- The paper introduces a modular, chunk-based framework with confidence-aware alignment and loop closure that extends 3D reconstruction to kilometer-scale RGB sequences.
- It leverages overlapping chunk processing and Sim(3) transformations to achieve robust performance despite dynamic elements and drift without requiring calibration.
- Empirical results on KITTI, Waymo, and Virtual KITTI datasets show superior accuracy and efficiency, establishing VGGT-Long as a state-of-the-art method.
VGGT-Long: Scalable Monocular 3D Reconstruction for Kilometer-Scale RGB Sequences
Introduction and Motivation
Monocular 3D reconstruction from uncalibrated RGB streams is a central challenge in autonomous driving and large-scale scene understanding. While recent Transformer-based foundation models such as VGGT have demonstrated strong local 3D perception capabilities, their application to long, unbounded outdoor sequences is fundamentally constrained by quadratic memory scaling and drift accumulation. Prior attempts to address these issues have relied on complex SLAM backends or additional sensor modalities, introducing significant engineering overhead and limiting generality. VGGT-Long proposes a minimalist, modular approach that leverages the intrinsic strengths of VGGT, extending its applicability to kilometer-scale sequences without requiring camera calibration, depth supervision, or model retraining.
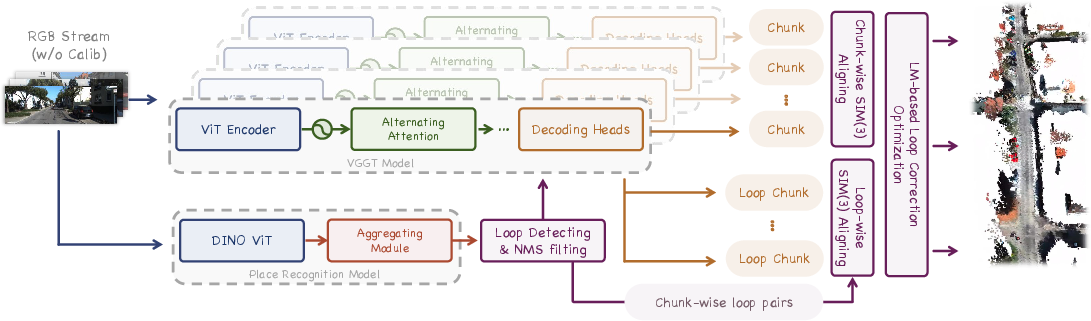
Figure 1: Overview of VGGT-Long, which processes long sequences by chunking, aligning, and loop closure, enabling scalable monocular 3D reconstruction for autonomous driving.
Methodology
Chunk-Based Processing and Local Alignment
VGGT-Long decomposes long RGB sequences into overlapping chunks, each processed independently by the VGGT model. This chunking strategy circumvents the prohibitive memory requirements of end-to-end Transformer inference on long sequences. For each chunk, VGGT outputs locally consistent camera poses and a dense 3D point map with per-point confidence estimates.

Figure 2: (a) Kilometer-scale sequences are divided into chunks. (b) Alignment is performed using overlapping frames in 3D space.
Adjacent chunks are aligned in 3D via a confidence-weighted Sim(3) transformation, estimated using IRLS with Huber loss. The confidence maps produced by VGGT are critical: low-confidence points (e.g., sky, dynamic objects) are down-weighted or discarded, ensuring that alignment is dominated by static, high-confidence structures. This approach is robust to dynamic scene elements and outliers, which are prevalent in outdoor driving scenarios.

Figure 3: Confidence-aware alignment suppresses the influence of high-speed dynamic objects, outperforming LiDAR in filtering dense traffic.
Loop Closure and Global Optimization
To mitigate drift, VGGT-Long incorporates a lightweight loop closure module. Visual place recognition (VPR) using DINOv2-based descriptors identifies loop candidates, and temporally disjoint sub-sequences are reprocessed by VGGT to generate high-quality loop-centric chunks. These are then aligned to the original chunks, providing robust geometric constraints for global optimization.
The global pose graph is optimized over Sim(3) transformations using a Levenberg-Marquardt solver, jointly minimizing sequential and loop closure constraints in the Lie algebra sim(3). This chunk-level optimization is highly efficient, converging in a few iterations and operating at millisecond timescales.
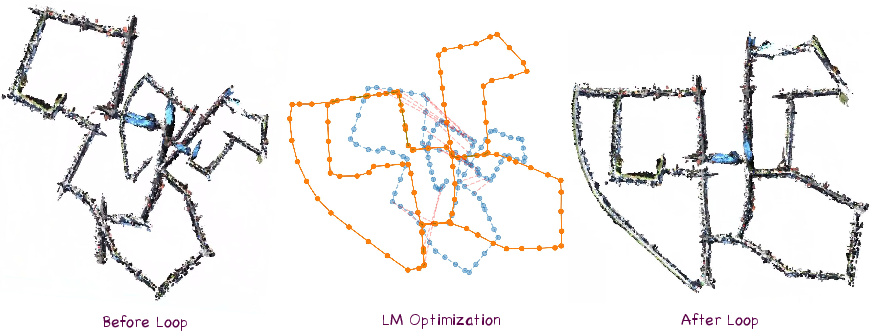
Figure 4: Without loop constraints, drift accumulates at kilometer scale; global LM optimization corrects this error.
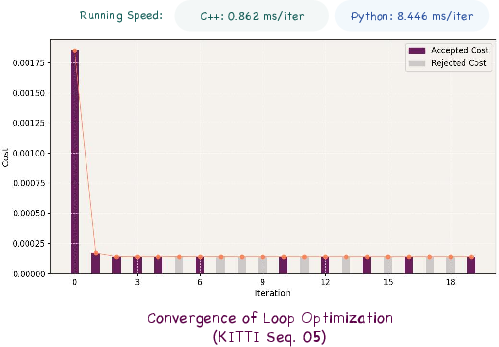
Figure 5: Loop optimization converges in three iterations, achieving millisecond-level performance.
Experimental Evaluation
Datasets and Metrics
VGGT-Long is evaluated on KITTI, Waymo Open, and Virtual KITTI datasets, covering real-world and synthetic, large-scale, and diverse environmental conditions. Metrics include Absolute Trajectory Error (ATE) for camera tracking and accuracy, completeness, and Chamfer distance for 3D reconstruction.
Quantitative and Qualitative Results
VGGT-Long achieves strong tracking and reconstruction performance across all datasets, outperforming prior learning-based methods (DROID-SLAM, DPVO, MASt3R-SLAM, CUT3R, Fast3R) in both accuracy and robustness. Notably, VGGT-Long is the only Transformer-based method to successfully process full-length sequences on a single RTX 4090 GPU, where others fail due to out-of-memory errors.
- On KITTI, VGGT-Long achieves an average ATE of 27.6m (18.3m excluding high-speed sequences), without requiring camera intrinsics, and consistently outperforms other learning-based and foundation model baselines.
- On Waymo, VGGT-Long attains an average ATE of 1.996m, with superior point cloud accuracy and completeness.
- On Virtual KITTI, VGGT-Long demonstrates robustness to weather and lighting domain shifts, maintaining low ATE across all conditions.
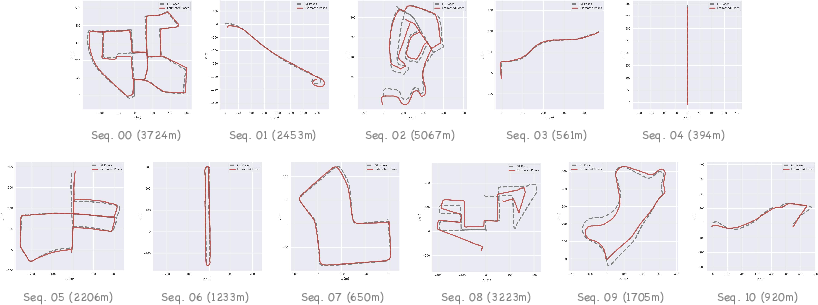
Figure 6: Trajectory visual results on KITTI. VGGT-Long maintains accuracy even when 2D loop detection fails due to ambiguous driving directions.
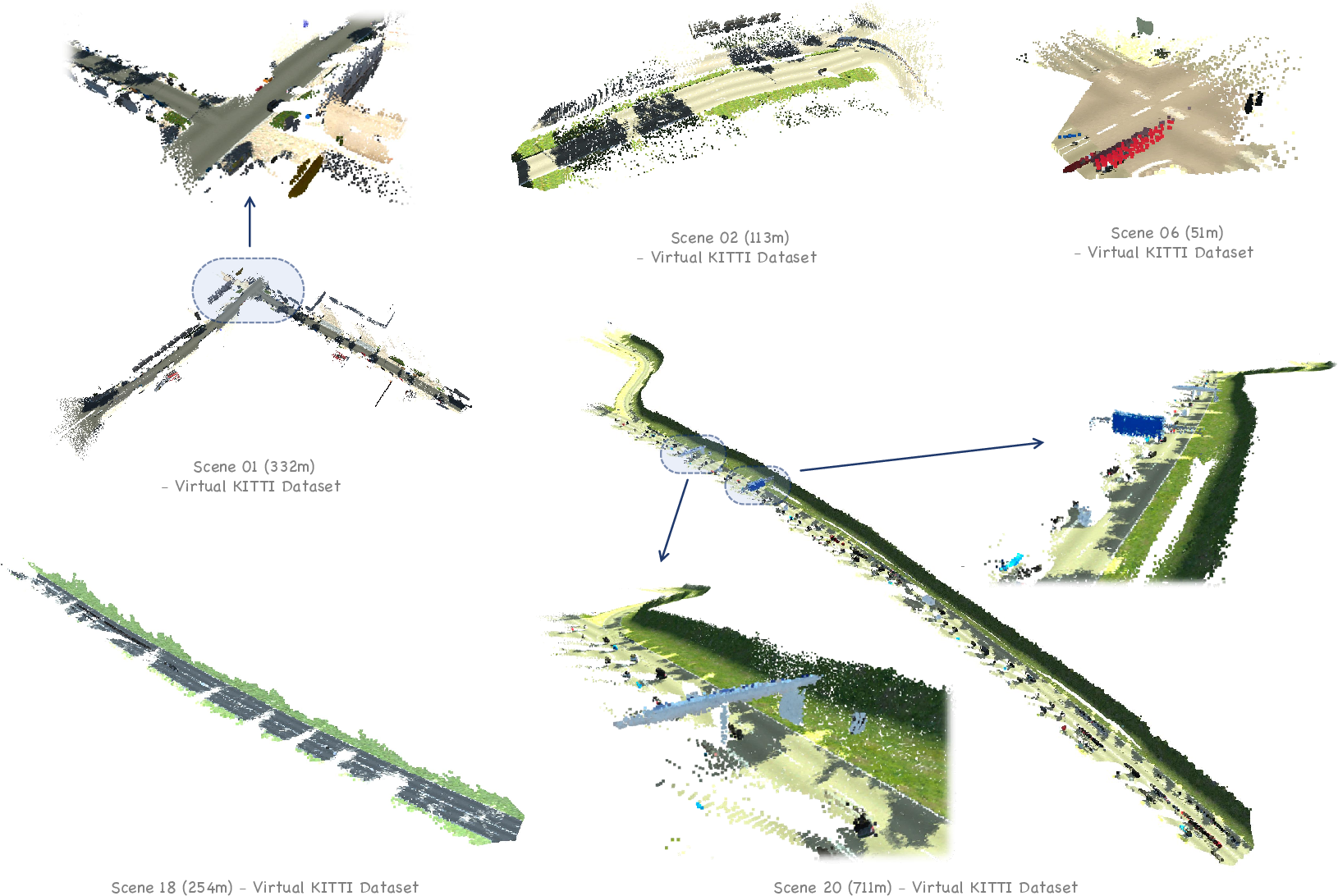
Figure 7: Visual results on Virtual KITTI, demonstrating robustness to synthetic domain shifts.

Figure 8: Visual comparison on Waymo Open Dataset, Part 1.
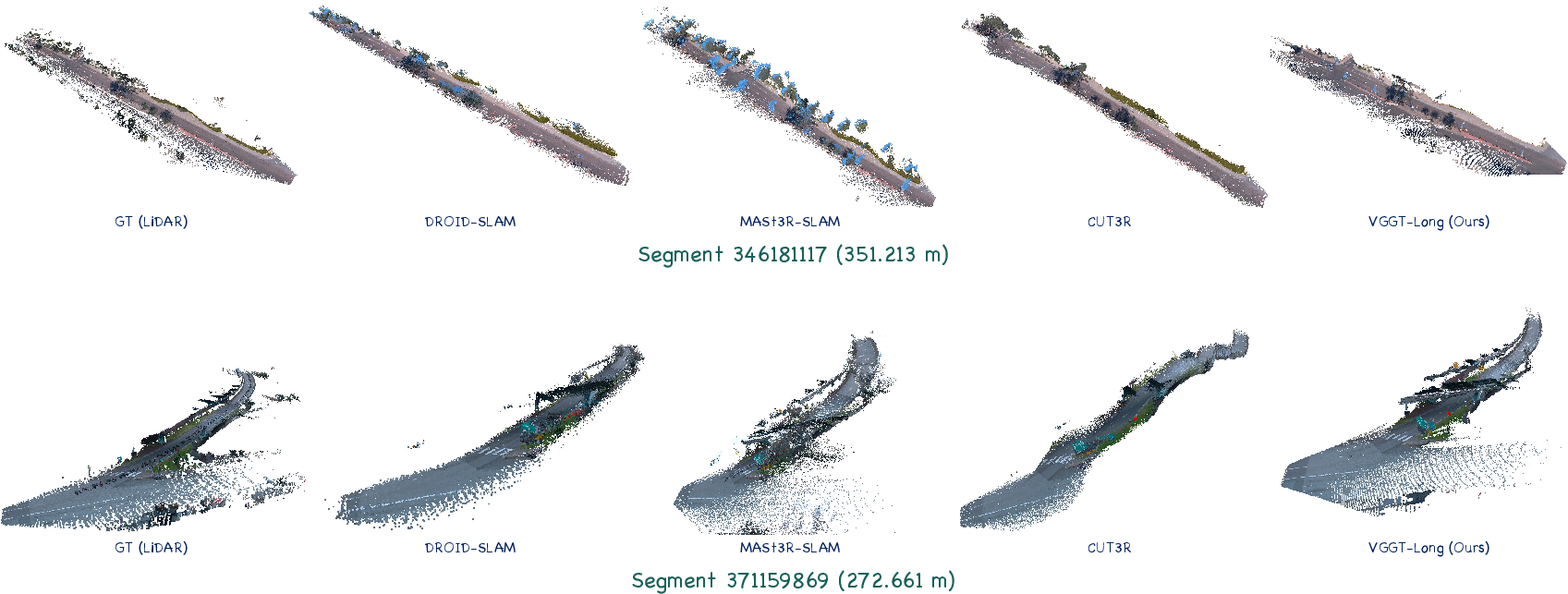
Figure 9: Visual comparison on Waymo Open Dataset, Part 2.

Figure 10: Visual comparison on Waymo Open Dataset, Part 3.

Figure 11: Visual comparison on Waymo Open Dataset, Part 4.
Ablation and Runtime Analysis
Ablation studies confirm the necessity of each component: disabling loop closure, IRLS, or confidence weighting leads to substantial degradation in ATE. The system achieves near real-time performance, with chunk processing at 2.6–2.8s per chunk and Sim(3) alignment at 0.2s. The global optimizer converges in three iterations, with per-iteration times of 0.4–1.3ms (C++).
Implementation Considerations
- Memory Management: Intermediate chunk outputs are offloaded to disk, and only relevant chunk pairs are loaded for alignment, enabling scalability to arbitrarily long sequences without exceeding CPU or GPU memory.
- No Calibration or Depth Supervision: VGGT-Long operates entirely on raw RGB input, without requiring camera intrinsics or ground-truth depth, increasing its applicability to real-world, uncalibrated settings.
- Minimal Backend Complexity: The system eschews complex SLAM backends, relying on the intrinsic capabilities of the foundation model and simple, efficient optimization routines.
Implications and Future Directions
VGGT-Long demonstrates that foundation models for 3D vision, when coupled with principled chunking, alignment, and loop closure strategies, can scale to real-world, kilometer-scale monocular reconstruction tasks. This approach challenges the prevailing assumption that large-scale reconstruction necessitates complex, multi-module systems. The results suggest that further improvements in foundation model architectures, confidence estimation, and chunk-level optimization could yield even greater scalability and accuracy.
Potential future directions include:
- Integration with real-time mapping and planning pipelines for autonomous vehicles.
- Extension to multi-modal inputs (e.g., event cameras, radar) while preserving the minimalist philosophy.
- Exploration of adaptive chunking and dynamic memory management for heterogeneous hardware environments.
- Investigation of self-supervised or continual learning strategies to further improve robustness in open-world deployment.
Conclusion
VGGT-Long provides a scalable, calibration-free solution for monocular 3D reconstruction in long, unbounded outdoor environments. By leveraging the strengths of foundation models and introducing a lightweight chunk-and-align framework, it achieves state-of-the-art performance on challenging benchmarks, with strong implications for the deployment of vision-based perception in autonomous systems.