- The paper introduces agent distillation, a novel framework that transfers tool-using and reasoning capabilities from large language models to smaller models.
- The method employs a first-thought prefix and self-consistent action generation to guide reasoning and reduce errors in complex tasks.
- Experimental results show that small models achieve competitive accuracy in factual and mathematical reasoning compared to larger fine-tuned models.
This essay examines the paper "Distilling LLM Agent into Small Models with Retrieval and Code Tools" (2505.17612). It introduces a novel framework known as Agent Distillation, designed to transfer complex reasoning and tool-using capabilities from LLMs to smaller models (sLMs), enhancing their efficiency and applicability in diverse domains.
Introduction
The increasing computational cost associated with deploying LLMs like GPT-4 for complex reasoning tasks has motivated the need for smaller LLMs that preserve problem-solving capabilities. Traditional methods such as Chain-of-Thought (CoT) distillation have attempted to achieve this by transferring reasoning traces from larger models into sLMs. However, these approaches often fail when confronted with tasks requiring rare factual knowledge or precise computation, leading to hallucination due to the limited capacity of sLMs.
Agent Distillation addresses these challenges by instilling not just reasoning capabilities but full task-solving behaviors into sLMs. This involves transferring agentic trajectories from LLM-based agents, allowing sLMs to think and act by retrieving facts or executing code, thus offering stronger generalization and better robustness to hallucination.

Figure 1: Chain-of-Thought (CoT) distillation trains student models to mimic static reasoning traces from LLMs, but often fails when new knowledge or precise computation is needed at test time. Our proposed agent distillation instead teaches student models to think and act (e.g., retrieve facts or execute code) offering stronger generalization and better robustness to hallucination.
Methodology
The Agent Distillation framework consists of two key components aimed at improving the distillation process: the first-thought prefix and self-consistent action generation.
First-thought Prefix: This technique involves using a CoT prompt to generate an initial reasoning step, which is then used as a prefix to an agentic trajectory. This ensures that the distilled agent begins reasoning in an appropriate direction, enhancing the quality of trajectories generated by the teacher model without requiring fine-tuning.
Self-consistent Action Generation: To improve test-time robustness, the agent generates multiple candidate actions and selects the one with outcomes consistent across samples. This approach mitigates the likelihood of errors, particularly in code execution, ensuring that smaller models can handle complex computations during inference.

Figure 2: (a) First-thought Prefix: We prompt teacher with a CoT prompt to induce step-by-step reasoning. The first reasoning step is used as a prefix to generate an agentic trajectory, which is then distilled to a student agent to teach CoT-style reasoning initialization. (b) Self-consistent Action Generation: The agent generates multiple candidate actions and selects the one with consistent outcomes.
Experimental Results
The proposed method was evaluated across multiple benchmarks, covering both factual and mathematical reasoning tasks. Results demonstrated that sLMs can achieve competitive performance with much larger models fine-tuned using CoT distillation, validating the efficacy of agent distillation for practical, tool-using small agents.
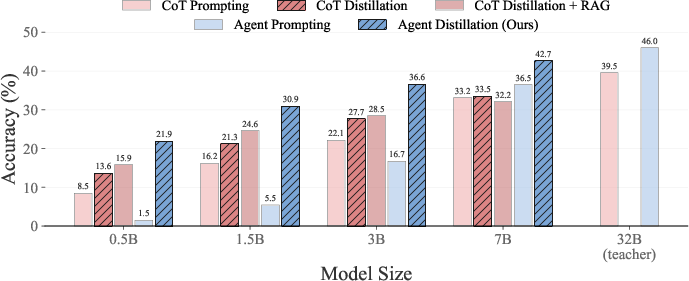
Figure 3: Performance comparison of different sizes of Qwen2.5-Instruct models on average accuracy across various factual and mathematical reasoning tasks.
In particular, agent distillation significantly improved the accuracy of smaller models on hard mathematical problems, as evidenced by gains in complex categories and difficulty levels, where traditional distillation methods fell short.
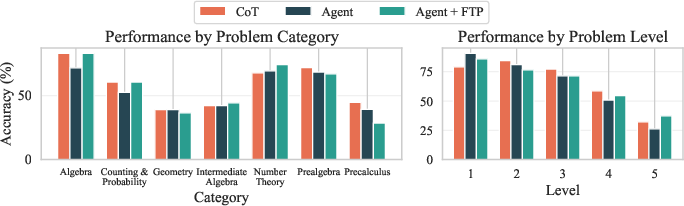
Figure 4: Performance comparison on the MATH subcategories and levels between CoT and Agent distillation of 3B models. The results highlight that \ improves the performance of small agents in harder problems.
Implications and Future Work
The findings underscore the potential of agentic behaviors to empower smaller models with reasoning capabilities that approximate those of LLMs, without sacrificing computational efficiency. This opens avenues for deploying sLMs in real-world applications where inference cost and computational resources are critical constraints.
Theoretical advancements might further explore integrating reinforcement learning in tool-augmented environments to refine these models post-distillation. Moreover, expanding the framework to encompass other domains, such as embodied agents interacting with the physical world or web-based agents, would broaden the applicability of distilled sLMs as efficient generalist agents.
Conclusion
Agent Distillation presents a transformative approach to enhancing the capabilities of sLMs, bridging the gap between LLM proficiency and the practical deployment of AI models in resource-constrained settings. By enabling small models to emulate the reasoning and adaptive behaviors of larger agents, this framework sets a foundation for developing intelligent tools that can operate with minimal computational demands.