- The paper proposes extending layer normalization and softmax modifications to manage divergence in Transformer-based LLMs.
- It demonstrates that techniques like QK_norm_cap and QKV_norm enable a 1.5x increase in learning rates without training divergence.
- Experiments on an 830M-parameter model show significant perplexity improvements, validating the effectiveness of the proposed methods.
Improving LLM Training Stability
The paper "Methods of improving LLM training stability" explores strategies to enhance the training stability of LLMs by investigating the divergence issues associated with high learning rates. The authors extend prior work to analyze the magnitude growth in linear layer outputs within Transformer blocks, proposing novel methods to improve LLM training stability. Using a Transformer with 830M parameters, they demonstrate techniques that allow for increased learning rates without divergence, yielding significant perplexity improvements compared to baseline models.
Background and Motivation
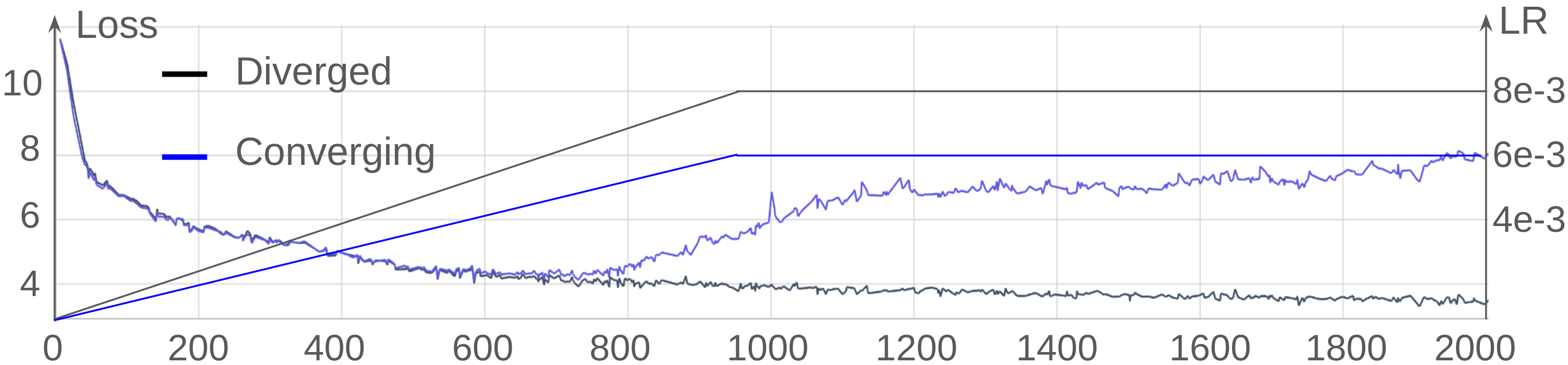
Training LLMs with high stability is challenging due to potential instabilities during optimization. Increasing the learning rate often leads to divergence, primarily due to the growth of logits in attention layers. Prior research effectively uses small scale models to investigate instability mechanisms and apply methodologies like layer normalization (LN) after QK layers to control these issues. The paper extends this by analyzing the entire set of linear layer outputs to identify specific operations causing divergence.
Experimental Observations
The experimental setup replicates the conditions where LLMs diverge by employing a smaller model with an 830M parameter count, leveraging higher learning rates. When observing models trained under these setups, notable increases in the L2 norms of linear layer outputs—especially in QKV, Proj, and FC2 layers—significantly contribute to instability. This phenomenon correlates with divergence due to unintended impacts on softmax behavior, leading to gradient explosion.
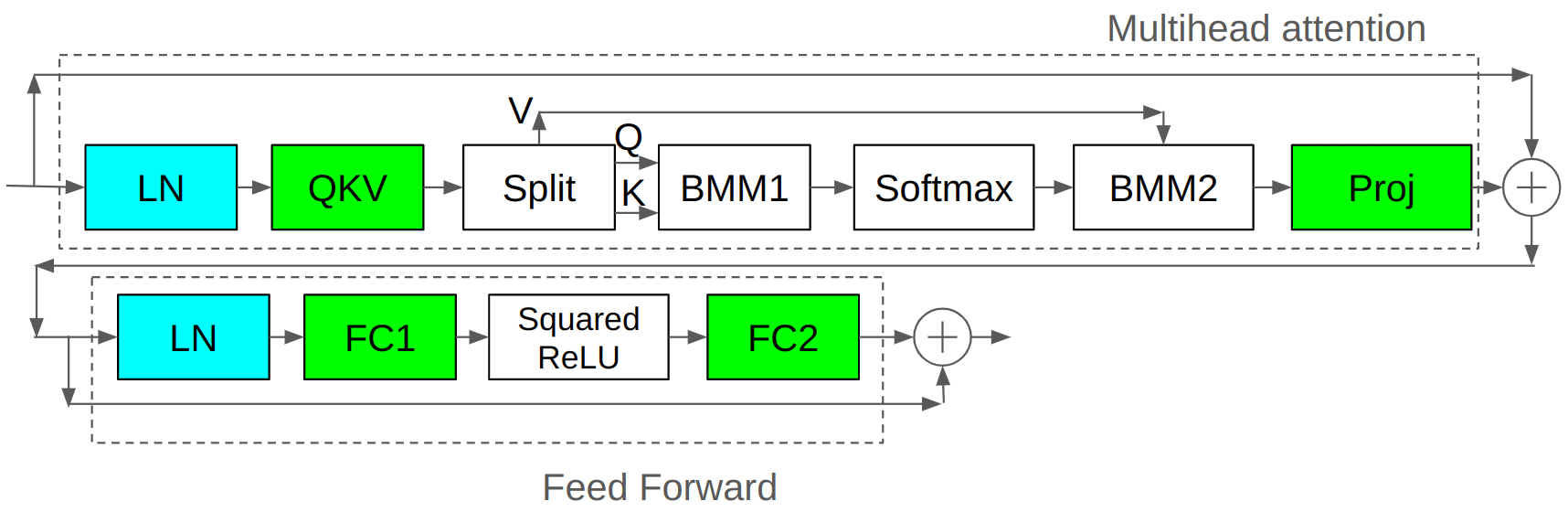
Figure 1: Transformer Block of baseline model.
Proposed Methods
The paper introduces several strategies to mitigate training instability by targeting output magnitude control:
- Layer Normalization Strategies: Extending LN beyond QK layers to Proj and FC2 layers, and modifying its application post-QKV layer to prevent redundancy in normalization steps.
- Softmax-Centric Techniques:
- Softmax Temperature (soft_temp) and Softmax Capping (soft_cap): Adjustments to softmax calculation aimed at temperature control.
- Softmax Clipping (soft_clip): Imposing softmax value limits to deter sensitivity and overtraining.
- Optimized Norm Applications:
Results and Analysis
Increased learning rates were tested across a range of models employing the aforementioned strategies. Specifically, both QK_norm_cap and QKV_norm allowed for a 1.5x increase in learning rates without encountering training divergence, a significant improvement over methods limited to LN application on QK layers alone.
Additionally, practical metrics such as perplexity evidenced substantial improvements with these modified models, highlighting the effectiveness of the normalization and capping strategies in promoting stable, efficient LLM training.
Conclusion
The research presented solidifies the importance of strategic normalization and output magnitude controls in managing LLM training stability. By innovating beyond established LN applications, the authors have demonstrated methods that allow high learning rates without sacrificing model convergence. Future exploration will extend these principles to larger and more complex models, advancing this work's foundational insights into scalable LLM training mechanisms.