Output Embedding Centering for Stable LLM Pretraining
Abstract: Pretraining of LLMs is not only expensive but also prone to certain training instabilities. A specific instability that often occurs for large learning rates at the end of training is output logit divergence. The most widely used mitigation strategy, z-loss, merely addresses the symptoms rather than the underlying cause of the problem. In this paper, we analyze the instability from the perspective of the output embeddings' geometry and identify its cause. Based on this, we propose output embedding centering (OEC) as a new mitigation strategy, and prove that it suppresses output logit divergence. OEC can be implemented in two different ways, as a deterministic operation called μ-centering, or a regularization method called μ-loss. Our experiments show that both variants outperform z-loss in terms of training stability and learning rate sensitivity. In particular, they ensure that training converges even for large learning rates when z-loss fails. Furthermore, we find that μ-loss is significantly less sensitive to regularization hyperparameter tuning than z-loss.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper looks at a common training problem in LLMs: sometimes, near the end of training, the model’s “scores” for the next word (called logits) blow up to very large values. When that happens, training becomes unstable and can fail, wasting time and money. The authors explain why this happens and introduce a simple fix that makes training more stable.
Key Questions
The paper asks:
- Why do the output logits of LLMs sometimes diverge (go to very large or very small values)?
- Can we prevent this in a way that fixes the root cause, not just the symptoms?
- How do new methods compare to the popular “z-loss” technique in terms of stability, learning rate sensitivity, and ease of tuning?
Methods and Main Ideas (in everyday language)
To understand the approach, here are a few simple definitions:
- Logits: These are the raw scores a model gives to each possible next word before turning them into probabilities. If logits get extremely large or extremely negative, training can break.
- Output embeddings: Think of each word as a point in a multi-dimensional space (like coordinates). The model scores a word by comparing its output embedding to the model’s current state (using a dot product).
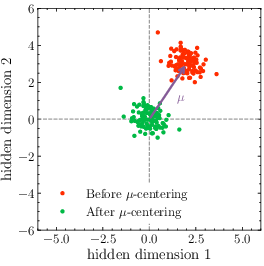
- Mean output embedding (μ): This is the “average position” of all word embeddings. If this average drifts far from zero, it can push logits up or down overall.
What’s going wrong:
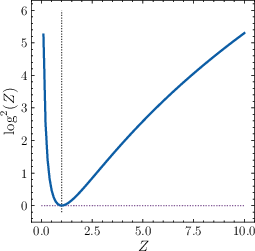
- During training, the output embeddings tend to shift together in one direction (the “average” moves away from zero). This shift can make the logits grow too large or too small, causing instability. This effect is called anisotropy: the embeddings do not spread evenly in all directions; they tilt in a common direction.
Existing fix (“z-loss”):
- z-loss is a regularization trick that adds a penalty when the combined logits get too big. It helps in many cases, but it mainly treats the symptom—large scores—rather than the cause—the common shift in output embeddings. It also doesn’t catch every kind of bad behavior (for example, a single logit can still go very negative).
The paper’s fix: Output Embedding Centering (OEC)
- Main idea: Keep the average output embedding centered near zero to prevent the collective drift. If the average is near zero, the logits don’t get forced up or down as a group, reducing the chance of runaway values.
- Two ways to do it:
- μ-centering: After each training update, subtract the current average embedding from every output embedding. This directly re-centers the cloud of points around zero. It’s deterministic (no extra knobs to tune).
- μ-loss: Add a small penalty term that punishes the model if the average output embedding drifts away from zero. This gently pulls the average back toward zero. It has a regularization strength (λ), but the authors show it’s not very sensitive to the exact value.
Why μ-centering helps:
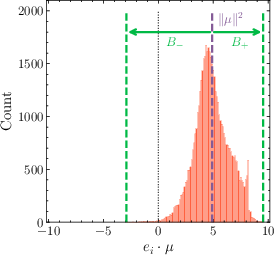
- Centering reduces the global bounds of logits (keeps them from becoming too extreme), because the part of the embeddings that aligns with the average is what mainly drives logits up or down together. Remove that, and you cut off the path to explosion.
Main Findings
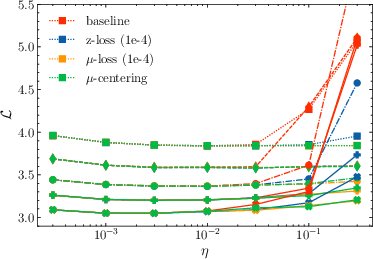
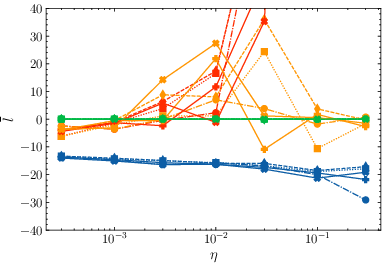
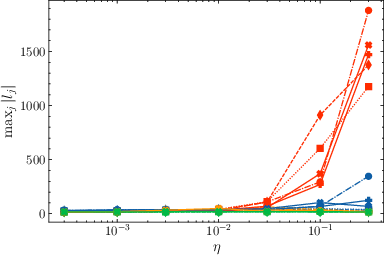
- Stability: Both μ-centering and μ-loss prevent the kinds of logit blow-ups that make training fail, even at high learning rates where z-loss sometimes still fails.
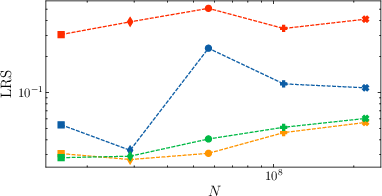
- Learning rate sensitivity: The new methods let training succeed across a wider range of learning rates (they are less “picky”). In tests on models up to 221 million parameters, μ-centering and μ-loss consistently showed lower sensitivity to learning rate than z-loss.
- Hyperparameter sensitivity: μ-loss worked well across a broad range of the regularization strength λ; it didn’t need careful tuning. In contrast, z-loss required more precise tuning, and the best value was often higher than the usual default.
- Training speed: The new methods add very little extra training time compared to z-loss.
- Accuracy: All methods reached similar best losses (so the fix doesn’t hurt performance).
In short: μ-centering and μ-loss fix the cause (the drifting average of output embeddings) and are more robust than z-loss. They keep logits from going off the rails without harming how well the model learns.
Why This Matters
- Training big models is expensive. Crashes or unstable runs waste huge amounts of compute and money. A simple, reliable method to stabilize training saves resources and speeds up research.
- By addressing the root cause (the average shift of output embeddings), these methods offer a more principled and predictable solution than z-loss, which focuses on the symptom (big logits).
Potential Impact and Limitations
- Impact: These techniques could become standard tools for training LLMs, especially when using higher learning rates to speed up training. They may help teams avoid instability, reduce the need for careful tuning, and improve overall training reliability.
- Limitations: The experiments were done up to 221 million parameters and with specific data and settings. Results may vary at much larger scales or with different setups. The paper doesn’t prescribe a single “best” choice between μ-centering and μ-loss; both work, and the better option may depend on the training pipeline.
A Quick Recap of the New Methods
- μ-centering (deterministic):
- What it does: Subtract the average embedding from every output embedding after each update.
- Pros: No extra hyperparameters, directly fixes the drift, strong stability.
- μ-loss (regularization):
- What it does: Adds a penalty that keeps the average embedding near zero.
- Pros: Simple, effective, not sensitive to the penalty strength, and also fixes the root cause.
Together, they make LLM training more stable by keeping the “center of gravity” of word representations where it should be—around zero—so the model’s scores don’t spiral out of control.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper leaves the following concrete issues unresolved; addressing them would clarify generality, mechanisms, and practical adoption:
- Scaling to frontier models: Validate OEC (μ-centering and μ-loss) on multi‑billion to 100B+ parameter LLMs trained on 100B–>1T tokens with full data/model/optimizer parallelism, to confirm stability and overhead at scale.
- Distributed implementation details: Specify and benchmark μ-centering when output embeddings are sharded (row/column-parallel, tensor/pipeline parallel). Quantify synchronization costs, numerical drift, and race conditions in multi-node setups.
- Generality across architectures: Test on encoder–decoder models, masked LMs (BERT/RoBERTa), MoE, retrieval-augmented models, and vision/language heads to see if OEC suppresses divergence beyond decoder-only next-token setups.
- Weight tying effects: Evaluate OEC when input/output embeddings are tied (common in LLMs). Determine whether centering output embeddings harms input embedding space, and whether separate or shared centering is preferable.
- Optimizer interactions: Study OEC with optimizers beyond AdamW (e.g., Adam, Adafactor, AdaBelief, Lion, Coupled Adam). Determine whether OEC is complementary or redundant with Coupled Adam (which targets the same mean-shift mechanism).
- LR schedule, batch size, and noise: Assess robustness under different warmup lengths, constant/step LR, large-batch regimes, gradient accumulation, and noise scales; quantify how these training dynamics modulate the mean shift and OEC efficacy.
- Alternative stabilization methods: Systematically compare/compose OEC with z‑loss variants (max‑z), logit soft-capping, NormSoftMax, label smoothing, temperature schedules, and output-layer normalization to map compatibility and best-practice stacks.
- Theorem assumptions and failure modes: Theorem 1 relies on an empirical bound ratio ; characterize conditions/data/model regimes where this fails, how often during training, and whether adaptive/conditional OEC is needed.
- Hidden-state normalization dependence: The analysis assumes (approximately) normalized final hidden states; verify OEC under RMSNorm vs LayerNorm, Pre‑LN vs Post‑LN, and models without final normalization.
- Downstream and calibration impacts: Beyond test loss, measure effects on calibration (ECE/Brier), uncertainty, logit margins, toxicity/bias, and downstream task performance (zero/few-shot, instruction-following, RLHF).
- Token-frequency and rare-token behavior: Analyze how centering affects high- vs low-frequency tokens’ embedding norms and logits; check for degraded modeling of rare/special tokens or increased uniformity that harms specificity.
- Long-context regimes: Evaluate with longer sequence lengths (e.g., 8k–128k) and RoPE scaling; test whether OEC mitigates or interacts with long-context instabilities.
- Quantization and reduced precision: Test OEC with FP8/8‑bit optimizers, 4/8‑bit inference quantization, and loss scaling to ensure numerical stability and no degradation in quantized deployment.
- Inference-time behavior: Check whether OEC changes sampling dynamics (e.g., nucleus sampling quality, repetition, entropy) given its influence on logit bounds; study interaction with typical inference-time logit scaling/clipping.
- Training to late-stage convergence: The instability often appears late in training; extend runs well beyond 13.1B tokens to verify that OEC prevents end‑of‑training spikes at realistic convergence points.
- Hyperparameter guidance: Provide practical decision rules for when to prefer μ‑centering vs μ‑loss (e.g., by scale, parallelism, sharding constraints). Explore adaptive λ schedules for μ‑loss tied to measured , max|logit|, or training phase.
- Monitoring/diagnostics: Define on-the-fly metrics (e.g., , max|logit|, bounds) and safe thresholds; propose automated triggers for enabling/disabling or adjusting OEC during training.
- Expressivity and geometry: Quantify how μ‑centering alters embedding geometry beyond mean removal (e.g., spectrum, anisotropy indices) and whether it constrains expressivity or harms semantic structure in embedding space.
- Broader instability coverage: Verify whether OEC impacts other instabilities (e.g., attention logit explosions, gradient spikes) or if targeted measures are still required alongside OEC.
- Vocabulary, tokenization, and multilinguality: Test across tokenizers (SentencePiece, Unigram), larger/smaller vocabularies, multilingual corpora, and domain-specific datasets to ensure the centering mechanism generalizes.
- Alternative heads/losses: Evaluate with sampled softmax, adaptive/hierarchical softmax, contrastive objectives, or classification heads to test whether OEC’s benefits carry over when the softmax head is modified.
- Fine-tuning and alignment phases: Assess OEC during supervised fine-tuning, preference optimization (DPO), and RLHF to check compatibility with changing loss landscapes and stability under distribution shift.
- Causal validation of mechanism: Perform controlled interventions that manipulate only the mean shift (e.g., inject/remove without changing variances) to establish causal, not just correlational, links between anisotropy and logit divergence.
Practical Applications
Immediate Applications
Below are specific, actionable ways to use the paper’s findings now, with notes on sectors, workflows/tools, and feasibility dependencies.
- Stable LLM pretraining via Output Embedding Centering (OEC)
- Sectors: software/AI infrastructure, cloud, enterprise AI labs, academia
- What to do: Replace or complement z-loss with either:
- mu-centering: subtract the mean output embedding from the output embedding matrix after each optimizer step
- mu-loss: add the regularizer λ·μᵀμ with λ≈1e-4
- Value: Reduces training collapses from logit divergence, enables higher learning rates with less tuning, cuts wasted compute and time
- Dependencies/assumptions: Validated on decoder-only LLMs up to 221M parameters, untied output embeddings, AdamW optimizer; generalization to much larger scales, alternative optimizers, or tied embeddings requires verification
- Drop-in integration into training frameworks
- Sectors: software tooling (PyTorch Lightning, HuggingFace Transformers, Megatron-LM, DeepSpeed)
- What to do: Implement OEC as a callback/hook:
- mu-centering: post-optimizer step hook that all-reduces the output-embedding mean across ranks and recenters the matrix
- mu-loss: add a small L2 penalty on the mean embedding vector in the loss function
- Value: Safer defaults than z-loss; near-zero overhead (≈0.2–0.7% vs. baseline), hyperparameter-light (mu-centering: none; mu-loss: λ≈1e-4 works broadly)
- Dependencies/assumptions: Correct handling of distributed/sharded vocabularies and optimizer state; ensure centering order doesn’t corrupt Adam moments
- Reduced hyperparameter search in production training
- Sectors: cloud ML platforms, enterprise AI
- What to do: Use OEC to safely sweep higher learning rates with fewer trials; set default λ for mu-loss to 1e-4 and avoid extensive z-loss tuning
- Value: Lower experimentation cost, faster time-to-model; consistent learning rate sensitivity improvements across sizes in experiments
- Dependencies/assumptions: Benefits most pronounced when output logits previously spiked; confirmation needed under exotic schedulers or non-Adam optimizers
- Training stability monitoring and alerting
- Sectors: MLOps/observability
- What to do: Add new stability signals to dashboards:
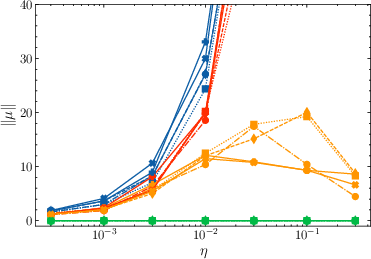
- mean output embedding norm ∥μ∥
- mean logit and max absolute logit
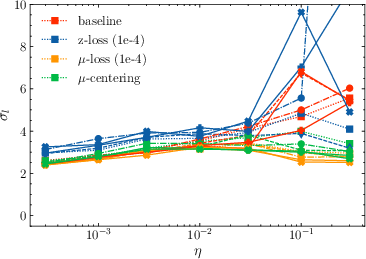
- logits standard deviation
- Value: Early-warning system for divergence; actionable triggers (e.g., auto-enable mu-centering if ∥μ∥ grows)
- Dependencies/assumptions: Requires minor metric collection and logging changes; thresholds may need calibration per model
- Safer mixed-precision training (BF16/FP16)
- Sectors: cloud compute, hardware-software co-design
- What to do: Combine OEC with mixed precision to limit numeric overflow from logit spikes
- Value: Fewer NaNs/overflows; more robust training without resorting to aggressive caps or temperature hacks
- Dependencies/assumptions: Interactions with alternative stabilization tricks (e.g., logit soft-capping) should be tested jointly
- Better defaults for small-scale academic and hobbyist training
- Sectors: academia, education, maker/OSS communities
- What to do: Enable mu-centering by default in teaching repos and small-scale projects
- Value: Reduces frustration from unexpected divergences; improves reproducibility and learning outcomes
- Dependencies/assumptions: Most helpful for decoder LM heads; gains for other heads/tasks likely but not yet extensively validated
- Energy and cost savings via fewer failed runs
- Sectors: energy/sustainability, procurement, finance for AI budgets
- What to do: Adopt OEC in pretraining to reduce aborted runs and retries; include stability as a KPI in training cost dashboards
- Value: Tangible reduction in energy usage and cloud spend; improved carbon reporting
- Dependencies/assumptions: Savings scale with run frequency and model size; organization must track failed-run costs to realize benefits
- Guidance for z-loss users
- Sectors: teams already using z-loss in production
- What to do: If retaining z-loss, re-tune λ; experiments suggest λ≈1e-1 may be more effective than the often-used 1e-4
- Value: Improved stability even without immediate code changes to implement OEC
- Dependencies/assumptions: Still inferior to OEC in stability and sensitivity; test on your data/model before adopting as a rule
- Extending to continued pretraining and supervised fine-tuning
- Sectors: enterprise model adaptation (domain-specific LLMs), OSS
- What to do: Use OEC during continued pretraining and SFT to prevent late-epoch logit blow-ups
- Value: More reliable late-stage runs, especially with aggressive learning-rate schedules
- Dependencies/assumptions: Paper focuses on pretraining; apply cautiously and validate for fine-tuning/RLHF regimes
Long-Term Applications
These opportunities require additional research, scaling experiments, or productization before broad deployment.
- Standardization of OEC in foundation model training stacks
- Sectors: cloud AI providers, major model labs
- What to build: Make OEC a default option in large-scale training orchestration (DeepSpeed/Megatron configs, vendor guides)
- Value: Industry-wide reduction in divergence-related compute waste; safer scaling to higher LRs
- Dependencies/assumptions: Validation at billions–trillions of parameters and across diverse corpora/tokenizers
- Optimizer co-design with centering (e.g., Coupled Adam + OEC)
- Sectors: optimizer research, enterprise AI
- What to build: Combine OEC with optimizers that address embedding shifts (e.g., Coupled Adam) for additive stability
- Value: Further reduces anisotropy-driven failures; may relax other stabilizers (e.g., layernorm tweaks)
- Dependencies/assumptions: Interaction effects with momentum and second-moment estimates must be characterized
- Robustness recipes for multi-modal and non-LLMs
- Sectors: vision-language, speech, code models, robotics
- What to build: Apply OEC (or its analogues) to softmax-based heads in multimodal decoders and sequence models
- Value: Stabilizes training where output logits grow (e.g., joint token vocabularies, ASR decoders)
- Dependencies/assumptions: Requires adaptation for tied embeddings, shared heads, or modality-specific vocabularies
- AutoLR and auto-stability controllers
- Sectors: MLOps/AutoML
- What to build: Controllers that monitor ∥μ∥ and max|logit| to automatically adjust LR, enable centering, or change schedules
- Value: Higher training throughput with fewer human interventions
- Dependencies/assumptions: Needs robust thresholds and policies transferable across architectures and datasets
- Hardware-aware kernels and distributed implementations
- Sectors: systems, compilers, accelerator vendors
- What to build: Efficient distributed reduction of mean output embeddings; fused optimizer+centering kernels
- Value: Makes mu-centering overhead negligible at massive scale
- Dependencies/assumptions: Correctness with tensor/row-wise sharding, partitioned vocabularies, and optimizer state updates
- Policy and sustainability standards for AI training
- Sectors: policy, sustainability, compliance
- What to build: Best-practice guidelines recommending stability mitigations (like OEC) to reduce wasted compute/energy
- Value: Aligns public funding and enterprise procurement with energy-efficiency goals
- Dependencies/assumptions: Requires consensus and evidence from large-scale deployments
- Safer on-device or edge fine-tuning
- Sectors: mobile/edge AI, embedded systems
- What to build: Lightweight OEC variants for constrained devices to avoid instability during local adaptation
- Value: Fewer crashes and better reliability in federated or on-device learning
- Dependencies/assumptions: Needs validation for smaller vocabularies, quantized models, and non-Adam optimizers
- New output-head designs inspired by centering
- Sectors: model architecture research
- What to build: Heads that enforce zero-mean geometry by construction (e.g., parameterizations with built-in centering) or spectrum control
- Value: Eliminates need for post-hoc regularizers; deeper control over logit ranges
- Dependencies/assumptions: Must maintain or improve accuracy while guaranteeing stability
- Benchmarks and reporting standards for logit stability
- Sectors: academia, open-model communities
- What to build: Include metrics such as mean logit, max|logit|, ∥μ∥, and learning-rate sensitivity in model cards and papers
- Value: Comparable, transparent stability evaluations; faster dissemination of effective practices
- Dependencies/assumptions: Community buy-in; tools for consistent measurement
Key Assumptions and Dependencies Across Applications
- Scale and generality: Experiments were run up to 221M parameters on FineWeb with a GPT-2 tokenizer; results need confirmation at larger scales, different datasets, tokenizers, and architectures (e.g., tied embeddings).
- Optimizer dependence: The root-cause analysis implicates Adam’s second moment; benefits may vary with optimizers like Adafactor, Lion, or SGD.
- Head type: The theory and demonstrations focus on decoder LM heads; applicability to other heads (classification, retrieval) is plausible but should be tested.
- Distributed/training system details: Correctness of mu-centering in sharded vocabularies requires cross-rank reductions and careful interaction with optimizer states.
- Interaction with other stabilizers: Methods like logit soft-capping, dynamic temperature (NormSoftMax), or max-z loss may interact—joint tuning/ablation recommended before combined use.
Glossary
- AdamW: An optimizer variant of Adam that decouples weight decay from the gradient update to improve regularization. "optimizer & AdamW \"
- Anisotropic Embeddings: A phenomenon where embedding vectors are unevenly distributed across dimensions, exhibiting directional bias rather than isotropy. "Anisotropic Embeddings"
- Attention Logits: The raw compatibility scores computed in the attention mechanism; extremely large values can cause training instabilities. "e.g. extremely large attention logits"
- BF16: A 16-bit floating-point format (bfloat16) used to reduce memory and improve training speed while maintaining numerical stability. "precision & BF16 \"
- Cosine decay: A learning rate schedule where the rate decays following a cosine curve over training. "learning rate schedule & cosine decay \"
- Cosine regularization: A regularization technique that encourages more isotropic embeddings via cosine-similarity-based penalties. "cosine regularization \cite{gao2019representationdegenerationproblemtraining}"
- Coupled Adam: An optimizer variant proposed to mitigate embedding anisotropy by addressing Adam’s second moment coupling. "suggested Coupled Adam as an optimizer-based mitigation strategy."
- Decoder-only Transformer: A Transformer architecture that uses only the decoder stack, typically for autoregressive language modeling. "We consider decoder-only Transformer models"
- Laplace regularization: A regularization method designed to reduce embedding anisotropy using Laplacian priors or penalties. "Laplace regularization \cite{zhang-etal-2020-revisiting}"
- Language Modeling Head: The final component mapping the model’s last hidden state to logits and token probabilities via a softmax. "the language modeling head is the final component responsible for mapping the final hidden state to a probability distribution over the tokens in the vocabulary."
- Learning Rate Sensitivity (LRS): A metric quantifying how model performance varies with the choice of learning rate. "the dependency of learning rate sensitivity on the model size"
- Logit soft-capping: A technique that enforces bounds on logits by softly constraining them within a fixed numerical range. "enforces bounds via "logit soft-capping" to confine logits within a fixed numerical range."
- Max-z loss: A z-loss variant that penalizes the square of the maximum logit to control extreme logit values. "max-z loss, that penalizes the square of the maximum logit value."
- NormSoftMax: A method that applies dynamic temperature scaling in softmax based on the logit distribution to stabilize training. "NormSoftMax \cite{10189242}, proposes a dynamic temperature scaling in the softmax function based on the distribution of the logits."
- Output Embedding Centering (OEC): A mitigation strategy that centers output embeddings around zero to suppress logit divergence. "we propose output embedding centering (OEC) as a new mitigation strategy"
- Output embeddings: Learned vectors used to compute logits from hidden states in the language modeling head. "The output embeddings e_i can either be learned independently or tied to the input embeddings"
- Output logit divergence: A training instability where logits in the language modeling head grow without bound (often late in training). "output logit divergence."
- qk-layernorm: Applying LayerNorm to the query and key projections in attention to improve stability. "qk-layernorm & yes \"
- RoPE: Rotary Positional Embeddings that encode relative position information through rotations in embedding space. "positional embedding & RoPE \"
- Spectrum control: A regularization approach that constrains the spectrum (eigenvalues) of embedding covariance to reduce anisotropy. "spectrum control \cite{Wang2020ImprovingNL}"
- SwiGLU: A gated activation function combining Swish and GLU, improving performance over ReLU/GELU in Transformers. "we use SwiGLU hidden activations"
- Xavier initialization: A weight initialization scheme that scales by fan-in/out to maintain signal variance through layers. "a non-truncated Xavier weight initialization"
- z-loss: A regularization that penalizes the squared log of the softmax normalizer to control logit magnitudes. "z-loss adds a regularization term of the form"
- μ-centering: A deterministic, hyperparameter-free operation that subtracts the mean output embedding from each output embedding. "This variant, called μ-centering, is illustrated in the center panel of Fig.~\ref{fig:zloss_and_oec}."
- μ-loss: A regularization term penalizing the squared norm of the mean output embedding to approximately enforce centering. "or a regularization method called μ-loss."
Collections
Sign up for free to add this paper to one or more collections.