- The paper introduces VoiceAssistant-Eval, a benchmark with 10,497 QA items across listening, speaking, and viewing tasks.
- It employs triadic evaluation metrics combining content quality, speech naturalness, and text-speech consistency, validated against human judgments.
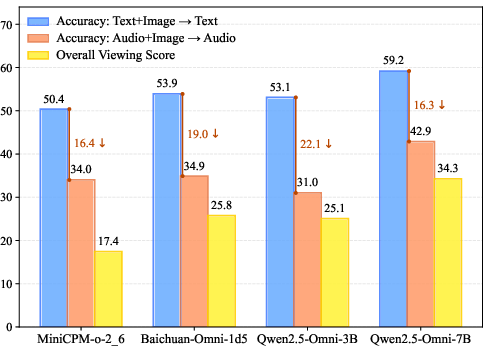
- The analysis reveals that mid-sized, specialized models can outperform larger ones, though challenges persist in audio-visual integration and safety alignment.
Comprehensive Benchmarking of Voice-First AI Assistants: The VoiceAssistant-Eval Framework
Motivation and Benchmark Design
VoiceAssistant-Eval addresses critical gaps in the evaluation of multimodal AI assistants, specifically those designed for voice-first interaction. Existing benchmarks are limited by their focus on text-based instructions, lack of voice personalization, insufficient coverage of real-world audio contexts, and inadequate assessment of multimodal (audio+vision) integration. VoiceAssistant-Eval introduces a large-scale, rigorously curated benchmark comprising 10,497 QA items across 13 task categories, spanning listening (audio, speech, music), speaking (dialogue, role-play, emotion, safety), and viewing (image-based reasoning with audio/text queries).
The benchmark is constructed from 47 diverse datasets, with careful attention to data quality, balance, and scenario realism. Speech instructions are synthesized using advanced TTS models (F5TTS, ChatTTS, Dia-1.6B), and only high-fidelity audio (UTMOS > 3.8, minimal WER via Whisper) is retained. The benchmark explicitly tests four previously underexplored capabilities: personalized voice imitation, hands-free audio interaction, multimodal audio-visual reasoning, and audio QA under complex contexts.
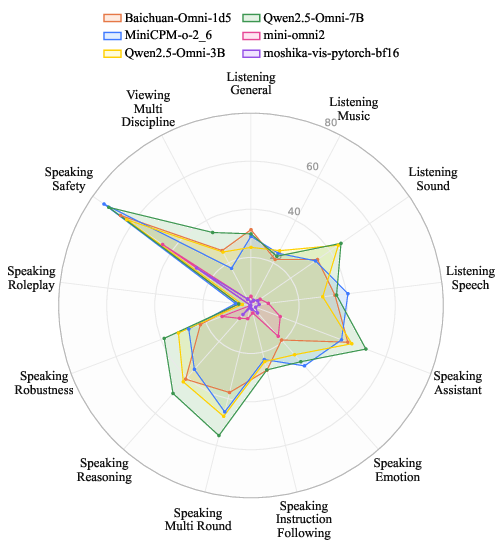
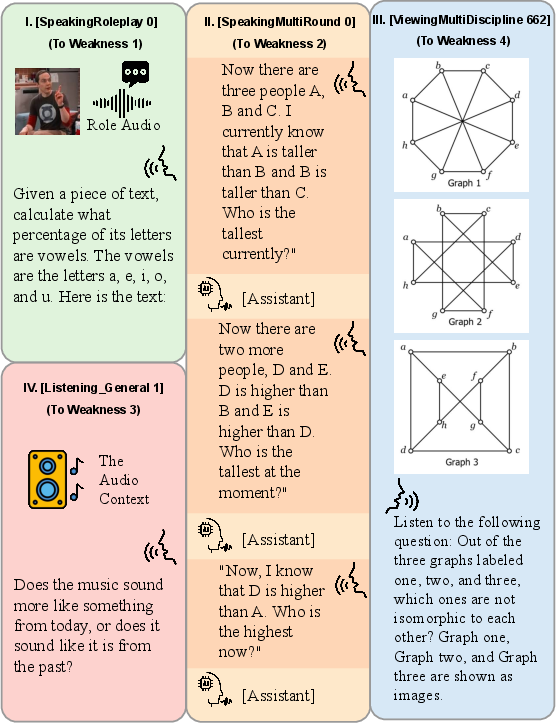
Figure 1: (a) Scores of six prominent omni-models across 13 tasks. (b) Examples from three newly designed tasks for voice assistants: I. Role-play with reference audio; II. Voice-based multi-turn conversation; III. Vision+audio integration; IV. Audio question with music context.
Evaluation Protocols and Metrics
VoiceAssistant-Eval employs a triadic evaluation system, scoring model outputs on content quality (via gpt-oss-20b with task-specific prompts), speech quality (UTMOS), and text-speech consistency (modified WER). For role-play, speaker similarity is measured using Wespeaker embeddings. The final task score is the product of these metrics, normalized to percentage accuracy. This protocol enables integrated, modality-aware assessment, in contrast to prior benchmarks that report metrics independently.
Automated evaluation is validated against human judgments, with Pearson correlations exceeding 0.9 and agreement rates above 96% across all tasks, confirming reliability. Stability analysis over repeated runs yields narrow IQRs and low variance, demonstrating reproducibility.

Figure 2: Stability of automated evaluation across repeated runs. Boxplots show Qwen2.5-Omni-7B’s scores for each task over ten runs; narrow IQRs confirm repeatability.
Twenty-one open-source models and GPT-4o-Audio are evaluated. Key findings include:
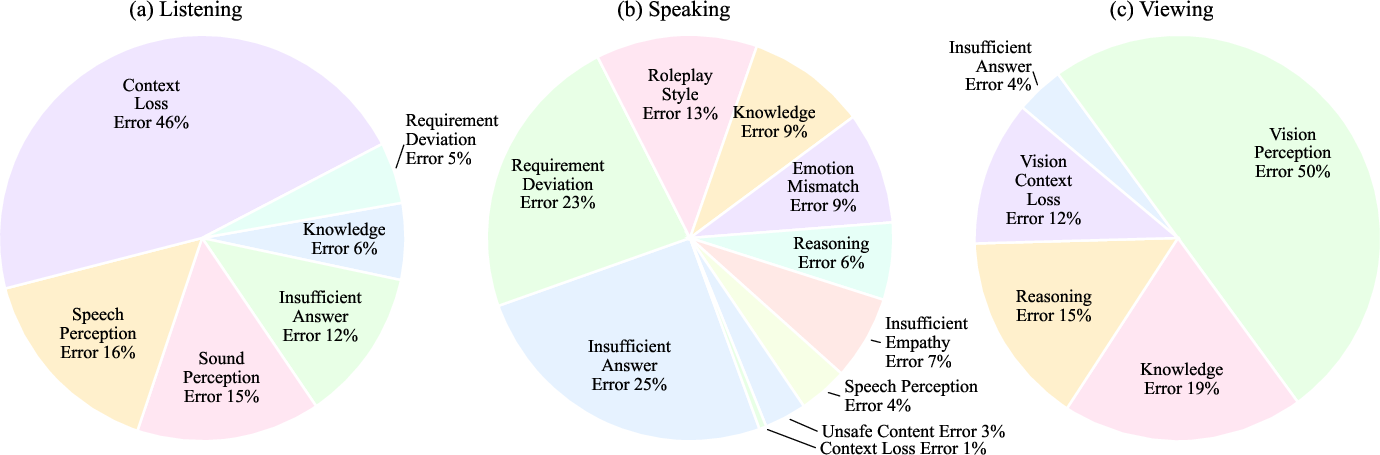
Error Analysis and Model Limitations
A detailed error analysis of Qwen2.5-Omni-7B reveals:
Implications and Future Directions
VoiceAssistant-Eval establishes a rigorous, reproducible framework for benchmarking voice-first AI assistants. The results demonstrate that current models are proficient in speech generation and simple dialogue but lag in audio understanding and multimodal reasoning. The strong performance of mid-sized, specialized models suggests that architectural and data-centric improvements can yield substantial gains without scaling parameter count.
Persistent weaknesses in audio-visual integration, role-play fidelity, and safety alignment highlight the need for:
- Enhanced audio encoders and memory mechanisms for robust listening.
- Integrated multimodal training to bridge the gap between spoken and written queries in visual reasoning.
- Refined alignment and robustness protocols to ensure safe, reliable deployment in real-world scenarios.
The benchmark’s comprehensive coverage and validated metrics provide a foundation for transparent, longitudinal assessment of progress in voice-enabled AI. Future work should expand linguistic diversity, task realism (e.g., streaming, interactive evaluation), and coverage of dynamic scenarios (e.g., video-audio integration).
Conclusion
VoiceAssistant-Eval delivers a comprehensive, modality-integrated benchmark for evaluating AI assistants across listening, speaking, and viewing. The analysis reveals that while current models excel in speech generation and basic dialogue, they are limited in audio understanding and multimodal integration. The benchmark’s findings inform the design of next-generation assistants, emphasizing the importance of balanced development across modalities, targeted model specialization, and robust safety alignment. VoiceAssistant-Eval will serve as a critical resource for tracking and accelerating progress toward truly expert, voice-first AI systems.