- The paper introduces Evict3R, which implements a training-free token eviction mechanism to control KV cache growth in streaming visual geometry transformers.
- It employs per-layer budget allocation and attention-based importance scoring to efficiently select and retain tokens, ensuring scalable memory usage.
- Experimental results show that Evict3R maintains 3D reconstruction and pose estimation accuracy while halving memory consumption compared to previous approaches.
Introduction and Motivation
Evict3R addresses a critical bottleneck in streaming visual transformer architectures, specifically StreamVGGT, which is designed for real-time, multi-view 3D perception. While StreamVGGT leverages causal attention and key–value (KV) caching to enable efficient autoregressive inference, its KV cache grows linearly with sequence length, resulting in unbounded memory consumption and limiting scalability for long-horizon tasks. Existing solutions either impose fixed external memories, risking information loss and drift, or require architectural modifications and retraining, complicating deployment.
Evict3R introduces a training-free, inference-time token eviction mechanism that enforces per-layer KV cache budgets and selects tokens for retention using attention-based importance scores. This approach is inspired by recent advances in LLM KV cache management, but is adapted for the unique requirements of visual geometry transformers. The method enables scalable streaming inference, allowing for longer sequences and denser frame sampling under strict memory constraints, with minimal impact on reconstruction accuracy and completeness.


Figure 1: Qualitative comparison of 3D pointmaps from StreamVGGT and Evict3R (B=0.2); Evict3R achieves similar reconstruction quality with less than half the memory.
Classical SfM and MVS pipelines provide accurate 3D reconstructions but are unsuitable for real-time, incremental updates due to their reliance on global optimization and repeated data association. End-to-end learning-based approaches, such as DUSt3R and VGGT, infer geometry directly from images but are typically offline and require re-encoding the entire sequence for new frames.
Streaming architectures, including CUT3R, Spann3R, and Point3R, introduce persistent states or explicit spatial pointer memories to manage context, but these solutions either suffer from capacity-induced drift or require complex architectural changes. StreamVGGT adopts causal attention with KV caching, enabling efficient streaming but at the cost of unbounded memory growth.
Token management strategies from the LLM literature, such as H2O, Scissorhands, D2O, and PyramidKV, use attention-based importance scores and layer-wise budget allocation to manage KV cache growth. Evict3R adapts these principles for visual transformers, introducing per-layer control and normalization strategies to ensure consistent token selection across layers.
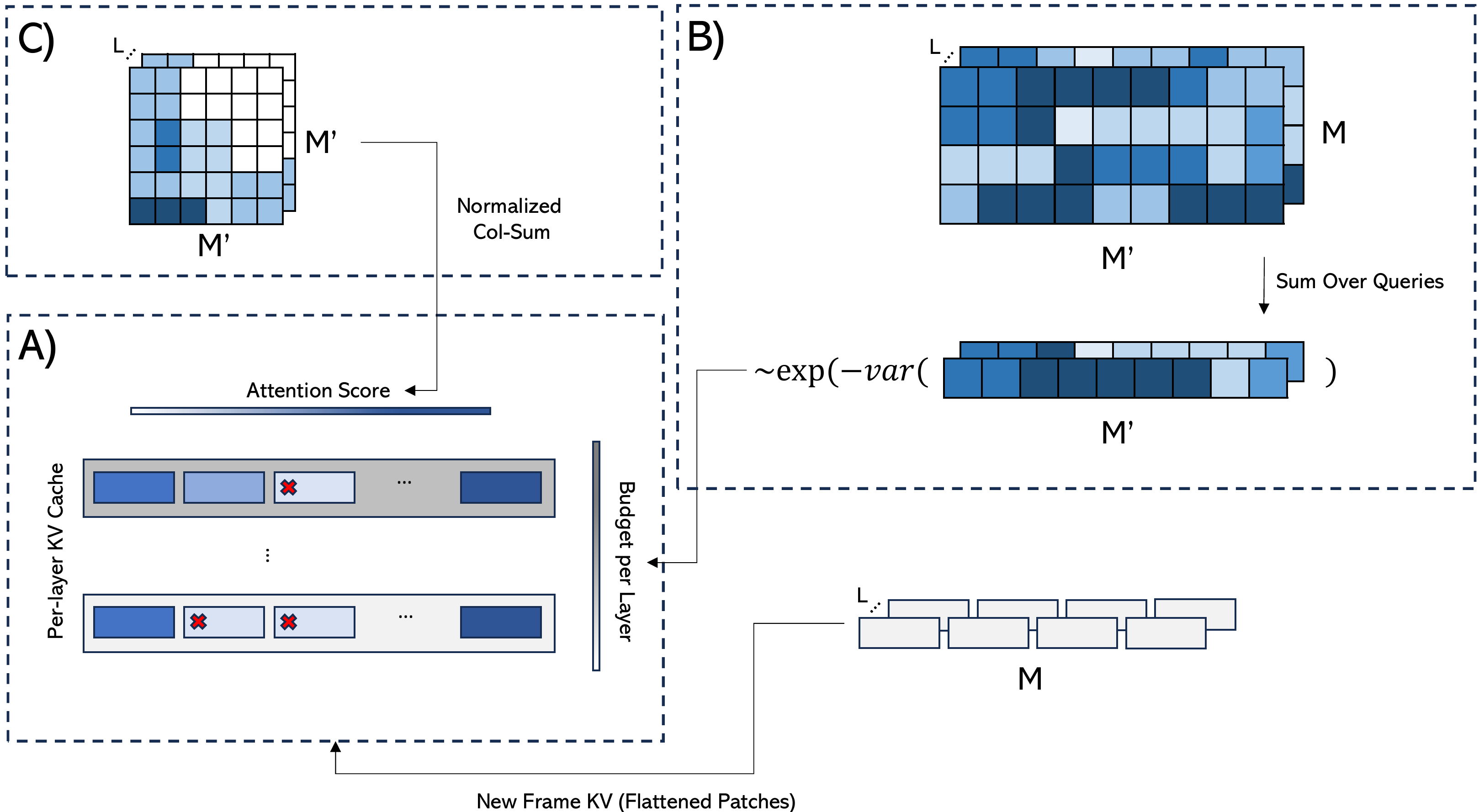
Figure 2: Overview of the token eviction framework: (A) tokens in each layer’s KV cache are ranked by attention importance and evicted under a per-layer budget; (B) importance scores are derived from query–key attention statistics; (C) scores are normalized for consistent selection across layers.
Methodology
StreamVGGT Architecture and KV Cache Growth
StreamVGGT processes input frames through a DINO encoder, producing feature tokens that are concatenated and passed through a transformer with alternating frame-wise and global self-attention layers. Causal global attention enables each incoming frame to attend to all previous frames via the cached KV memory, supporting incremental updates and low-latency inference. However, the KV cache size increases linearly with the number of frames, leading to scalability issues.
Per-Layer Budget Allocation
Evict3R sets a total KV cache budget B and allocates it across global-attention layers based on attention sparsity, measured by the variance of attention maps. Layers with denser attention patterns receive larger budgets, while sparser layers are allocated fewer tokens. The allocation is computed as:
πℓ=∑r=1Lgexp(−Var(St(r))/τ)exp(−Var(St(ℓ))/τ)
Bℓ=⌊B⋅πℓ⌋
where St(ℓ) is the sum of attention weights for cached tokens in layer ℓ, and τ is a temperature parameter.
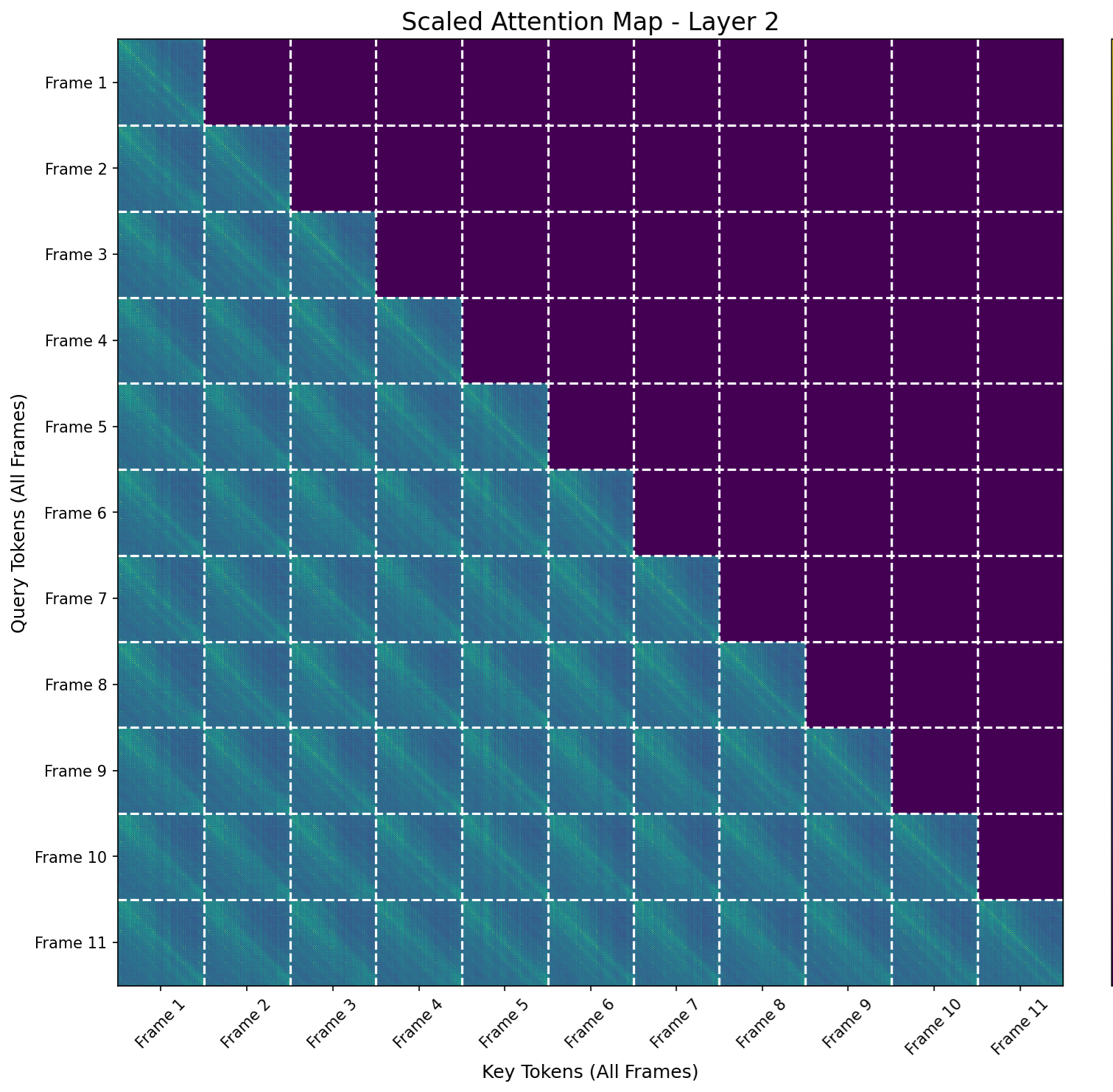
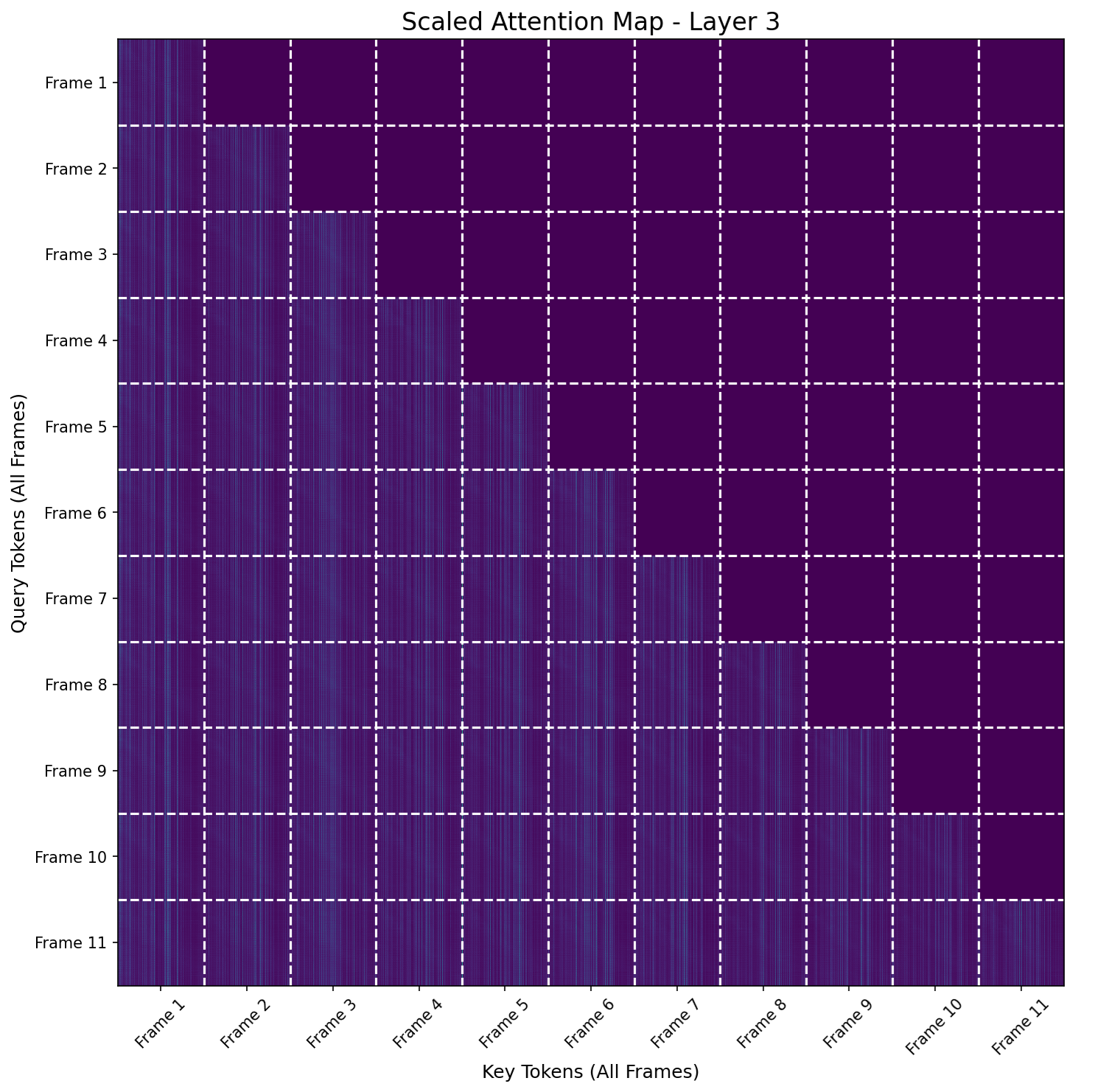
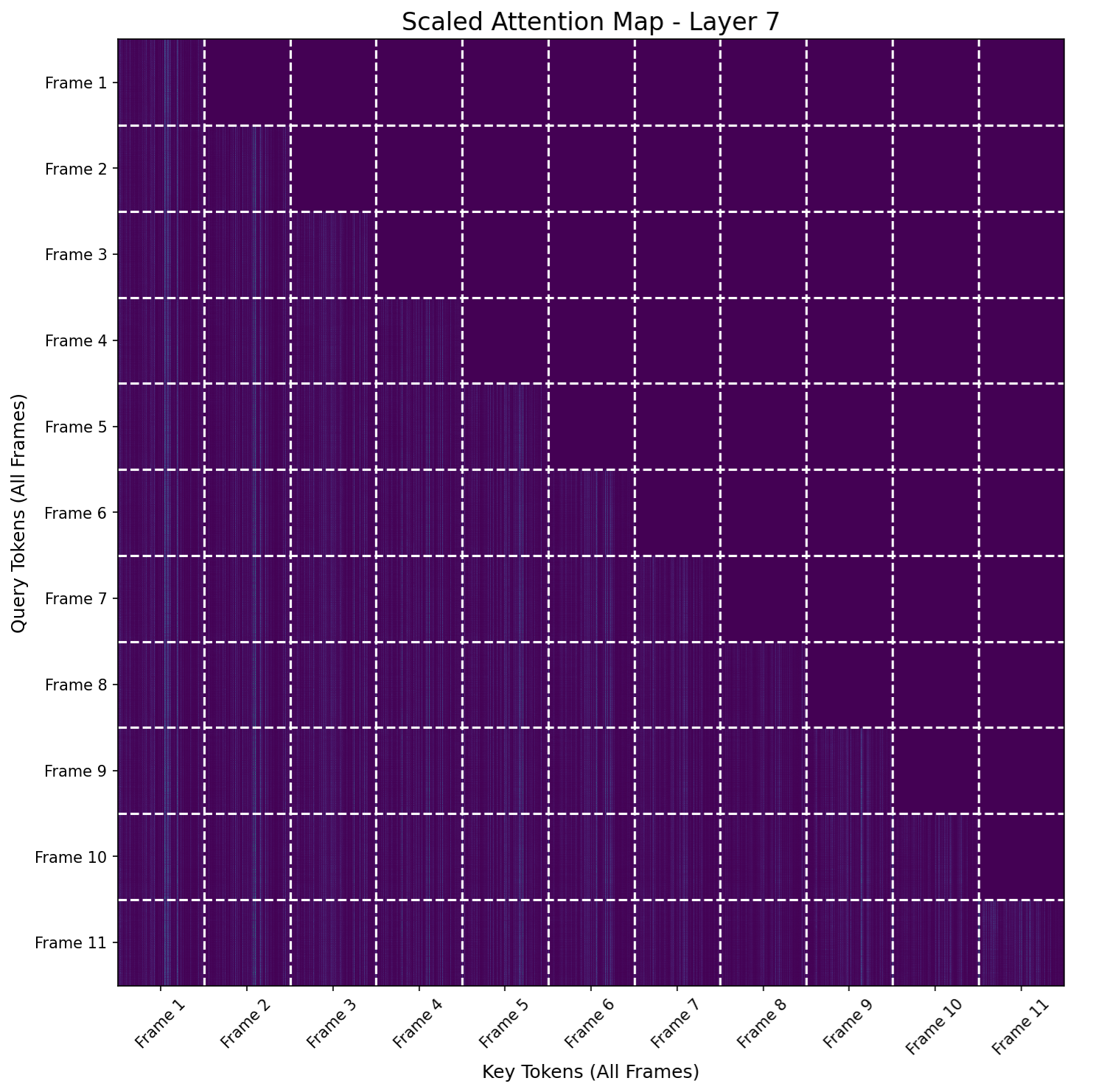
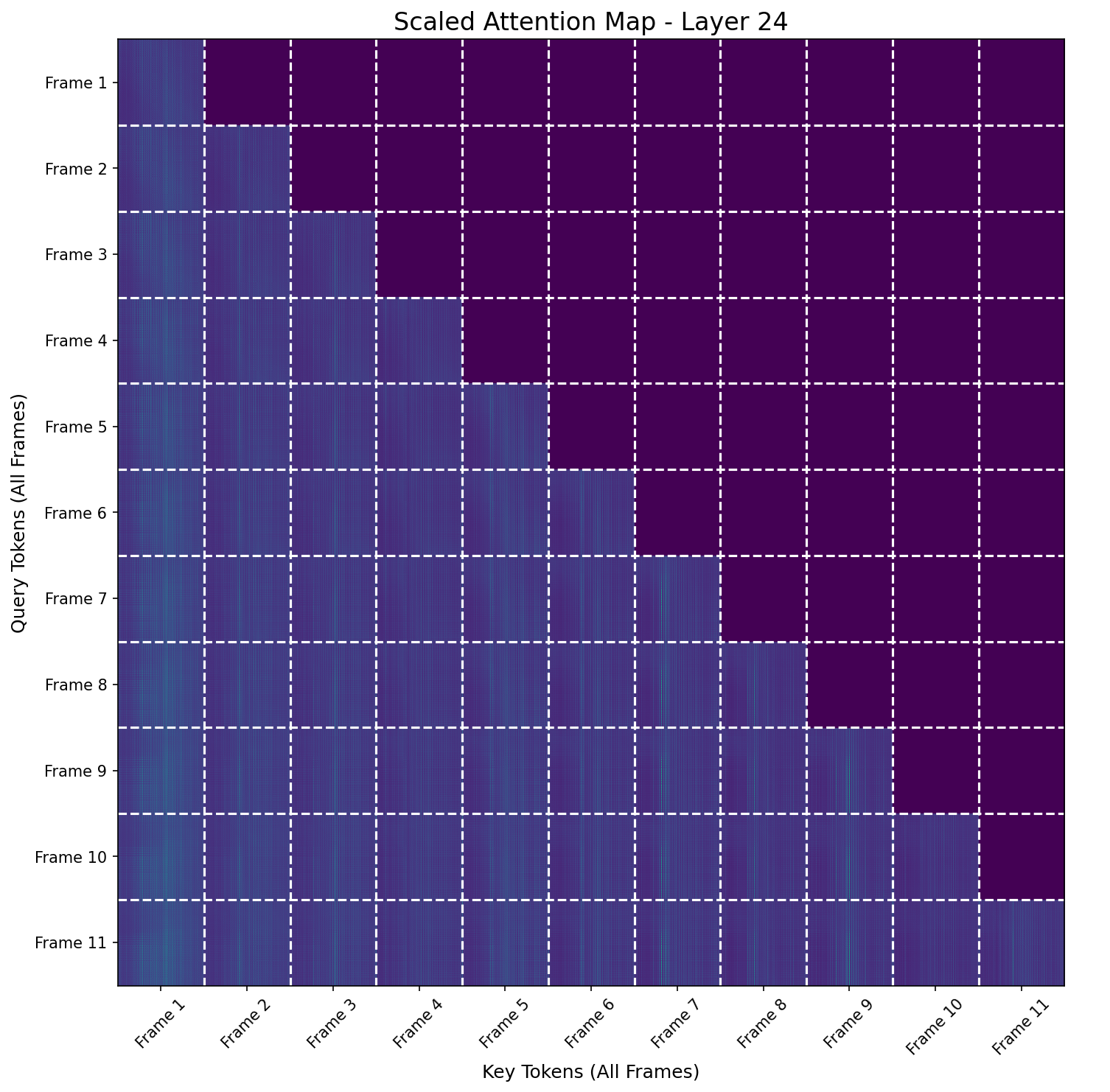
Figure 3: Head-averaged attention maps for StreamVGGT layers, illustrating dense attention in early and late layers and sparser patterns in middle layers.
Token Selection and Eviction
Tokens are ranked for eviction using a normalized cumulative attention score, aggregating attention received across time, heads, and queries. Row-length normalization corrects for early steps with fewer keys, and exposure normalization accounts for token tenure in the cache:
ij(ℓ)=ej(ℓ)c^j(ℓ)
where c^j(ℓ) is the row-length normalized cumulative attention and ej(ℓ) is the exposure count. Tokens from the first frame and special tokens (camera, register) are always retained to preserve global reference and reconstruction integrity.
Eviction is performed per layer when the cache exceeds its budget, discarding the least important tokens until sufficient slots are available for new keys and values.




Figure 4: Token eviction masks for the first layer across frames 2–5; blue-bordered squares indicate evicted tokens, showing preference for retaining tokens covering salient geometry.
Experimental Results
Video Depth Estimation
On Sintel and KITTI, Evict3R matches StreamVGGT accuracy at moderate budgets, with absolute relative error (Abs Rel) and δ<1.25 metrics remaining stable as the budget decreases. For example, on KITTI, Evict3R with B=0.8 achieves Abs Rel of 0.174 and δ<1.25 of 71.9, closely matching StreamVGGT.
3D Reconstruction
On 7-Scenes and NRGBD, Evict3R maintains reconstruction quality under strict memory budgets. With ultra-long sequences (8× and 10× frames), Evict3R reduces peak memory usage from 18.63 GB to 9.39 GB on 7-Scenes, with accuracy and completeness dropping by only 0.003. Notably, under low budgets (B=0.1), Evict3R can outperform StreamVGGT on NRGBD, demonstrating that denser frame sampling enabled by eviction can improve reconstruction accuracy.
Camera Pose Estimation
Evict3R achieves competitive performance on Sintel and TUM-dynamics, with absolute translation error (ATE) and relative errors comparable to online streaming baselines. The method remains robust under tight budgets, with performance degrading gracefully as the budget is reduced.
Ablation Studies
Evict3R’s scoring-based eviction outperforms random and uniform budget allocation strategies, especially under tight budgets. Qualitative analysis of eviction masks confirms that the method preferentially retains tokens covering salient geometry, supporting the design objective.
Latency analysis shows that token eviction stabilizes per-frame inference time as sequence length increases, mitigating the quadratic growth in computational cost associated with unbounded KV caches.
Implications and Future Directions
Evict3R demonstrates that principled, training-free token eviction can effectively bound memory usage in streaming visual transformers without sacrificing accuracy. The approach is architecture-agnostic, requiring no retraining or modification of model weights, and can be flexibly tuned at inference time. This enables practical deployment of streaming 3D perception models on resource-constrained hardware and supports long-horizon tasks in robotics and autonomous systems.
Theoretical implications include the validation of attention-based importance scoring and layer-wise budget allocation for visual transformers, extending concepts from LLMs to the vision domain. Future work may explore adaptive budget allocation, integration with external spatial memories, and application to other streaming transformer architectures.
Conclusion
Evict3R provides an effective solution to the memory scalability challenge in streaming visual geometry transformers. By enforcing per-layer KV cache budgets and evicting redundant tokens based on normalized attention scores, the method enables efficient, long-horizon streaming inference with minimal impact on reconstruction quality. Extensive experiments confirm strong accuracy–efficiency trade-offs, and ablation studies validate the robustness of the eviction strategy. Evict3R represents a practical advancement toward scalable, real-time 3D perception in resource-limited environments.

