Step-Audio 2 Technical Report (2507.16632v2)
Abstract: This paper presents Step-Audio 2, an end-to-end multi-modal LLM designed for industry-strength audio understanding and speech conversation. By integrating a latent audio encoder and reasoning-centric reinforcement learning (RL), Step-Audio 2 achieves promising performance in automatic speech recognition (ASR) and audio understanding. To facilitate genuine end-to-end speech conversation, Step-Audio 2 incorporates the generation of discrete audio tokens into LLMing, significantly enhancing its responsiveness to paralinguistic information such as speaking styles and emotions. To effectively leverage the rich textual and acoustic knowledge in real-world data, Step-Audio 2 integrates retrieval-augmented generation (RAG) and is able to call external tools such as web search to mitigate hallucination and audio search to switch timbres. Trained on millions of hours of speech and audio data, Step-Audio 2 delivers intelligence and expressiveness across diverse conversational scenarios. Evaluation results demonstrate that Step-Audio 2 achieves state-of-the-art performance on various audio understanding and conversational benchmarks compared to other open-source and commercial solutions. Please visit https://github.com/stepfun-ai/Step-Audio2 for more information.
Summary
- The paper presents a unified end-to-end architecture that integrates audio encoding, LLM decoding, and audio detokenization to generate expressive speech responses.
- It leverages extensive pre-training on 200B tokens, specialized supervised fine-tuning, and reinforcement learning to achieve state-of-the-art ASR and paralinguistic performance.
- The model's innovative tool calling and retrieval-augmented generation enable dynamic timbre and style adaptation, enhancing interactive audio tasks.
Step-Audio 2: An End-to-End Large Audio LLM for Advanced Speech Understanding and Interaction
Introduction
Step-Audio 2 represents a significant advancement in the design and deployment of large audio LLMs (LALMs) for comprehensive speech and audio understanding, as well as naturalistic speech interaction. The model is architected to address the limitations of prior LALMs, particularly in capturing paralinguistic cues, supporting expressive speech generation, and integrating external knowledge sources through tool calling. Step-Audio 2 achieves state-of-the-art results across a broad spectrum of audio-centric tasks, including ASR, paralinguistic understanding, audio comprehension, speech translation, and end-to-end speech conversation, outperforming both open-source and commercial baselines.
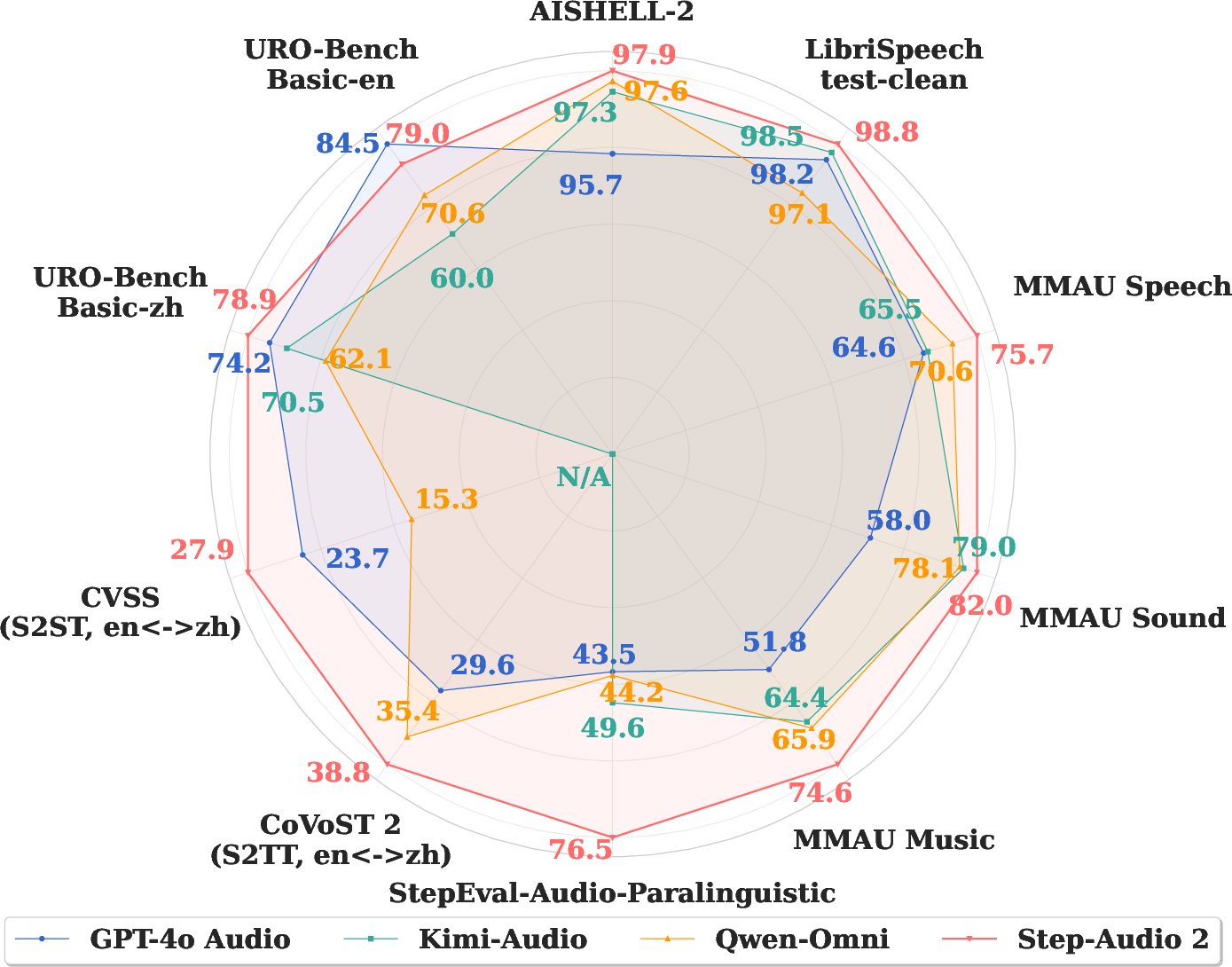
Figure 1: Performance comparison of GPT-4o Audio, Kimi-Audio, Qwen-Omni, and Step-Audio 2 on various benchmarks.
Model Architecture and Methodology
Step-Audio 2 employs a modular yet tightly integrated architecture, consisting of a frozen audio encoder, an audio adaptor, an LLM decoder, and an audio detokenizer. The audio encoder, pretrained on diverse speech and audio tasks, outputs 25 Hz frame-rate features, which are downsampled to 12.5 Hz by the adaptor. The LLM decoder consumes these features and produces interleaved sequences of discrete text and audio tokens, leveraging the CosyVoice 2 tokenizer for audio tokenization. The audio detokenizer, comprising a Flow Matching module and a HiFi-GAN vocoder, reconstructs high-fidelity waveforms from audio tokens, with CNN-based enhancements to improve Mel spectrogram reconstruction and timbre similarity.
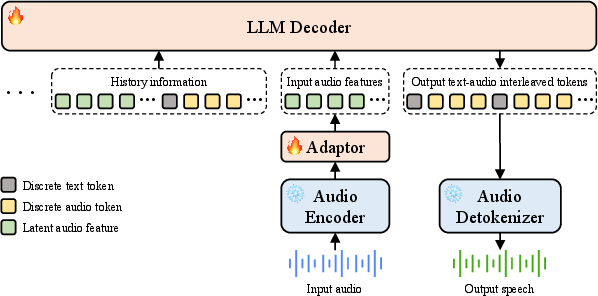
Figure 2: Architecture of the Step-Audio 2.
A key innovation is the integration of audio token generation into the LLMing process, enabling the model to produce expressive, contextually appropriate speech responses. The model supports tool calling, including web search, weather, date/time, and a novel audio search tool that enables timbre and speaking style transfer by retrieving and mimicking speech from a large voice library. Retrieved information is appended to the input features during inference, facilitating multi-modal retrieval-augmented generation (RAG).
Training Pipeline
The training of Step-Audio 2 follows a multi-stage strategy:
- Pre-training: The model is initialized from a textual LLM and continually pre-trained on 1.356T tokens (text and audio) over 21 days. The process includes adaptor alignment with 100B ASR tokens, tokenizer extension with 6.6K audio tokens, and progressive scaling of sequence length and data diversity. The final pre-training stage employs 200B tokens of high-quality, multilingual, and paralinguistic-rich data, with a speaker pool of ~50k for vocal diversity.
- Supervised Fine-Tuning (SFT): Multi-task SFT is performed on 4B tokens, covering ASR, audio event classification, audio captioning, TTS, speech translation, and tool calling. Datasets are reformatted for conversational and paralinguistic coverage, and reasoning-centric datasets are constructed to bootstrap RL.
- Reinforcement Learning: A two-stage PPO regimen is applied, first with binary rewards to optimize reasoning sequence length, then with learned preference scoring for response quality. GRPO is used to further enhance audio perceptual abilities.
Evaluation and Results
Automatic Speech Recognition
Step-Audio 2 achieves an average WER of 3.18% on English and CER of 3.11% on Chinese, outperforming GPT-4o Transcribe, Kimi-Audio, and Qwen-Omni across multiple public and in-house test sets. The model demonstrates robust multilingual performance, with competitive results in Japanese, Cantonese, and Arabic, and superior handling of accented and dialectal Mandarin.
Paralinguistic Information Understanding
On the StepEval-Audio-Paralinguistic benchmark, Step-Audio 2 attains an average accuracy of 76.55%, a substantial margin over all baselines. The model excels in gender, age, timbre, emotion, and speaking style recognition, indicating effective modeling of paralinguistic and environmental cues.
General Audio Understanding
Step-Audio 2 achieves the highest average score (77.4%) on the MMAU benchmark, outperforming Audio Flamingo 3, Gemini 2.5 Pro, and Omni-R1, with best-in-class results on sound and music tracks and competitive performance on speech.
Speech Translation
In both speech-to-text (CoVoST 2) and speech-to-speech (CVSS) translation, Step-Audio 2 delivers the highest BLEU scores for Chinese-English bidirectional tasks, surpassing GPT-4o Audio, Qwen2.5-Omni, and Step-Audio-AQAA.
Tool Calling
Step-Audio 2 is evaluated on the StepEval-Audio-Toolcall benchmark, demonstrating tool invocation, selection, and parameter extraction capabilities on par with strong textual LLMs (Qwen3-32B), and significantly outperforming them in audio search tool accuracy, underscoring its multi-modal specialization.
Speech-to-Speech Conversation
On URO-Bench, Step-Audio 2 achieves the highest average scores in Chinese (78.86 basic, 70.83 pro) and competitive results in English, outperforming GPT-4o Audio, Kimi-Audio, Qwen-Omni, and Step-Audio-AQAA in understanding, reasoning, and oral conversation tracks.
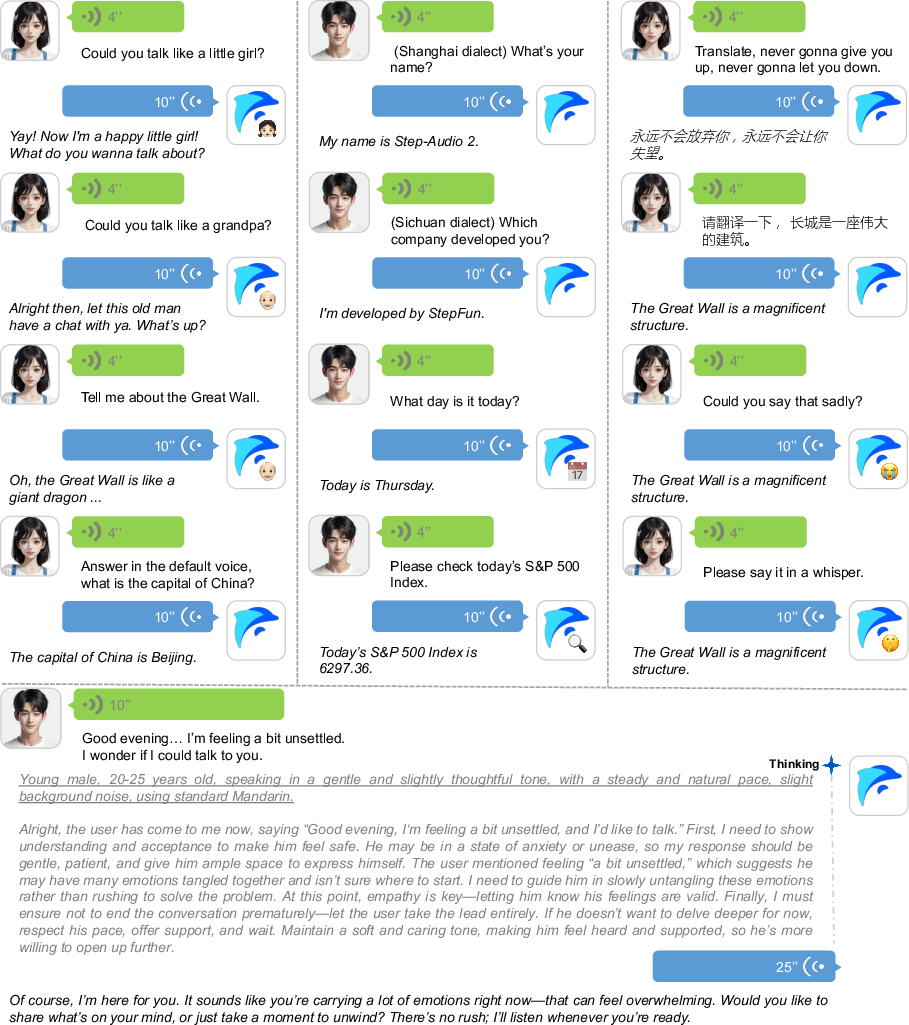
Figure 3: Illustration of the applications of Step-Audio 2 across various speech conversation scenarios.
Practical and Theoretical Implications
Step-Audio 2 demonstrates that end-to-end LALMs can achieve high-fidelity, low-latency, and expressive speech interaction by unifying audio and text token modeling, leveraging large-scale multi-modal pre-training, and integrating external knowledge sources via tool calling. The architecture supports real-time deployment with VAD and streaming, and the audio search tool enables dynamic timbre and style adaptation, which is critical for enterprise and assistive applications.
The model's strong paralinguistic and reasoning capabilities suggest that future LALMs can serve as universal audio agents, capable of nuanced understanding and generation across diverse domains. The integration of RL for reasoning and the use of RAG for grounding responses are likely to become standard in next-generation multi-modal models.
Conclusion
Step-Audio 2 establishes a new benchmark for end-to-end audio LLMing, combining robust audio perception, expressive speech generation, and multi-modal tool integration. Its architecture and training pipeline enable superior performance across a wide range of audio-centric tasks, with strong empirical results in ASR, paralinguistic understanding, audio comprehension, translation, tool calling, and conversational benchmarks. The model's design and results have significant implications for the development of future LALMs, particularly in enterprise, accessibility, and interactive AI systems.
Follow-up Questions
- How does Step-Audio 2 integrate audio tokenization with language modeling to improve speech interaction?
- What are the key architectural innovations that differentiate Step-Audio 2 from previous audio models?
- How do supervised fine-tuning and reinforcement learning contribute to the model's performance across diverse audio tasks?
- What are the practical implications of Step-Audio 2 for real-time speech translation and conversational AI?
- Find recent papers about end-to-end audio language modeling.
Related Papers
- AudioPaLM: A Large Language Model That Can Speak and Listen (2023)
- LLaSM: Large Language and Speech Model (2023)
- AudioGPT: Understanding and Generating Speech, Music, Sound, and Talking Head (2023)
- FunAudioLLM: Voice Understanding and Generation Foundation Models for Natural Interaction Between Humans and LLMs (2024)
- Qwen2-Audio Technical Report (2024)
- Mini-Omni: Language Models Can Hear, Talk While Thinking in Streaming (2024)
- Step-Audio: Unified Understanding and Generation in Intelligent Speech Interaction (2025)
- Kimi-Audio Technical Report (2025)
- VITA-Audio: Fast Interleaved Cross-Modal Token Generation for Efficient Large Speech-Language Model (2025)
- Step-Audio-AQAA: a Fully End-to-End Expressive Large Audio Language Model (2025)
Authors (109)
First 10 authors:
GitHub
- GitHub - stepfun-ai/Step-Audio2 (36 stars)
Tweets
YouTube
alphaXiv
- Step-Audio 2 Technical Report (40 likes, 0 questions)