ORION: Option-Regularized Deep Reinforcement Learning for Cooperative Multi-Agent Online Navigation
Abstract: Existing methods for multi-agent navigation typically assume fully known environments, offering limited support for partially known scenarios such as warehouses or factory floors. There, agents may need to plan trajectories that balance their own path optimality with their ability to collect and share information about the environment that can help their teammates reach their own goals. To these ends, we propose ORION, a novel deep reinforcement learning framework for cooperative multi-agent online navigation in partially known environments. Starting from an imperfect prior map, ORION trains agents to make decentralized decisions, coordinate to reach their individual targets, and actively reduce map uncertainty by sharing online observations in a closed perception-action loop. We first design a shared graph encoder that fuses prior map with online perception into a unified representation, providing robust state embeddings under dynamic map discrepancies. At the core of ORION is an option-critic framework that learns to reason about a set of high-level cooperative modes that translate into sequences of low-level actions, allowing agents to switch between individual navigation and team-level exploration adaptively. We further introduce a dual-stage cooperation strategy that enables agents to assist teammates under map uncertainty, thereby reducing the overall makespan. Across extensive maze-like maps and large-scale warehouse environments, our simulation results show that ORION achieves high-quality, real-time decentralized cooperation over varying team sizes, outperforming state-of-the-art classical and learning-based baselines. Finally, we validate ORION on physical robot teams, demonstrating its robustness and practicality for real-world cooperative navigation.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A simple explanation of “ORION: Option-Regularized Deep Reinforcement Learning for Cooperative Multi-Agent Online Navigation”
Overview
This paper is about teaching a team of robots to move through places like warehouses where the map is not fully correct or up to date. Each robot has its own destination, but the team does best when robots also help each other by finding and sharing new information about the map. The authors introduce ORION, an AI method that helps robots decide when to go straight to their own goals and when to explore and share map updates that make the whole team faster. The main success measure is the time until the last robot finishes (this is called the “makespan”).
Key objectives
Here are the main questions the paper tries to answer:
- How can robots navigate well when the map they start with is partly wrong or outdated?
- How can each robot decide, on its own, when to focus on its own path versus when to help teammates by exploring and sharing information?
- How can the team share what they see and use it to reduce confusion about the map in real time?
- Can this work quickly and reliably in big, complex spaces and on real robots?
How ORION works (in everyday terms)
Think of a group of friends trying to find their way through a constantly changing maze using old printed maps and walkie-talkies. ORION gives them a smart way to combine what the old map says with what they are seeing right now, and to switch between two “modes”: going straight to their own goal or detouring to help others.
To do this, ORION combines a few ideas:
- Mixing old maps with live observations
- Robots start with a “prior map” (what they believe the layout is) that might be wrong in places.
- As they move, their sensors discover what’s actually there (the “current map”).
- ORION fuses these two into a single, smarter view, sort of like superimposing your old map with a transparent layer of what you’re currently seeing, and weighting the reliable parts more.
- Seeing the world as a graph
- Instead of thinking in every possible direction, robots use a network of dots (safe positions) connected by lines (safe moves). This “graph” is simpler to plan on.
- The system marks which spots are explored, who has been there, where there might be helpful “frontiers” (edges of unknown areas), and where goals lie.
- Two high-level modes (the “options”)
- Mode 1: Self-navigation — head toward your own goal efficiently.
- Mode 2: Cooperation — explore uncertain areas or collect information to help teammates.
- ORION learns when to stay in a mode and when to switch. You can think of it like having an inner coach that says, “Keep going to your goal,” or “Now is a good time to scout for the team.”
- A simple rule for before and after you arrive
- Before arriving at your own goal, you mostly go there but may take small helpful detours if it benefits the team.
- After arriving, instead of just waiting, you might briefly go explore nearby unknown spots to help others, then return. This prevents wasted time when some robots are idle but others are stuck.
- Learning to make good decisions over time
- The system is trained in simulation using reinforcement learning (learning by trial and error).
- During training, a special “critic” has access to the full, correct map (only during training, not during real use) to help judge which choices lead to better team results.
- After training, each robot makes fast, independent decisions based on what it knows and what the team has shared—no single boss robot is needed (this is called decentralized control).
- Safety and coordination
- Robots avoid bumping into each other by not entering the same spot at the same time or crossing the same path in opposite directions.
Main findings and why they matter
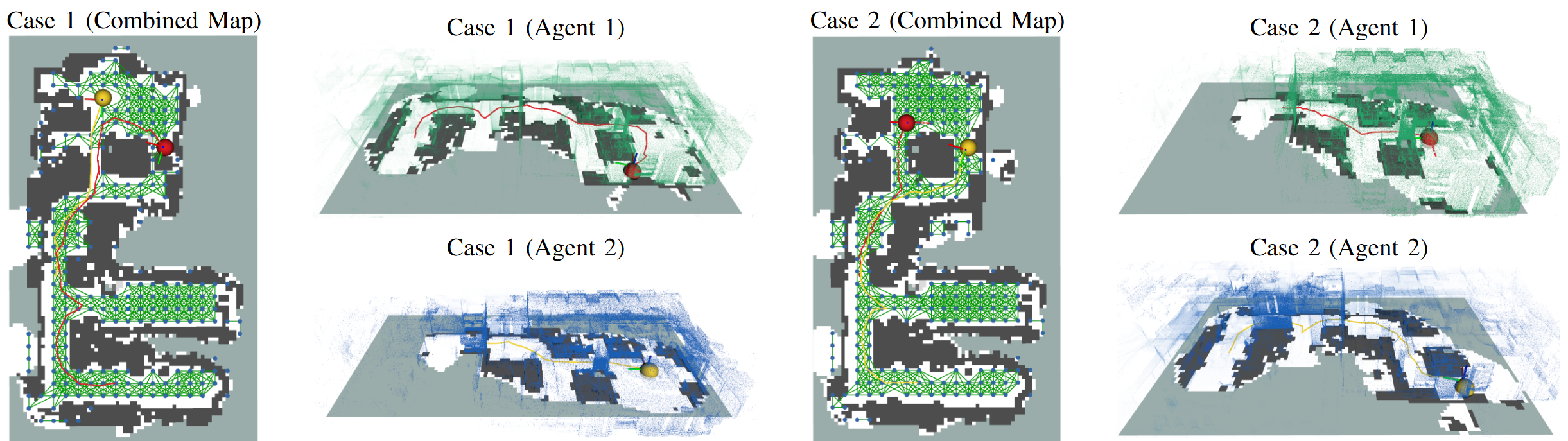
Across many tests—simulated mazes, a large warehouse simulator, and real robots—ORION showed clear benefits:
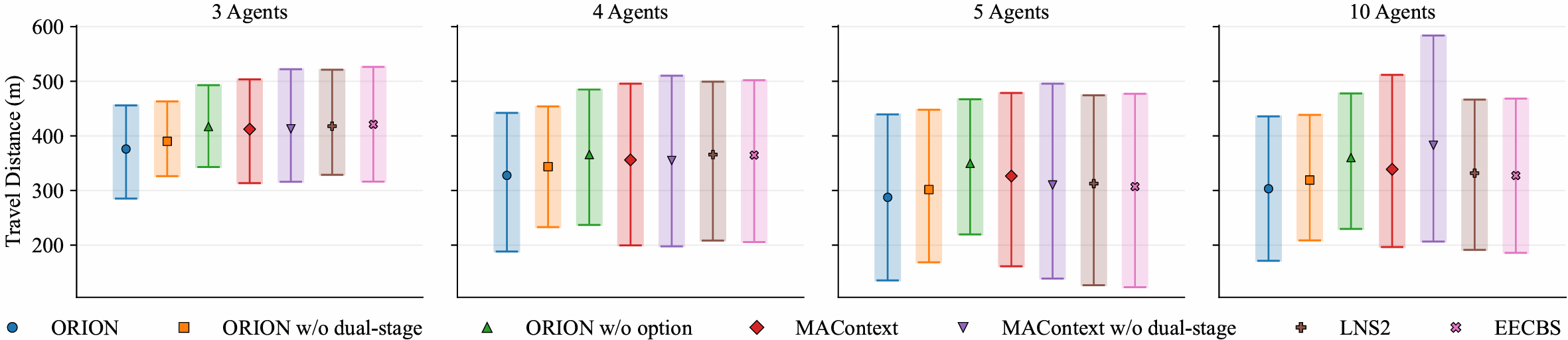
- Faster team completion (lower makespan)
- In large simulated maps with 3–10 robots, ORION reduced the time for the last robot to finish by about 7% to 13% compared to strong planning methods, and up to about 20% compared to some learning baselines.
- Letting robots help after they reach their goals (the “dual-stage cooperation”) brought up to about 14% extra improvement.
- Smarter teamwork
- Robots that finish early don’t just sit; they explore helpful spots and share what they find.
- Help is targeted: it often focuses on the teammate who is slowed down the most by wrong or missing map details.
- Real-time performance
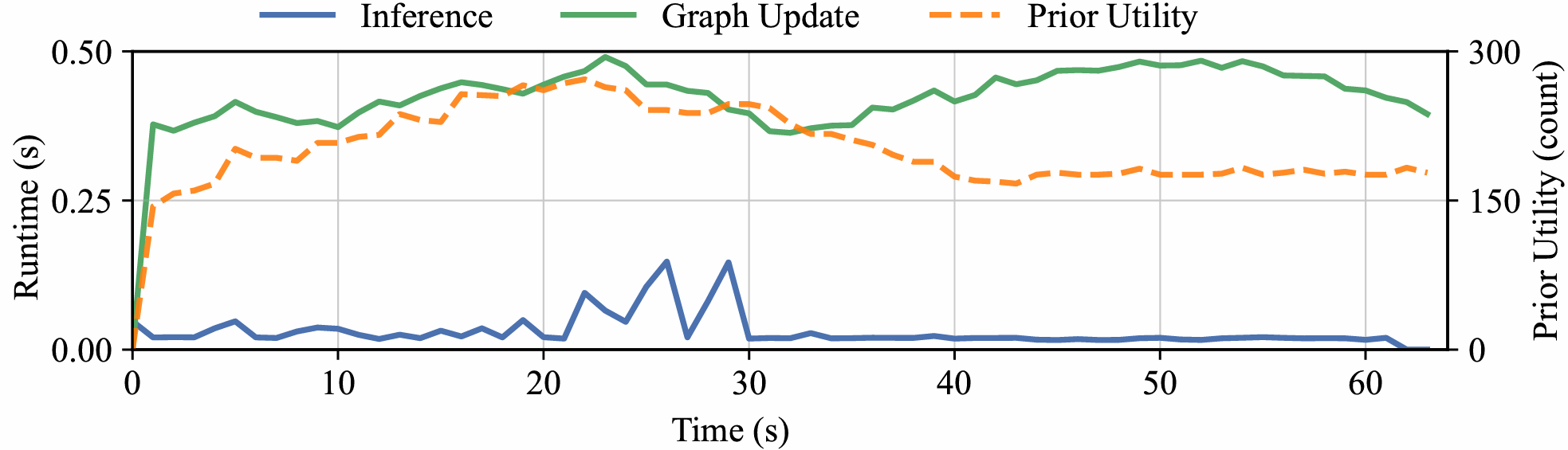
- ORION runs fast enough for real use: decisions typically take under 0.2 seconds in the warehouse simulator.
- It also worked on real robots in an office, without extra fine-tuning, showing that the method is practical outside simulation.
These results matter because warehouses and factories often change their layouts. A method that adapts on the fly and turns “idle time” into helpful scouting makes the whole team more reliable and efficient.
Implications and potential impact
If robots can smoothly switch between “get to my goal” and “help the team” while constantly fixing the map, they can:
- Work better in places that change often (like warehouses with rearranged shelves).
- Finish jobs faster as a group, not just as individuals.
- Scale to larger teams without getting in each other’s way.
- Transfer from simulation to the real world with little extra effort.
A current limitation is that ORION assumes robots can share what they see without communication problems. A next step is to handle limited or unreliable communication, so teams can still coordinate well even with spotty connections.
Overall, ORION shows a practical path toward smarter, cooperative robot teams that learn when to prioritize themselves and when to pitch in—leading to faster, safer, and more efficient operations in the real world.
Knowledge Gaps
Unresolved Knowledge Gaps, Limitations, and Open Questions
Below is a single, consolidated list of gaps and open questions that remain after this work. Each item is phrased to suggest concrete directions future researchers could pursue.
- Communication constraints: The method assumes perfect, reliable, global communication for map sharing. How does ORION perform under limited bandwidth, latency, packet loss, or intermittent connectivity, and what communication policies (e.g., adaptive compression, prioritized messages, event-triggered sharing) best preserve makespan improvements?
- Localization and map alignment: Real-world multi-robot deployments require consistent pose alignment and distributed SLAM. How robust is ORION to localization drift, map-frame misalignment, loop-closure delays, or inconsistent team beliefs, and can belief-aware policies explicitly reason about and correct map fusion errors?
- Sensor noise and perception uncertainty: The current map is treated as “reliable” online observations; robustness to false positives/negatives, occlusions, or degraded sensing (e.g., dust, reflective surfaces) is not evaluated. How should uncertainty be modeled and propagated (e.g., via probabilistic occupancy, entropy) within the encoders and decision layers?
- Privileged critic during training: The centralized critic uses ground-truth maps (privileged information). What is the empirical and theoretical impact on actor behavior when this privilege is removed or approximated, and can value estimation be stabilized without ground-truth access (e.g., via uncertainty-aware critics or constrained policy learning)?
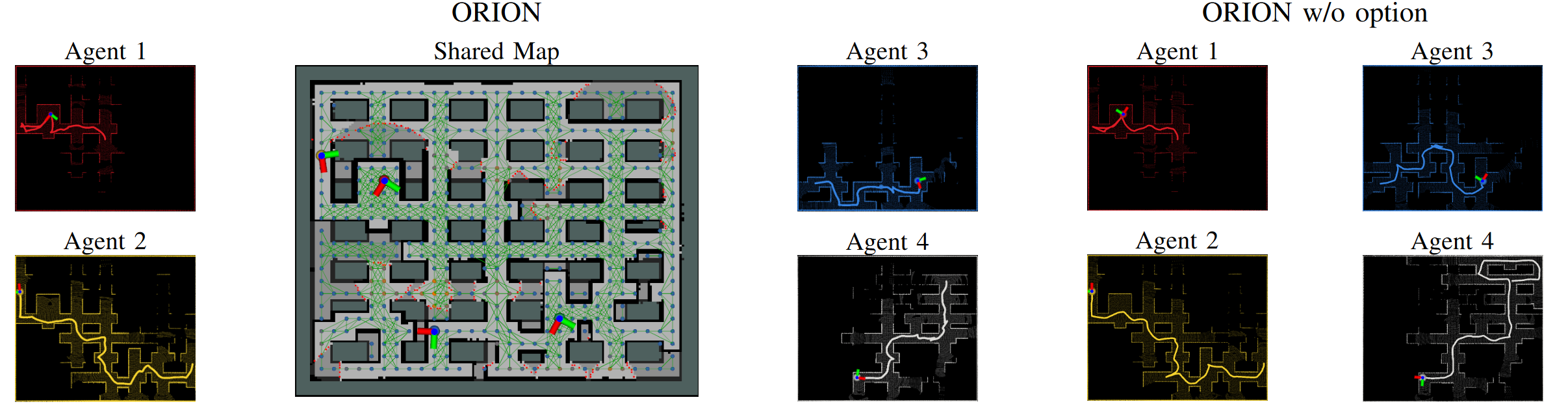
- Option space design: The option set is restricted to two modes (self-directed navigation and cooperative assistance). Can more granular or learned options (e.g., targeted scouting, information relay, traffic unblocking, escorting) yield better cooperation, and how should options be discovered, pruned, or composed adaptively?
- FSM-based option masking: The finite-state machine governing option transitions is hand-specified (e.g., post-arrival bias to assistance). Can transition masks be learned from data or generalized across tasks, and what is the trade-off between hard constraints and soft regularization in avoiding invalid or counterproductive option switching?
- Termination policy calibration: The termination head optimizes switching via a Q-differential advantage but lacks analysis of sensitivity to hyperparameters (e.g., λ for termination loss, α for entropy). What are robust calibration strategies, and does the termination mechanism remain stable across environments with different uncertainty regimes?
- Graph construction and scalability: Nodes are sampled uniformly and attention is masked by local edges. How do graph size, sampling density, and neighbor connectivity affect performance, memory, and runtime on larger maps (e.g., 500×500 m), and can adaptive or learned graph sampling reduce computation while preserving plan quality?
- Long-range reasoning: Attention is restricted to local neighborhoods; cross-attention fuses prior/current maps but may be myopic. Can hierarchical or multi-scale graph encoders enable long-range waypoint reasoning and global shortcut discovery under partial observability?
- Risk-aware planning into unknown space: The planning graph includes samples from unknown cells without explicit risk modeling. How should the policy incorporate hazard likelihoods, visibility, and clearance (e.g., chance constraints, risk budgets) when choosing exploratory trajectories?
- Frontier utility design: Utilities are defined by frontier counts within a range. Are information-theoretic objectives (e.g., expected information gain, mutual information with teammates’ goals) more effective, and how do utility definitions impact exploration efficiency and makespan?
- Collision guarantees and deadlocks: Safety is modeled via vertex/edge conflict rules, but the learned waypoint policy offers no formal guarantees against deadlocks or livelocks in decentralized execution. Can formal methods (e.g., online control barrier functions, asynchronous conflict resolution protocols) be integrated without harming performance?
- Dynamic obstacles and human–robot interaction: Evaluations consider static environmental changes but not moving obstacles (e.g., forklifts, humans). How can ORION extend to socially compliant navigation and dynamic obstacle prediction under partial observability?
- Kinodynamic and non-holonomic constraints: Agents move on a discrete graph with uniform step costs; acceleration limits, turning radii, and model-specific constraints are not considered. How does incorporating kinodynamic feasibility into the decoder (or a refinement layer) affect real-world performance?
- Task dynamics and re-planning: Targets are fixed; dynamic task arrivals, cancellations, or time windows are not studied. How should option policies adapt to evolving task sets and reassignments to minimize makespan and idle time?
- Heterogeneous teams: All agents are assumed identical. How do differing sensors, speeds, footprint sizes, or aerial/ground mixtures affect coordination, and can ORION learn role-specialized options for heterogeneous teams?
- Large-scale team sizes: Simulations evaluate up to 10 agents (and 3–5 in Gazebo); scalability to 50–100+ agents typical in warehouses is untested. What architectural or training changes (e.g., sparse attention, decentralized critics, curriculum scaling) are needed to maintain performance at scale?
- Real-world validation breadth: Real-world tests use two ground vehicles in an office environment. How does ORION perform in larger, cluttered warehouses, under frequent layout changes, with higher sensing noise and more agents?
- Computational budget on embedded hardware: Runtime is reported for Python implementations; no evaluation on embedded compute (e.g., Jetson, industrial PCs) under strict latency budgets. What optimizations (model compression, quantization, graph pruning) preserve performance while meeting real-time constraints?
- Reward shaping and credit assignment: The team-level objective is makespan, but reward shaping and credit assignment specifics are under-described. How do different reward decompositions (e.g., counterfactual baselines, difference rewards) impact cooperative behaviors and training stability?
- Ablation coverage: Ablations consider options and dual-stage strategy but not encoders, guideposts, masks, or termination losses. Which components contribute most to generalization and robustness, and where are the failure modes?
- Prior-map discrepancy regimes: Performance is not analyzed against controlled discrepancy magnitudes (e.g., proportion of altered obstacles, spatial distribution of changes). What are the boundaries where ORION’s cooperation remains effective, and when does it degrade?
- 3D environments and multi-level structures: The map is 2D occupancy; warehouses often have multi-level storage and mezzanines. How should 3D mapping, vertical connectivity, and occlusion be encoded in the graph and policy?
- Assistance budgeting post-arrival: Post-arrival exploration is governed by “return in time” heuristics without an explicit budget or constraint model. Can formal assistance budgets or time-to-return constraints improve predictability and safety while preserving makespan gains?
- Benchmarking breadth: Baselines include MAPF replanners and a single learning-based method. How does ORION compare to multi-agent active SLAM, decentralized POMDP planners, or information-sharing policies with learned communication (e.g., learned message passing under uncertainty)?
- Safety, compliance, and certification: No analysis of worst-case behavior, formal guarantees, or conformance to industrial safety standards. What verification tools or safety layers can be added without nullifying the benefits of learned cooperation?
Practical Applications
Immediate Applications
Below are near-term, deployable use cases that closely match the paper’s validated settings (indoor, 2D, reliable communication, LiDAR-based mapping) and leverage ORION’s fused prior/online mapping, option-critic switching between self-navigation and assistance, and the dual-stage cooperation strategy.
- Warehouse and Factory AMRs: resilient fulfillment and material transport (Robotics, Logistics/Manufacturing)
- Use case: Autonomous mobile robots (AMRs/AGVs) continue operating when shelf layouts or aisles change mid-shift. Robots that finish early scout uncertain aisles and share verified routes so bottleneck teammates avoid dead-ends, reducing makespan and improving throughput.
- Tools/products/workflows:
- ORION-powered “cooperative exploration mode” for idle AMRs integrated with ROS/ROS2 Nav stacks and a WMS/MES plugin for live map updates.
- Fleet management microservice for option-aware waypoint selection and team map fusion; dashboard visualizing prior-map discrepancies and assistance actions.
- Assumptions/dependencies: Reliable Wi‑Fi for global map sharing; 2D indoor occupancy maps; accurate localization and time-sync; LiDAR (or equivalent) perception; safety layer (e.g., CBF/ORCA) for last-resort collision avoidance; integration with WMS task assignment.
- Hospital logistics robots under evolving layouts (Healthcare, Robotics)
- Use case: Delivery robots handle partial corridor closures or ward reconfigurations; post-delivery, a robot quickly verifies alternative corridors and shares updated routes to reduce delays for others.
- Tools/products/workflows:
- ORION as a plug-in to hospital fleet managers; “post-arrival assistance” toggle for robots waiting at stations.
- Unified mapping node (e.g., OctoMap) fused with ORION’s graph encoder for low-latency re-routing.
- Assumptions/dependencies: Clear human-safety constraints and speed limits; connectivity in hallways; institutional policies allowing map sharing; limited crowd density or separate human-aware local planner.
- Retail store restocking and in-store logistics (Retail, Robotics)
- Use case: Robots navigate changing aisles/planograms; idle units confirm newly blocked shelves and broadcast passable paths to reduce team travel time.
- Tools/products/workflows:
- Store “digital twin” updated in near real time from ORION’s shared map; integration with planogram management tools.
- Option-aware mission scheduler that assigns “assist” tasks to early finishers.
- Assumptions/dependencies: Indoor coverage (Wi-Fi), consistent localization in visually repetitive aisles, acceptance of frequent micro-replans in store operations.
- Cleaning and facilities robots in offices, malls, airports (Facilities, Robotics; Daily Life in commercial settings)
- Use case: Multiple cleaners coordinate when floor access changes (events, night shifts). After finishing a zone, one robot briefly surveys adjacent uncertain zones and shares verified passes.
- Tools/products/workflows:
- ORION in multi-robot cleaning fleet managers; uncertainty heatmaps to focus scouting.
- Integration with building management systems (BMS) to reflect temporary closures.
- Assumptions/dependencies: 2D navigation suffices; consistent marking of temporary barriers; moderate robot team sizes; reliable comms indoors.
- Security patrol robots: fast re-routing and collaborative verification (Security, Robotics)
- Use case: Patrol robots respond to ad-hoc closures; first robot at a checkpoint scans near a blocked fire door and shares updates to minimize detours for others.
- Tools/products/workflows:
- ORION-backed patrol scheduler distributing “assist” tasks conditioned on route criticality.
- Patrol logs linking map updates to response-time SLAs.
- Assumptions/dependencies: Policy-compliant operation after-hours; comms coverage; integration with access-control events.
- Academic research and teaching: realistic multi-agent partial-map navigation (Academia, Software)
- Use case: Benchmarking decentralized cooperation under partial observability; studying option-based intent switching and multi-robot exploration–exploitation trade-offs.
- Tools/products/workflows:
- Open-source ORION codebase with Gazebo/ROS integration, training scripts, and new maze/warehouse benchmarks for reproducible studies.
- Curriculum labs on multi-agent RL, option-critic design, and graph encoders.
- Assumptions/dependencies: GPU resources for training; familiarity with ROS/Gazebo; synthetic-to-real generalization handled by sensor emulation and curriculum fine-tuning.
Long-Term Applications
These use cases require further research, scaling, or engineering beyond the paper’s assumptions (e.g., limited/intermittent communication, 3D or outdoor environments, dense human crowds, heterogeneous teams, or stricter certification).
- Limited/Intermittent Communications and Bandwidth-Aware Cooperation (Robotics, Networking)
- Use case: Warehouses/factories with patchy Wi‑Fi or interference; robots must reason about teammates’ uncertain beliefs and schedule map sharing opportunistically.
- Tools/products/workflows:
- Delay-tolerant map sharing protocols and belief inference modules; bandwidth-aware option policies.
- Edge–cloud split for compressing map deltas and prioritizing high-value updates.
- Assumptions/dependencies: New comms-aware training objectives and robustness to stale teammate beliefs; rigorous testing for safety under comms dropouts.
- Human-centric spaces with dense crowds and social norms (Healthcare, Retail, Airports; Robotics + HRI)
- Use case: Teams move through crowded public spaces while respecting social navigation constraints and intent-expressive behaviors.
- Tools/products/workflows:
- Fusion of ORION’s high-level cooperation with social navigation policies (e.g., learning social costs, explicit human intent models).
- Validation pipelines for HRI safety and compliance.
- Assumptions/dependencies: Rich perception for humans, prediction models, liability frameworks; additional certification and explainability.
- Multi-floor/3D and heterogeneous teams (ground + aerial) for inspection and inventory (Energy, Construction, Mining, Utilities; Robotics)
- Use case: Power plant inspections, construction site mapping, underground mines—mixed robots cooperatively reduce uncertainty in 3D environments and share multi-layer maps.
- Tools/products/workflows:
- 3D graph encoders and voxel maps; cross-platform option embeddings for drones/UGVs; multi-layer map fusion.
- Integration with digital twins for as-built/as-is reconciliation.
- Assumptions/dependencies: Robust 3D SLAM in GPS-denied spaces; safety envelopes for aerial robots; cross-robot calibration and time sync; higher compute and memory budgets.
- City-scale last-mile delivery fleets and campus logistics (Smart Cities, Logistics; Robotics)
- Use case: Large robot fleets coordinate around temporary closures and events; post-arrival robots scout nearby blocks and share verified passability to reduce fleet-wide delays.
- Tools/products/workflows:
- Hierarchical planners combining ORION-like local cooperation with global routing/traffic services; V2X-enabled map sharing.
- Fleet-wide dashboards with uncertainty overlays and incident heatmaps.
- Assumptions/dependencies: Outdoor mapping under GPS multipath; regulatory permissions; secure V2X channels; weather robustness.
- Cross-vendor, standards-based multi-robot interoperability (Policy, Industry Standards, Software)
- Use case: Mixed fleets (different OEMs) share map updates and intents in a standard format to enable cooperative assistance across brands.
- Tools/products/workflows:
- Open standards for occupancy/map deltas, robot state, and option/intention messages; certification programs for cooperative behaviors.
- Assumptions/dependencies: Industry and regulator buy-in; security and privacy mechanisms; conformance testing suites.
- Joint policy–environment co-optimization (adaptive layouts) (Manufacturing, Logistics; Robotics + Operations Research)
- Use case: Shelving or workstation layouts are reconfigurable; planning co-optimizes robot policies and environment to minimize makespan under uncertainty.
- Tools/products/workflows:
- Integration of ORION-like policies with layout optimizers/digital twins to suggest aisle configurations that reduce exploration burden.
- Assumptions/dependencies: Real-time layout actuation costs; safety checks; ROI validation for frequent reconfiguration.
- Consumer multi-robot home services (Daily Life, Smart Home; Robotics)
- Use case: Teams of home robots (vacuum + inspector) coordinate in changing households; early finisher scouts to confirm blocked rooms (e.g., guest room, pet gates) for others.
- Tools/products/workflows:
- Lightweight ORION variants on embedded hardware; home-grade mapping and privacy-preserving sharing between devices.
- Assumptions/dependencies: Cost-effective multi-robot households, robust localization without infrastructure, private/local map sharing, user acceptance.
- Finance/Operations analytics: throughput and ROI modeling for cooperative fleets (Finance/Operations, Software)
- Use case: Quantify makespan reductions and throughput gains from option-aware cooperation; forecast staffing and asset utilization.
- Tools/products/workflows:
- Simulation-based digital twins that replay tasks with/without ORION; KPIs linking uncertainty reduction to cycle times and costs.
- Assumptions/dependencies: High-fidelity task and demand models; access to operational data; alignment with existing BI tools.
Cross-cutting assumptions and dependencies to consider
- Technical:
- Current validation is 2D indoor navigation with LiDAR and occupancy grids; extension to 3D, outdoor, and heavy dynamics requires additional perception and mapping capability.
- Assumes accurate localization, shared frames, and synchronized clocks.
- Centralized training with privileged information; deployment uses decentralized inference—domain shift must be managed for new sites.
- Real-time inference demonstrated in Python; production systems may need C++/GPU optimization.
- Operational:
- Reliable or at least predictable communications were assumed; limited/intermittent comms remains an open research direction noted by the authors.
- Safety and compliance layers must wrap around the learned policy (e.g., CBFs, ORCA, geofencing).
- Integration with fleet/task managers (WMS/MES/BMS) and digital twins is essential for end-to-end value.
- Organizational/Policy:
- Standards for map data formats and secure sharing are needed for multi-vendor interoperability.
- Privacy and security controls for shared maps (especially in hospitals/retail).
- Change management and operator training for understanding assistance behaviors and uncertainty dashboards.
Glossary
- beacon set: A clustered set of informative viewpoints (with non-zero utility) used as candidate regions to navigate toward in planning. "We further cluster all viewpoints with non-zero utility within a range into a beacon set~\cite{liang2024hdplanner},"
- Bernoulli sampling: A random draw from a Bernoulli distribution (two outcomes) used here to decide whether to terminate an option. "Finally, a Bernoulli sampling"
- bounded-suboptimal MAPF: A Multi-Agent Path Finding approach that guarantees solutions within a known factor of optimal while reducing search cost. "a bounded-suboptimal MAPF planner that combines Explicit Estimation Search at the high level with focal search at the low level."
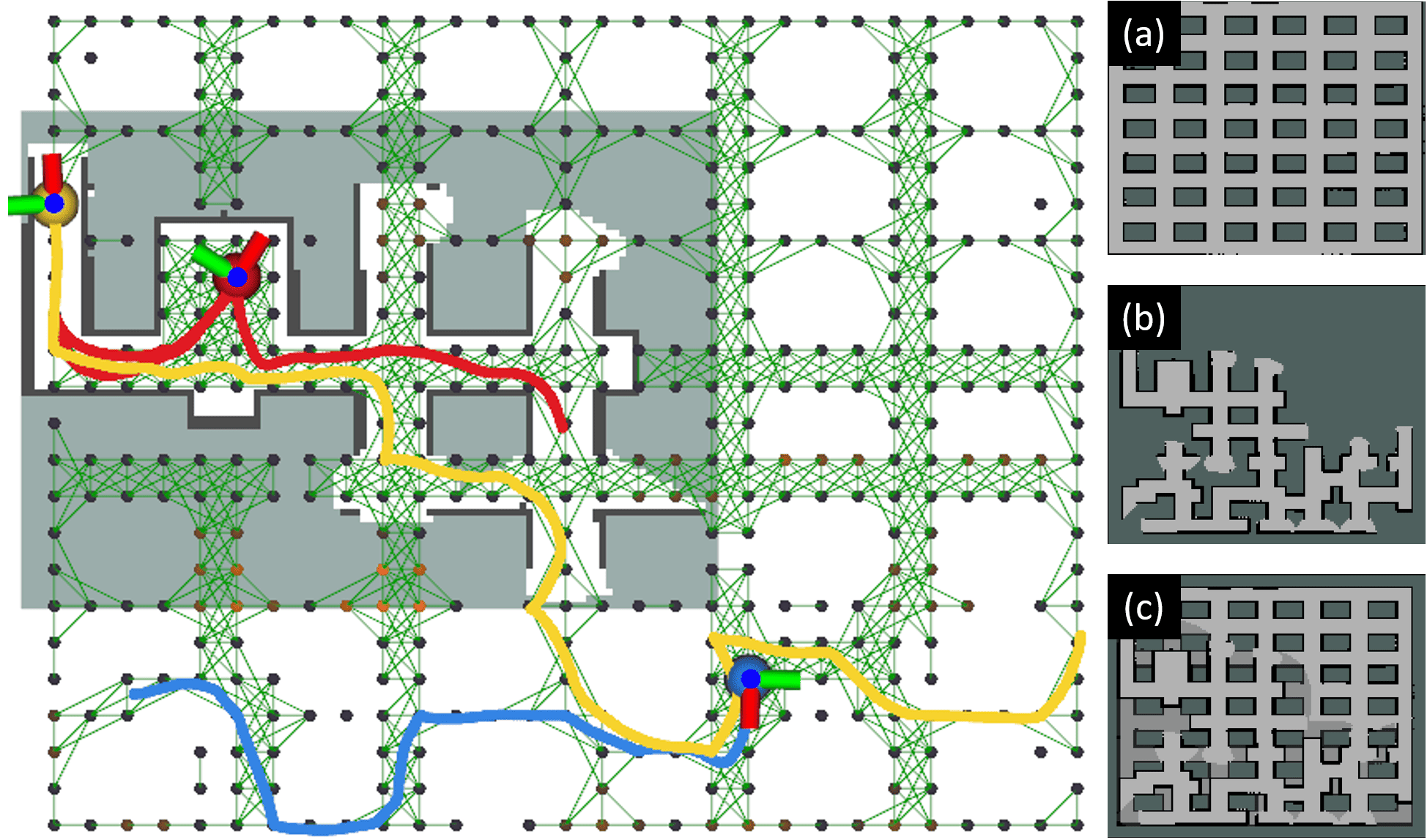
- combined map: A fused representation that integrates prior map information with online observations to reason about partially changed environments. "and (c) combined map that fuse prior/online sources to reason about partially changed environments."
- cooperation guidepost: A planned route toward regions most informative for assisting teammates, especially toward unverified targets. "Cooperation guidepost $g_{c,j$}: if any target remains unverified,"
- counterfactual value: An estimated return for an alternative decision (e.g., if the option terminates) used to compute termination advantages. "and the counterfactual value if the option terminates"
- cross-attention layer: An attention mechanism that fuses two feature sets by attending across them (e.g., prior and current graph features). "via a cross-attention layer"
- Dijkstra trajectory: The shortest-path route computed on a graph using Dijkstra’s algorithm, used here as a navigation guide. "the Dijkstra trajectory on "
- dual-stage cooperation strategy: A policy design that distinguishes between pre-arrival and post-arrival behaviors to enable timely assistance to teammates. "We further introduce a dual-stage cooperation strategy"
- EECBS: A specific bounded-suboptimal MAPF planner (Enhanced Edge-Conflict-Based Search) combining high-level Explicit Estimation Search and low-level focal search. "EECBS~\cite{li2021eecbs}, a bounded-suboptimal MAPF planner"
- Explicit Estimation Search: A high-level search strategy that explicitly estimates costs to guide bounded-suboptimal planning. "Explicit Estimation Search at the high level"
- finite-state machine (FSM): A discrete controller encoding admissible transitions between options to ensure valid high-level behavior switching. "Here we introduce a finite-state machine (FSM)"
- focal search: A heuristic search variant that focuses on a subset of promising nodes to speed up bounded-suboptimal search. "with focal search at the low level."
- frontiers: Boundaries between known free space and unknown areas used to drive exploration. "extending the notion of frontiers~\cite{yamauchi1998frontier}"
- Gazebo: A high-fidelity robotics simulator used for large-scale environment evaluation. "We further evaluate our approach in a \SI{70}{m}\SI{60}{m} Gazebo warehouse environment,"
- graph attention-based network: A neural architecture that applies attention mechanisms over graph-structured data to encode relational states. "we design a graph attention-based network"
- ground truth map: The actual (correct) map of the environment, potentially differing from the prior map and used as privileged information during training. "The true environment is described by a ground truth map "
- LNS2: A large neighborhood search-based MAPF solver that iteratively repairs collision-containing paths for scalability. "LNS2~\cite{li2022mapf}, a highly efficient and scalable planner"
- MAAC: Actor-Attention-Critic, a multi-agent RL framework where a centralized critic uses attention over agents. "Following MAAC~\cite{iqbal2019actor}, the critic computes a query"
- makespan: The time or distance until the last agent reaches its target; the team-level objective to minimize. "minimizing the overall makespan,"
- masked self-attention: An attention mechanism restricted by a mask (e.g., graph edges) so nodes attend only to neighbors. "and then applies multiple masked self-attention layers."
- masked softmax: A softmax operation applied after masking invalid options/transitions, ensuring probabilities only over allowed choices. "computed via a masked softmax:"
- Multi-Agent Centralized Critic: A critic architecture that conditions value estimates on the joint state/actions/options of all agents. "Multi-Agent Centralized Critic"
- Multi-Agent Path Finding (MAPF): The problem of computing coordinated, collision-free paths for multiple agents, typically on discrete graphs. "Another closely related domain is Multi-Agent Path Finding (MAPF)"
- navigation guidepost: A planned route guiding the agent toward its own target via informative regions (e.g., beacons). "Navigation guidepost $g_{n,j$}: the Dijkstra trajectory on "
- OctoMap: A probabilistic 3D occupancy mapping framework used to build and update the online map in real time. "We use OctoMap with an occupancy resolution of \SI{0.4}{m}"
- option-critic: A hierarchical RL framework that learns options (temporally extended actions) with learned intra-option policies and termination. "At the core of ORION is an option-critic framework"
- option-state values: Value estimates conditioned on both the current state and the active option, used for long-term evaluation. "the critic decoder produces the option-state values"
- pointer layer: A neural mechanism that scores and selects from discrete candidates (e.g., neighboring waypoints) by attention. "a pointer layer computes attention scores"
- pointer-network decoder: A decoder that selects the next waypoint by pointing to graph nodes based on attention scores. "the intra-option policy is realized through a pointer-network decoder"
- prior occupancy map: An initial, possibly outdated map indicating free and occupied regions available before online operation. "a 2D prior occupancy map "
- privileged graph encoder: A training-time encoder that accesses ground-truth information to provide low-variance value estimates. "differs in its use of a privileged graph encoder."
- privileged ground-truth information: Accurate environmental data available only during training (not at execution) to stabilize learning. "has access to privileged ground-truth information (i.e., the ground-truth map)"
- temporal-difference (TD) regression objective: A value-learning objective minimizing Bellman errors via bootstrapped targets. "via a temporal-difference (TD) regression objective."
- termination head: A network module estimating the probability of ending the current option at each step. "we define a termination head function"
- transformer decoder: An attention-based decoder module refining node features by attending to other agents or context. "refined by a transformer decoder"
- vertex and edge collisions: Discrete-time conflicts where two agents occupy the same node (vertex) or traverse the same edge (especially in opposite directions). "Agents must avoid vertex and edge collisions,"
- waypoint decoder: The module selecting the next waypoint conditioned on option and node features. "while the waypoint decoder integrates the option feature with the current node feature"
Collections
Sign up for free to add this paper to one or more collections.