XStreamVGGT: Extremely Memory-Efficient Streaming Vision Geometry Grounded Transformer with KV Cache Compression
Abstract: Learning-based 3D visual geometry models have benefited substantially from large-scale transformers. Among these, StreamVGGT leverages frame-wise causal attention for strong streaming reconstruction, but suffers from unbounded KV cache growth, leading to escalating memory consumption and inference latency as input frames accumulate. We propose XStreamVGGT, a tuning-free approach that systematically compresses the KV cache through joint pruning and quantization, enabling extremely memory-efficient streaming inference. Specifically, redundant KVs originating from multi-view inputs are pruned through efficient token importance identification, enabling a fixed memory budget. Leveraging the unique distribution of KV tensors, we incorporate KV quantization to further reduce memory consumption. Extensive evaluations show that XStreamVGGT achieves mostly negligible performance degradation while substantially reducing memory usage by 4.42$\times$ and accelerating inference by 5.48$\times$, enabling scalable and practical streaming 3D applications. The code is available at https://github.com/ywh187/XStreamVGGT/.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Plain‑Language Summary of “XStreamVGGT”
1) What is this paper about?
This paper is about making a powerful 3D vision model run much faster and use far less memory when it processes long videos. The model turns a video (a stream of frames) into 3D information like depth, camera motion, and 3D points. The challenge is that, as the video gets longer, the model’s “memory” grows and grows, which slows it down and can even crash it. The authors propose XStreamVGGT, a way to shrink that memory without retraining the model and without losing much accuracy.
2) What questions are the researchers trying to answer?
- How can we stop the model’s memory from growing forever as more video frames come in?
- Can we throw away or compress parts of that memory while keeping the results almost as accurate?
- Will these tricks make the model fast enough and light enough to use on long videos in real time?
3) How does their method work?
First, a quick idea of how these models think:
- Transformers use something called attention, which relies on three parts: Queries (Q), Keys (K), and Values (V). You can think of it like searching in a library:
- Query: what you’re looking for right now.
- Key: labels on index cards that tell you what information they relate to.
- Value: the actual information you want to read.
- To be fast, the model saves the Keys and Values from past frames in a “KV cache,” like keeping a stack of index cards instead of rewriting them every time.
The problem: with every new frame, the stack of index cards grows. After many frames, the stack gets huge and slow to search.
XStreamVGGT does two things to fix this:
- Pruning (throwing out less useful cards)
- The model looks at the new frame’s Query (what it currently needs) and compares it to the stored Keys (what each saved token is about).
- It computes “importance scores” to figure out which past tokens matter most for answering current questions.
- It always keeps:
- Tokens from the very first frame (as a stable 3D reference).
- Tokens from the current frame (the latest information).
- From the middle frames, it keeps only the top‑scoring tokens and discards the rest. This keeps the memory within a fixed size, no matter how long the video is.
- Quantization (shrinking the numbers)
- Computer numbers in these models are usually 16 or 32‑bit floats. Quantization turns them into smaller integers (like 4‑bit) to save space—similar to saving a photo with slightly lower quality to make the file smaller.
- The authors noticed a pattern: in the Key tensors, a few channels (like columns in a spreadsheet) often have much bigger values than others—these are “outliers.” If you compress everything the same way, those outliers force the whole tensor to use a wider range, which hurts precision.
- Their solution:
- Quantize Keys per channel (compress each column with its own settings) to handle outliers better.
- Quantize Values per token (compress each token individually), which works well because Values don’t show strong outliers.
- This is “tuning‑free,” meaning they don’t retrain or fine‑tune the original model—they just change how memory is stored.
Together, pruning + quantization keep the cache small and efficient, while preserving the information the model actually needs.
4) What did they find, and why is it important?
They tested on several tasks:
- 3D reconstruction (turning video into 3D point clouds) on 7‑Scenes and NRGBD.
- Camera pose estimation (tracking where the camera moved) on TUM and ScanNet.
- Video depth estimation (how far things are) on Sintel, Bonn, and KITTI.
Main results:
- Memory use dropped by about 4.4×.
- Speed increased by about 5.5× (more frames per second).
- Accuracy stayed almost the same: small, often barely noticeable changes across tasks and datasets.
Why this matters:
- Long videos no longer cause the model to run out of memory.
- Faster processing makes real‑time or near‑real‑time 3D understanding much more practical.
5) What’s the bigger impact?
With XStreamVGGT, you can process long video streams for 3D tasks on more modest hardware, making it more realistic to use in:
- AR/VR (building 3D maps of the environment as you move).
- Drones and robots (understanding the 3D world on the fly).
- Phones or edge devices (where memory and speed are limited).
In short, the paper shows that smartly choosing which “memories” to keep and how to store them lets big 3D vision models run fast and light, without giving up much accuracy. The authors also suggest a next step: adapt the memory budget automatically based on how complex or fast‑moving the scene is, so the system can be even smarter about what it keeps.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following points summarize what remains missing, uncertain, or unexplored in the paper, highlighting concrete directions for future research:
- Lack of theoretical guarantees or principled analysis for the query-pooled inner-product importance estimator (e.g., error bounds, sensitivity to noise, and conditions under which token importance correlates with downstream accuracy).
- No ablation of pruning hyperparameters beyond cache length (e.g., grouping size g, number of pooled tokens, head-averaging vs. head-specific importance, top-k selection strategy, and per-layer pruning rates).
- Fixed cache budget (ℒ_max = 2K) without adaptive policies; no mechanism to adjust cache size by scene complexity, motion magnitude, or long-term temporal dependencies.
- Always retaining first-frame KVs assumes the first frame is an optimal geometric anchor; failure modes when the first frame is low-quality, partially occluded, or from a different viewpoint are not analyzed.
- No strategy for detecting scene changes or loop closures to refresh or augment anchor frames (e.g., multi-keyframe retention, keyframe re-selection, or anchor update criteria).
- Unclear per-layer compression policy: whether pruning/quantization is applied uniformly across layers despite likely layer-specific redundancy and sensitivity; no per-layer ablation or optimization.
- Insufficient quantification of KV outlier characteristics (Keys vs. Values) across layers, heads, datasets, and sequence lengths; current evidence is visual and anecdotal rather than statistically characterized.
- Quantization design space is under-explored: only asymmetric uniform INT4 with group size 64 is evaluated; no study of different bit-widths (e.g., 2-bit, 3-bit), group sizes, per-head granularity, or mixed-precision strategies.
- No isolation of the contributions of pruning vs. quantization to memory reduction and speedup (e.g., separate benchmarks to quantify their individual and joint effects on accuracy and latency).
- Latency and memory gains reported on a single 80GB A100; portability to consumer GPUs, edge devices, and other accelerators (with limited INT4 support or different memory hierarchies) is not validated.
- Overhead of quantization/dequantization, scale/zero-point computation and storage, and indexing metadata is not decomposed; true end-to-end gains may vary with kernel implementations and hardware support.
- Compatibility claims with FlashAttention are not empirically substantiated with end-to-end kernels that integrate pruning and quantization; potential kernel-level bottlenecks remain untested.
- No robustness analysis for challenging dynamics (fast motion, motion blur, non-rigid objects) or adverse conditions (low light, severe occlusion), despite noticeable relative degradation on Bonn.
- No evaluation on scenarios requiring long-range temporal memory (e.g., loop closure, revisiting previously seen areas) to assess whether pruning induces catastrophic forgetting or drift.
- Token selection may cause temporal thrashing (rapidly replacing tokens) and loss of time-consistency; no metrics or analyses on temporal stability of reconstructions and poses.
- Limited task coverage: results focus on depth, reconstruction, and pose; impact on other geometry tasks (optical flow, feature tracking, relocalization, novel view synthesis) is unexplored.
- No comparison to alternative KV management baselines beyond full-length StreamVGGT (e.g., sliding windows, uniform subsampling, H2O/heavy-hitter pruning, attention-sink preservation) to contextualize trade-offs.
- Tuning-free design is appealing, but it is unclear whether lightweight adaptation (e.g., quantization-aware calibration, test-time training, or distillation) could recover residual accuracy without significant cost.
- The decision to average over attention heads for importance estimation may discard head-specific signals (e.g., specialization for motion vs. geometry); head-aware policies are not investigated.
- Special tokens (camera and register tokens) are always preserved; the impact of pruning or reweighting these tokens, or learning their retention policies, is not studied.
- No analysis of error propagation from quantized KVs through attention to outputs (e.g., per-layer error profiles, sensitivity of specific heads/channels to quantization noise).
- No guidance on selecting ℒ_max given resolution, token count per frame, or task constraints; a predictive model to set cache budgets under accuracy/latency targets is absent.
- Memory savings are reported for increasing frame lengths, but not for higher resolutions or variable aspect ratios that change token counts; scaling trends with resolution are unknown.
- Multi-view redundancy is discussed conceptually, yet experiments are limited to single-camera video; applicability to true multi-camera streaming (synchronization, viewpoint diversity) remains untested.
- Interaction with StreamVGGT’s alternating attention (spatial vs. temporal) is not dissected; whether spatial attention KVs should be treated differently from temporal KVs is not addressed.
- No statistical significance testing or confidence intervals on reported metrics; robustness across runs/seeds and dataset splits is unclear.
- Training-time implications are not considered (e.g., whether similar compression can accelerate training or if training with compressed KVs improves inference resilience).
- Potential integration with memory summarization (e.g., learned token compaction, cluster prototypes) instead of pure pruning is unexplored.
- Safety and fairness aspects (e.g., whether compression disproportionately degrades performance in certain scene types or under specific conditions) are unexamined.
Practical Applications
Immediate Applications
Below is a concise set of practical, deployable use cases that leverage XStreamVGGT’s tuning-free KV cache pruning and quantization to deliver 4.42× memory reduction and 5.48× faster inference with mostly negligible accuracy loss.
- Real-time robot navigation and SLAM acceleration (Robotics)
- Use case: Replace or augment monocular depth and pose estimation modules in mobile robots and drones to extend mission duration and reduce latency when processing long video streams.
- Workflow/tools: ROS node wrapping XStreamVGGT; TensorRT/ONNX export with FlashAttention; integration with ORB-SLAM/visual odometry pipelines as a geometry prior.
- Assumptions/dependencies: RGB input with moderate motion; INT4 quantization support on target hardware; cache budget selection (e.g., 2K) tuned to platform constraints.
- On-device AR occlusion and scene understanding for smartphones and headsets (Consumer XR, Mobile, Software)
- Use case: Provide fast streaming depth for occlusion, hit-testing, and physics in ARKit/ARCore apps on devices without LiDAR.
- Workflow/tools: Unity/Unreal plugin using XStreamVGGT for depth; per-frame causal attention with bounded KV cache; app-side pooling parameter g=16 as default.
- Assumptions/dependencies: Stable frame rate and adequate GPU/NPU; small accuracy trade-offs acceptable for XR interactions.
- Continuous 3D scanning for construction, real estate, and facility management (AEC)
- Use case: Capture long walkthroughs to produce room-scale point clouds or meshes without out-of-memory errors, enabling longer scans per device.
- Workflow/tools: Mobile capture app + server-side microservice running XStreamVGGT; export to Open3D/CloudCompare; optional post-processing with Poisson reconstruction.
- Assumptions/dependencies: Scenes with sufficient texture; first-frame preservation as reference; cloud GPU with INT4-capable kernels for cost savings.
- Industrial inspection and assembly line monitoring (Manufacturing)
- Use case: Continuous streaming 3D reconstruction of parts/products on conveyor belts for geometry-based QA while increasing the number of concurrent video streams per GPU.
- Workflow/tools: GStreamer ingestion → XStreamVGGT inference → geometric deviation analytics; PLC integration for pass/fail triggers.
- Assumptions/dependencies: Controlled lighting; domain generalization of VGGT family to industrial textures or mild fine-tuning.
- Broadcast and virtual production camera tracking (Media/VFX)
- Use case: Real-time camera pose and depth to drive virtual sets, LED walls, and match-moving with lower latency on long takes.
- Workflow/tools: Plugins for Nuke/Blender/Unreal reading XStreamVGGT outputs; bounded KV cache prevents performance collapse on extended shots.
- Assumptions/dependencies: Synchronized camera feed; acceptable small pose-error deltas; dequantization overhead hidden in CUDA kernels.
- Autonomous driving research stacks (Automotive R&D)
- Use case: Monocular depth and ego-motion cues for prototyping perception modules without high memory growth during long drives.
- Workflow/tools: Integration with AV research frameworks (Apollo, Autoware) as a geometry prior; per-channel Key quantization for robustness to outliers.
- Assumptions/dependencies: Domain shift (outdoor/high-speed) may require validation; timing guarantees depend on hardware accelerators.
- Drone-based mapping and search-and-rescue (Public safety, Robotics)
- Use case: Extended flight-time 3D mapping in cluttered environments with reduced memory footprint to fit edge GPUs onboard or in mobile command centers.
- Workflow/tools: WebRTC streaming → edge gateway running XStreamVGGT → live map updates; mission control UI for overlays.
- Assumptions/dependencies: Reliable video link; resilient performance in dynamic scenes.
- Multi-tenant cloud 3D inference service (Cloud, SaaS)
- Use case: Host many parallel customer video streams for depth/reconstruction with lower GPU memory, reducing per-stream cost.
- Workflow/tools: Kubernetes autoscaling; XStreamVGGT as a stateless microservice; observability dashboards tracking cache pressure and FPS.
- Assumptions/dependencies: INT4 quantization kernels available; SLA/QoS guardrails for cache budgets.
- Dataset auto-annotation for depth and camera pose (Academia, Data Ops)
- Use case: Generate depth and pose labels from long videos for training vision models at scale with predictable memory usage.
- Workflow/tools: Batch pipelines with XStreamVGGT; export to COCO/TFRecords; label inspection with CVAT or FiftyOne.
- Assumptions/dependencies: Accuracy suffices for weak supervision; consistent frame rates.
- Energy and cost-aware AI procurement guidelines (Policy)
- Use case: Encourage adoption of memory-efficient streaming models to cut inference energy and cloud costs for public-sector deployments.
- Workflow/tools: Benchmark reporting including “KV cache efficiency” metrics; procurement templates that prefer bounded-cache models.
- Assumptions/dependencies: Policy bodies accept model-level efficiency metrics; transparent reporting of speed/memory trade-offs.
- Classroom and lab demos for long-sequence geometry (Education)
- Use case: Teach streaming attention and 3D geometry with a practical, open-source codebase that avoids OOM during live demos.
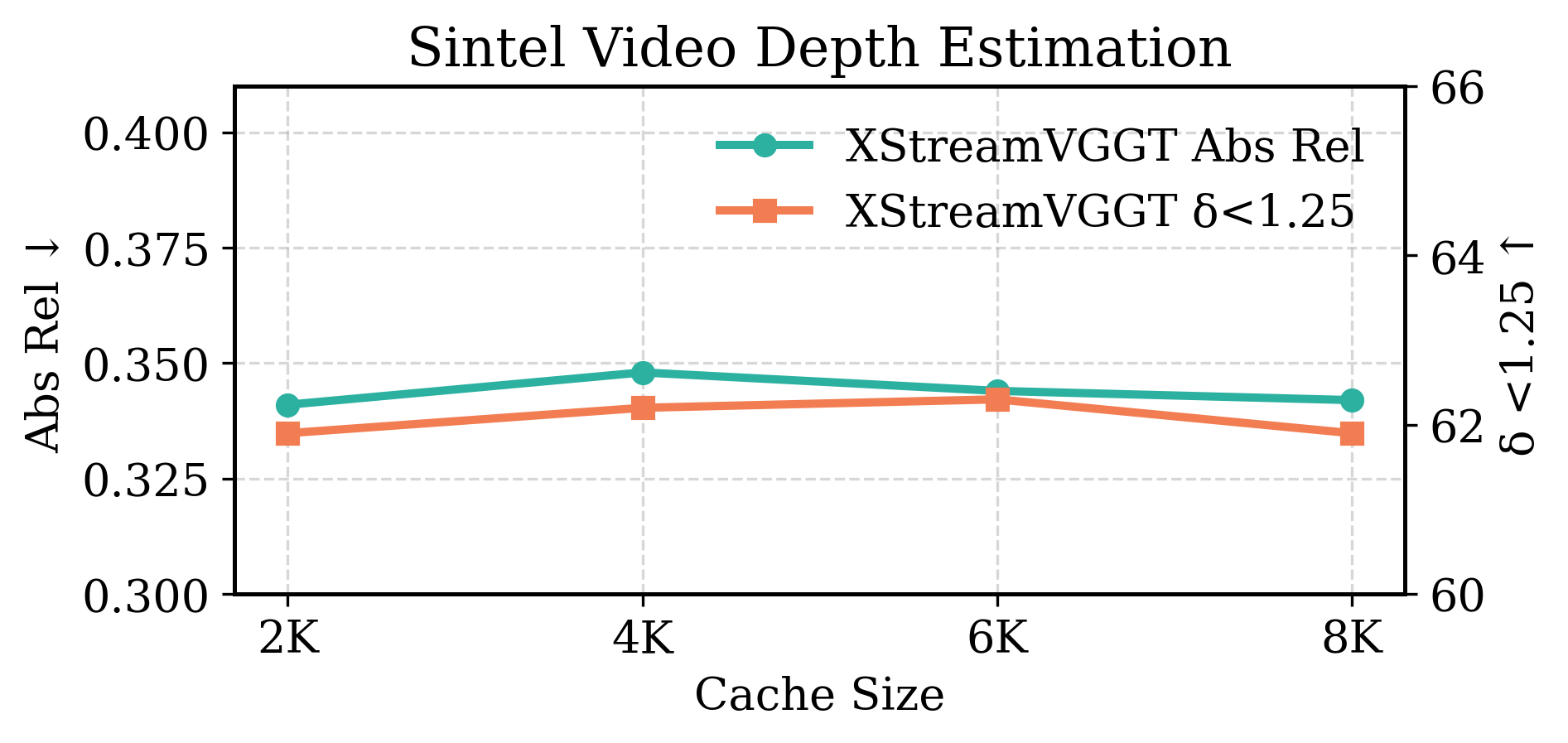
- Workflow/tools: Jupyter notebooks; small GPUs; ablation of cache length (2K/4K/8K) using Sintel or KITTI videos.
- Assumptions/dependencies: Access to sample datasets; instructors familiar with PyTorch and FlashAttention.
- Home scanning and DIY measurement (Daily life)
- Use case: Efficient room scanning for furniture fit, renovation planning, or insurance documentation without requiring LiDAR devices.
- Workflow/tools: Mobile app using XStreamVGGT; export to floor-plan and basic measurements; shareable 3D walkthrough.
- Assumptions/dependencies: Sufficient lighting and textures; tolerance for small geometry deviations in consumer settings.
Long-Term Applications
The following opportunities are plausible but require further research, scaling, domain adaptation, or hardware/software maturation.
- Always-on world modeling for AR glasses (XR, Edge AI)
- Vision: Continuous, on-device 3D scene understanding for occlusion, navigation, and shared spatial anchors.
- Dependencies: NPU/GPU support for per-channel/per-token quantization; further model distillation; thermal constraints; adaptive cache budgets.
- City-scale streaming mapping and digital twins (Smart cities)
- Vision: Multi-hour, multi-agent video streams aggregated to produce up-to-date 3D maps with bounded memory across nodes.
- Dependencies: Distributed KV cache management; cross-camera synchronization; policy/privacy compliance for public imagery.
- Multi-camera rigs and collaborative 4D telepresence (Telecom, Collaboration)
- Vision: Real-time fusion of multiple viewpoints to create live 3D scenes for remote work, sports, and events.
- Dependencies: Multi-view token importance strategies; network-aware cache coordination; standardized streaming formats.
- Production-grade autonomous driving adoption (Automotive)
- Vision: Deploy memory-bounded monocular geometry modules in production stacks for redundancy and failover.
- Dependencies: Safety validation, corner-case robustness (night, rain, glare), domain-specific training, sensor fusion with LiDAR/radar.
- Hardware co-design and KV-aware accelerators (Semiconductors)
- Vision: ASIC/FPGA blocks that natively support per-channel Key and per-token Value quantization and fast dequantization for attention.
- Dependencies: Vendor toolchains; compiler support; standardized APIs for KV compression.
- Adaptive cache budgets driven by scene complexity (Software, Research)
- Vision: Dynamically adjust cache length based on motion, texture, and task confidence to balance accuracy and latency.
- Dependencies: Reliable scene-complexity metrics; policy logic; safeguards against oscillation and drift.
- Training-time memory optimization (ML Systems)
- Vision: Extend KV compression to training (e.g., curriculum-based cache policies, outlier-aware gradients) for large-scale 3D pretraining.
- Dependencies: Algorithmic advances for stable backprop with quantized caches; mixed-precision tooling; reproducible curricula.
- Hybrid pipelines with NeRF/Gaussian Splatting (Content creation, Mapping)
- Vision: Use streaming depth/pose to seed or regularize radiance field methods for faster, more stable online reconstruction.
- Dependencies: Tight coupling between geometry outputs and radiance field optimizers; robust handoff protocols.
- Privacy-preserving, on-device 3D intelligence (Policy, Security)
- Vision: Keep geometry inference on-device to minimize raw video transmission and reduce privacy risk while maintaining performance.
- Dependencies: Efficient local accelerators; encrypted model updates; policy frameworks endorsing edge inference.
- Standardization of KV cache compression for vision transformers (Standards, Open source)
- Vision: Establish common metrics, APIs, and benchmarks for KV compression beyond LLMs (e.g., “KV efficiency scores” for 3D models).
- Dependencies: Community consensus, cross-vendor kernels, dataset coverage across indoor/outdoor/dynamic scenes.
Cross-cutting assumptions and dependencies
- Model/base weights: XStreamVGGT is a tuning-free wrapper around StreamVGGT/VGGT-style architectures; availability and licensing of base weights and code are required.
- Hardware kernels: Effective utilization depends on optimized attention kernels (e.g., FlashAttention) and quantization libraries (e.g., KIVI INT4, group size 64).
- Cache strategy: First-frame preservation is a design assumption; poor initial frames or extreme scene changes may require adaptive reference selection.
- Domain robustness: Reported negligible degradation is validated on specific datasets (Sintel, KITTI, Bonn, TUM, ScanNet, 7-Scenes, NRGBD); out-of-domain performance should be re-validated.
- Latency budgets: Dequantization overhead must be amortized by GPU parallelism; tight real-time constraints may prompt further kernel optimization.
- Policy and compliance: For public or safety-critical deployments, additional auditing, energy reporting, and reliability testing are necessary.
Glossary
- Absolute relative error (Abs Rel): A depth estimation metric measuring the average relative difference between predicted and ground-truth depths. "Absolute relative error (Abs Rel) and (the percentage of predicted depths within a 1.25-factor of the ground-truth depth) are adopted as evaluation metrics."
- Absolute Translation Error (ATE): A camera pose metric quantifying the absolute difference in translation between predicted and ground-truth trajectories. "We report Absolute Translation Error (ATE), Relative Translation Error (RPE\textsubscript{trans}), and Relative Rotation Error (RPE\textsubscript{rot}) as evaluation metrics."
- Alternating-attention design: A transformer architecture pattern that alternates attention types (e.g., spatial and temporal) across layers. "X_t is then fed into a spatio-temporal transformer encoder comprising L layers with an alternating-attention design."
- Asymmetric uniform quantization: A quantization scheme using non-symmetric ranges with a scale and zero-point to map floats to integers. "In this work, we adopt the widely used asymmetric uniform quantization scheme."
- Autoregressive LLMs: Models that generate outputs sequentially by conditioning on previously generated tokens. "StreamVGGT further replaces the global attention with frame-wise causal attention, following a design philosophy analogous to autoregressive LLMs."
- Bit-width: The number of bits used to represent quantized values; smaller bit-widths yield smaller memory usage. "which is parameterized by a scale factor s, a zero-point z, and a bit-width b."
- Camera token: A special token prepended to the token sequence to encode camera-related information. "In addition to the patch tokens, StreamVGGT prepends a camera token "
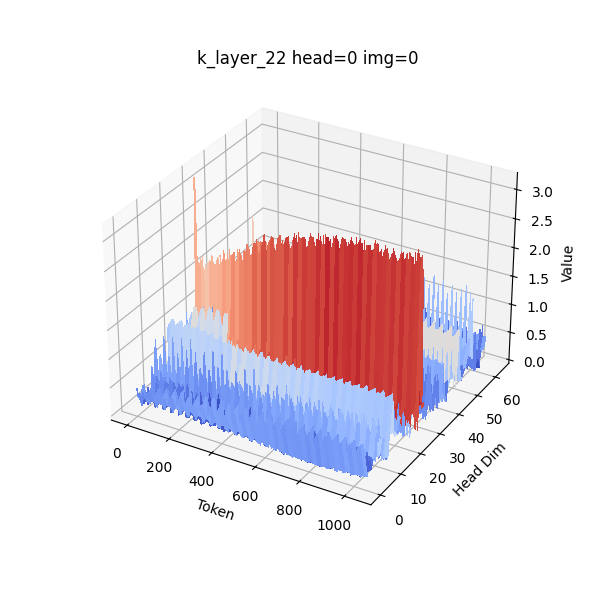
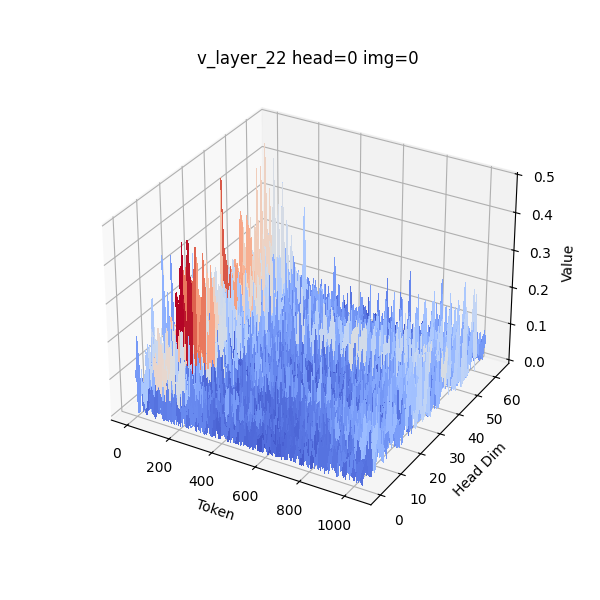
- Channel-wise outliers: Rare high-magnitude values concentrated in specific channels of a tensor, affecting quantization. "The Key exhibits pronounced channel-wise outliers, with a small number of channels having larger magnitudes than the rest."
- Clamp: An operation that restricts values to a specified numerical range during quantization. "and restricts values to the valid range."
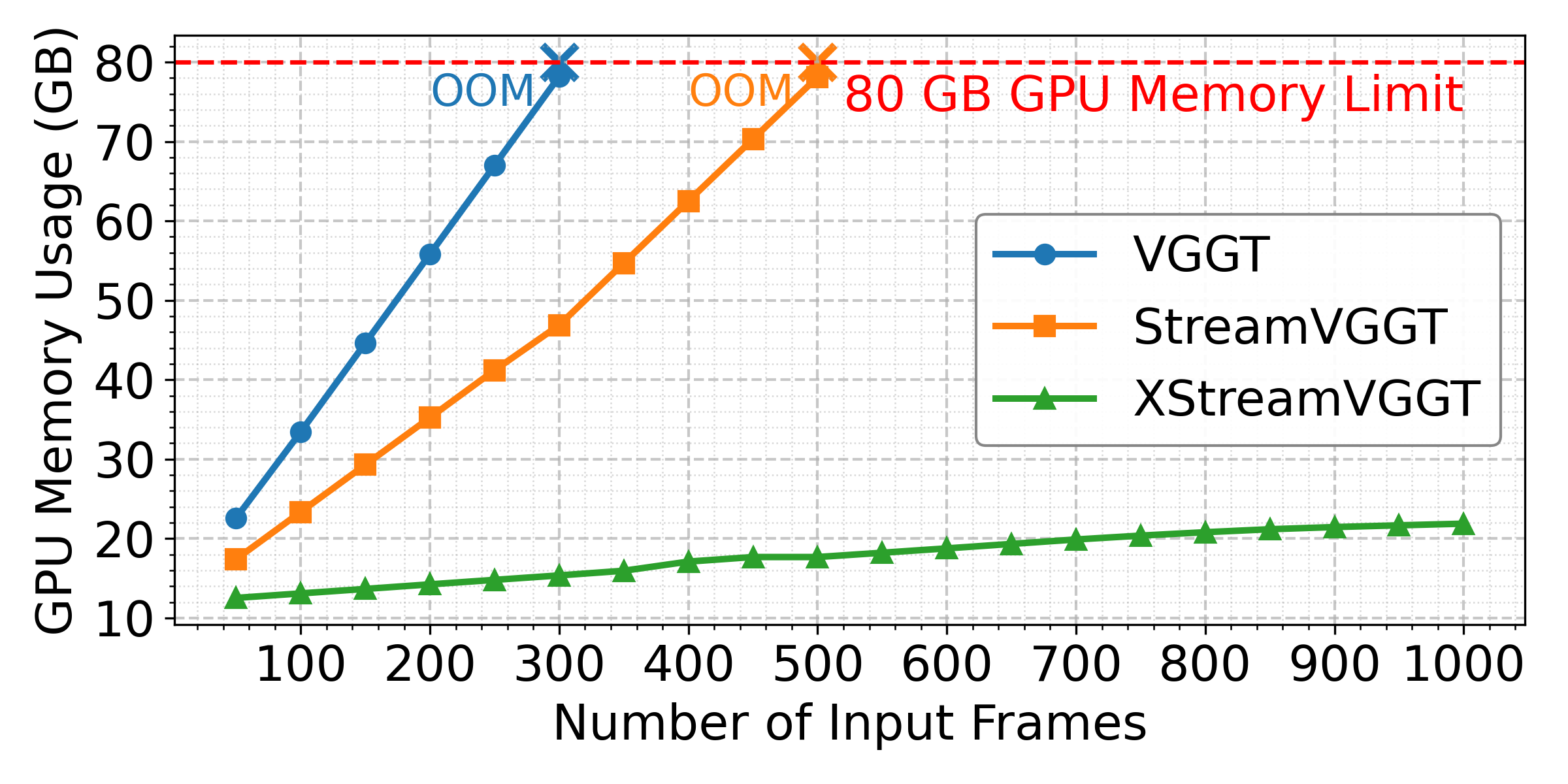
- Context length: The number of past tokens or frames maintained in memory during inference. "As context lengths increase, the KV cache can grow into a substantial memory bottleneck, emphasizing the need for effective compression"
- Dequantization: The process of mapping quantized integers back to floating-point values using scale and zero-point. "During attention computation, the quantized tensors are dequantized as"
- Dense depth estimation: Predicting per-pixel depth values across an image or video frame. "including dense depth estimation, point map regression, and camera pose prediction"
- Dynamic range: The span between minimum and maximum tensor values that quantization must cover. "these outliers dominate the dynamic range, severely inflating the quantization scale and drastically reducing the effective precision"
- FlashAttention: A highly optimized attention kernel that accelerates and reduces memory use in attention computation. "Notably, this procedure is fully compatible with highly optimized attention kernels such as FlashAttention"
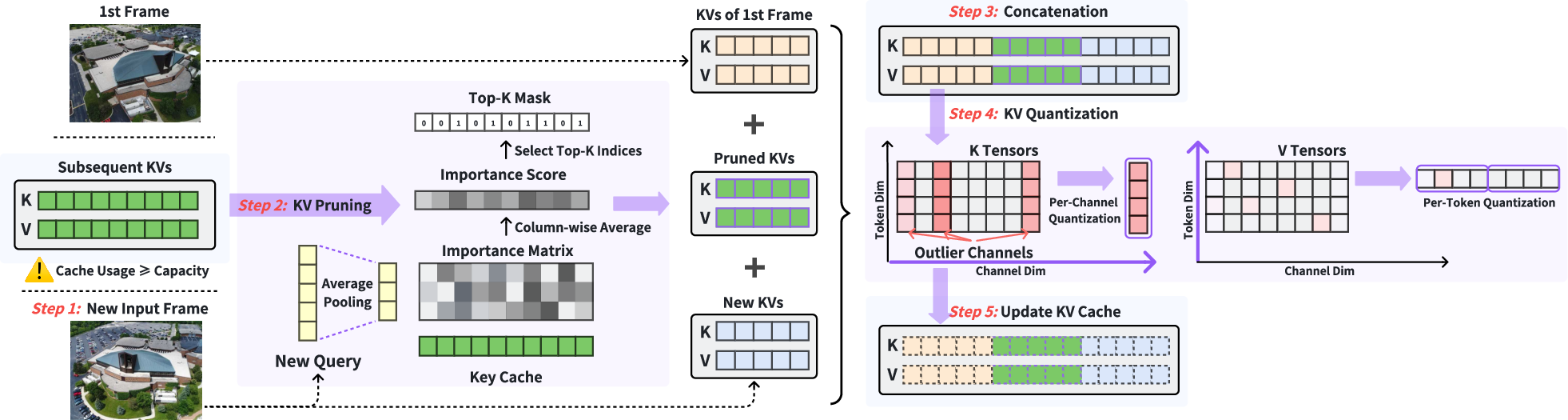
- First-frame KVs: The cached keys and values from the initial frame preserved as a stable geometric reference. "pruning the cache to a bounded budget while preserving the first-frame KVs as geometric references"
- Frame-wise causal attention: An attention mechanism that only attends to current and past frames, enabling streaming. "StreamVGGT further replaces the global attention with frame-wise causal attention"
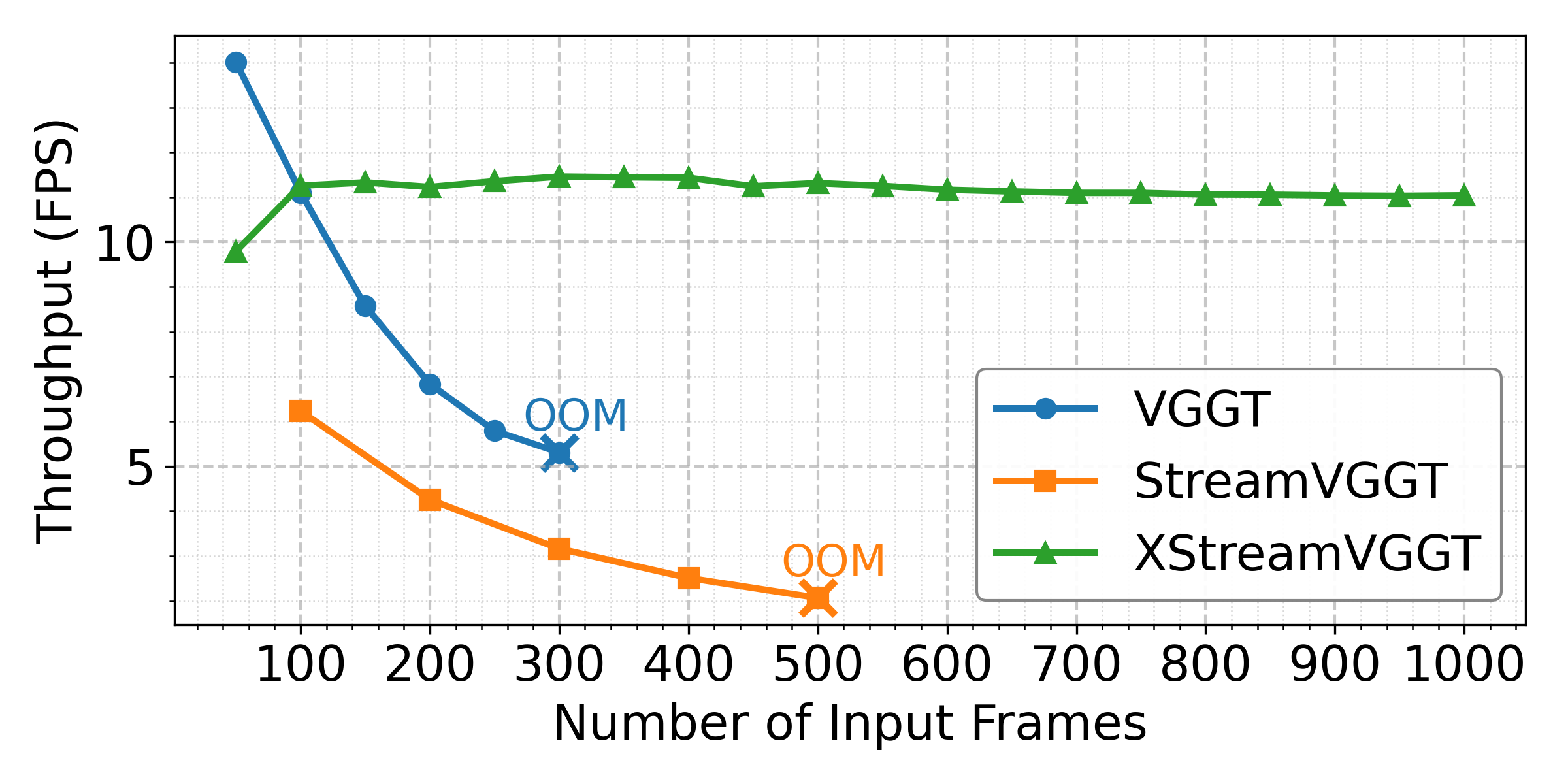
- FPS (Frames per second): A throughput metric indicating how many frames are processed per second during inference. "StreamVGGT and VGGT exhibit rapid FPS degradation and quickly encounter out-of-memory (OOM) errors, whereas XStreamVGGT consistently maintains higher FPS without OOM."
- INT4: A 4-bit integer quantization format that compresses tensors for memory efficiency. "KV quantization is performed using KIVI with INT4 and a group size of 64"
- KIVI: A tuning-free quantization method for KV caches enabling low-bit storage. "KV quantization is performed using KIVI with INT4 and a group size of 64"
- KV cache: A memory of past attention keys and values that allows reusing context during inference. "KV cache enables efficient inference by avoiding redundant recomputation of past KVs."
- KV cache pruning: Removing less important past keys and values to keep the cache within a budget. "We propose a query-guided KV cache pruning mechanism to eliminate multi-view redundancy while retaining the most informative historical tokens within a fixed cache length"
- KV quantization: Compressing keys and values into low-bit representations to reduce memory footprint. "we incorporate KV quantization to further reduce memory consumption."
- Multi-view inputs: Multiple distinct viewpoints or frames of the same scene that can introduce redundancy. "Specifically, redundant KVs originating from multi-view inputs are pruned through efficient token importance identification"
- Normal Consistency (NC): A 3D reconstruction metric assessing alignment of predicted surface normals with ground truth. "We adopt Accuracy (Acc), Completion (Comp), and Normal Consistency (NC) as evaluation metrics"
- Out-of-memory (OOM) errors: Failures that occur when GPU memory usage exceeds available capacity. "StreamVGGT and VGGT exhibit rapid FPS degradation and quickly encounter out-of-memory (OOM) errors"
- Patch embedding network: A module that converts image patches into token embeddings for transformer processing. "the model first converts it into a sequence of visual tokens via a patch embedding network"
- Per-channel quantization: Quantizing each channel separately to better handle channel-specific distributions and outliers. "we design a per-channel Key and per-token Value quantization scheme"
- Per-token quantization: Quantizing each token independently to adapt to token-level distributions. "we design a per-channel Key and per-token Value quantization scheme"
- Query-guided pruning: Using the current queries to estimate importance and prune historical KV tokens accordingly. "We propose a query-guided KV cache pruning mechanism"
- Relative Rotation Error (RPE_rot): A camera pose metric measuring rotational drift between consecutive frames. "We report Absolute Translation Error (ATE), Relative Translation Error (RPE\textsubscript{trans}), and Relative Rotation Error (RPE\textsubscript{rot}) as evaluation metrics."
- Relative Translation Error (RPE_trans): A camera pose metric measuring translational drift between consecutive frames. "We report Absolute Translation Error (ATE), Relative Translation Error (RPE\textsubscript{trans}), and Relative Rotation Error (RPE\textsubscript{rot}) as evaluation metrics."
- Scale factor (quantization): The step size used to map float values onto discrete integer levels. "The scale factor determines the quantization step size"
- Spatio-temporal transformer encoder: A transformer that models spatial and temporal dependencies across frames. "X_t is then fed into a spatio-temporal transformer encoder comprising L layers with an alternating-attention design."
- StreamVGGT: A streaming extension of VGGT that processes frames online using causal attention. "StreamVGGT further replaces the global attention with frame-wise causal attention"
- Temporal attention: Attention computed across time steps using current queries and cached past keys/values. "Temporal attention is then formulated as"
- VGGT (Visual Geometry-Grounded Transformer): A large-scale transformer unifying multiple 3D vision tasks. "the Visual Geometry-Grounded Transformer (VGGT) unifies multiple 3D vision tasks within a single framework"
- XStreamVGGT: The proposed method combining pruning and quantization for memory-efficient streaming. "We propose XStreamVGGT, a tuning-free approach that systematically compresses the KV cache through joint pruning and quantization"
- Zero-point: An integer offset ensuring that zero is exactly representable in the quantized domain. "the zero-point ensures that the real-valued zero is exactly representable within the integer domain."
Collections
Sign up for free to add this paper to one or more collections.

