "feed-forward networks (FFNs) operate under SP."
- Group Relative Policy Optimization (GRPO): A critic-free PPO variant that normalizes rewards within a group of samples to compute relative advantages. "Group Relative Policy Optimization~(GRPO)~\cite{shao2024deepseekmathpushinglimitsmathematical} is a critic-free variant of PPO tailored for reasoning tasks."
- Group Sequence Policy Optimization (GSPO): An extension that uses sequence-level importance ratios for policy optimization. "Note that we employ GSPO~\cite{zheng2025groupsequencepolicyoptimization}, which utilizes a sequence-level formulation for the importance ratio ."
- Hybrid parallelism: Combining multiple parallelization strategies (e.g., data, tensor, sequence) to scale training efficiently. "we adopt a hybrid parallelism strategy:"
- Importance ratio: The likelihood ratio between current and behavior policies used for off-policy correction in PPO-like methods. "denotes the importance ratio"
- Liger Kernel: A set of optimized Triton kernels; here used for a memory-efficient loss computation by sharding over sequence length. "we adopt the Liger Kernel~\cite{hsu2025ligerkernelefficienttriton}'s loss function."
- LM head: The final linear projection from hidden states to vocabulary logits in LLMs. "meaning that the LM head and loss computation contribute a non-negligible portion of the memory footprint."
- Long horizons: RL settings where credit assignment spans many steps or tokens, making optimization unstable if not handled carefully. "stabilizing training with long horizons"
- LLM-as-a-data-filtering: Using the model itself to estimate sample difficulty and curate an aligned training set. "namely LLM-as-a-data-filtering."
- Mixed-policy trajectory reuse: Reusing batches of trajectories across multiple gradient steps to improve efficiency, blending on- and off-policy updates. "mixed-policy trajectory reuse."
- Mode collapse: Degeneration where a model produces low-diversity outputs or over-optimizes a narrow mode. "stabilization heuristics to avoid over-optimization and mode collapse"
- Model collapse: Training failure where a model’s outputs degrade broadly, often after unstable fine-tuning. "model collapse and training instability"
- Multi-hop natural language: Tasks requiring reasoning across multiple pieces of information or steps to reach an answer. "multi-hop natural language"
- Multi-task RL: A reinforcement learning setup that jointly optimizes multiple task objectives to prevent regression. "Mitigating task regression via multi-task RL."
- Off-policy regime: An optimization phase where updates are made using data generated by a different (older) policy. "it transitions into an increasingly off-policy regime"
- On-policy training: RL updates using data generated by the current policy at the time of sampling. "on-policy training exhibits high variance"
- Parallel Muon: An optimizer framework designed to handle arbitrary gradient and parameter placements for flexible parallelization. "Because Parallel Muon introduced at Motif-2-12.7B-Instruct~\cite{lim2025motif2127btechnical} is designed to operate under arbitrary gradient and parameter placement configurations"
- Proximal Policy Optimization (PPO): A widely used RL algorithm that constrains policy updates via clipping for stability. "Group Relative Policy Optimization~(GRPO)~\cite{shao2024deepseekmathpushinglimitsmathematical} is a critic-free variant of PPO tailored for reasoning tasks."
- Reinforcement Learning Fine-Tuning (RLFT): Post-SFT optimization using RL objectives and rewards to improve reasoning or alignment. "We detail a robust Reinforcement Learning Fine-Tuning (RLFT) pipeline"
- Reward modeling: Designing task-specific reward signals or models to evaluate and guide generated outputs. "We detail our approach to reward modeling for diverse reasoning tasks"
- Reward shaping: Modifying reward signals (e.g., with penalties or bonuses) to guide learning, which can introduce noise if misapplied. "Lesson 2: Impact of reward shaping on unparsable trajectories."
- Rollouts: Sampled trajectories or responses generated by a policy for evaluation and training. "generating rollouts per prompt"
- Sequence parallelism (SP): Splitting transformer computation across the sequence dimension to reduce per-device memory. "DeepSpeed-Ulysses sequence parallelism (SP)"
- SkyPilot: An intercloud orchestration framework for multi-node/multi-cluster training and resource abstraction. "Our infrastructure is operated using the SkyPilot~\cite{yang2023skypilot} framework, which enables seamless multi-node and multi-cluster provisioning as well as unified resource abstraction across heterogeneous compute environments."
- Stratified sampling: Sampling that preserves or equalizes proportions across categories to balance datasets. "and perform stratified sampling to equalize the distribution across these four sub-domains."
- Tensor parallelism (TP): Splitting model tensor operations (e.g., attention) across devices to scale model capacity. "attention layers are handled with tensor parallelism (TP)"
- Test-time scaling: Boosting inference performance by allocating more compute at inference (e.g., longer chains of thought, multiple samples). "test-time scaling, which allocates more inference compute through longer thinking traces"
- Trust region: A constraint on policy updates to prevent overly large parameter changes in RL optimization. "Unlike standard settings that enforce a tight trust region"
- Value network: A model component that estimates expected returns to reduce variance in policy gradient methods. "without incurring the computational overhead of training a value network."
- vLLM: A high-throughput LLM serving/runtime system used to generate long sequences efficiently. "we configured our serving infrastructure to maximize the generation length of vLLM, as detailed in \S~\ref{sec:sys_ops}."
- Weight-sharded: Distributing model weights across devices to reduce memory footprint per device. "FFNs using SP can be weight-sharded across the SP mesh"
Collections
Sign up for free to add this paper to one or more collections.