LongLive: Real-time Interactive Long Video Generation
Abstract: We present LongLive, a frame-level autoregressive (AR) framework for real-time and interactive long video generation. Long video generation presents challenges in both efficiency and quality. Diffusion and Diffusion-Forcing models can produce high-quality videos but suffer from low efficiency due to bidirectional attention. Causal attention AR models support KV caching for faster inference, but often degrade in quality on long videos due to memory challenges during long-video training. In addition, beyond static prompt-based generation, interactive capabilities, such as streaming prompt inputs, are critical for dynamic content creation, enabling users to guide narratives in real time. This interactive requirement significantly increases complexity, especially in ensuring visual consistency and semantic coherence during prompt transitions. To address these challenges, LongLive adopts a causal, frame-level AR design that integrates a KV-recache mechanism that refreshes cached states with new prompts for smooth, adherent switches; streaming long tuning to enable long video training and to align training and inference (train-long-test-long); and short window attention paired with a frame-level attention sink, shorten as frame sink, preserving long-range consistency while enabling faster generation. With these key designs, LongLive fine-tunes a 1.3B-parameter short-clip model to minute-long generation in just 32 GPU-days. At inference, LongLive sustains 20.7 FPS on a single NVIDIA H100, achieves strong performance on VBench in both short and long videos. LongLive supports up to 240-second videos on a single H100 GPU. LongLive further supports INT8-quantized inference with only marginal quality loss.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces LongLive, a new AI system that can create long, high-quality videos in real time while you guide it with text prompts as it’s generating. Think of it like directing a movie live: you type “a cat walking on the beach,” then later “the cat jumps into a boat,” and the video smoothly follows along without awkward changes or glitches.
What problem is it trying to solve?
Making long videos with AI is hard for two big reasons:
- Quality: When you switch prompts mid-video (for example, changing location or style), the video often looks jumpy or inconsistent. The story can break, styles can clash, and objects might suddenly change or disappear.
- Speed: Long videos require a lot of computation and memory. Many high-quality methods are too slow for real-time use, making users wait a long time.
LongLive aims to be both smooth and fast, even for minute-long videos, and it lets you interact during generation (you can change the prompt while it’s running).
What were the main questions the researchers asked?
- How can we keep long videos consistent (same characters, smooth motion) while allowing live prompt changes?
- How can we make the system fast enough for real-time use, not just short clips?
- How can we train the model so it handles long videos well, instead of doing great on short clips but falling apart on long ones?
How does LongLive work? (Explained with simple ideas)
LongLive uses an “autoregressive” approach. That means it generates videos frame by frame, one after another, using what it already created as context—like writing a story sentence by sentence, using the previous sentences to decide the next one.
Here are the key ideas, explained with everyday analogies:
- KV cache (memory notes): As the model generates frames, it keeps a “notebook” of what happened before (called key–value or KV cache) so it can continue quickly without re-reading the entire story every time. This makes generation fast.
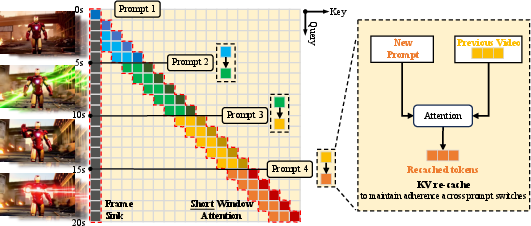
- KV recache (refresh the notes when prompts change): If you switch prompts mid-video, the model’s notebook still has lots of old prompt info. KV recache is like flipping to a fresh page: the model rebuilds its notes using the video frames it already made and the new prompt. This keeps the video smooth but makes it follow your new instructions right away.
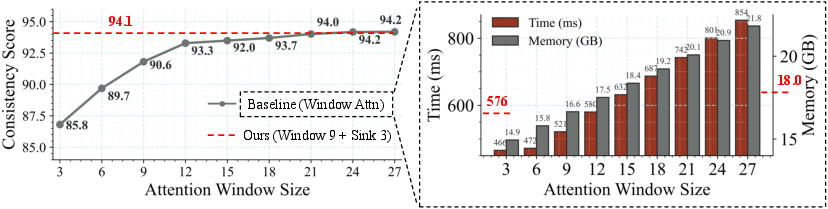
- Short-window attention (focus on the recent past): Looking at every frame ever made is expensive. Instead, the model focuses mostly on the most recent chunk of frames—like paying attention to the last few seconds of the scene rather than the whole movie. This speeds things up.
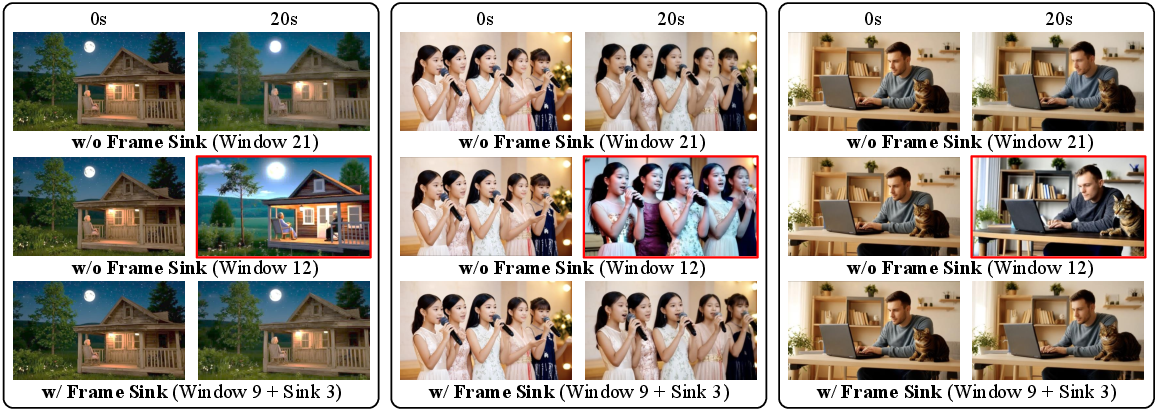
- Frame sink (a permanent anchor): If you only look at the recent past, you might forget important long-term details (like who the main character is or the overall style). A “frame sink” is like a sticky anchor—early frames are kept permanently in memory so the model always has a stable reference. This preserves long-range consistency while keeping speed high.
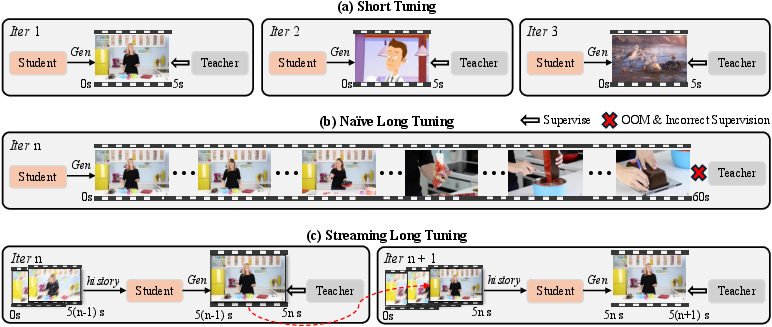
- Streaming long tuning (practice long runs, not just short sprints): Many models are trained only on short clips and then asked to make long videos at test time, which leads to drift and mistakes over time. LongLive trains on long sequences in a rolling, streaming way—just like how it will run in real life. This “train-long–test-long” setup helps it stay stable over minutes, not just seconds.
- Teacher–student guidance without huge datasets: A strong “teacher” model guides the “student” model on shorter clips, repeatedly, while the student stitches these clips into long sequences. This avoids needing a giant dataset of long videos.
- INT8 quantization (make it lighter): The model can run in a compressed format (INT8), which makes it smaller and faster with only a tiny drop in quality—like saving a high-resolution photo to a smaller file size without losing much detail.
What did they find?
- Real-time speed: LongLive runs at about 20.7 frames per second on a single NVIDIA H100 GPU. That’s fast enough for real-time interaction.
- Long duration: It can generate videos up to 240 seconds (4 minutes) on one H100 GPU while staying consistent and high-quality.
- Better prompt switching: KV recache helps the video respond quickly to new prompts without sudden visual jumps, keeping transitions smooth.
- Strong quality: It scores very well on standard video benchmarks (like VBench) for both short and long videos, showing good visual quality, smooth motion, and strong alignment with prompts.
- Efficient training: They fine-tuned a 1.3-billion-parameter model for minute-long videos in about 32 GPU-days, which is quite efficient for research-scale training.
- Smaller model option: With INT8 quantization, the model size drops from about 2.7 GB to 1.4 GB with minimal quality loss.
Why is this important?
- Live storytelling: Creators can direct scenes in real time—adjusting style, characters, and actions on the fly—without the video breaking.
- Practical speed: Because it’s fast, you can use it interactively for creative work, education, streaming, and prototyping.
- Stable long videos: It keeps characters, backgrounds, and motion consistent over minutes, which is crucial for making watchable long-form content.
- Widely useful: The ideas (KV recache, short-window attention, frame sink, train-long–test-long) can help other video AI systems become faster and more reliable, not just this one.
In short, LongLive shows how to make long, interactive AI videos that are both smooth and fast, bringing us closer to real-time, controllable AI filmmaking.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper that future work could address:
- Portability of the proposed KV-recache, short-window attention, and frame-sink mechanisms to other architectures and base models (e.g., diffusion-only, hybrid Diffusion-AR, I2V models) is not evaluated.
- Training includes only one prompt switch per 60-second sequence; the effect of frequent, rapid, or adversarial prompt switches (e.g., dozens per minute) on adherence and continuity is untested.
- Frame-sink tokens fixed to the first frame chunk may preserve outdated style/identity when prompts change; the impact of sinks on prompt-switch compliance—and whether adaptive or prompt-aware sink updates are needed—remains unexplored.
- The choice of sink token count, placement, and update policy (e.g., periodic sinks, per-scene sinks, or dynamic sinks) is not ablated beyond “first frame chunk”; optimal designs are unknown.
- Window size is fixed; content-aware or dynamic window scheduling (e.g., larger window for high-motion or re-entrance scenes) is not studied, nor are policies to trade off adherence vs. consistency on the fly.
- KV-recache granularity is underspecified: whether to rebuild all layers’ K/V caches or only cross-attention K/V, and the optimal subset to recache per switch, is not ablated.
- The latency and memory overhead of KV-recache at scale (as a function of window size W, number of switches n, and sequence length) are not quantified for real-time UX (e.g., ms-per-switch).
- Interaction between frame-sink and KV-recache is not analyzed; sinks may counteract recache during style/identity changes, leading to semantic inertia.
- Long-range dependencies beyond the first frames (e.g., returning to a scene after minutes, episodic callbacks) are not supported by the sink design and are not evaluated; hierarchical/global memory alternatives are untested.
- Failure modes under noisy, contradictory, or rapidly edited streaming prompts (e.g., quick succession of conflicting instructions, negative prompts) are not measured.
- Semantic adherence is lower than Self-Forcing in short-clip VBench (Table 1); the root causes (e.g., short-window constraints, sink bias) and strategies to recover adherence without losing consistency are not analyzed.
- The method is validated at 832×480 and 16 FPS; scaling to higher resolutions (1080p/4K) and higher frame rates (24–60 FPS), and the associated throughput/quality trade-offs, are not studied.
- Maximum tested length is 240 seconds on a single H100; behavior beyond 240 seconds (drift, identity collapse, motion artifacts) and safeguards against very-long-horizon failure are unknown.
- Quantization is reported to cause “marginal quality loss,” but detailed long-horizon metrics (VBench-Long, CLIP per segment), prompt-switch adherence under INT8, and exact throughput/memory gains are not provided.
- Generalization to different hardware (consumer GPUs like RTX 4090/A5000 or multi-GPU inference) is not assessed; memory footprints and FPS on non-H100 devices remain unknown.
- Real-time interaction latency (end-to-end user-perceived delay per frame and at switch) is not reported; the system’s responsiveness under typical UI/network conditions is unquantified.
- The custom interactive evaluation set (160×60s sequences) is not fully described or released; standardized metrics for transition smoothness, semantic lag, and identity preservation across switches are lacking.
- Reliance on a short-clip teacher (DMD) for long-sequence distillation is not stress-tested; effects of teacher bias, misalignment, or failure on long-horizon supervision quality and student robustness are unexamined.
- Training data for prompt-switch scenarios is generated via Qwen; coverage of diverse narratives (multi-character interactions, complex physics, camera choreographies) and out-of-domain generalization are not benchmarked.
- The recache step “encodes the generated prefix as visual context,” but the exact encoding path (latent vs. pixel-space, encoder architecture, cost) and its sensitivity to compression artifacts are not detailed.
- Comparative evaluation against planning-based approaches (e.g., film-structure planners) under matched throughput is absent; the trade-offs between implicit AR memory and explicit temporal planning remain unclear.
- Multi-modality (audio generation, camera trajectory control, depth/segmentation conditioning, 3D scene consistency) is not supported; the feasibility of integrating such controls is not explored.
- Safety, content filtering, and controllable constraints (e.g., avoiding harmful content during interactive generation) are not discussed or evaluated.
- Reproducibility of streaming long tuning (hyperparameters, seeds, window/sink settings) across different datasets and base models—and the stability of convergence—are not reported.
Practical Applications
Immediate Applications
Below are concrete use cases that can be deployed now, leveraging LongLive’s released code/model, real-time causal inference (20.7 FPS on a single H100), KV-recache for smooth prompt switching, short-window attention + frame sink for efficient long-range consistency, streaming-long tuning (train-long–test-long), and INT8 inference.
- Media and Entertainment — Real-time previsualization and live directing
- What: Directors and artists steer long sequences with a “prompt timeline,” inserting style/scene changes on the fly while maintaining visual continuity via KV-recache.
- Tools/products/workflows: “Director’s Console” (timeline prompt editor), NLE plugin (Premiere/DaVinci/Resolve) that adds time-coded prompt tracks and preview; video super-resolution step (e.g., RTX/VSR) to upscale 832×480 outputs for review.
- Assumptions/dependencies: Single-GPU H100 (or cloud), latency budgets, content moderation; upscaling for production review; license/usage terms of the released model.
- Live Events and Broadcast — Interactive stage/backdrop visuals
- What: VJs and event producers morph visuals in sync with music cues or audience inputs; frame-sink maintains long-range coherence despite frequent prompt changes.
- Tools/products/workflows: “VJ Live Gen” app with MIDI/OSC cue binding; OBS/NDI integration; cue sheets mapped to prompt switches using KV-recache.
- Assumptions/dependencies: Reliable GPU on-site or low-latency cloud link; safety filters to avoid unsafe or IP-sensitive generations.
- Advertising and Growth — Rapid creative iteration and personalization
- What: Generate long-form ad variants with controllable segment themes (brand, product, CTA) and smooth transitions; A/B testing by swapping prompt segments.
- Tools/products/workflows: “Prompt-Track Ad Generator” that ingests a storyboard and exports multi-variant long videos; post-chain upscalers; brand style loras or prompt libraries.
- Assumptions/dependencies: Brand safety review; approval workflow; dataset/style constraints to avoid IP violations; cloud serving costs.
- Education — Teacher-steered explainer videos
- What: Instructors drive visuals during a lesson (e.g., change scenes to illustrate concepts) while preserving subject continuity; supports minute-long sequences at interactive rates.
- Tools/products/workflows: “Lesson Visualizer” classroom plugin (timeline prompts mapped to the syllabus), LMS integration; semantic prompt library for curricula.
- Assumptions/dependencies: Factual accuracy is not guaranteed (use as illustrative B-roll, not authoritative depictions); moderation; GPU or cloud access.
- Game Development — Cutscene prototyping and dynamic background generation
- What: Rapidly block out long cutscenes with in-editor prompt tracks; designers can switch style/mood mid-sequence with smooth handoffs using KV-recache.
- Tools/products/workflows: Unity/Unreal plugin streaming frames as textures; “Prompt Sequencer” track in Timeline/Sequencer; optional handoff to artists for final assets.
- Assumptions/dependencies: Engine plugin integration; 480p baseline output (use upscaling for previews); not a replacement for final production assets.
- Computer Vision R&D — Long-horizon synthetic data generation
- What: Create long, consistent sequences for evaluating/training tracking, re-ID, long-term consistency metrics; prompt switches stress-test identity/background persistence.
- Tools/products/workflows: “LongStream Data Forge” with scripted prompt transitions; automatic slicing and annotation hooks; VBench/VBench-Long scoring loop.
- Assumptions/dependencies: Domain gap to real-world data; automated labeling remains nontrivial; quality metrics ≠ downstream model performance guarantees.
- MLOps/Inference Engineering — Cost-efficient serving recipes
- What: Productionize streaming T2V with short-window attention, frame sink, and INT8; predictable memory footprint and higher throughput per GPU.
- Tools/products/workflows: Triton/TensorRT/TorchServe deployment; “Timeline-conditioned Generation API” (start/append/switch endpoints); autoscaling and prompt-logging for auditing.
- Assumptions/dependencies: H100 or comparable accelerators; quantization calibration; throughput/cost trade-offs vs. latency SLOs.
- Academic Repro and Extensions — Train-long–test-long recipe
- What: Use the open-source streaming-long tuning loop to align training and inference for other AR video models; ablate window size and sink strategies.
- Tools/products/workflows: “LongStream Trainer” library; teacher–student distillation with rolling KV reuse; evaluation via VBench-Long and CLIP segment scores.
- Assumptions/dependencies: Access to a competent teacher for short clips; ~32 GPU-days for fine-tuning reference; careful memory management to avoid OOM.
Long-Term Applications
These require further research, scaling, or ecosystem development (e.g., higher resolution, multi-modal coherence, hardware/compute efficiency, policy readiness).
- Virtual Production at Broadcast/Film Quality (4K, multi-minute, photoreal)
- What: Real-time, audience-steered long videos for virtual sets and LED volumes; on-the-fly scene/style changes with continuity.
- Needed advances: Higher resolution and photorealism, temporal stability under fast camera motion, multi-view consistency; multi-GPU/cluster streaming; integrated denoising/upscaling.
- Dependencies: Content provenance/watermarking; IP/licensing/union rules; robust moderation.
- On-Device AR/VR Generation
- What: Edge generation for glasses/phones/headsets to render adaptive long scenes locally.
- Needed advances: Further compression (beyond INT8), distillation, sparsity; custom accelerators; thermal/energy-aware scheduling; sub-50 ms interaction loops.
- Dependencies: Mobile-class NPU support; model safety and offline guardrails.
- Interactive TV/Games — Audience-steered narratives
- What: Live shows or games where viewers switch story branches via prompts; KV-recache ensures smooth continuity between branches.
- Needed advances: Guardrails for harmful content, latency guarantees at scale, scalable multi-tenant serving, IP-safe style controls.
- Dependencies: Moderation policies; platform UX for real-time prompt control.
- Enterprise-Scale Personalization (Ads, Training, Comms)
- What: Personalized long-form assets (training modules, onboarding, compliance) auto-planned by LLMs into prompt timelines with smooth transitions.
- Needed advances: Script-to-prompt planners, factuality constraints, visual identity locking (characters, brand assets) across long horizons.
- Dependencies: Governance for accuracy and disclosure; auditing for prompt provenance and edits.
- Synthetic Data at Scale for Robotics/Autonomous Systems
- What: Long, diverse, controllable scenarios to train/evaluate long-horizon perception/planning.
- Needed advances: Physics grounding, controllable agents and dynamics, object permanence under occlusion, closed-loop simulation; labels/annotations.
- Dependencies: Tooling for scenario control; alignment with simulator standards; validation of transfer to real-world performance.
- Multi-Modal Co-Generation (Video+Audio+Speech+FX)
- What: One-pass story engine that generates video with synchronized narration, SFX, and music while supporting prompt updates.
- Needed advances: Cross-modal KV-recache, alignment of beat/phoneme with visual events, lip-sync, latency-aware co-synthesis.
- Dependencies: Rights for model voices/music; safety and copyright filters.
- Creative Co-Pilots — Script/Storyboard to Long Video
- What: LLM-based planners convert scripts into time-aligned prompt tracks; LongLive executes with high continuity; iterative refinement via human-in-the-loop.
- Needed advances: Robust script parsing, temporal reasoning, style/asset libraries, automatic transition planning to minimize semantic shock.
- Dependencies: Toolchain integration (Final Draft, Celtx); asset licensing; creator control.
- Methodological Transfer — KV-recache and Frame Sink in Other Streams
- What: Apply “cache refresh” and global-sink tokens to other streaming generative modalities (audio, 3D, diffusion hybrids) and instruction-updatable LLMs.
- Needed advances: Cross-attention/cache semantics for multi-modal architectures, stability proofs/heuristics for long-context rollouts.
- Dependencies: Architectural compatibility (e.g., DiT-like blocks), evaluation protocols for long-form coherence.
- Policy and Standards — Provenance, Watermarking, and Auditability
- What: Standardize disclosure and provenance (C2PA-style) for interactive long-generation; “prompt-switch logs” for transparency.
- Needed advances: Robust watermarking for long videos with prompt-segment metadata; platform APIs for audit trails.
- Dependencies: Industry alignment, regulatory guidance, interoperability with content platforms.
Notes on feasibility and constraints across applications:
- Hardware: Reported real-time rates (20.7 FPS) are on an NVIDIA H100 at 832×480; consumer GPUs will be slower. Upscaling pipelines are often needed for production quality.
- Cost/latency: Cloud deployment and multi-user scaling require careful MLOps (autoscaling, KV reuse, quantization) and guardrails.
- Quality/safety: VBench/CLIP metrics do not guarantee factual accuracy or safety; human review and moderation are essential for many sectors.
- IP/data: Training data licenses, brand/likeness rights, and content provenance must be respected; watermarking/logging should be part of workflows.
- Generalization: KV-recache and frame sink are architectural techniques that should transfer to related AR/DiT systems, but require validation per model.
Glossary
- Ablation study: A controlled comparison to isolate the effect of a specific component or setting in the system. "Ablation study on KV recache."
- Attention-sink tokens: Special persistent tokens kept in the attention cache to act as global anchors, stabilizing long-range consistency during generation. "Prior work reported that attention-sink tokens alone do not prevent long-rollout collapse in video models"
- Autoregressive (AR): A generative modeling approach that predicts the next element (e.g., frame) based on previously generated elements in a causal manner. "a frame-level autoregressive (AR) framework for real-time and interactive long video generation."
- Bidirectional attention: An attention mechanism that attends to both past and future positions, increasing computation and preventing cache reuse in generation. "suffer from low efficiency due to bidirectional attention."
- Causal attention: An attention mechanism restricted to past positions only, enabling efficient autoregressive generation and KV caching. "LongLive is a causal attention, frame-level AR video generation model"
- CLIP score: A text–visual similarity metric computed using the CLIP model to measure semantic alignment of generated content with prompts. "CLIP scores are reported on 10s video segments with the same semantics"
- Cross-attention: An attention operation where queries from one modality/stream (e.g., video tokens) attend to keys/values from another (e.g., prompt embeddings). "cross-attention and self-attention layers alternate."
- Chunk-wise prediction: Generating sequences in fixed-size chunks rather than frame-by-frame, often used to scale training and inference. "MAGI-1 scales AR video generation to large models and datasets through chunk-wise prediction"
- DiT (Diffusion Transformer): A transformer-based architecture tailored for diffusion models that interleave self- and cross-attention layers. "In DiT architectures, cross-attention and self-attention layers alternate."
- DMD: A distillation technique used to supervise a student generator using a teacher diffusion model on short clips. "we apply DMD on this short clip."
- Distillation: Training a student model to match the outputs or behaviors of a teacher model for improved performance or efficiency. "and (iii) in distillation, feed the teacher model with the new prompt as well"
- Diffusion-Forcing models: Hybrid methods that couple diffusion generation with autoregressive prediction or conditioning to improve efficiency or control. "Diffusion and Diffusion-Forcing models can produce high-quality videos but suffer from low efficiency due to bidirectional attention."
- Frame sink: A frame-level attention sink that keeps a fixed set of early frame tokens globally attendable to preserve long-range consistency under local attention. "frame-level attention sink (abbreviated as frame sink)"
- GPU-days: A measure of training compute equal to the number of GPUs multiplied by the number of days used. "minute-long generation in just 32 GPU-days."
- INT8-quantized inference: Running a model with 8-bit integer weights/activations to reduce memory and improve speed with minimal quality loss. "LongLive further supports INT8-quantized inference with only marginal quality loss."
- Key–value (KV) states: The stored keys and values from attention layers that can be cached and reused to accelerate autoregressive inference. "refresh the cache by recomputing keyâvalue states conditioned on the preceding frames and the new prompt."
- KV cache: A per-layer cache of key–value states used to avoid recomputation and speed up autoregressive decoding. "rolling out generation with KV cache"
- KV recache: Refreshing the KV cache at prompt-switch boundaries using recent frames and the new prompt to remove residual semantics while keeping visual continuity. "we introduce KV recache."
- Latent frames: Frames represented in a compressed latent space used internally by the model for attention and generation. "Window 21 latent frames"
- Local window attention: Attention restricted to a fixed recent temporal window, reducing computation and memory while focusing on nearby frames. "we adopt local window attention during inference"
- Out-of-memory (OOM): A failure mode when GPU memory is exhausted during training or inference on long sequences. "naïvely unrolling and backpropagating through long sequences easily triggers out-of-memory (OOM) issues"
- Prompt inertia: The tendency of a generator to continue following the previous prompt after a switch, delaying or weakening adherence to the new prompt. "Retaining the cache preserves continuity but induces prompt inertia: the model sticks to the previous prompt"
- Rollout: The sequential process of generating frames over time, feeding model outputs back as context. "As the rollout continues, small prediction errors accumulate"
- Self-attention: An attention operation where sequence elements attend to each other within the same modality/stream. "cross-attention and self-attention layers alternate."
- Short window attention: A specific local-window attention setup that uses a smaller temporal window to significantly accelerate generation. "we introduce \underline{short window attention} combined with a frame-level attention sink"
- Streaming long tuning: A training procedure that extends generation clip-by-clip on long sequences, reusing cached context and supervising each new clip. "we introduce a streaming long tuning procedure"
- Semantic coherence: The consistency and alignment of meaning and prompt semantics across frames and during transitions. "ensuring visual consistency and semantic coherence during prompt transitions."
- Temporal locality: The property that nearby frames carry most of the predictive information for the next frame in video generation. "Motivated by evidence of temporal locality in video generation"
- Train-long–test-long: Training on long sequences to align with inference conditions and reduce degradation over long horizons. "to align training and inference (train-longâtest-long)"
- VBench: A benchmark suite for evaluating video generation quality and semantic alignment. "achieves strong performance on VBench in both short and long videos."
- VBench-Long: The long-horizon variant of VBench focused on consistency and quality over extended durations. "We evaluate longliveâs single-prompt long-video generation on VBench-Long"
- Window attention: An attention scheme that limits the receptive field to a temporal window rather than the entire sequence. "StreamDiT trains a diffusion model with window attention"
Collections
Sign up for free to add this paper to one or more collections.

