PersonaLive! Expressive Portrait Image Animation for Live Streaming
Abstract: Current diffusion-based portrait animation models predominantly focus on enhancing visual quality and expression realism, while overlooking generation latency and real-time performance, which restricts their application range in the live streaming scenario. We propose PersonaLive, a novel diffusion-based framework towards streaming real-time portrait animation with multi-stage training recipes. Specifically, we first adopt hybrid implicit signals, namely implicit facial representations and 3D implicit keypoints, to achieve expressive image-level motion control. Then, a fewer-step appearance distillation strategy is proposed to eliminate appearance redundancy in the denoising process, greatly improving inference efficiency. Finally, we introduce an autoregressive micro-chunk streaming generation paradigm equipped with a sliding training strategy and a historical keyframe mechanism to enable low-latency and stable long-term video generation. Extensive experiments demonstrate that PersonaLive achieves state-of-the-art performance with up to 7-22x speedup over prior diffusion-based portrait animation models.




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces PersonaLive, a way to make a still portrait (a single picture of a person) come to life as a moving, expressive video—fast enough to use during live streaming. It focuses on keeping the face realistic, the movements natural, and the video smooth, all while cutting down the time it takes to generate each frame.
Key Objectives
The researchers set out to solve three simple problems:
- How can we make portrait animations look great and feel expressive, but still run in real time for live streaming?
- How can we control both facial expressions (like smiles or eyebrow raises) and head movement (like turning or nodding) in a natural way?
- How can we generate long videos without the quality slowly getting worse over time?
Methods and Approach
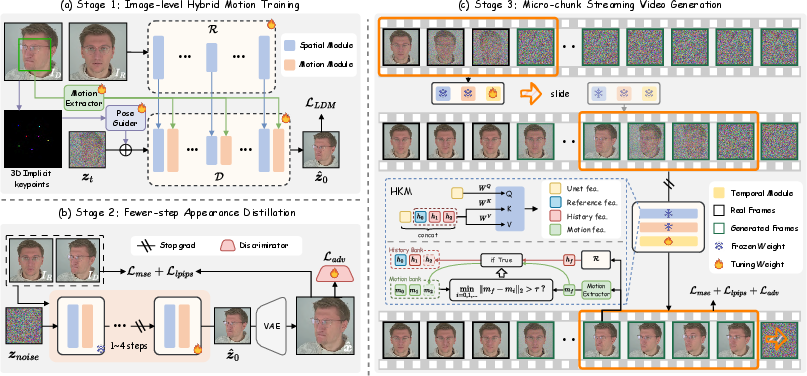
Think of PersonaLive as a smart animation pipeline with three main parts:
1) Hybrid Motion Signals: “Instructions” for expression and head movement
- The system uses two types of motion clues:
- Implicit facial representations: a compact “code” that captures subtle facial expressions.
- 3D keypoints: important points on the face in 3D that tell the system how the head turns, moves, and scales.
- Analogy: It’s like giving an artist two sets of instructions—one for detailed expressions (smiles, frowns) and one for head pose (tilt, turn)—so the final animation feels lifelike.
2) Fewer-Step Appearance Distillation: Doing the same job with fewer steps
- Diffusion models normally “clean up” noise step by step to make a clear image. The team noticed that, for portrait animation, the structure and motion are figured out early, and many later steps are just slow polishing.
- They trained the model to skip unnecessary polishing while keeping the look sharp and realistic.
- Analogy: If you’re polishing a sculpture, once the shape is perfect, you don’t need to spend forever buffing—just enough to look great.
3) Micro-Chunk Streaming: A steady “conveyor belt” for live video
- Instead of processing long videos in big chunks (which can cause delays and glitches at the boundaries), the model breaks the video into tiny groups of frames called “micro-chunks.”
- It processes these with a sliding window—like an assembly line—so new frames are ready quickly and smoothly.
- To keep long videos stable, they add:
- Sliding Training Strategy: During training, the model practices on its own predictions, not just perfect examples. This helps it avoid mistakes piling up later.
- Historical Keyframe Mechanism: The system keeps a “memory” of important past frames to keep the look consistent (no sudden changes in skin texture, clothes, or lighting).
- Motion-Interpolation Initialization: It smoothly blends from the reference photo’s default look to the driving video’s motion at the start, avoiding a jumpy first few frames.
Main Findings and Why They Matter
Here are the key results, explained simply:
- Fast: PersonaLive runs at about 15.82 frames per second with around 0.25 seconds of delay, which is fast enough for live streaming. With a lighter decoder (TinyVAE), it can reach ~20 FPS.
- High quality: Even with fewer steps, the animations keep identity (they still look like the person), preserve detailed expressions, and stay sharp.
- Stable over time: Long videos stay smooth and consistent—fewer glitches, less “drift” in appearance or motion.
- Big speedup: It’s up to 7–22× faster than many earlier diffusion-based portrait animation methods.
Why this matters: Live streamers, VTubers, and apps that use digital avatars need animations that look great and respond quickly. PersonaLive makes that practical.
Implications and Impact
PersonaLive could make virtual avatars more usable for:
- Live streaming and VTubing: Real-time, expressive faces without expensive motion-capture gear.
- Video calls and virtual presenters: More natural digital identities for privacy or fun.
- Games and customer support: Fast, lifelike face animation on everyday hardware.
The authors also note two limitations and future directions:
- The system doesn’t yet fully take advantage of repeated similarity between nearby frames (temporal redundancy), which could make it even faster.
- It’s trained mostly on human faces, so it can struggle with non-human characters (like animals or cartoons), sometimes causing blurry or distorted features.
Overall, PersonaLive shows that you can have both speed and quality for live portrait animation, opening the door to more responsive and engaging digital experiences.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, framed to guide future research:
- Explicit exploitation of temporal redundancy across consecutive frames is absent; investigate recurrent/cached feature reuse, partial denoising, and incremental updates to reduce per-frame computation and extend denoising windows.
- Robustness to extreme motions (large yaw/pitch/roll), occlusions (hands/microphones), rapid head translations, and self-shadowing is not systematically evaluated; establish stress-test benchmarks and failure analyses under these conditions.
- Generalization beyond human faces is limited; develop domain adaptation or multi-domain training (cartoon/anime/animals), geometry-aware retargeting, or hybrid explicit–implicit shape models to handle non-human morphologies.
- Scalability to higher resolutions (720p/1080p/4K) and impact on latency, memory footprint, and stability are untested; characterize speed–quality trade-offs and optimize the pipeline for HD streaming.
- Real-time performance is only reported on a single NVIDIA H100; profile and optimize on commodity GPUs (e.g., RTX 3060/4060), integrated GPUs, mobile SoCs, and CPUs, including quantization/Pruning and memory usage reporting.
- Long-term stability is demonstrated on ~minute-long videos; quantify drift/identity preservation over tens of minutes to hours, and define metrics/criteria for “indefinite” streaming without collapse.
- Micro-chunk scheduling (number of micro-chunks N, noise levels tₙ, window size M) is underexplored; systematically study schedules (linear/cosine/exponential), adaptive scheduling, and their effects on temporal coherence, identity, and latency.
- Historical Keyframe Mechanism lacks analysis of threshold sensitivity (τ), bank size/eviction policy, feature fusion strategy, and runtime overhead; evaluate how these choices affect identity drift, stability, and speed.
- Sliding Training Strategy has no theoretical or empirical characterization of exposure-bias mitigation beyond ablations; analyze training–inference distribution mismatch quantitatively and explore curriculum/self-correction variants.
- The “appearance redundancy” hypothesis motivating fewer-step distillation is not quantified; measure per-step contributions to structure vs. texture, and validate across different backbones and datasets.
- Distillation is not compared against established few-step accelerators (LCM, DMD/DMD2, Self-/Diffusion Forcing) on the same portrait tasks; perform head-to-head comparisons and combine methods where complementary.
- Reliance on adversarial loss to recover detail without CFG raises training stability questions; characterize artifacts/mode collapse risks and explore discriminator designs, regularization, or perceptual priors that maintain identity fidelity.
- Sensitivity to the 3D keypoint estimator’s errors and cross-identity morphology mismatch (e.g., scale calibration, face shape differences) is not analyzed; incorporate calibration, retargeting, or learned canonicalization to reduce misalignment artifacts.
- Motion-Interpolated Initialization (MII) is underspecified; formalize the interpolation schedule, compare interpolation families, and test robustness when the reference and driving motions are highly dissimilar.
- Temporal module choice is narrow (AnimatedDiff-style integration); benchmark alternative temporal architectures (memory tokens, causal transformers, recurrent modules) and attention patterns for streaming constraints.
- Identity preservation metrics rely on ArcFace; assess metric bias across demographics, large poses, and occlusions, and complement with additional recognizers and human perceptual studies.
- Dataset diversity and fairness (age, skin tone, gender, accessories, lighting) are not quantified; audit training/testing distributions and report subgroup performance to identify systematic biases.
- Safety and misuse are not addressed; explore watermarking, provenance tracking, or real-time deepfake detection compatible with streaming generation.
- Streaming overhead from the historical keyframe and motion banks (feature extraction, storage, concatenation) is not reported; instrument and optimize for low-latency constraints.
- Impact of TinyVAE vs. standard VAE on detail fidelity, identity, and temporal stability is only briefly mentioned; perform a thorough trade-off analysis and consider lightweight decoders tailored to faces.
- Control dimensions remain limited to facial dynamics and head motion; expand to audio-driven lip-sync, text prompts for emotion/intensity, or fine-grained controls (eye gaze, eyelid blinks) with latency-aware conditioning.
- Multi-person/multi-view or full upper-body animation is not supported; extend hybrid motion signals and conditioning to handle torso/hands and multi-camera/view consistency.
- The LV100 benchmark details (availability, licensing, annotation, protocols) are unclear; release a standardized, long-form evaluation suite to foster reproducible streaming portrait research.
Practical Applications
Below is an overview of practical, real-world applications that follow from PersonaLive’s findings and innovations (hybrid motion control with implicit facial signals + 3D keypoints, fewer-step appearance distillation, and micro‑chunk streaming with sliding training and historical keyframes). Items are grouped by deployment horizon and note sector fit, potential products/workflows, and key feasibility dependencies.
Immediate Applications
The following can be deployed with current capabilities (real‑time, low‑latency, human‑face domain at 512×512, 4 denoising steps, H100-class performance).
- Bold VTubing and live-creator avatars (Media/Entertainment)
- What: Real-time, expressive portrait animation for Twitch/YouTube/TikTok creators with stable long-form streams and low latency.
- Product/Workflow: OBS/WebRTC plugin or SDK that takes a single portrait as reference + webcam as the driving stream; server or on-device inference; leverage historical keyframes for consistent looks across multi-hour streams.
- Assumptions/Dependencies: GPU inference (paper reports 15.8–20 FPS on H100; consumer GPUs will be slower), face-centric framing and in-distribution lighting/poses, appropriate licensing for motion/keypoint extractors.
- Bold Customer support and sales avatars (Enterprise CX; Retail/E‑commerce)
- What: Live agents represented by consistent brand personas in video chats or website widgets, preserving agent privacy while conveying expressions and head movement.
- Product/Workflow: Web SDK integrated into chat platforms; backend GPU service generating avatar video from agent webcam; optional identity anonymization via a standard brand portrait.
- Assumptions/Dependencies: WebRTC latency budgets, enterprise security/compliance, organizational acceptance of avatar-mediated support.
- Bold Video conferencing “persona” mode (Software/Communications)
- What: Replace the user’s video with a professional headshot animated in real time for meetings (privacy, bandwidth, and presentation benefits).
- Product/Workflow: Plug-ins for Zoom/Teams/Meet; micro‑chunk streaming minimizes lag and chunk boundary artifacts; initial Motion-Interpolated Initialization avoids cold-start artifacts.
- Assumptions/Dependencies: Platform integration support, GPU/edge inference, user consent and disclosure.
- Bold Live e-commerce and marketing spokes-avatars (Marketing/Advertising)
- What: Brand ambassadors that react naturally to a presenter’s motions in live commerce and product demos with low-latency identity-consistent visuals.
- Product/Workflow: Branded reference portrait + presenter’s webcam; cloud service for live campaigns; consistent identity via historical keyframes over long sessions.
- Assumptions/Dependencies: Brand safety and disclosure policies; GPU capacity for peak audiences.
- Bold Face anonymization overlays for journalists/whistleblowers (Policy/Public Interest; Daily Life)
- What: Real-time replacement of a person’s appearance with a generic or chosen portrait while preserving expressions and head pose for communication authenticity.
- Product/Workflow: Secure client-to-server pipeline; driving video remains local or encrypted; only synthesized stream is broadcast/recorded.
- Assumptions/Dependencies: Ethical/legal review, consent, disclosure; risk of misuse if safeguards aren’t in place; quality depends on in-domain human faces.
- Bold Creator post-production acceleration for facial reenactment (Media Production)
- What: Fast, few-step reenactment to align performance across cuts (e.g., talking-head corrections or language-localized segments) without heavy compute.
- Product/Workflow: NLE plug-in (Premiere/Resolve) for batch reenactment using PersonaLive’s 4-step distillation; long takes benefit from micro‑chunk stability.
- Assumptions/Dependencies: Driver video availability (PersonaLive is video-driven; pure audio-driven is out-of-scope), resolution constraints (512×512; upscaling may be needed).
- Bold Virtual receptionists/kiosks (Hospitality/Retail)
- What: On-site screens with expressive avatar faces controlled by remote operators or scheduled content.
- Product/Workflow: Thin client capturing operator webcam + cloud GPU rendering; content scheduling leverages keyframe logging to maintain appearance continuity across sessions.
- Assumptions/Dependencies: Reliable connectivity, privacy posture for operator streams, adequate edge hardware if on-prem.
- Bold Academic research testbed for streaming diffusion (Academia/Software)
- What: A reference implementation to study real-time diffusion, autoregressive micro-chunking, exposure-bias mitigation, and long-term temporal stability.
- Product/Workflow: Reproducible benchmarks (TalkingHead-1KH, LV100), ablations for sliding training and keyframe banks; baseline for new streaming methods.
- Assumptions/Dependencies: Access to training data and pretrained modules (motion extractor, 3D keypoint extractor), compute for fine-tuning.
Long-Term Applications
These require further R&D, domain adaptation, or platform maturation (e.g., broader device targets, regulatory frameworks, non-human domains).
- Bold Audio-driven streaming avatars (Media/Education/Enterprise)
- What: Animate from live speech alone, mapping audio to expressions and lip motion without a driving video.
- Product/Workflow: Integrate an audio-to-expression module upstream of PersonaLive’s motion pathway; maintain micro‑chunk streaming for low latency.
- Assumptions/Dependencies: Robust audio-to-motion models; alignment and phoneme accuracy; retraining to reduce exposure bias under audio-only conditions.
- Bold Mobile/edge deployment at scale (Software/Telecom)
- What: Real-time performance on laptops/mobiles for privacy and cost control.
- Product/Workflow: Aggressive quantization and further step reduction; TinyVAE or similar decoders; hardware acceleration paths (NPUs).
- Assumptions/Dependencies: Model compression (e.g., quantized diffusion), memory constraints, battery/thermal budgets; potential quality trade-offs.
- Bold Non-human/stylized avatar domains (Animation/Gaming/Creative Tools)
- What: High-quality live animation of cartoons, stylized characters, or animal avatars.
- Product/Workflow: Domain-specific datasets and retraining for keypoint/motion encoders; tailored priors for non-human morphology.
- Assumptions/Dependencies: Dataset curation and licensing; method currently struggles with non-human domains (paper limitation).
- Bold AR/VR telepresence with 3D-aware avatars (XR/Robotics)
- What: Expressive avatars in XR meeting rooms or robot faces that reflect user expressions with stable long sessions.
- Product/Workflow: Extend 3D reasoning beyond keypoints; multi-view/head-tracked rendering; combine with spatial audio and gaze models.
- Assumptions/Dependencies: Deeper 3D modeling, latency-critical XR stacks, headset/robot SDK integration.
- Bold Bandwidth-efficient telepresence via motion-stream coding (Communications)
- What: Transmit only hybrid motion embeddings/keypoints and reconstruct video on the receiver side to cut bandwidth.
- Product/Workflow: Client-side motion/keypoint extraction; server or peer-side rendering; adaptive bitrate via variable micro‑chunk noise schedules.
- Assumptions/Dependencies: Standardized motion codecs; synchronization and error recovery; privacy/security for motion data.
- Bold Compliance, disclosure, and watermarking for live synthetic video (Policy/Standards)
- What: Policy frameworks and tooling to disclose synthetic avatars in live settings and deter impersonation.
- Product/Workflow: Real-time watermarking at latent/pixel level; platform UI for disclosure; audit logs of historical keyframes used.
- Assumptions/Dependencies: Regulatory alignment, platform enforcement, robust watermarks that survive re-encoding and streaming.
- Bold Synthetic data generation for training vision models (Academia/AI/Healthcare)
- What: Generate diverse, expression-rich face video datasets for tasks like expression recognition or pose estimation.
- Product/Workflow: Automated pipelines that vary motion inputs and lighting; curate stable long sequences using historical keyframes.
- Assumptions/Dependencies: Bias and realism validation; ensuring that synthetic data improves generalization; licensing of source portraits.
- Bold Healthcare/Telemedicine privacy avatars (Healthcare)
- What: Preserve patient identity while allowing clinicians to read expressions or lip movements.
- Product/Workflow: HIPAA-compliant video pipelines; on-device extraction to protect raw video; clinician portal with visual quality controls.
- Assumptions/Dependencies: Clinical validation, ethics review, accessibility considerations; strong consent management.
- Bold Expressive AI agents (Software/AI assistants)
- What: LLM-based assistants with consistent on-brand faces for contact centers, hospitality, or education.
- Product/Workflow: TTS + audio-to-motion + PersonaLive rendering + micro‑chunk streaming; tools for brand persona management.
- Assumptions/Dependencies: End-to-end latency control; robust emotion-to-motion mapping; safety guardrails.
- Bold Broadcasting/advertising governance (Policy/Media)
- What: Standards for disclosure in live commerce and broadcast to prevent deceptive practices using avatarized presenters.
- Product/Workflow: Platform policies, real-time disclosure badges, certification for compliant avatar generators.
- Assumptions/Dependencies: Multi-stakeholder agreement (regulators, platforms, advertisers); detection and enforcement infrastructure.
Notes on feasibility and deployment:
- Performance and hardware: Reported 15.8–20 FPS is on an NVIDIA H100 at 512×512; consumer hardware will require optimization (quantization, TinyVAE, fewer steps) or cloud offload.
- Domain: Trained primarily on human faces; out-of-domain content (cartoons/animals) may fail without retraining.
- Pipeline: Requires face-centric framing, stable lighting, and reliable motion/keypoint extractors; licensing of third-party components must be checked.
- Ethics and safety: High potential for misuse (impersonation); deployments should include consent, disclosure, watermarking, and moderation controls.
- Integration: Real-time use needs tight coupling with streaming stacks (OBS/WebRTC/RTMP), low-latency transport, and session management (keyframe banks, initialization strategies).
Glossary
- 2D landmarks: 2D keypoints marking facial features used to condition pose or motion in generation. "Compared with the 2D landmarks~\cite{animateanyone, magicpose} and motion frames~\cite{x-portrait, megactor-sigma} used in existing methods, 3D implicit keypoints provide a more flexible and controllable representation of head motion."
- 3D implicit keypoints: Latent 3D keypoint representation inferred from images to capture head pose and geometry without explicit meshes. "we adopt hybrid motion signals, composed of implicit facial representations \cite{x-nemo} and 3D implicit keypoints~\cite{facevid2vid, liveportrait}, to achieve simultaneous control of both facial dynamics and head movements."
- AED: Average Expression Distance; a metric measuring expression similarity between generated and driving frames. "Motion accuracy is calculated as the average L1 distance between extracted expression (AED~\cite{fomm}) and pose parameters (APD~\cite{fomm}) of the generated and driving images using SMIRK~\cite{smirk}, with lower values indicating better expression and pose similarity."
- APD: Average Pose Distance; a metric measuring pose similarity between generated and driving frames. "Motion accuracy is calculated as the average L1 distance between extracted expression (AED~\cite{fomm}) and pose parameters (APD~\cite{fomm}) of the generated and driving images using SMIRK~\cite{smirk}, with lower values indicating better expression and pose similarity."
- ArcFace Score: Identity similarity score derived from ArcFace embeddings used to evaluate identity preservation. "We utilize the ArcFace Score~\cite{arcface} as the identity similarity (ID-SIM) metric."
- autoregressive micro-chunk streaming paradigm: A scheme that emits frames sequentially by conditioning on previous outputs, organizing frames into small chunks with progressively higher noise. "we adopt an autoregressive micro-chunk streaming paradigm~\cite{diffusionforcing} that assigns progressively higher noise levels across micro chunks with each denoising window"
- canonical keypoints: Neutral reference keypoint configuration serving as the base for pose transformations. "where represents the canonical keypoints, , , and represent the rotation, translation, and scale parameters, respectively."
- CFG technique: Classifier-Free Guidance; a sampling method to strengthen conditional signals in diffusion models. "rely on the CFG technique~\cite{cfg} to enhance visual fidelity and expression control"
- chunk-wise processing: Splitting long videos into independent fixed-length segments for processing. "the limitations of chunk-wise processing."
- ControlNet: A diffusion add-on that injects structural control signals (e.g., pose, edges) into the generation process. "These methods typically employ ControlNet~\cite{controlnet} or PoseGuider~\cite{animateanyone} to incorporate motion constraints into the generation process."
- cross-attention layers: Attention mechanism allowing the denoiser to attend to conditioning embeddings (e.g., motion). "which are then injected into via cross-attention layers."
- denoising steps: Iterative reverse-diffusion sampling iterations required to generate an image or video. "Most of them require over 20 denoising steps~\cite{ddim}"
- denoising window: The set of frames processed together at a given denoising step within streaming generation. "Formally, the denoising window at step is defined as a collection of micro-chunks:"
- diffusion forcing: A framework making diffusion models operate autoregressively for streaming generation. "RAIN~\cite{rain} adopts the diffusion forcing framework~\cite{diffusionforcing} for streaming generation on anime portrait data."
- exposure bias: Train–inference mismatch in autoregressive models that causes error accumulation over time. "To mitigate exposure bias~\cite{exposurebias1, exposurebias2} inherent in the autoregressive paradigm, we design a Sliding Training Strategy (ST)..."
- FVD: Fréchet Video Distance; a metric measuring distributional distance between video feature embeddings. "FVD~\cite{fvd} and tLP~\cite{tlp} are used to evaluate temporal coherence."
- Historical Keyframe Mechanism (HKM): Strategy that selects past generated frames as auxiliary references to stabilize appearance over long sequences. "an effective Historical Keyframe Mechanism~(HKM) that adaptively selects historical frames as auxiliary references, effectively mitigating error accumulation during streaming generation."
- ID-SIM: Identity similarity metric used for cross-reenactment evaluation. "We utilize the ArcFace Score~\cite{arcface} as the identity similarity (ID-SIM) metric."
- implicit facial representations: Latent embeddings capturing fine-grained facial dynamics for motion control. "we adopt hybrid motion signals, composed of implicit facial representations \cite{x-nemo} and 3D implicit keypoints~\cite{facevid2vid, liveportrait}"
- Latent Diffusion Models (LDMs): Diffusion models operating in compressed latent space to improve efficiency. "Diffusion models~\cite{ddpm, ddim, sde} have demonstrated strong generative capabilities, with Latent Diffusion Models (LDMs)~\cite{ldm} further improving efficiency by performing the denoising process in a lower-dimensional latent space."
- LPIPS loss: Learned Perceptual Image Patch Similarity; a perceptual distance metric used as a training loss. "combines MSE loss, LPIPS loss~\cite{lpips} and adversarial loss~\cite{gan}"
- micro-chunks: Small groups of frames within a denoising window assigned different noise levels to enable streaming. "we divide each denoising window into multiple micro-chunks with progressively higher noise levels"
- Motion-Interpolated Initialization (MII): Initializing the first denoising window with interpolated motion between reference and driving signals to avoid abrupt transitions. "we introduce a Motion-Interpolated Initialization~(MII) strategy, which constructs the first denoising window using the reference image combined with interpolated implicit motion signals"
- PoseGuider: Module that injects pose/structure maps into a diffusion backbone to guide motion. "injected into via PoseGuider~\cite{animateanyone}."
- prompt traveling technique: Method to smoothly vary prompts across time to improve temporal smoothness across chunk boundaries. "X-Portrait~\cite{x-portrait} and X-NeMo~\cite{x-nemo} adopt the prompt traveling technique~\cite{edge} to enhance temporal smoothness across chunk boundaries."
- ReferenceNet: Reference-conditioned network used to inject appearance features from a source image into the diffusion model. "Building upon the recent success of ReferenceNet-based diffusion animation method~\cite{ x-portrait, x-nemo, followyouremoji}, we incorporate several novel components."
- Sliding Training Strategy (ST): Training procedure that mimics streaming inference by sliding denoising windows and learning from model predictions. "we design a Sliding Training Strategy (ST) to eliminate the discrepancy between the training and inference stages"
- SMIRK: Toolset for extracting expression and pose parameters for evaluation. "using SMIRK~\cite{smirk}, with lower values indicating better expression and pose similarity."
- StyleGAN2: GAN architecture used as a discriminator to improve realism during training. "For the discriminator, we employ the StyleGAN2~\cite{stylegan2} architecture, initialized with weights pretrained on the FFHQ~\cite{stylegan} dataset."
- temporal module: Video-focused extension modeling temporal relations across frames in the denoiser. "we integrate a temporal module~\cite{animatediff} into the denoising backbone ."
- TinyVAE: Lightweight VAE decoder enabling faster latent-to-pixel reconstruction. "by replacing the standard VAE decoder with the TinyVAE~\cite{TinyVAE} decoder, PersonaLive can further boost the inference speed to 20 FPS."
- tLP: Temporal LPIPS; a perceptual metric assessing frame-to-frame consistency. "FVD~\cite{fvd} and tLP~\cite{tlp} are used to evaluate temporal coherence."
- VAE decoder: Variational autoencoder decoder that maps latents to pixel space in diffusion pipelines. "replacing the standard VAE decoder with the TinyVAE~\cite{TinyVAE} decoder"
Collections
Sign up for free to add this paper to one or more collections.