Optimal Embedding Learning Rate in LLMs: The Effect of Vocabulary Size
Published 17 Jun 2025 in cs.LG, cs.AI, cs.CL, and stat.ML | (2506.15025v1)
Abstract: Pretraining LLMs is a costly process. To make this process more efficient, several methods have been proposed to optimize model architecture/parametrization and hardware use. On the parametrization side, $\mu P$ (Maximal Update Parametrization) parametrizes model weights and learning rate (LR) in a way that makes hyperparameters (HPs) transferable with width (embedding dimension): HPs can be tuned for a small model and used for larger models without additional tuning. While $\mu$P showed impressive results in practice, recent empirical studies have reported conflicting observations when applied to LLMs. One limitation of the theory behind $\mu$P is the fact that input dimension (vocabulary size in LLMs) is considered fixed when taking the width to infinity. This is unrealistic since vocabulary size is generally much larger than width in practice. In this work, we provide a theoretical analysis of the effect of vocabulary size on training dynamics, and subsequently show that as vocabulary size increases, the training dynamics \emph{interpolate between the $\mu$P regime and another regime that we call Large Vocab (LV) Regime}, where optimal scaling rules are different from those predicted by $\mu$P. Our analysis reveals that in the LV regime, the optimal embedding LR to hidden LR ratio should roughly scale as $\Theta(\sqrt{width})$, surprisingly close to the empirical findings previously reported in the literature, and different from the $\Theta(width)$ ratio predicted by $\mu$P. We conduct several experiments to validate our theory, and pretrain a 1B model from scratch to show the benefit of our suggested scaling rule for the embedding LR.
The paper introduces a theoretical framework revealing that vocabulary size shifts optimal embedding learning rate scaling for LLMs.
It empirically validates that the LV regime, with a Θ(√width) scaling ratio, significantly enhances model performance on test sets.
The findings challenge the conventional μP paradigm, offering practical guidelines for more efficient hyperparameter tuning in LLM training.
Optimal Embedding Learning Rate in LLMs: The Effect of Vocabulary Size
Introduction
The paper investigates the influence of vocabulary size on the training dynamics of LLMs and proposes a novel scaling rule for the embedding learning rate. The current Maximal Update Parametrization (μP) assumes a fixed vocabulary size when scaling model width to infinity, which contradicts the practical scenario where vocabulary size is often larger than the model width. This work provides a theoretical framework showing that training dynamics interpolate between the μP regime and a new Large Vocabulary (LV) regime as vocabulary size increases. The study's findings suggest that the optimal ratio of embedding learning rate to hidden layer learning rate scales as Θ(width), deviating from the Θ(width) suggested by μP.
Theoretical Framework and Contributions
The authors introduce a theoretical framework to analyze the effects of vocabulary size on training dynamics in LLMs. Traditionally, μP provides scaling rules that aim for hyperparameter transferability across different model sizes, ensuring optimal feature learning by maximizing feature updates. This is crucial when dealing with large models, where hyperparameter tuning becomes prohibitively expensive.
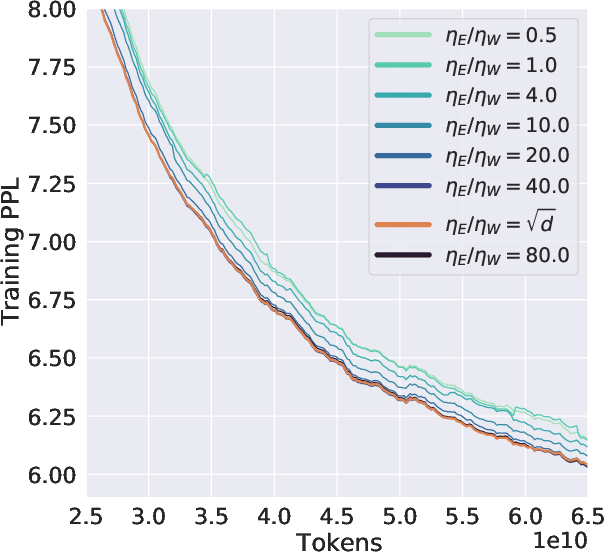
The study's critical insight is that vocabulary size significantly affects the optimal learning rate for embedding layers. Theoretically, as vocabulary size increases, the dynamics shift to a regime with different optimal scaling rules for the learning rates. Specifically, in the LV regime, the optimal embedding learning rate to hidden layer learning rate ratio should scale as Θ(width) instead of the constant behavior expected in μP.
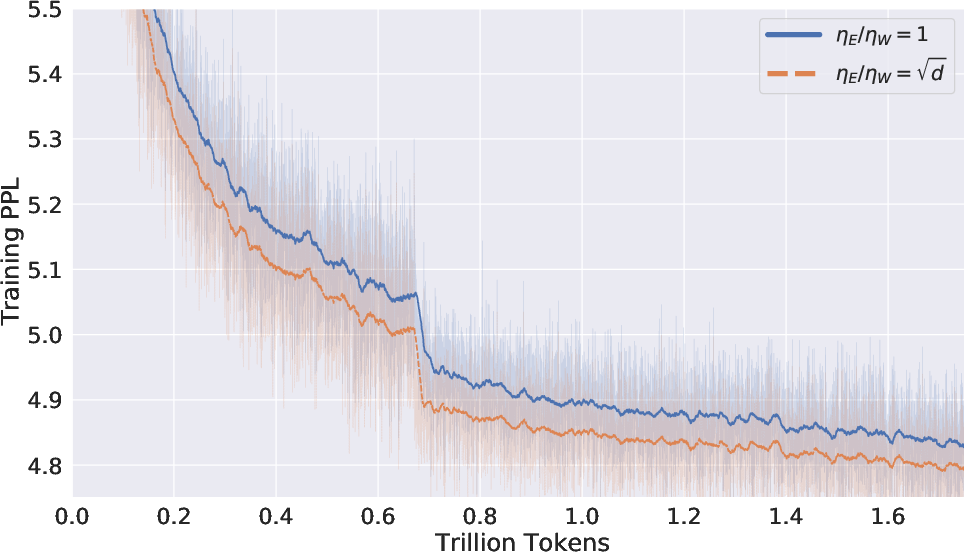
Figure 1: LLM Pre-training Perplexity of 1B Transformer.
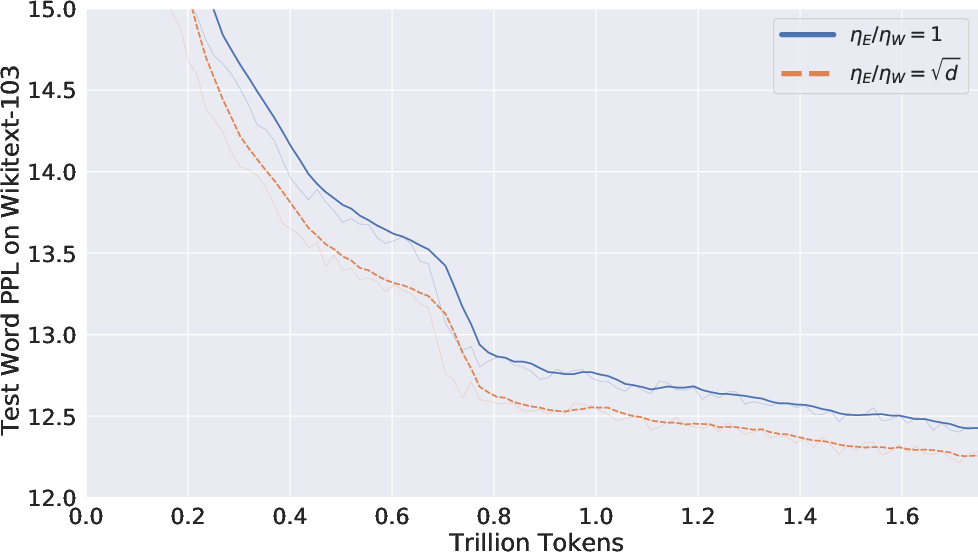
The theoretical analysis is supported by empirical validation where a 1B parameter Transformer model was pretrained from scratch. The experimental results confirm that using the newly proposed scaling rule for the embedding learning rate leads to significant performance improvements, especially on the Wikitext test set.
Figure 2: Perplexity of 1B Transformer on the Wikitext Test Set.
Practical Implications
The insights from this paper have several practical implications. First, the realization that vocabulary size affects the optimal embedding learning rate requires a reconsideration of existing μP rules in scenarios where vocabulary size is substantial. This is particularly relevant for LLMs where vocabulary sizes typically exceed width. By adopting the LV regime's scaling rules, practitioners can achieve more efficient training dynamics, leading to improved performance and faster convergence.
In terms of implementation, modifying existing training setups to accommodate these new scaling rules involves adjusting the learning rate schedules for embedding layers in line with the model width. This change is minor but can have substantial effects on the model’s efficiency and learning capabilities.
Conclusion
This paper's contributions lie in challenging and extending the μP paradigm by incorporating vocabulary size considerations into the scaling rules for LLM training. The research provides both theoretical backing and empirical evidence for a shift in optimal learning rate ratios as vocabulary sizes increase. Practically, this work enables more efficient hyperparameter tuning and model scaling, which are essential for deploying LLMs in real-world applications. The adoption of the LV regime’s insights can lead to more resource-efficient training processes, reducing the computational overhead typically associated with large-scale natural language processing models.