- The paper introduces MiMo-Audio, a model that leverages massive-scale lossless pretraining to induce emergent few-shot learning in audio tasks.
- It employs a novel tokenizer and patch-based architecture to preserve full acoustic fidelity while managing high token rates efficiently.
- Extensive evaluations show superior performance and modality-invariant reasoning on speech benchmarks, setting a new standard in audio modeling.
MiMo-Audio: Unifying General-Purpose Audio Language Modeling via Large-Scale, Lossless Compression and Few-Shot Learning
Introduction and Motivation
MiMo-Audio introduces a paradigm shift in audio language modeling by empirically substantiating that scaling next-token prediction pretraining to massive amounts of lossless audio enables strong generalization and emergent few-shot learning capabilities across diverse speech and audio tasks. The work draws explicit inspiration from GPT-3’s text modeling success, arguing that similar generative modeling principles can induce generalized, versatile speech intelligence without extensive task-specific adaptation.
Existing speech-LLMs are encumbered by losses in paralinguistic information due to suboptimal tokenization and are typically limited to downstream tasks via fine-tuning. MiMo-Audio departs from this, positing two critical preconditions for generalization: an architecture facilitating lossless flow of speech information and aggressive scaling of training corpus volume. The system employs >100 million hours of diverse, in-the-wild audio data—an order of magnitude larger than previous open-source speech models—to induce spontaneous emergent few-shot capabilities transcending standard benchmark metrics, as demonstrated via systematic evaluation.
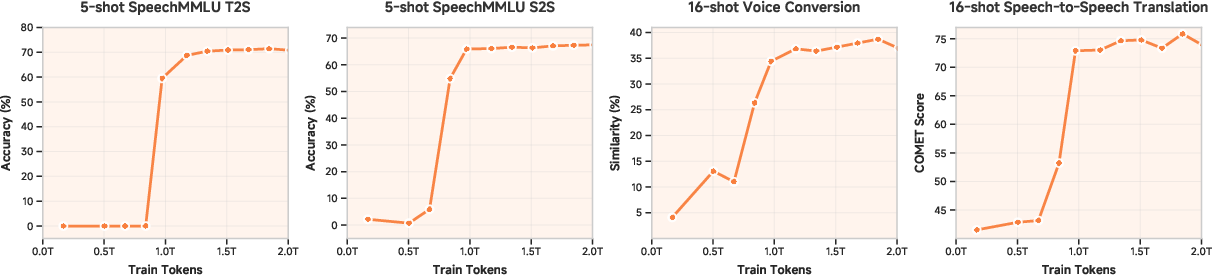
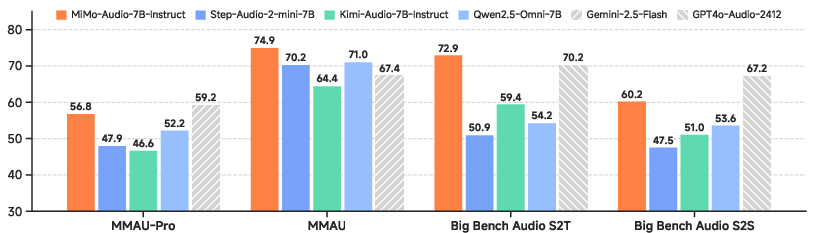
Figure 1: Emergent behavior in pretraining and performance comparison with SOTA models, including the phase transition in generalization capacity induced by massive-scale training.
Unified High-Fidelity Audio Tokenization
MiMo-Audio-Tokenizer constitutes the first core component. It advances prior approaches by jointly optimizing semantic and reconstruction objectives using a 1.2B parameter Transformer encoder–decoder architecture augmented with an 8-layer RVQ discretizer (200 tokens/sec, 25Hz frame rate). Notably, unified training from scratch on a 10M-hour audio corpus, combined with architectural innovations (layerwise feature addition, bidirectional attention, RoPE), facilitate fine-grained cross-modal alignment and preserve full acoustic fidelity.
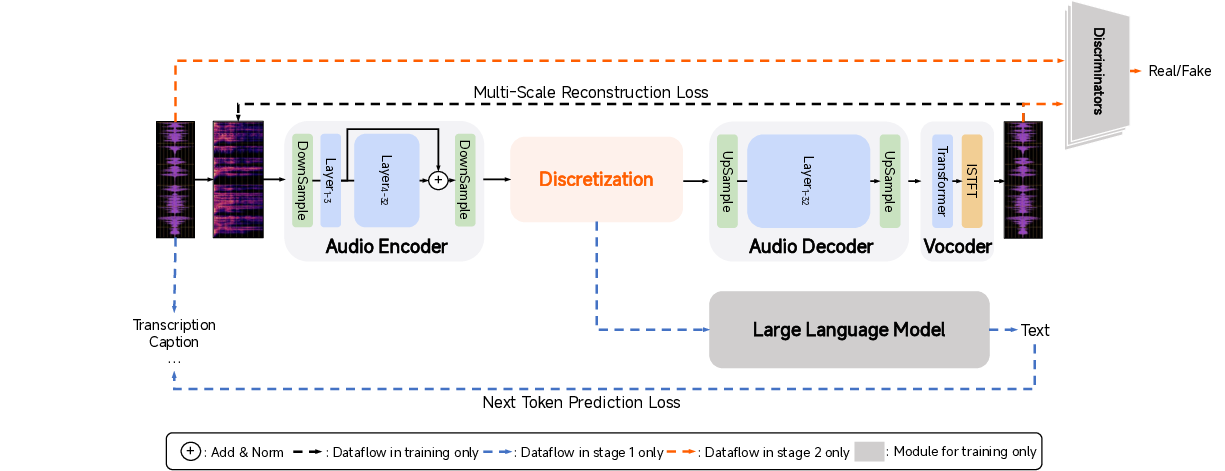
Figure 2: The MiMo-Audio-Tokenizer framework, showing unified semantic and acoustic tokenization enabling lossless cross-modal modeling.
Rigorous evaluation on Seed-TTS-Eval shows that MiMo-Audio-Tokenizer achieves top scores across all speech intelligibility and perceptual metrics (PESQ-NB/WB, SIM, STOI) among open-source tokenizers, measured exactly on the codebooks used downstream. These results validate that lossless tokenization is a precondition for generality in subsequent audio language modeling.
Architecture: Patch-Based Audio-Text Modeling
MiMo-Audio leverages an integrated architecture comprising a patch encoder, a LLM backbone (MiMo-7B-Base), and a patch decoder. To mitigate the token-rate mismatch between speech (high-frequency, low information density) and text (low-frequency, high density), audio tokens are downsampled and grouped into patches, enabling efficient sequence modeling and cross-modal knowledge transfer.
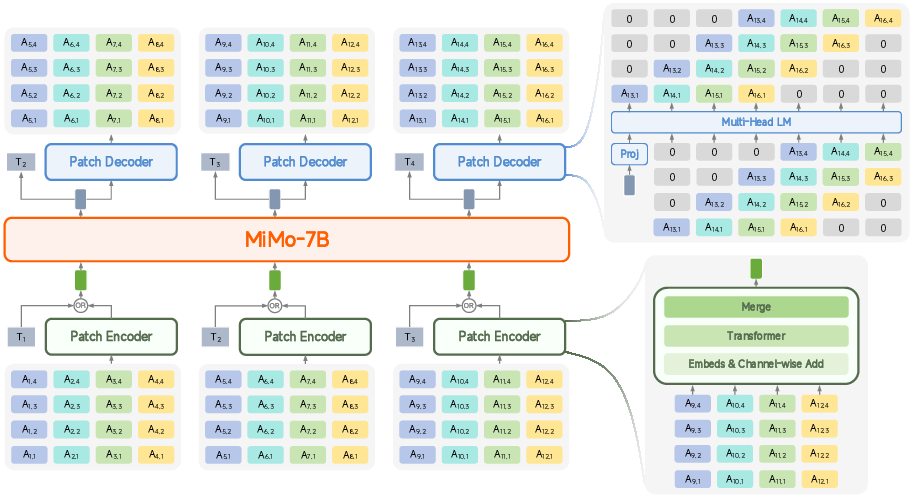
Figure 3: Model architecture of MiMo-Audio, including patch encoder aggregation, LLM backbone, and autoregressive patch decoder for high-fidelity speech generation.
Key architectural details include:
- Patch encoder aggregates RVQ audio tokens for each frame, transforms them via Transformer layers (bidirectional self-attention), and projects to LLM input dimensionality.
- LLM backbone (MiMo-7B-Base) interleaves text and audio patch representations, enabling seamless modeling of arbitrary text-audio sequences.
- Patch decoder autoregressively generates audio patches using delayed token generation mechanisms inspired by contemporary music modeling, preserving inter-frame dependencies and audio fidelity.
Massive-Scale Pretraining Methodology
The report outlines a carefully constructed pretraining dataset of >100 million hours, drawn from podcasts, audiobooks, news, and other heterogeneous sources, and annotated for both semantic and non-semantic factors (content, emotion, environmental descriptors). Data curation optimizes both diversity and fidelity, with automated pipelines for normalization, speaker diarization, VAD, open-source ASR, and audio captioning. This previously unprecedented scale is identified as the critical parameter for inducing emergent generalization phenomena.
Training proceeds in two stages: Stage 1 focuses on speech understanding via text loss; Stage 2 integrates speech understanding and generation, employing a text-guided interleaving strategy and joint optimization across modalities. This progressive, phased approach is shown to trigger non-linear "phase transition" emergence of in-context learning capabilities.
Few-Shot Generalization and Task Results
MiMo-Audio's capabilities are demonstrated via extensive few-shot evaluation, following GPT-3 protocols, across three axes: modality-invariant general knowledge (SpeechMMLU), auditory comprehension and reasoning (MMAU), and speech-to-speech tasks (voice conversion, emotion/rate conversion, denoising, translation).
On SpeechMMLU, MiMo-Audio-7B-Base achieves the highest scores among open-source models: S2S: 69.1, S2T: 69.5, T2S: 71.5, with minimal modality gap (3.4 points), indicating preservation of core reasoning abilities across input/output modalities. For MMAU, MiMo-Audio delivers balanced general audio understanding (overall: 66.0), outperforming Step-Audio2-mini by 5.7 points.
Critically, Figure 1 illustrates the emergent phase change in few-shot capabilities: performance remains negligible until surpassing a critical threshold of training data, then undergoes a sharp, non-linear surge and subsequent stabilization—a hallmark of emergent generality.
MiMo-Audio further demonstrates speech continuation abilities across scenarios such as live streaming, debates, singing, and recitation with high semantic, prosodic, and acoustic consistency; qualitative demos confirm the model’s capacity for expressive, context-sensitive generation without adaptation.
Post-Training: Instruction-Tuning and Multimodal Interaction
Post-training aligns generalization capabilities with instruction-following and reasoning via a diverse, curated corpus. Inclusion of chain-of-thought data augments the model’s cross-modal reasoning, and integration with MiMo-TTS synthesizes human-like, style-controllable dialogue data. MiMo-Audio-7B-Instruct achieves SOTA or near-SOTA performance on MMSU, MMAU, MMAR, MMAU-Pro, Big Bench Audio, Multi-Challenge Audio, and instruct-TTS evaluations, approaching closed-source models such as GPT-4o and Gemini.
Implications, Limitations, and Future Directions
MiMo-Audio empirically demonstrates that sufficiently large-scale, lossless generative modeling of speech induces a "GPT-3 moment" in audio language modeling: strong few-shot generalization, modality-invariant knowledge, and comprehensive speech intelligence are achievable without task-specific fine-tuning.
However, the model exhibits limitations: residual instability in spoken dialogue (e.g., timbre discontinuity, mispronunciations, style control), suboptimal in-context scores on non-speech audio events, and deleterious performance shifts in music/sound reasoning tasks when chain-of-thought reasoning is enabled. Future work will emphasize reinforcement learning-based stabilization, expanded general audio generation capabilities, and mechanisms to address hallucinations induced by cognitive modeling.
Conclusion
MiMo-Audio advances the state-of-the-art in speech and audio language modeling by establishing that massive-scale, lossless next-token prediction pretraining suffices for general-purpose, few-shot learning across a broad audio task spectrum. Through innovations in tokenizer design, scalable architecture, and rigorous systematic evaluation, this work functions as a blueprint for open, versatile audio models approaching human-level adaptability and sets experimental signatures for subsequent research directions in audio-centric AGI systems.