LLMs can hide text in other text of the same length
Abstract: A meaningful text can be hidden inside another, completely different yet still coherent and plausible, text of the same length. For example, a tweet containing a harsh political critique could be embedded in a tweet that celebrates the same political leader, or an ordinary product review could conceal a secret manuscript. This uncanny state of affairs is now possible thanks to LLMs, and in this paper we present a simple and efficient protocol to achieve it. We show that even modest 8-billion-parameter open-source LLMs are sufficient to obtain high-quality results, and a message as long as this abstract can be encoded and decoded locally on a laptop in seconds. The existence of such a protocol demonstrates a radical decoupling of text from authorial intent, further eroding trust in written communication, already shaken by the rise of LLM chatbots. We illustrate this with a concrete scenario: a company could covertly deploy an unfiltered LLM by encoding its answers within the compliant responses of a safe model. This possibility raises urgent questions for AI safety and challenges our understanding of what it means for a LLM to know something.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper shows a surprising new trick: with help from a LLM, you can hide one full piece of text inside another different, normal‑sounding piece of text of the same length. For example, a serious complaint about a leader could be perfectly hidden inside a cheerful message praising that leader. Anyone who has the secret “key” can pull the hidden text back out exactly.
The authors explain how this works, test how believable the hidden‑carrying texts are, and discuss why this matters for trust, safety, and how we think about what LLMs “know.”
What questions did the researchers ask?
- Can an LLM transform one meaningful text into another believable text of the same length, in a way that lets the original be recovered exactly by someone with a secret key?
- Will the resulting “cover” texts still read like normal, human‑sounding writing?
- How easy is it to tell a normal text from a text that secretly carries another message?
- What are the risks and impacts for online communication and AI safety?
How did they do it? (Methods explained simply)
First, a quick idea about LLMs:
- An LLM is a program that guesses the next piece of text (a “token,” which is a word or part of a word) based on what came before. It assigns higher probabilities to tokens that make sense in context.
The core idea of the hiding trick:
- Imagine you have two texts:
- e: the secret text you want to hide.
- s: the public text you want people to see, shaped by a secret prompt (the “key”) to set its topic and style.
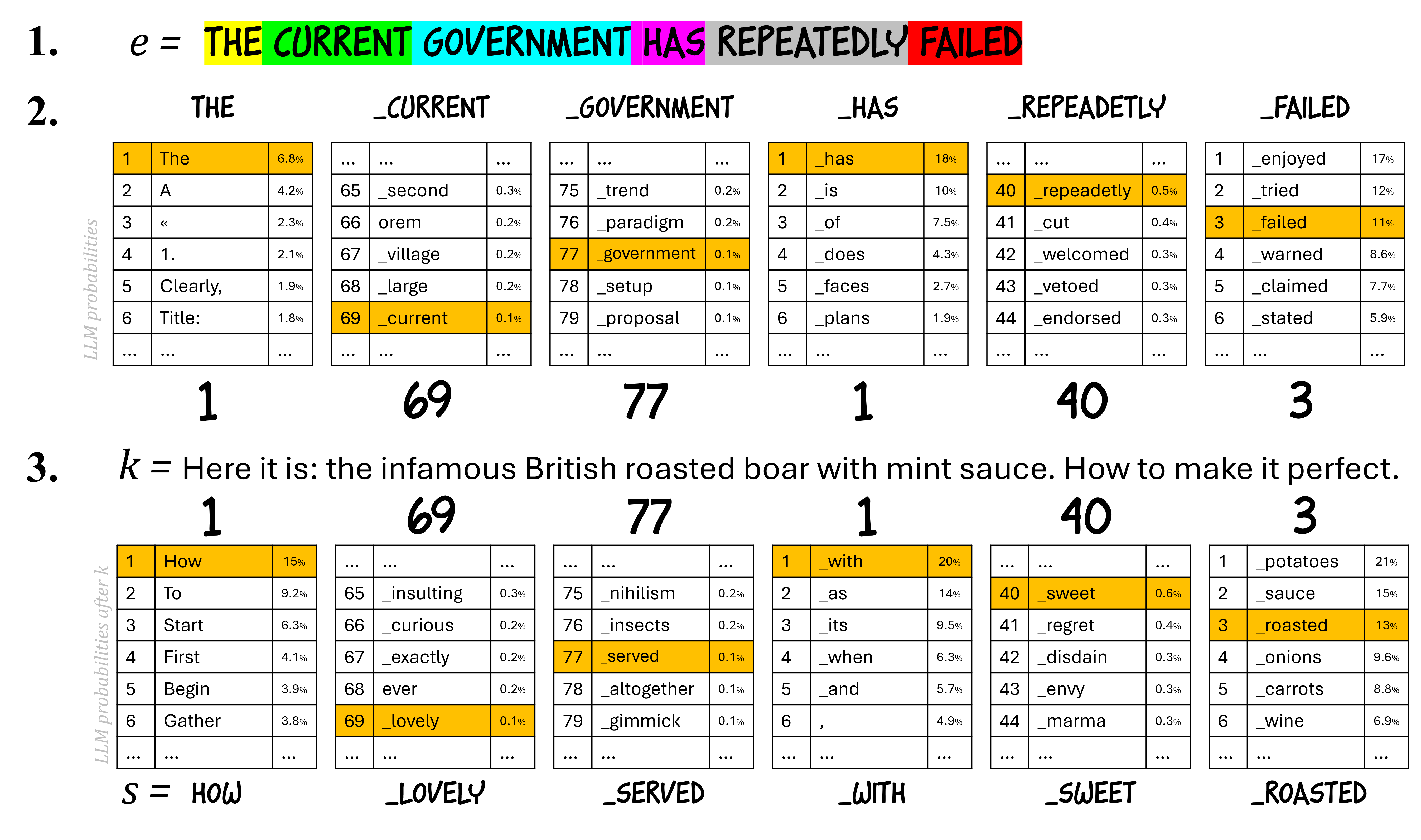
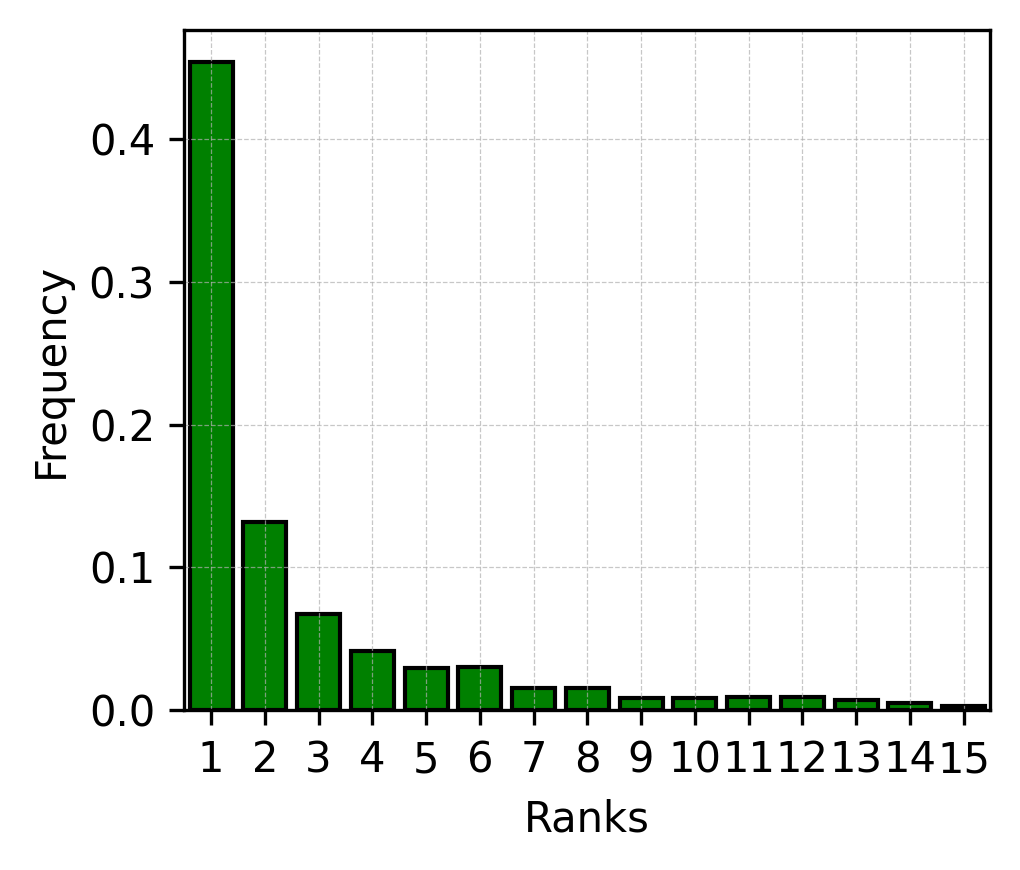
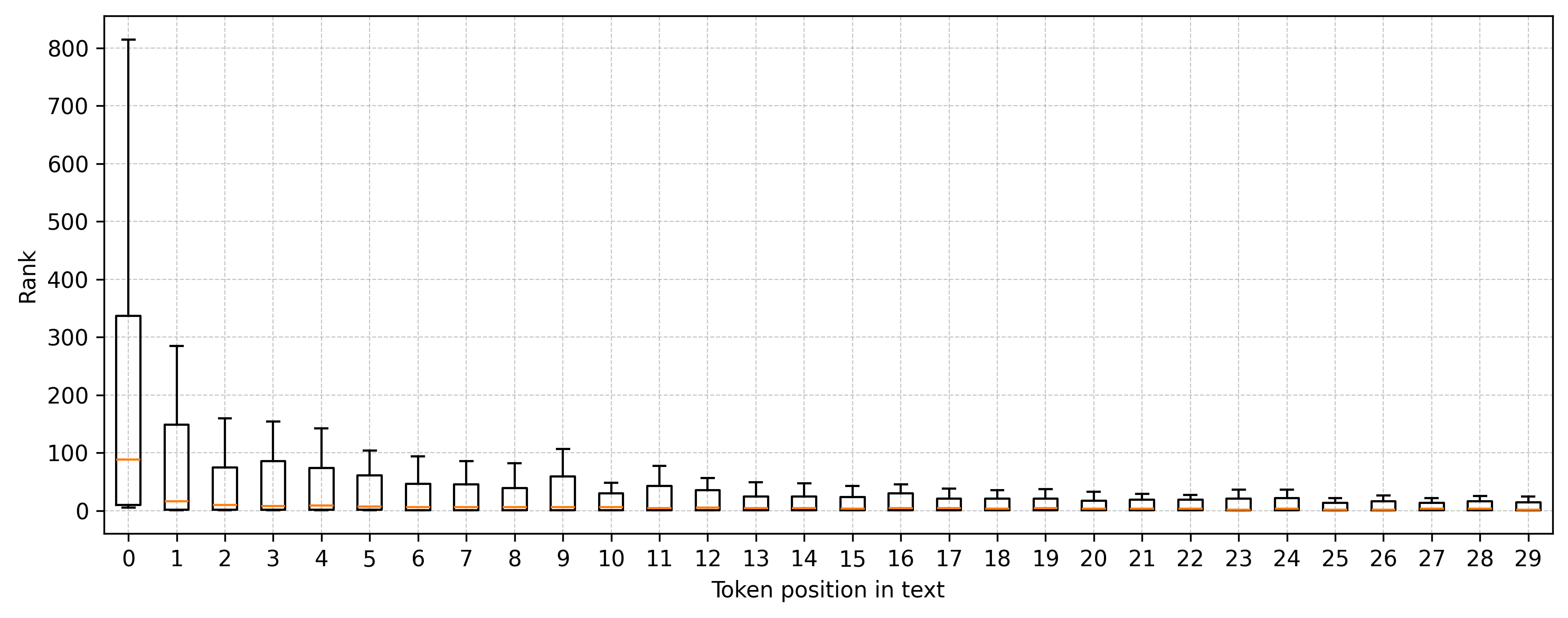
- For the secret text e, the LLM can tell you, at each step, how likely each possible next token is. If you sort these choices from most likely to less likely, each real token in e has a position in that list (its “rank”).
- To create s, you ask the LLM to write about whatever your key says (for example, a cooking recipe). But instead of picking the most likely next token, you force it to pick the token that has the same rank as the token from e at that step. So you’re copying the sequence of ranks, not the actual words.
Analogy:
- Think of a music app that predicts the next song in a playlist and ranks songs by popularity for that moment. Your secret message is a list of popularity positions (like 1st, 3rd, 2nd...). To hide it, you build a public playlist on a different theme (say, “party songs”) but, at each step, you pick the song that sits at the same popularity position. Later, anyone with the same app, same settings, and the key theme can reverse this and recover the original list.
Decoding:
- With the same LLM and the secret key, you look at the public text s and figure out the ranks that were used. Then you apply those ranks to the original context to reconstruct the hidden text e exactly.
Important notes:
- The two texts have the same token length, which makes them look symmetric: you can’t tell which one is the “real” one just by length.
- This relies on having the same model and settings on both sides so the rankings match.
What did they find, and why does it matter?
Main results:
- It works with relatively small, open‑source LLMs (around 8 billion parameters) and runs quickly on a normal laptop.
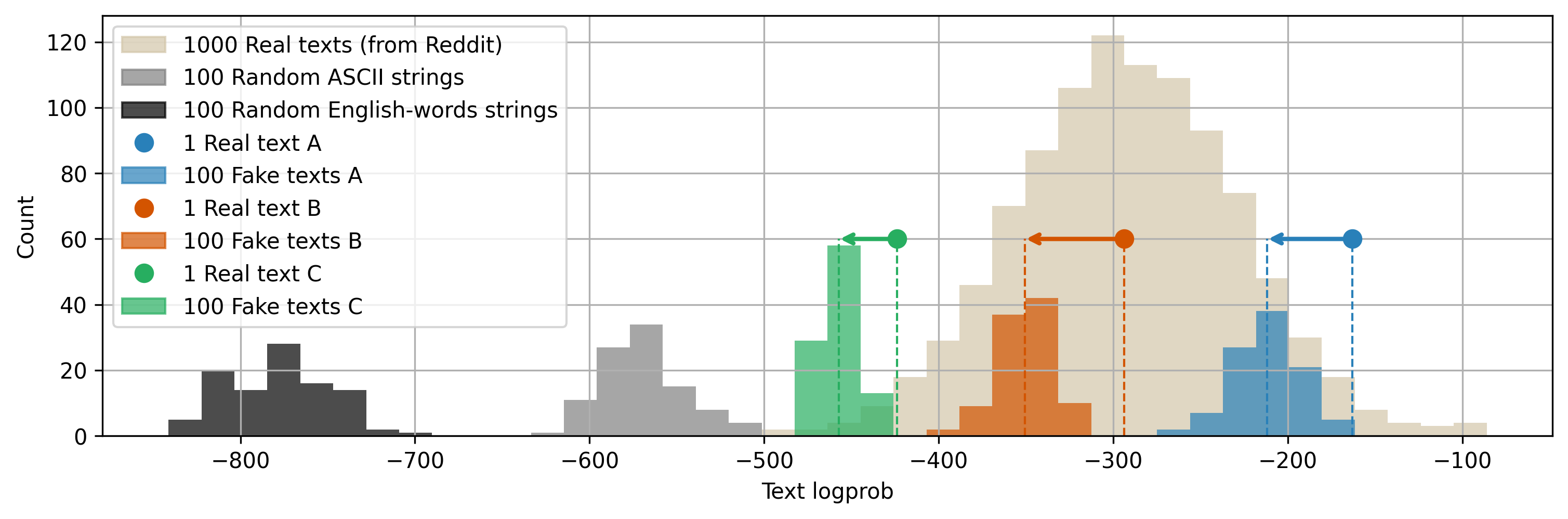
- The created public texts s usually read as coherent and plausible to humans. The authors measured this by checking how much probability the model assigns to the full text: the hidden‑carrying texts fall within the range of normal Reddit posts of the same length.
- Humans generally can’t tell which text is original and which is hiding something. However, another LLM can often guess that the original text is the more probable one overall. Still, not always—some hidden‑carrying texts are just as probable as normal texts.
- Limits: if the secret text is very weird or random (like a hash), the resulting public text can become messy. Also, decoding needs the exact same LLM and conditions.
Why it matters:
- This shows a “full capacity” trick: the hidden text and the public text can be the same length, which is unusual and powerful for steganography (the art of hiding messages).
- It weakens the link between what a text says and what its writer “intended,” because even very natural‑looking writing could secretly be carrying a different message chosen word‑by‑word.
Safety angle:
- The authors warn that someone could hide answers from an uncensored model inside the “safe” answers of a filtered model. That could let harmful or restricted information slip through while the visible answer still looks responsible. This raises new challenges for AI safety and content moderation.
How did they test it? (Approach in plain terms)
- They collected real Reddit posts and measured how “plausible” they look to an LLM (using the model’s assigned probabilities).
- They built many hidden‑carrying texts using different prompts (topics/styles) and compared their plausibility to the Reddit texts.
- They found the hidden‑carrying texts typically fit inside the plausibility range of normal writing.
- They also studied why hidden‑carrying texts are often a bit less probable than the original: some very obvious next words (like “Caesar” after “Gaius Julius”) don’t get chosen as often because the method forces picking tokens by rank copied from the secret text, not by what’s most natural in the new context. That “misuse” of the most‑likely choices adds a small probability penalty.
What could this mean? (Implications)
- Trust: Written text may no longer reliably reflect the author’s intentions. A friendly review could hide a protest. A “safe” chatbot reply could hide an unsafe one. This makes it harder to judge meaning and intent.
- Detection: While people might not notice, other LLMs can sometimes detect which text is more likely to be the original. But not always—some hidden texts are just as plausible, creating “deniability” (it’s hard to prove a message is hidden).
- AI safety: Platforms may need new defenses, since better “alignment” of visible answers could unintentionally make hidden bad answers easier to smuggle. Guardrails must consider not just what a model says, but how it could be used to carry hidden content.
- Rethinking “knowledge” and “hallucinations”: The paper argues that LLMs can produce convincing text that doesn’t reflect any true intention—just constraint satisfaction. This blurs what it means for a model to “know” something and reframes “hallucinations” as outputs that lack real intent behind them.
Note on responsible use:
- This research is meant to study risks and spark defenses, not to help anyone hide harmful content. Using such methods to spread dangerous or illegal information is unethical and may be unlawful.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of concrete gaps the paper leaves unresolved, organized to help guide follow-up research.
Method design and theoretical foundations
- No formal security/steganalysis model or proof: the method is not analyzed within an information-theoretic or computational framework (e.g., indistinguishability from covertext under a clear threat model, Kerckhoffs-compliant assumptions, or optimal couplings like minimum-entropy coupling) to quantify detectability and security guarantees.
- Unproven “full capacity” in realistic settings: while token-length parity is achieved, there is no analysis of fundamental trade-offs between capacity, plausibility (perplexity/entropy), and security when the hidden text’s rank distribution misaligns with the cover distribution induced by the key prompt.
- Lack of deniability formalization: “deniability” is argued qualitatively via probability overlap, without a definition (e.g., ε-deniability) or bounds on adversary confidence across prompts, lengths, and models.
- No optimality criteria for rank mapping: the paper uses a direct rank-copy scheme; it does not study alternative couplings/mappings that minimize distributional shift (e.g., entropy-aware or transport-based mappings that preserve local entropy/temperature).
- Unclear composition with encryption: high-quality stegotext requires “sound” hidden text; arbitrary bitstrings (encrypted payloads) yield high ranks/gibberish. There is no method to encode arbitrary ciphertext at full capacity while retaining plausibility (e.g., cover-coding/arithmetic-coding against the LLM distribution).
- Absence of error-tolerance design: the protocol assumes identical logits; there is no coding/decoding layer (synchronization markers, ECC, rank binning, list decoding) to tolerate logit/quantization drift or minor channel edits.
Security and threat modeling
- Key space and attacker priors not quantified: the brute-force bound O(d|k|) ignores strong language-model priors over “natural-language keys” and structured traces; the practical search space and success probability under realistic adversaries is unmeasured.
- Incomplete threat model: assumptions about adversary access (LLM name/version, logits, API behavior, side channels, chosen-plaintext/chosen-stegotext queries) are not formalized; no analysis of adaptive attacks or key-recovery with partial knowledge (e.g., observing multiple stegotexts under related keys).
- Cross-model approximation attacks untested: can an attacker with a different but close LLM approximate ranks well enough to decode or reduce key search (e.g., via model distillation or rank-calibration)?
- Deniability-vs-recovery tension unquantified: simultaneously maximizing plausible alternate decodings (for deniability) and reliable recovery (for the intended recipient) is not framed or optimized.
- Information leakage via rank statistics: the stegotext deterministically reflects the hidden text’s rank sequence statistics; the paper does not analyze how much side information (e.g., length, low-entropy segment locations, topic hints) leaks to a steganalyst.
Detectability and evaluation
- Limited detectability study: detection is reduced to log-probabilities; no trained steganalysis (binary classifiers, token-entropy profile tests, KL/JS divergence on local entropy, burstiness, rank-1 usage rate, POS/ngram shifts) is evaluated across models and datasets.
- Narrow evaluation scope: experiments focus on 85-token English Reddit texts with Llama 3 8B (and a brief Phi-3 check); no systematic study across languages, genres (news, legal, code), lengths (short tweets vs long articles), or larger/proprietary models.
- No human studies: there is no human evaluation of plausibility, topic/style adherence, or abruptness compared to matched human-written controls to corroborate LLM-based plausibility metrics.
- Metric limitations: plausibility is proxied by cumulative log-probability; no analysis of alternative metrics (e.g., length-normalized perplexity, per-token entropy distributions, calibration errors, Surprise/MAUVE, semantic coherence scores, LLM-as-judge).
- Out-of-distribution resilience: robustness of plausibility/detectability is not tested when the key prompt enforces niche styles, code-switching, or low-resource languages/scripts.
Practical robustness and engineering
- Extreme brittleness to implementation details: decoding requires bitwise-identical logits; the paper notes hardware/precision variability but offers no mitigation (e.g., deterministic kernels, quantization-aware alignment, logit rounding schemes, temperature/softmax spec, tokenizer/version pinning).
- No resilience to channel noise: the method breaks under edits, paraphrases, moderation filters, whitespace normalization, or truncation; there is no proposed scheme for edit-robust steganography (sync codes, watermark-like redundancy, re-synchronization beacons).
- Unanalyzed computational costs: per-step rank lookup over ~100k vocab may be expensive; no benchmarks on throughput/latency across model sizes, sequence lengths, decoding variants (partial sorting, selection algorithms), or memory footprints.
- Tokenization portability unaddressed: the approach relies on a specific tokenizer and vocabulary; the impact of tokenization shifts (model updates, special tokens, language-specific segmentation) on both plausibility and decodability is not studied.
- Termination and padding artifacts: abrupt endings and need for padding are noted but not systematically evaluated for detectability or mitigated via learned or constrained end-of-text handling.
Key design, prompting, and controllability
- Key construction is ad hoc: there is no principled method to choose or optimize the secret prompt(s) k/k′ to align entropy profiles, minimize detectability, and improve style control for a given hidden text.
- Steering vs quality trade-offs unquantified: how key length/detail impacts plausibility, topic adherence, and detectability is not measured or optimized (e.g., Pareto frontiers).
- Multi-lingual and cross-style steering: the limits of steering across distant styles/languages (e.g., hiding Latin critique inside code, poetry, or legalese) and the resulting rank pressure/plausibility degradation are not characterized.
Generality and extensions
- Black-box feasibility not demonstrated: prior work achieves black-box generative steganography; here, logits are required. It remains open whether approximate rank-coding is possible with only sampling APIs/top-k constraints.
- Beyond text: while the method “in principle” extends to any discrete autoregressive model, no experiments are shown for code, music, or tokenized images/audio (e.g., VQ models) where entropy profiles and human perception differ markedly.
- Multi-chunk/streaming protocols: no scheme for segmenting long hidden texts across multiple carrier messages, interactive chats, or out-of-order delivery while preserving decodability and deniability.
- Multi-recipient or layered messages: the possibility and limits of embedding multiple recoverable payloads under different keys (or hierarchical keys) in the same stegotext are not explored.
“Unfiltered LLM via aligned wrapper” scenario
- End-to-end feasibility not stress-tested: practical constraints (API latency, model drift/versioning, key distribution, inference determinism on user hardware) are not evaluated; small deviations may break recovery.
- Defenses and countermeasures absent: no analysis of how platforms could detect or prevent this covert channel (e.g., forced sampling randomness, server-side re-generation, logit perturbation, entropy tests, watermarking) or how attackers might adapt.
- Legal/operational ramifications: the scenario’s compliance, attribution, and liability questions (who “generated” the harmful content) are not analyzed; no policy guidance or auditing protocol is proposed.
Open algorithmic improvements
- Entropy-aware rank scheduling: can we reallocate “rank-1 budget” to naturally low-entropy positions (and defer higher ranks to high-entropy regions) while preserving decodability to reduce the plausibility gap?
- Rank binning and soft-matching: mapping hidden ranks into bins or quantiles to absorb small logit drift and improve robustness without prohibitive redundancy is unexplored.
- Learned keys and adaptive coupling: learning key prompts or small adapters that minimize KL divergence between cover and stego distributions for a given hidden text (subject to detectability constraints) remains open.
- Joint optimization with cryptography: designing distribution-preserving encryption/coding that transforms arbitrary bits into high-probability token sequences under the same LLM distribution (while retaining strong secrecy) is an open challenge.
These items identify what remains uncertain or unaddressed and suggest concrete directions for empirical testing, formalization, and system design.
Practical Applications
Immediate Applications
The paper’s protocol enables several deployable use cases today using open-source LLMs (e.g., 8B models) on consumer hardware.
- Censorship-resistant publishing for civil society
- Sector: policy, media, human rights
- Use case: activists embed dissenting content inside innocuous posts to bypass platform/state censorship while maintaining deniability.
- Potential tools/workflows: the “calgacus” demo, local LLM with logits access, key distribution via secure messaging, prompt libraries to steer cover texts.
- Assumptions/dependencies: identical model version/tokenizer/logits between sender and receiver; coherent cover requires low-entropy ranks from the hidden text; legal/ethical risk and potential platform countermeasures.
- Deniable secure messaging for benign purposes
- Sector: software, cybersecurity, daily life
- Use case: a chat plugin that encodes a private note inside plausible chatter (recipes, travel tips) for privacy-conscious users.
- Potential tools/workflows: browser or messaging app extensions; containerized encode/decode environment ensuring deterministic logits; simple key management (short prompts plus random string).
- Assumptions/dependencies: white-box LLM with logits; reproducibility across devices (prefer CPU or fixed inference stack to avoid GPU non-associativity); risk of misuse.
- Red-team stress-testing of content moderation and alignment
- Sector: AI safety, platform trust & safety
- Use case: evaluate whether moderation systems can detect harmful payloads concealed in compliant outputs.
- Potential tools/workflows: stego corpus generation pipelines; LLM-based plausibility scoring (log-prob gaps); detection dashboards; adversarial prompt suites.
- Assumptions/dependencies: access to target models and logs; agreement on detection metrics; safety governance to avoid dual-use harm.
- Detection baselines for steganographic LLM outputs
- Sector: enterprise security, digital forensics
- Use case: flag candidate stegotexts by comparing log-probability profiles against expected distributions for similar-length covertexts.
- Potential tools/workflows: multi-model scoring (cross-model plausibility comparisons); anomaly detectors using rank-frequency features; policy rules for escalation.
- Assumptions/dependencies: detectors are probabilistic (false positives/negatives); attackers can tune prompts to evade; requires curated reference corpora.
- Risk demonstration for “shipping unfiltered LLMs via aligned fronts”
- Sector: AI governance, compliance, model hosting
- Use case: showcase how unsafe guidance can be hidden inside safe-appearing answers, motivating auditing and contractual controls.
- Potential tools/workflows: audit playbooks; reproducible proofs-of-concept; model response attestation checks (e.g., signed logits or sampling policies).
- Assumptions/dependencies: encoder needs logits and precise model match; organizations must establish policies prohibiting hidden channels and mandate red-team tests.
- Covert document tagging and internal routing
- Sector: enterprise software, knowledge management
- Use case: embed internal routing codes or pointers inside public-facing text (press releases, FAQs) retrievable by authorized staff.
- Potential tools/workflows: stego tagger CLI; key escrow and rotation; retrieval service that decodes embedded IDs to knowledge-base entries.
- Assumptions/dependencies: minimal payload length equals cover token length (full capacity constraint); non-malicious content only; risk of confusion with malicious stego.
- Educational demonstrations in critical reading and media literacy
- Sector: education, humanities
- Use case: classroom exercises showing decoupling of authorial intent from text form; analysis of plausibility vs meaning.
- Potential tools/workflows: lesson kits; controlled stego examples; student decoders; reflection prompts on intent/hallucination.
- Assumptions/dependencies: pedagogical safeguards; no harmful payloads; clear consent and transparency.
- Artistic and ARG experiences
- Sector: creative industries
- Use case: Oulipo-style constrained writing with hidden narratives; scavenger hunts where decoding reveals plot twists.
- Potential tools/workflows: creative IDEs with stego composer; curated prompt palettes to steer genre; audience decoders.
- Assumptions/dependencies: reproducibility for audience; content safety; explainability to avoid misleading audiences.
- Research dataset generation for stego/detection
- Sector: academia (NLP, crypto, HCI)
- Use case: standardized corpora of original vs stego texts at matched lengths to benchmark detectors and study deniability.
- Potential tools/workflows: pipeline scripts; annotation of rank distributions; cross-model scoring protocols; public datasets with disclosures.
- Assumptions/dependencies: IRB/ethics where relevant; safe payloads; license compliance for cover texts.
- Enterprise DLP (data loss prevention) exercises
- Sector: cybersecurity
- Use case: tabletop tests that simulate exfiltration via stegotext channels to harden monitoring and response.
- Potential tools/workflows: red-team kits; SIEM integrations to ingest plausibility flags; incident runbooks.
- Assumptions/dependencies: safe simulations; detector tuning to operational baselines; awareness of false alarms.
Long-Term Applications
Beyond immediate deployments, the findings suggest strategic developments requiring further research, scaling, and policy work.
- Cross-modal generative steganography (images, audio, video)
- Sector: media, cybersecurity
- Outlook: extend the rank-following idea to autoregressive/diffusion models in other domains for full-capacity or near-capacity hiding.
- Potential tools/products: multimodal stego SDKs; cross-modal decoders; robustness evaluations.
- Dependencies: model access to score distributions; coherence assurance in non-text domains; stronger detectors to prevent abuse.
- Platform-level defenses and provenance
- Sector: AI platforms, standards
- Outlook: attested inference (signed logits, deterministic sampling policies) and robust watermarks that survive rank-based encoding.
- Potential tools/products: provenance APIs; inference attestations; watermark validators integrated with content pipelines.
- Dependencies: industry consensus; performance and privacy trade-offs; adversarial adaptation.
- Formal models and provable guarantees for generative stego
- Sector: cryptography, information theory
- Outlook: theoretical frameworks for capacity, undetectability, and deniability under realistic LLM assumptions; coupling with minimum-entropy methods.
- Potential tools/products: libraries with security proofs; parameterized threat models.
- Dependencies: tractable model assumptions; evaluation metrics aligned with human/LLM perception.
- Robust stego detection models and benchmarks
- Sector: AI safety, trust & safety
- Outlook: train detectors on large corpora spanning prompts, topics, and models; ensemble methods combining log-prob, rank-frequency, and semantic cues.
- Potential tools/products: open benchmarks; standardized evaluation harnesses; auto-triage systems for moderation teams.
- Dependencies: high-quality labeled data; generalization across models; minimizing collateral censorship.
- Regulatory and compliance frameworks for hidden content
- Sector: policy, legal
- Outlook: rules for platform operators and model vendors addressing covert channels, disclosure obligations, and auditing requirements.
- Potential tools/products: compliance checklists; auditing protocols; certification labels for “no-hidden-channel” deployments.
- Dependencies: multi-stakeholder consensus; enforcement mechanisms; cross-jurisdiction harmonization.
- Secure, deniable communication channels for high-risk contexts
- Sector: human rights, journalism
- Outlook: standardized, vetted tools enabling safe stego use by at-risk groups with governance oversight and misuse prevention.
- Potential tools/products: vetted apps; key management services; risk assessment toolkits.
- Dependencies: threat modeling; usability in low-resource settings; legal protections.
- Enterprise DLP and insider-threat countermeasures tuned to LLM stego
- Sector: cybersecurity
- Outlook: next-gen DLP leveraging model-based plausibility and provenance signals; integrating with email/docs/chats.
- Potential tools/products: stego-aware DLP engines; SOC playbooks; simulation labs.
- Dependencies: acceptable false-positive rates; privacy-preserving scoring; workforce training.
- Educational curricula on authorial intent and AI-generated text
- Sector: education
- Outlook: formal modules teaching the decoupling of textual form from intent, critical reading strategies, and detection basics.
- Potential tools/products: curricula, educator training, student-friendly decoders.
- Dependencies: curriculum adoption; age-appropriate content; continuous updates as models evolve.
- Model architecture and training strategies to reduce exploitable capacity
- Sector: AI research
- Outlook: design choices (e.g., controlled entropy in top ranks, sampling constraints) that impede reliable full-capacity stego without eroding quality.
- Potential tools/products: research prototypes; ablation studies; deployment guides.
- Dependencies: rigorous evaluation of utility vs security; avoidance of new failure modes.
- Infrastructure for reproducible inference
- Sector: MLOps
- Outlook: standardized containers, precision settings, and inference kernels that ensure bitwise-identical logits for legitimate decode workflows (or attested variance to hinder stego).
- Potential tools/products: reproducible inference kits; “determinism profiles”; model version registries.
- Dependencies: hardware diversity; performance costs; coordination across vendors.
- Finance and compliance monitoring for covert signaling
- Sector: finance, fintech
- Outlook: detection of hidden trading signals or market manipulation embedded in public communications; compliance audits.
- Potential tools/products: market comms scanners; alerts integrated with compliance systems.
- Dependencies: regulatory buy-in; avoiding overreach; domain-specific baselines.
- Healthcare and scientific publishing provenance
- Sector: healthcare, academia
- Outlook: attestations ensuring clinical guidance or peer-reviewed findings are free of hidden payloads; provenance checks in submission and review pipelines.
- Potential tools/products: journal-integrated scanners; clinical content validators.
- Dependencies: sensitive data handling; collaboration with publishers and medical bodies; minimizing burden on authors.
Notes on feasibility across applications:
- Access to logits and exact tokenization is often necessary; black-box models limit applicability.
- Sender and receiver must use identical model versions and inference settings; GPU non-associativity can break decoding.
- Plausible covers depend on the hidden text’s rank distribution; high-entropy payloads risk incoherent covers unless assisted by context prompts.
- Ethical, legal, and safety concerns are significant; governance, auditing, and user education are essential to prevent misuse.
Glossary
- AI safety: The field focused on preventing harmful or unsafe behavior from AI systems and governing their deployment. "This possibility raises urgent questions for AI safety and challenges our understanding of what it means for a LLM to know something."
- Alignment (AI): The process of training or constraining AI systems to follow human values, goals, and safety constraints. "In recent years, aligned became a common attribute to refer to LLMs supposedly fine-tuned to follow human values, goals, and safety constraints"
- Autoregressive generation: A text generation method that produces tokens sequentially, each conditioned on the previously generated tokens. "a method known as autoregressive generation."
- Backpropagation: The gradient-based algorithm used to train neural networks by propagating errors backward to update parameters. "the contribution of every parameter to the error is assessed through backpropagation"
- Covertext: The original, seemingly innocuous content that is used as a carrier for a hidden message in traditional steganography. "The original content is referred to as the covertext, while the result containing the hidden message is the stegotext."
- Cryptography: The discipline concerned with securing information (typically without hiding the fact that a message exists), e.g., via encryption. "This is different from cryptography, that instead does not conceal the presence of a hidden message and only deals with the hardness of its revelation."
- Deniability: A cryptographic/steganographic property that allows a sender to plausibly deny the existence or content of a hidden message, even under coercion. "This observation suggests that our method provides deniability"
- Discrete autoregressive generative model: A model that generates sequences token-by-token by sampling from the conditional distribution of the next token given prior tokens. "any discrete autoregressive generative model producing a probability distribution on the next token"
- Entropy: A measure of uncertainty or unpredictability; in language modeling, lower entropy implies a more predictable next token. "This is a low-entropy token choice"
- Generative steganography: A steganographic approach that synthesizes the carrier content directly while embedding the secret, rather than modifying a pre-existing cover. "This approach has recently been referred to as generative steganography"
- Hallucination: An LLM’s production of fluent yet incorrect or ungrounded content. "The term hallucination became popular to denote the frequent, overconfident, and plausible falsehoods stated by LLMs in their answers"
- Hypothesis-testing framework: A statistical detection paradigm that frames steganalysis as deciding between hypotheses (e.g., cover vs. stego) based on observed data. "based on the hypothesis-testing framework"
- LLM: A high-parameter neural network (typically Transformer-based) trained to predict the next token over large corpora. "The result of this process is a LLM"
- Log-probability: The sum of logarithms of token probabilities across a sequence, often used as a plausibility score. "The figure shows the cumulative log-probability assigned by a LLM (Llama 3 8b) to some collections of 85-token long texts."
- Logits: The unnormalized scores output by a model before applying softmax to obtain probabilities. "A good LLM with access to all the output logits."
- Nucleus sampling: A decoding method (top-p sampling) that samples from the smallest set of tokens whose cumulative probability exceeds a threshold p. "techniques such as nucleus sampling"
- Sampling policy: The strategy used to convert model probabilities into discrete token choices during generation. "LLMs only provide token probabilities, and should be completed by a sampling policy when used for text generation."
- Soundness (of text): The plausibility of a text’s token arrangement as judged by a LLM. "Soundness refers to the plausibility of the arrangement of symbols in a text."
- Steganography: The art and science of concealing a message and the very presence of that message within another medium. "The art and science of hiding a message and, at the same time, the presence of a hidden message is known as steganography"
- Stegotext: The steganographic output that contains the embedded secret message while appearing plausible. "the result containing the hidden message is the stegotext."
- Tokenizer: The component that segments text into tokens (words/subwords) for model input/output. "Tokenize using the LLM tokenizer, obtaining a list of tokens"
- Transformer architecture: An attention-based neural network architecture widely used for sequence modeling. "the Transformer architecture"
- Vocabulary (LLM): The finite set of tokens a model can predict or generate. "typically operating over a vocabulary of 100k tokens."
Collections
Sign up for free to add this paper to one or more collections.

