- The paper proposes a novel hybrid attention architecture combining Gated DeltaNet and Sliding Window Attention to achieve scalable and efficient vision-language modeling.
- It introduces a three-stage training protocol involving distillation, instruction SFT, and long-sequence fine-tuning to enhance long-context generalization and fast inference.
- Experimental results demonstrate state-of-the-art performance on VQA, OCR, and document benchmarks while maintaining constant memory usage and sub-quadratic inference time.
InfiniteVL: Hybrid Linear-Sparse Attention for Unbounded, Efficient Vision-Language Modeling
Motivation and Background
The scalability of Vision-LLMs (VLMs) is fundamentally limited by the quadratic complexity and ever-growing key-value (KV) cache requirements of Transformer-based architectures during inference. Existing approaches to efficient context handling in VLMs converge on two principal directions: windowed attention variants, which restrict attention computation to local windows to reduce complexity but sacrifice long-term context retention, and linear attention variants, which provide sub-quadratic complexity and fixed cache size but are typically unable to maintain fine-grained local or information-dense semantics. These paradigms force a trade-off between global context memory and local task accuracy.
InfiniteVL sets out to obviate this dichotomy, offering a hybrid attention architecture that synergistically combines Gated DeltaNet linear modules and Sliding Window Attention (SWA), thereby supporting both scalable context modeling and fine-grained multimodal reasoning under constant computational and memory budgets.
InfiniteVL Architecture
InfiniteVL adopts a three-part design consisting of a vision encoder, an MLP-based visual projector, and a decoder-only LLM. The vision encoder leverages high-resolution ViT and is natively capable of processing arbitrary visual input modalities—images, video sequences, or streaming data. Visual token sequences are projected to the LLM embedding space and concatenated with tokenized text inputs. The main processing stack interleaves Hybrid Blocks, each containing one SWA layer followed by three Gated DeltaNet layers.
This hybridization delivers fine-grained local attention through SWA, maintaining performance on information-dense, short-context tasks, while Gated DeltaNet layers confer constant-complexity, scalable context retention for arbitrarily long input streams. The memory mechanism of DeltaNet employs a Householder-style update, effectively mitigating low-rank collapse and memory collisions common to vanilla linear attention. Notably, the entire system remains self-contained, eliminating the need for external memory augmentation, facilitating deployment on constrained hardware.
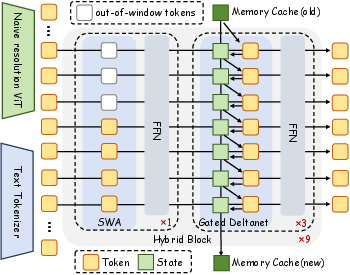
Figure 1: Overview of the InfiniteVL model architecture, showing the components, data flow, and hybrid attention scheme.
Training Protocol
Model performance and sample efficiency are achieved through a targeted three-stage training strategy:
- Distillation Pretraining: Parameters (excluding attention layers) are initialized from a full-attention teacher VLM (Qwen2.5-VL). Attention layers are replaced by Gated DeltaNet modules, which are first aligned layer-wise via MSE loss and then end-to-end via soft target distillation.
- Instruction SFT: The model is fine-tuned for robust, instruction-following multimodal alignment using high-quality dialog and task-specific corpora, with large-scale supervised signal. Image resolution is increased and maximum sequence length is 8192 tokens to facilitate domain transfer, efficient alignment, and format controllability.
- Long-Sequence SFT: To promote robust length generalization and long-range multimodal reasoning, maximum context lengths are extended to $32,768$ tokens, and training incorporates a diverse blend of long video QA/caption, high-resolution document, and multimodal instruction samples, principally via LoRA adapters for efficiency.
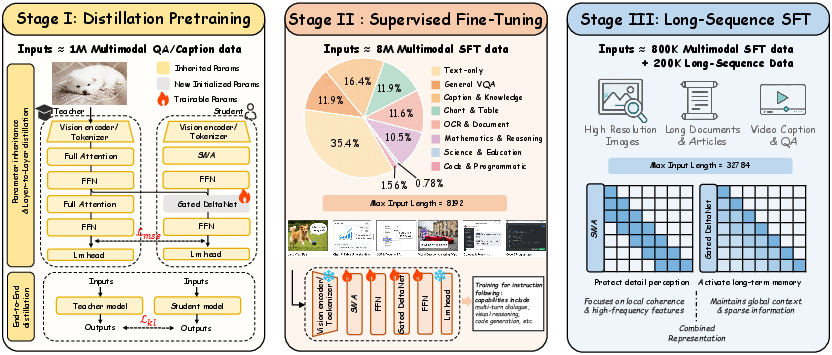
Figure 2: Training protocol of InfiniteVL, illustrating staged distillation, alignment, and task-specific fine-tuning.
Experimental Results
Multimodal Benchmarking
InfiniteVL attains competitive performance with state-of-the-art, similarly sized Transformer-based VLMs (e.g., Qwen2.5VL-3B, InternVL2.5-4B), outperforming all prior linear/hybrid VLMs (e.g., Cobra-3B, MaTVLM-3B) across a comprehensive suite of benchmarks encompassing VQA, document understanding, OCR, chart reasoning, and general multimodal comprehension. Specifically, on information-dense metrics such as DocVQA, TextVQA, and OCRBench, InfiniteVL either matches or closely approaches the top-performing transformer models—a significant deviation from previous linear-complexity VLMs, which exhibit a historic drop on these tasks.
Long-Context Generalization and Inference Efficiency
A key result is InfiniteVL's strong length generalization: evaluation on ultra-long context video benchmarks demonstrates that InfiniteVL maintains stable accuracy as input sequence size increases, whereas windowed-transformer baselines (Qwen2.5VL-3B(SWA)) degrade sharply beyond their context window. InfiniteVL retains coherence and memory over input streams exceeding 1024 frames (up to 256K tokens).
Furthermore, InfiniteVL delivers over 3.6× inference speedup at 50K tokens compared to leading FlashAttention-2–accelerated Transformers, with a constant per-token latency and fixed memory use (∼9 GB VRAM), independent of sequence length. In real-time streaming, the system sustains 24 FPS at a stable compute profile, whereas transformer baselines suffer exponential slowdowns and memory exhaustion as cache grows.
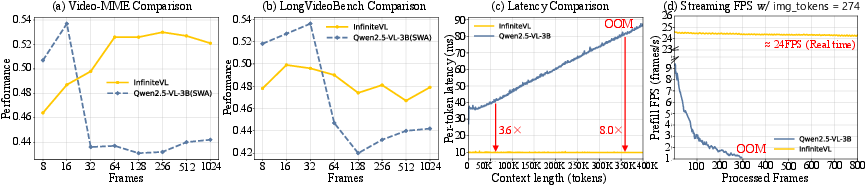
Figure 3: InfiniteVL maintains stable accuracy/efficiency with growing context, unlike window-based models suffering performance degradation and resource exhaustion in long-sequence scenarios.
Memory Dynamics and Robustness in Streaming Settings
Analysis of the Gated DeltaNet cache norm reveals rapid initial growth followed by plateauing and stabilization with increasing input frames. This indicates effective memory management, avoiding the instability and collapse observed in traditional linear or windowed attention under unbounded streaming input regimes.
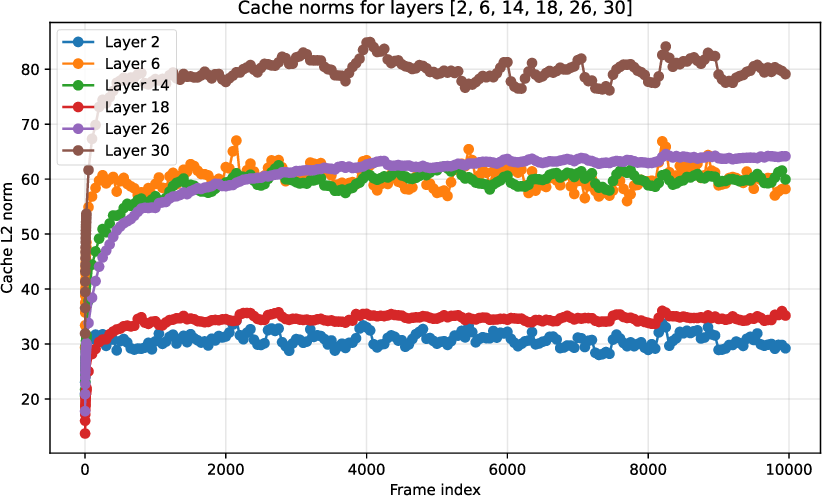
Figure 4: L2 norm of the linear-layer memory cache, showing efficient stabilization with context growth during streaming input.
Qualitative Analysis
InfiniteVL demonstrates strong zero-shot generalization across diverse visual-language tasks, including fine-grained OCR, information-structural document, and chart reasoning. Furthermore, long-horizon streaming understanding is robust—even at over 500K tokens—preserving situational context and reasoning capability in extended input sequences.
(Figures 5, 6, and 7)
Figure 5: Example visual-language scenarios with accurate compositional and semantic understanding.
Figure 6: Streaming video understanding with preservation of long-term context and memory retention.
Figure 7: Additional examples of robust comprehension under ultra-long context streaming inputs.
Theoretical and Practical Implications
InfiniteVL demonstrates that a hybridization of linear and windowed sparse attention can achieve both the long-term memory retention of state-space architectures and the fine-grained local context modeling of transformers. By inherently solving the KV cache scaling problem without sacrificing efficiency or downstream performance, the model is ideally positioned for deployment on edge devices and in streaming AI agents.
The three-stage training pipeline, specifically the staged distillation approach from large-scale Transformers to a hybrid linear/sparse student, is shown to be critical for stability and downstream efficacy. The results indicate that sample-efficient, scalable multimodal generalization is attainable even under limited resource and data constraints when leveraging judicious architectural hybridization and knowledge transfer.
Prospects for Future Work
Further research should explore optimization of the ratio and arrangement of SWA to DeltaNet layers, dynamic reweighting of memory retention mechanisms, and more expressive, domain-specific memory representations. There is also a potential to extend hybrid linear-sparse designs to cross-modal generation or to augment with biologically inspired continual learning schemes for memory stability under distribution shift.
Conclusion
InfiniteVL establishes a compelling architecture and training framework for unbounded, efficient vision-language modeling. Through its hybridization of sparse and linear attention, InfiniteVL not only matches transformer-based VLMs on canonical VQA, OCR, and document benchmarks, but also achieves sequence-length–agnostic inference both in latency and memory—a crucial step toward practical, scalable multimodal AI deployment. The approach exemplified by InfiniteVL is likely to inform the next generation of efficient, resilient, and deployable foundation models for vision-language tasks (2512.08829).

