LiveTalk: Real-Time Multimodal Interactive Video Diffusion via Improved On-Policy Distillation
Abstract: Real-time video generation via diffusion is essential for building general-purpose multimodal interactive AI systems. However, the simultaneous denoising of all video frames with bidirectional attention via an iterative process in diffusion models prevents real-time interaction. While existing distillation methods can make the model autoregressive and reduce sampling steps to mitigate this, they focus primarily on text-to-video generation, leaving the human-AI interaction unnatural and less efficient. This paper targets real-time interactive video diffusion conditioned on a multimodal context, including text, image, and audio, to bridge the gap. Given the observation that the leading on-policy distillation approach Self Forcing encounters challenges (visual artifacts like flickering, black frames, and quality degradation) with multimodal conditioning, we investigate an improved distillation recipe with emphasis on the quality of condition inputs as well as the initialization and schedule for the on-policy optimization. On benchmarks for multimodal-conditioned (audio, image, and text) avatar video generation including HDTF, AVSpeech, and CelebV-HQ, our distilled model matches the visual quality of the full-step, bidirectional baselines of similar or larger size with 20x less inference cost and latency. Further, we integrate our model with audio LLMs and long-form video inference technique Anchor-Heavy Identity Sinks to build LiveTalk, a real-time multimodal interactive avatar system. System-level evaluation on our curated multi-turn interaction benchmark shows LiveTalk outperforms state-of-the-art models (Sora2, Veo3) in multi-turn video coherence and content quality, while reducing response latency from 1 to 2 minutes to real-time generation, enabling seamless human-AI multimodal interaction.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces LiveTalk, a system that can generate talking avatar videos in real time. It listens to a user’s voice or reads text, then creates a video of a face speaking with natural lip movements, expressions, and consistent identity. The big idea is making powerful video AI models much faster so they can be used for live, back-and-forth conversations.
Key Objectives and Questions
The authors wanted to solve these main problems:
- How can we turn slow, high-quality video models into fast, real-time ones without losing visual quality?
- How do we make these models respond to multiple inputs at once—text, a reference image (the avatar’s face), and audio—so the interaction feels natural?
- How can we keep the speaker’s face looking consistent during long conversations (minutes), without the identity drifting or getting blurry?
- Can this real-time system actually beat state-of-the-art models in multi-turn conversations while responding instantly?
How They Did It (Methods and Approach)
What is a diffusion video model?
Imagine starting with a very noisy, blurry video and cleaning it step by step until it looks real. That’s what diffusion models do: they “denoise” frame by frame. The problem is, doing many cleaning steps across all frames makes them slow—often taking 1–2 minutes to make a short clip. That’s too slow for live interaction.
What is distillation?
Distillation is like teaching a quicker “student” model to copy a slower “teacher” model. The student learns to produce high-quality results using fewer steps. Think of it as learning shortcuts without losing detail.
The standard recipe they started from: Self Forcing
- Stage 1: ODE Initialization. The student practices by following the teacher’s denoising path at a few selected steps. This helps the student learn to clean up frames in just a small number of steps.
- Stage 2: On-policy Distillation (DMD). The student generates its own video examples, then compares them to the teacher’s guidance and improves. “On-policy” means training on the student’s own outputs—like practicing with your own answers to get better.
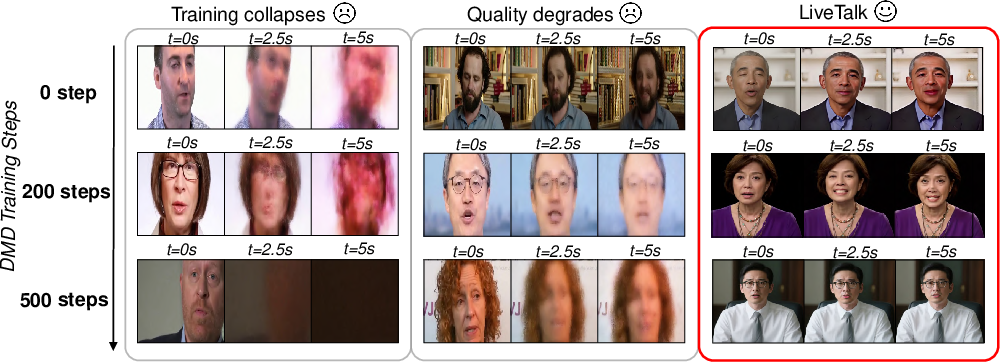
In real life, this can be tricky. If the student makes bad outputs, it can learn the wrong lessons and get worse over time. With text-only inputs, this method worked well. But when the model takes text + image + audio together (multimodal), training became unstable: flickering, black frames, and blurry faces appeared.
The improvements that made it work
To stabilize training and make the real-time model strong under multimodal inputs, the authors made three key upgrades:
- Curate better conditions
- Use a high-quality reference image of the avatar’s face (clear, bright, sharp).
- Refine text prompts to describe motion and expressions (e.g., “speaking clearly with expressive gestures”).
- Keep audio clean and aligned.
- Train the ODE stage to full convergence
- Give the student more time to fully learn the teacher’s denoising steps before moving to the harder, on-policy stage. This creates a solid foundation.
- Learn faster in the short effective window
- Use slightly higher learning rates (train faster) and stronger guidance from the teacher. This helps the student lock in lip-sync and motion quality before training gets unstable.
Building the full LiveTalk system
- The “thinker/talker” is an audio LLM (Qwen3-Omni) that understands the user and speaks back in streaming audio.
- The “performer” is the distilled video model, which takes:
- The streaming audio (for lip movements)
- A reference image (the avatar’s identity)
- A motion-focused text prompt
- It generates video in small blocks (a few frames at a time) with just 4 diffusion steps per block—fast enough for real time.
- Keeping identity stable in long conversations: Anchor-Heavy Identity Sinks (AHIS)
- Think of the model’s attention as a memory. AHIS reserves most of that memory for high-quality “anchor” frames from early in the video (the best-looking samples of the speaker’s face) and uses a smaller part for recent frames.
- This helps the avatar keep its identity consistent for minutes, reducing drift or distortion.
- Parallel pipeline
- While the model is denoising the current block, it decodes the previous one to pixels. This keeps playback smooth and avoids pauses.
Main Findings and Why They Matter
- Real-time speed without big quality loss
- The distilled model reaches about 24.8 frames per second on a single GPU.
- First frame shows up in about 0.33 seconds (down from 83+ seconds in the baseline).
- That’s roughly 20–25× faster throughput and 200–250× lower latency than comparable non-real-time models.
- Quality and lip-sync hold up
- Visual quality and audio-visual sync are comparable to or better than similar-size or even larger models that run much slower.
- Strong in multi-turn conversations
- On a custom benchmark for multi-turn interaction, LiveTalk beat leading models (Sora2 and Veo3) in multi-video coherence and overall content quality.
- It maintains context across turns and responds in real time, making the conversation feel natural.
Why it matters: High-quality video generation usually means waiting a long time. This work shows you can keep the look and sync strong while making it fast enough for live use.
Implications and Potential Impact
- Real-time avatars for education, customer support, entertainment, and accessibility
- Imagine talking to a historical figure avatar in class, getting instant help from a brand’s representative, or having a personal assistant who responds with both voice and face naturally—without delays.
- Lower costs and wider access
- Faster models mean less computation time and energy, so more people and apps can use them.
- Better research recipes for multimodal training
- The paper offers a practical, repeatable recipe to turn slow multimodal diffusion models into fast, stable ones. Future work can build on this for richer control (gestures, emotions, backgrounds) and longer conversations.
- Responsible use
- As realistic avatars become common, it’s important to consider consent, deepfake risks, watermarking, and clear disclosure so people know when they’re talking to an AI.
In short: LiveTalk shows how to make high-quality, multimodal talking avatars run in real time, keep identity consistent, and hold natural, multi-turn conversations—opening the door to truly interactive AI experiences.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a concise list of unresolved issues and concrete directions for future work that emerge from the paper.
- Generalization beyond talking avatars: The approach is only validated on face-centric, audio-driven avatar generation; it remains unclear how the distillation recipe and system perform on non-avatar videos (e.g., full-body motion, multi-person scenes, camera motion, complex environments).
- Resolution and duration scaling: Performance, stability, and latency are reported at 512×512 and short clips; the trade-offs and failure modes at higher resolutions (e.g., 1024×1024) and longer durations (minutes-scale) are untested.
- Block size and step count trade-offs: The chosen block size (b=3) and 4-step denoising are fixed; there is no systematic exploration of how these choices affect audio-visual sync, flicker, temporal coherence, and throughput, nor guidance on optimal settings per task.
- On-policy DMD stability under multimodal conditioning: The paper identifies a “peak-then-degrade” learning window but does not provide a principled analysis of instability causes (critic-generator coupling, modality-specific gradients) or propose stabilization techniques (regularization, gradient penalties, adaptive noise schedules, robust critic EMA).
- Modality-specific guidance tuning: Classifier-free guidance (CFG) is tuned mainly to strengthen audio; the optimal per-modality guidance (text, image, audio) and dynamic/adaptive CFG schedules during training/inference remain unexplored.
- Audio condition robustness: The system’s sensitivity to audio SNR, accents, languages, speaking rates, prosody variability, and real-world background noise is not quantified; methods to ensure robust lip-sync under diverse audio conditions are missing.
- Condition curation dependence: The recipe relies on curated, high-quality image/text conditions; how to achieve comparable stability and quality with noisy, low-quality, or misaligned multimodal inputs (without heavy curation) is an open problem.
- Data scale and diversity: Distillation uses ~4k curated conditions from Hallo3/HDTF; the impact of larger, more diverse datasets (poses, lighting, occlusions, demographics) on stability and generalization is not studied.
- Identity preservation quantification: The Anchor-Heavy Identity Sinks (AHIS) method is proposed without quantitative identity metrics (e.g., ArcFace ID similarity over time, color drift measures); optimal sink/rolling KV ratios, window size, and trade-offs with motion consistency are not ablated.
- KV-cache design and memory budget: The long-horizon caching scheme (sink + rolling tokens) lacks analysis of memory footprint, scaling with duration, and failure modes (e.g., stale anchors, overfitting to early identity) under limited GPU memory.
- Streaming audio windowing: Overlapped window sizes, stride, and latency/sync trade-offs are not specified or compared; guidelines for choosing windows under real-time constraints are missing.
- Evaluation metrics coverage: Identity consistency, temporal stability (e.g., jitter, LPIPS-t), head-pose dynamics, and gesture naturalness metrics are absent; relying on FID/FVD and Sync-C/D may overlook avatar-specific artifacts.
- Statistical rigor and variance: Results are averaged over 100 clips; confidence intervals, variance, and statistical significance (especially when claiming parity or superiority to larger baselines) are not reported.
- Multi-turn evaluation reliability: The VLM-as-evaluator (Qwen3-VL-30B) may introduce bias (same model family as the talker); human studies, cross-evaluator triangulation, and calibration/grounding of VLM judgments are missing.
- Baseline comparability: Fairness of multi-turn comparisons to closed systems (Veo3, Sora2) is unclear (prompting, lengths, modalities, memory); reproducible evaluation protocols and raw outputs for independent verification are not provided.
- Theoretical grounding for improved distillation: While empirical improvements are shown (curated conditions, converged ODE, aggressive LR/CFG), a theory explaining why these stabilize multimodal DMD and how to generalize them is absent.
- Portability across model families: The recipe is validated on OmniAvatar/Wan2.1 variants; whether it transfers to other DiT architectures, teachers of different sizes, or non-diffusion teachers is not tested.
- Failure case taxonomy: Visual artifacts (flicker, blurriness, black frames) are noted, but a systematic taxonomy with root-cause analysis and diagnostics (e.g., per-modality attribution, critic prediction error over time) is missing.
- Robust training without collapse: Methods to extend the effective learning window (e.g., rollout filtering, critic pretraining, noise annealing, curriculum over condition complexity, adversarial regularization) are not explored.
- End-to-end system latency accounting: Reported sub-second first-frame latency and per-turn latency lack detailed breakdown (audio generation, video denoising, decoding, I/O); sensitivity to network jitter and device heterogeneity is unknown.
- Safety and misuse: Ethical risks (deepfake misuse, identity spoofing), watermarking, provenance tracking, and opt-out protections for identities are not discussed; mechanisms to detect or prevent malicious usage are absent.
- Personalization and control: Fine-grained control over emotion, expressiveness, head pose, gaze, and gestures via multimodal prompts is not systematically evaluated; adaptability to user-specific style and rapid personalization remains open.
- Multilingual support: The system’s performance across languages (phonetic differences, lip articulation) and cross-lingual prompts is unmeasured; training or inference adaptations for multilingual robustness are needed.
- Noisy or occluded visuals: Robustness to occlusions, extreme head poses, rapid motion, lighting changes, and camera zooms has not been assessed; targeted augmentations or training strategies could be developed.
- Compute and energy footprint: Training/inference hardware, memory usage, and energy cost are not detailed; guidelines for deployment on commodity hardware or edge devices and associated trade-offs are missing.
- Reproducibility details: Architectural changes to enable causal attention/KV caching, exact hyperparameters for ODE and DMD stages, and code paths for AHIS are only briefly described; a full, reproducible recipe with configs and scripts is needed.
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that leverage the paper’s distilled real-time multimodal diffusion model, the LiveTalk system, AHIS identity preservation, and the associated training/inference recipes and benchmark.
- Real-time customer service avatars
- Sectors: software, retail, finance, telecom
- What: Interactive, lip-synced virtual agents that understand user queries (audio/text) and respond as talking-head videos with sub-second latency.
- Tools/products/workflows: LiveTalk SDK or API embedded in web/mobile, WebRTC/SIP integration for call centers, CRM workflow hooks (Zendesk, Salesforce), KV-cache streaming with AHIS to preserve consistent brand identity.
- Assumptions/dependencies: High-quality reference image per “agent,” GPU inference for 24.82 FPS throughput, robust TTS/ASR/LLM (e.g., Qwen3-Omni), safety/misinformation filters, consent and disclosure for synthetic media.
- Live VTubing and virtual influencers
- Sectors: media/entertainment, creator economy
- What: Streamers produce real-time avatar content with low latency and sustained identity coherence across long sessions.
- Tools/products/workflows: OBS/Streamlabs virtual camera plugin; block-wise AR generation with overlapping audio windowing; AHIS to prevent identity drift; prompt templates for emotion/gesture control.
- Assumptions/dependencies: Stable upstream audio, moderation for platform policies, IP/likeness rights.
- E-learning tutors and training explainers
- Sectors: education, enterprise L&D
- What: Interactive course modules and Q&A “talking instructor” that reacts to learner input.
- Tools/products/workflows: LMS plugin (SCORM/xAPI) embedding LiveTalk; batch-to-live switch (scripted explanation → on-demand avatar Q&A); curated motion-focused prompts for clearer pedagogy; multi-turn evaluation benchmark for QA.
- Assumptions/dependencies: Verified content sources; domain-aligned LLM; GPU or cloud API budget; accessibility compliance.
- Real-time media localization and lip-synced dubbing
- Sectors: media/localization, advertising
- What: On-the-fly dubbing with lip movements aligned to the translated speech.
- Tools/products/workflows: Translate-TTS-LiveTalk pipeline; higher teacher-score CFG for stronger audio-visual sync; post-edit review UI; batch inference for back-catalog, streaming for live events.
- Assumptions/dependencies: Cross-lingual phoneme mapping quality; rights for re-voicing and likeness; legal review per market.
- Low-bandwidth telepresence for video calls
- Sectors: communications, remote work
- What: Send audio + a single reference image; reconstruct talking-head video locally with minimal bandwidth.
- Tools/products/workflows: Conferencing plugins (Zoom/Teams virtual camera); rolling KV cache + AHIS to minimize drift; pipeline-parallel denoise/decode to stay ahead of playback.
- Assumptions/dependencies: Local GPU/edge accelerator or efficient cloud; clear disclosure to participants; enterprise compliance.
- Digital greeters and kiosks
- Sectors: hospitality, retail, transportation
- What: Storefront or terminal helpers that converse naturally, answer FAQs, and maintain consistent persona.
- Tools/products/workflows: Embedded kiosk app; FAQ + RAG for domain answers; AHIS for identity reliability; failover to text-only mode on resource constraints.
- Assumptions/dependencies: Noise-robust microphones; network QoS; guardrails for adversarial prompts.
- Daily-life assistants and language partners
- Sectors: consumer apps, education
- What: Personal assistants with face-to-face interaction, pronunciation/lip-reading practice for language learners.
- Tools/products/workflows: Mobile companion app; prompt styles for articulation; Sync-C/D monitoring to track lip-sync quality; benchmark-driven regression tests across versions.
- Assumptions/dependencies: User consent for avatar personalization; device compute or latency-acceptable cloud.
- Research and benchmarking toolkit
- Sectors: academia, industrial research
- What: Reproducible on-policy distillation recipe for multimodal diffusion; multi-turn interaction benchmark; AHIS as a training-free identity-preservation technique.
- Tools/products/workflows: Open-source code/models; curated condition generation (Qwen-Image, super-resolution) and motion-focused prompts; standardized evaluation (FID/FVD/IQA/ASE + Sync-C/D + VLM-as-evaluator for multi-turn).
- Assumptions/dependencies: Access to teacher models (e.g., OmniAvatar-14B) for score guidance; licensing of LLMs/VLMs; compute for ODE + DMD phases.
- Content pre-visualization and rapid iteration
- Sectors: creative studios, marketing
- What: Quickly iterate talking-head scripts, emotional variations, and call-to-action videos before final production.
- Tools/products/workflows: Prompt banks for expressions/gestures; batch generation at 4 steps; editorial review loops; asset library of reference identities with AHIS presets.
- Assumptions/dependencies: Brand approvals; bias/representation checks.
Long-Term Applications
The following require additional research, scaling, safety, or ecosystem development beyond the paper’s current scope.
- Full-body, multi-person, and in-the-wild real-time avatars
- Sectors: entertainment, gaming, social, telepresence
- What: Extend beyond frontal talking-heads to expressive full-body, multi-speaker scenes with camera motion.
- Dependencies: Stronger multimodal control (pose/gesture), long-context temporal stability beyond minutes, improved exposure-bias mitigation for complex scenes, multi-agent KV-memory scheduling, larger curated multimodal datasets.
- On-device and edge deployment (mobile/AR/robotics)
- Sectors: robotics, consumer hardware, energy
- What: Run low-latency interactive avatars on edge devices and AR glasses.
- Dependencies: Quantization/distillation to sub-1B models, hardware acceleration (NPUs), energy-efficient VAE/DiT, memory-efficient KV caching and AHIS variants; thermal constraints; intermittent connectivity.
- Multimodal agents for embodied robotics and service robots
- Sectors: robotics, hospitality, elder care
- What: Robots with human-like visual expression synchronized to speech and context, increasing trust and clarity.
- Dependencies: Robust audio perception in real environments; safety alignment; integration with perception/action stacks; social acceptability and human factors studies.
- Real-time cross-lingual translation with high-fidelity lip synthesis
- Sectors: media, education, diplomacy
- What: Translate speech and synchronize lips to target language phonemes in real time.
- Dependencies: Accurate cross-lingual phoneme-to-viseme mapping; cultural/linguistic nuance control; error-handling UX.
- Personalized tutors and coaches with long-term memory
- Sectors: education, health/wellness
- What: Avatars that remember user history, adapt pedagogy, and maintain consistent persona over months.
- Dependencies: Privacy-preserving memory systems, federated learning, robust identity preservation across updates, explainability of pedagogy, longitudinal safety protocols.
- Synthetic data generation for vision and speech training
- Sectors: AI/ML tooling
- What: Create large-scale, diverse, rights-managed talking-head datasets to train recognition, ASR, lip-reading.
- Dependencies: Proven domain transfer benefits; watermarking/provenance; de-biasing pipelines; licensing frameworks.
- Advanced controllability and editing
- Sectors: creative tools, advertising, film
- What: Fine-grained control over emotion, style, gaze, co-speech gesture, timing; interactive editing during streaming.
- Dependencies: Richer conditioning signals, reinforcement learning from user feedback, stable on-policy training with more controls, standardized gesture/emotion taxonomies.
- Standards, safety, and policy infrastructure
- Sectors: policy/regulation, trust & safety
- What: Disclosure requirements, content provenance (e.g., C2PA), robust watermarking for video diffusion, deepfake detection, consent management for likeness.
- Dependencies: Broad industry and regulator coordination; interoperable metadata standards; legal frameworks for identity rights and redress.
- Enterprise-grade compliance and risk controls
- Sectors: finance, healthcare, government
- What: Audit trails, content moderation, PII handling, bias/fairness audits, SOC2/ISO controls for avatar deployments.
- Dependencies: Domain-specific datasets and tests (e.g., medical/financial), model cards and incident response procedures, red-teaming of multimodal agents.
- Next-generation distillation and stability methods
- Sectors: AI research, platforms
- What: More robust on-policy methods for complex multimodal conditioning; 1–2 step video diffusion at high fidelity; generalized identity-preserving caches beyond AHIS.
- Dependencies: Theoretical understanding of critic–generator coupling in DMD, curriculum over conditions, adaptive CFG, automated condition curation, better failure detection/recovery during training.
- Multi-party, multi-turn collaborative meetings with avatars
- Sectors: enterprise collaboration
- What: Real-time, multi-avatar conversations with shared context, memory, and turn-taking visuals.
- Dependencies: Scalable KV scheduling across participants, dialogue-state tracking over long horizons, UI/UX research, network synchronization and QoS guarantees.
Cross-cutting assumptions and dependencies affecting feasibility
- Compute and latency: Achieving 24.82 FPS and sub-second first-frame latency typically requires a capable GPU and the 1.3B distilled model; mobile/edge needs further optimization.
- Condition quality: High-quality reference images and motion-focused prompts are pivotal to stability and fidelity; poor conditions can destabilize training/inference.
- Upstream model stack: Quality of ASR, TTS, and audio-LLM (e.g., Qwen3-Omni) directly affects usability; multilingual performance may vary.
- Rights and compliance: Likeness/IP permissions, disclosure of synthetic media, and content moderation are necessary in many jurisdictions and platforms.
- Safety and trust: Risk of impersonation, misinformation, and bias requires watermarking/provenance, user consent flows, and policy alignment.
- Data and domain shift: Out-of-domain robustness, accents/noisy audio, and diverse demographics require continued evaluation and dataset curation.
- Integration maturity: Productionizing requires SDKs/APIs, monitoring (Sync-C/D, FID/FVD/IQA/ASE), autoscaling, fallback modes, and observability.
These applications map directly to the paper’s contributions: a practical distillation recipe for multimodal diffusion (curated conditions, converged ODE initialization, aggressive DMD schedule), block-wise AR with 4-step sampling for real-time throughput, streaming audio conditioning and pipeline parallelism for stable low-latency playback, and AHIS for long-horizon identity preservation—together enabling deployable, real-time multimodal avatar systems.
Glossary
- Anchor-Heavy Identity Sinks (AHIS): A training-free KV-cache strategy that dedicates a large fraction of attention memory to early high-fidelity frames to preserve speaker identity over long generations. Example: "we introduce a training-free technique, the Anchor-Heavy Identity Sinks (AHIS), which successfully keeps the generated speaker visually undistorted on a time scale of minutes."
- ASE: An aesthetics metric for evaluating visual appeal/esthetic quality of generated videos. Example: "we employ FID~\cite{fid}, FVD~\cite{fvd}, IQA~\cite{qalign}, and ASE~\cite{qalign} to assess visual quality and aesthetics"
- attention sinks: Special tokens stored in the KV cache to attract attention and stabilize long-context generation. Example: "we allocate part of the KV cache as attention sinks~\cite{xiao2024efficientstreaminglanguagemodels}"
- autoregressive (AR): A causal generation paradigm that produces outputs sequentially, conditioning on previously generated content. Example: "convert pretrained, bidirectional, many-step video diffusion models into causal, few-step autoregressive (AR) ones via distillation techniques"
- bidirectional attention: Attention mechanism that allows tokens/frames to attend to both past and future elements during generation/denoising. Example: "the simultaneous denoising of all video frames with bidirectional attention via an iterative process in diffusion models"
- block-wise AR generation: Generating video in small blocks of frames autoregressively to enable streaming with low latency. Example: "through block-wise AR generation."
- block-wise causal attentions: Attention design where each block attends only to permissible causal context (e.g., previous blocks), not future frames. Example: "to obtain a few-step causal student model with block-wise causal attentions"
- classifier-free guidance: A guidance technique that mixes conditional and unconditional scores to control alignment strength with conditions. Example: "Note that, for multimodal conditioning, can be estimated with the classifier-free guidance~\cite{ho2022classifier} strategy using separate scales for various conditions."
- critic: An auxiliary denoising score network trained to track the generator’s evolving distribution and provide gradients for distribution matching. Example: "a trainable critic , and the training alternates between updating the generator and the critic ."
- Diffusion transformers (DiTs): Transformer-based diffusion models that denoise in the latent/pixel space using attention architectures. Example: "Diffusion transformers (DiTs)~\cite{peebles2023scalable, brooks2024video, wan2025wan, chen2025hunyuanvideo} have enabled appealing visual fidelity for video generation."
- Distribution Matching Distillation (DMD): An on-policy distillation method that matches the student’s rollout distribution to the teacher via score-based objectives. Example: "Distribution Matching Distillation (DMD) then addresses the exposure bias~\cite{yin2024one, yin2024improved, yin2025slow} of the model after ODE initialization"
- EMA (exponential moving average): A parameter-averaging technique to stabilize training and evaluation of models. Example: "with EMA decay 0.99."
- exposure bias: The mismatch where a model trained on ground-truth trajectories performs poorly when conditioned on its own imperfect outputs. Example: "to minimize exposure bias~\cite{ning2023elucidating, schmidt2019generalization, huang2025self} from causality based on on-policy rollouts."
- FID: Fréchet Inception Distance; a metric assessing similarity between generated and real image distributions. Example: "we employ FID~\cite{fid}, FVD~\cite{fvd}, IQA~\cite{qalign}, and ASE~\cite{qalign}"
- FVD: Fréchet Video Distance; a metric assessing distributional similarity for videos, capturing temporal quality. Example: "we employ FID~\cite{fid}, FVD~\cite{fvd}, IQA~\cite{qalign}, and ASE~\cite{qalign}"
- IQA: Image quality assessment metric used to gauge perceptual quality of generated frames. Example: "we employ FID~\cite{fid}, FVD~\cite{fvd}, IQA~\cite{qalign}, and ASE~\cite{qalign}"
- KV cache: Key–value attention cache that stores past attention states for efficient autoregressive inference. Example: "Clean KV cache from previous blocks is prefilled for visual consistency"
- latent frames: Video frames represented in a compressed latent space (e.g., VAE latents) rather than pixels. Example: "Each block (3 latent frames) undergoes 4-step diffusion"
- lip-sync: The alignment between generated mouth movements and the driving audio. Example: "Our model generates temporally coherent video with natural facial expressions, accurate lip-sync to the audio conditions"
- mode collapse: A failure mode where the generator produces limited or degenerate outputs, losing diversity/quality. Example: "potentially triggering mode collapse~\cite{ge2025senseflowscalingdistributionmatching}"
- multimodal conditioning: Guiding generation with multiple modalities (e.g., text, image, audio) simultaneously. Example: "Self Forcing can result in extensive visual artifacts ... for the multimodal setting"
- ODE initialization: A distillation stage that trains the student to match sparse teacher ODE trajectories, providing a strong starting point. Example: "an initialization stage based on ODE trajectory distillation ... to obtain a few-step causal student model"
- on-policy distillation: Distillation where the student is trained on its own rollouts rather than teacher-forced data to reduce train–test mismatch. Example: "on-policy distillation~\cite{lu2025onpolicydistillation, agarwal2024policy} with self-generated rollouts~\cite{huang2025self}"
- overlapped windowing: A streaming strategy that uses overlapping audio windows to provide sufficient context while maintaining low latency. Example: "Our solution uses overlapped windowing: we encode and generate as soon as a small windowed segment becomes available"
- pipeline parallelism: Running different stages (e.g., denoising and decoding) concurrently to reduce end-to-end latency. Example: "We adopt pipeline parallelism: while the current block undergoes denoising, the previous block is simultaneously decoded."
- prefilling: Populating the KV cache with prior context before generating the next block to improve consistency. Example: "we perform clean KV prefilling across blocks using a sink+rolling token cache"
- rolling tokens: Recent-context KV tokens that evolve over time to carry short-term history for continuity. Example: "rolling tokens carry recent history."
- score network: A model that predicts the score (gradient of log-density) used in diffusion training and distillation objectives. Example: "a frozen teacher score network ~\cite{song2020score,yin2024one,yin2024improved}"
- Self Forcing: A two-stage distillation framework (ODE init + on-policy DMD) for converting bidirectional diffusion into causal few-step AR generation. Example: "Self Forcing~\cite{huang2025self} is one of the most effective approaches, which follows a two-stage procedure."
- sink tokens: Fixed KV entries that persist across time to provide stable anchors (e.g., identity features). Example: "persistent sink tokens retain global context"
- Sync-C/D: Lip-sync metrics from SyncNet measuring correlation (C) and distance (D) between audio and mouth motion. Example: "and Sync-C/D~\cite{syncnet} to measure lip-sync synchronization between the audio condition and the generated lip movements."
- trajectory distillation: Training the student to match teacher denoising trajectories at selected timesteps. Example: "It subsamples timesteps from the teacher's step denoising trajectory ... based on which the causal student is asked to predict clean "
- VAE (variational auto-encoder): A generative model used here as a compression codec to map between pixels and latent frames. Example: "the latent corresponding to video frames yielded by a compression variational auto-encoder (VAE)~\cite{kingma2013auto, rombach2022high}"
- VLM-as-evaluator: Using a vision-LLM as an automatic evaluator for multimodal interaction quality. Example: "We adopt Qwen3-VL-30B-A3B-Instruct~\cite{bai2025qwen2} as the VLM-as-evaluator~\cite{lee2024prometheus}"
- z-score transformation: Normalization method that standardizes scores by mean and standard deviation for fair comparison. Example: "we normalize raw scores for each metric using z-score transformation."
Collections
Sign up for free to add this paper to one or more collections.