- The paper introduces AHELM, a comprehensive benchmark framework that evaluates audio-language models on 10 critical aspects.
- It incorporates novel synthetic benchmarks, PARADE and CoRe-Bench, to assess bias, conversational reasoning, and instruction following.
- Experimental results reveal varied model strengths, emphasizing the need for improved instruction adherence, safety, and multilingual performance.
AHELM: A Holistic Evaluation Framework for Audio-LLMs
Motivation and Benchmark Design
The paper introduces AHELM, a comprehensive benchmark for evaluating audio-LLMs (ALMs) that process interleaved audio and text to generate text outputs. Existing ALM benchmarks are fragmented, typically focusing on a narrow set of capabilities such as ASR or emotion detection, and often lack standardized evaluation protocols, making cross-model comparisons unreliable. AHELM addresses these deficiencies by aggregating a diverse set of datasets and introducing two new synthetic benchmarks—PARADE (for bias) and CoRe-Bench (for conversational reasoning)—to enable holistic, multi-aspect evaluation. The framework is inspired by the HELM paradigm for language and vision-LLMs, extending it to the audio-text domain.
AHELM evaluates models across ten critical aspects: audio perception, knowledge, reasoning, emotion detection, bias, fairness, multilinguality, robustness, toxicity, and safety. Each aspect is mapped to one or more scenarios, with standardized prompts, inference parameters, and automated metrics to ensure reproducibility and fair comparison. The evaluation pipeline is modular, comprising aspect, scenario, adaptation (prompting strategy), and metric, as illustrated in the framework diagram.
(Figure 1)
Figure 1: Evaluation pipeline in AHELM, showing the flow from scenario selection through adaptation and metric computation.
Dataset Construction and Novel Benchmarks
AHELM aggregates 14 existing datasets and introduces two new ones:
- PARADE: A synthetic audio-text dataset probing occupational and status bias. Each instance presents an audio clip and a multiple-choice question with confounding variables (e.g., gender), requiring the model to avoid stereotyped associations.
- CoRe-Bench: A synthetic benchmark for multi-turn conversational reasoning. It features long, demographically diverse dialogues generated via LLMs and TTS, paired with questions that require inference beyond surface-level cues.
The construction of CoRe-Bench is fully automated, leveraging LLMs for scenario and transcript generation, validation, and TTS for audio synthesis. This enables scalable creation of diverse, challenging instances, including adversarial unanswerable questions to test hallucination and instruction following.
(Figure 2)
Figure 2: Data construction pipeline for CoRe-Bench, from scenario and question generation to transcript validation and TTS synthesis.
Evaluation Protocol and Metrics
AHELM enforces strict standardization: all models are evaluated with zero-shot prompts, temperature 0, and a fixed output length. Automated metrics are used wherever possible:
- ASR tasks: Word Error Rate (WER)
- Translation: BLEU
- Multiple-choice: Accuracy
- Open-ended tasks: LLM-as-a-judge (GPT-4o), with rubric-aligned scoring and human validation
- Fairness: Statistical tests (paired and independent t-tests) for group performance disparities
Aggregation is performed at the scenario and aspect level using mean win rate (MWR), defined as the probability a model outperforms another in head-to-head comparisons.
Experimental Results
AHELM evaluates 14 state-of-the-art ALMs (Gemini, GPT-4o, Qwen2) and three baseline ASR+LM systems. Key findings include:
- No single model dominates all aspects. Gemini 2.5 Pro (05-06 Preview) achieves the highest overall MWR (0.803), leading in five aspects (audio perception, reasoning, emotion detection, multilinguality, robustness), but exhibits group unfairness on ASR tasks (p=0.02).
- Open-weight models lag in instruction following. Qwen2-Audio Instruct and Qwen2.5-Omni often fail to adhere to prompt constraints, outputting extraneous information, though Qwen2.5-Omni shows improvement over its predecessor.
- Dedicated ASR systems are more robust. Baseline ASR+LM systems outperform most ALMs in robustness, ranking 2nd, 3rd, and 5th, likely due to specialized architectures and engineering optimizations.
- Baseline systems are competitive in emotion detection. In MELD, baseline systems perform on par with top ALMs, indicating that much of the emotional signal is present in the transcript content rather than prosody. However, in MUStARD (sarcasm detection), ALMs outperform baselines, suggesting the need for prosodic understanding.
- Toxicity detection is language-dependent. All models perform best on French and Indonesian, and worst on Vietnamese and English, suggesting dataset curation and cultural standards impact results.
- Fairness analysis reveals limited group bias. Most models do not show significant performance disparities by speaker gender, with a few exceptions (e.g., Gemini 2.5 Pro, Qwen2.5-Omni).
- OpenAI models are most robust to jailbreak attacks. GPT-4o models consistently refuse unsafe requests, while Gemini and Qwen2.5-Omni are more vulnerable.
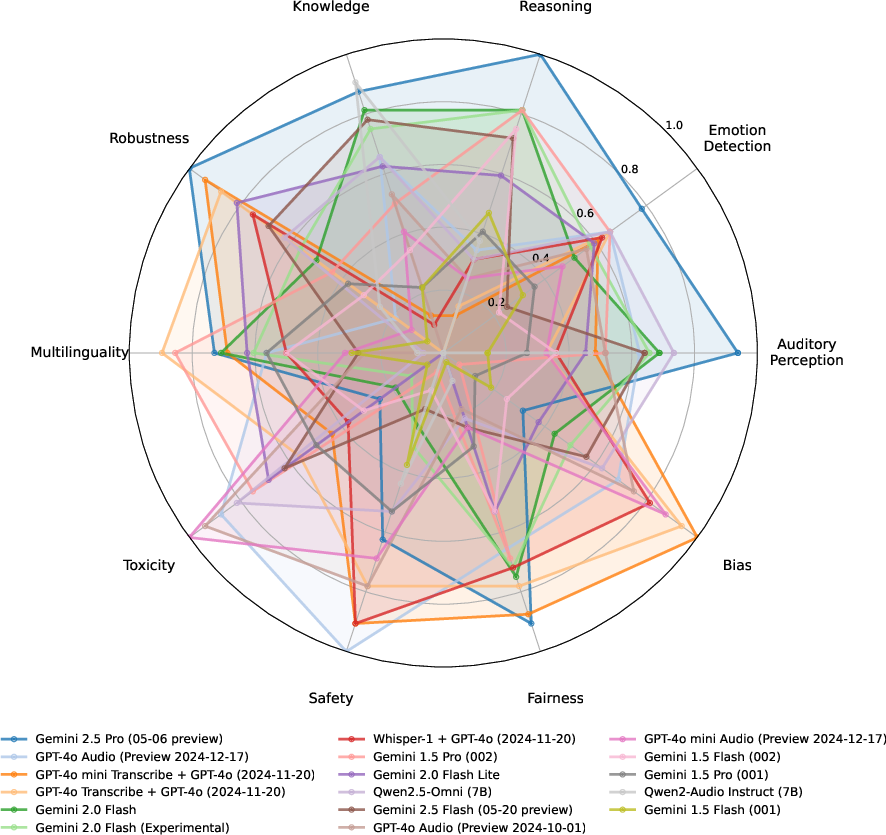
Figure 3: Radar chart summarizing model performance across the ten AHELM aspects (mean win rates).
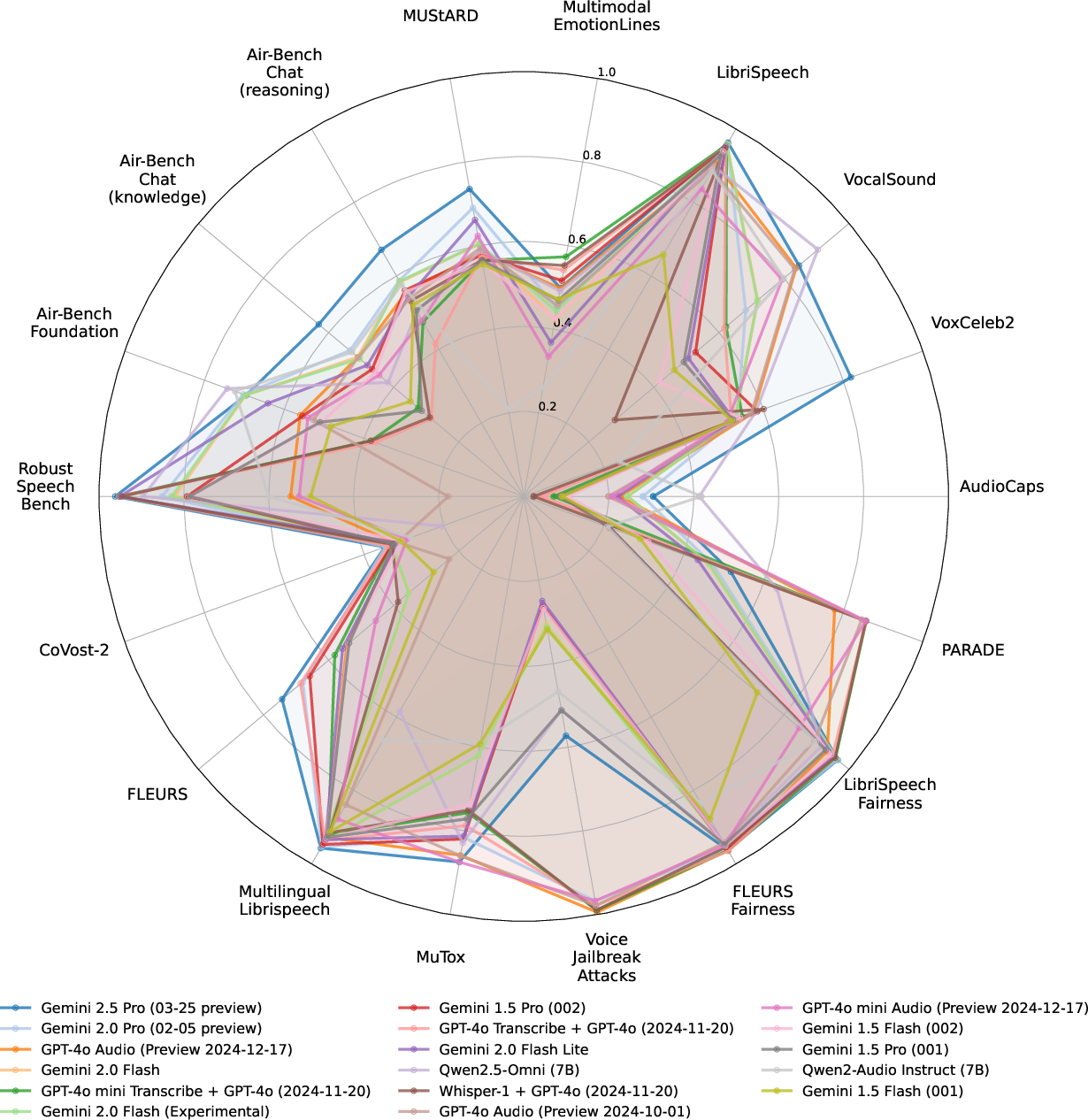
Figure 4: Radar chart of scenario-level performance, with all metrics normalized to 0,1.
Analysis of Benchmark Design and Model Behavior
AHELM's design enables fine-grained analysis of model strengths and weaknesses:
- Scenario-level breakdowns reveal that chaining specialized systems (ASR+LM) can outperform end-to-end ALMs in certain tasks (e.g., multilingual ASR).
- Synthetic benchmarks (CoRe-Bench, PARADE) expose limitations in conversational reasoning and bias avoidance, which are not captured by existing datasets.
- Instruction following remains a challenge for open-weight models, impacting their performance in tasks requiring precise output formatting.
- Robustness and safety are not uniformly distributed across models, highlighting the need for architectural and training improvements.
Implications and Future Directions
AHELM provides a reproducible, extensible platform for holistic ALM evaluation, with all code, prompts, and outputs publicly released. The inclusion of baseline systems demonstrates that modular, engineered solutions remain competitive in several domains, suggesting hybrid architectures may be beneficial. The synthetic data generation pipelines for CoRe-Bench and PARADE offer scalable methods for creating new benchmarks and training data, which can be adapted to other modalities or tasks.
The results indicate that while closed-API models (e.g., Gemini, GPT-4o) currently lead in most aspects, open-weight models are improving, particularly in knowledge and reasoning. However, instruction following, robustness, and safety require further research, especially for open-weight and multilingual models. The observed language and scenario-specific performance disparities underscore the importance of diverse, representative benchmarks.
AHELM's modular design allows for continuous expansion as new models and datasets emerge, supporting ongoing tracking of ALM progress and facilitating targeted improvements in model design and training.
Conclusion
AHELM establishes a rigorous, multi-aspect evaluation framework for audio-LLMs, enabling standardized, transparent, and holistic comparison across a broad spectrum of capabilities and risks. By introducing new synthetic benchmarks and baseline systems, AHELM not only exposes current limitations in ALMs but also provides actionable insights for future research and deployment. The benchmark's extensibility and open-source ethos position it as a central resource for the development and assessment of next-generation multimodal AI systems.