- The paper shows that distributional similarity between synthetic chain-of-thought traces and model outputs yields superior downstream generalization compared to human-annotated correct traces.
- Experiments across models like Gemma, Llama, and Qwen reveal that even synthetically generated, 'wrong' CoT traces provide valuable localized reasoning signals that enhance training efficiency and accuracy.
- The findings challenge traditional data curation practices by prioritizing alignment with a model's native output over rigid correctness, suggesting new strategies for SFT and potential refinements in RLHF pipelines.
Shape of Thought: Distributional Similarity Surpasses Final-Answer Correctness in Reasoning-Focused SFT
Introduction and Motivation
"Shape of Thought: When Distribution Matters More than Correctness in Reasoning Tasks" (2512.22255) systematically interrogates the dogma that correctness is the primary criterion for data efficacy in reasoning-focused supervised fine-tuning (SFT) of LLMs. The study reveals that the distributional alignment between synthetic chain-of-thought (CoT) traces and the student model has a more pronounced effect on downstream generalization than the mere correctness of the final answer. Notably, training on model-generated CoT traces—regardless of whether these traces yield the correct final answer—can increase performance relative to training with human-annotated, fully correct traces.
This essay formalizes the experiment-centric findings, situating them within the research on noisy label learning and inductive biases in overparameterized models. The analysis traverses various reasoning domains and LLM families, critically reevaluating annotation pipelines, teacher-student distillation paradigms, and the metrics of success for reasoning data curation.
Experimental Setup and Methodology
The authors utilize Gemma, Llama, and Qwen models at multiple scales (1.5B–9B parameters) and employ four reasoning and code generation benchmarks: MATH, GSM8K, Countdown, and MBPP. Three forms of fine-tuning data are considered:
- H (Human-annotated CoTs): Manually written, fully verified, and deemed maximally correct.
- G (Synthetic, Gold): Model-generated CoTs from a stronger teacher LLM, filtered to ensure a correct final answer.
- W (Synthetic, Wrong): Model-generated CoTs with final answers explicitly marked as wrong, typically excluded from SFT in prior pipelines.
The critical innovation is that both G and W are drawn from a teacher model’s own output distribution; W traces, while yielding incorrect answers, often contain substantial stretches of locally correct or reusable reasoning steps.
SFT is performed with cross-entropy minimization against these datasets. Evaluation is performed with final-answer correctness and (for code) Pass@1 rates.
Core Empirical Findings
Synthetic Data’s Distributional Advantage
SFT with synthetic CoTs (both G and W) consistently outperforms SFT with human-annotated gold data (H) on MATH, GSM8K, Countdown, and MBPP, including when analyzing maximal attained accuracy per experiment:
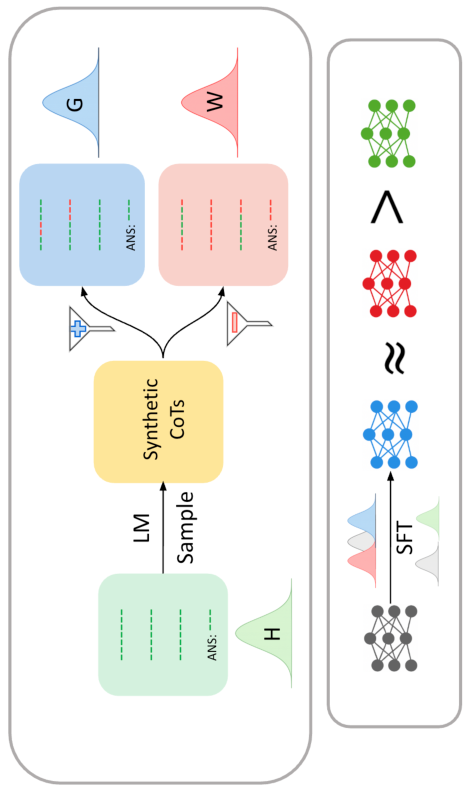
Figure 1: Fine-tuning on synthetic CoTs, regardless of final answer correctness, often yields higher downstream accuracy than using human-written data.
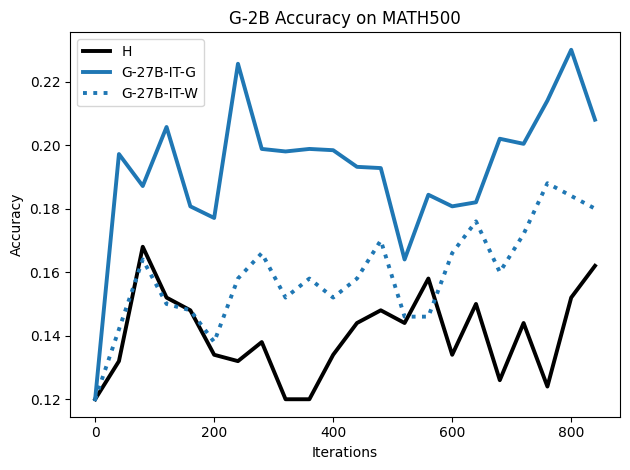
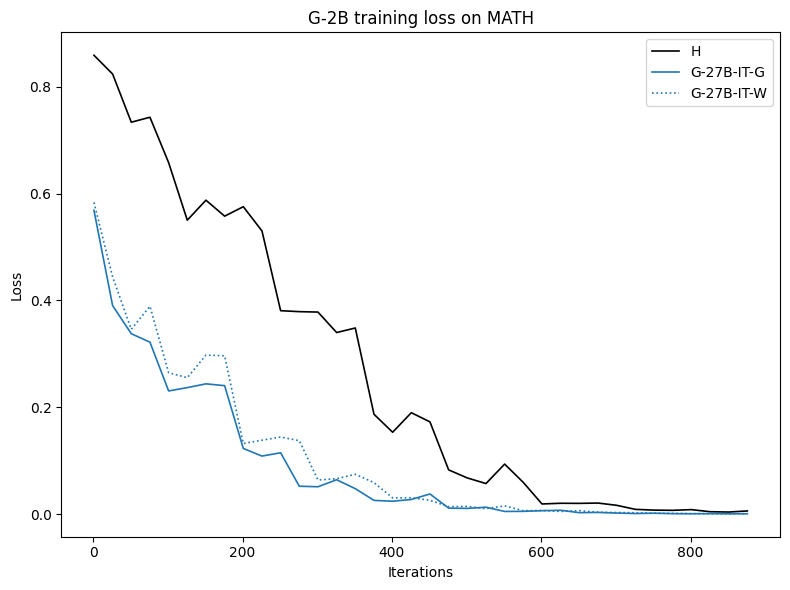
Figure 2: SFT on both G and W synthetic traces outperforms H traces on the MATH500 test set, highlighting distributional dynamics.
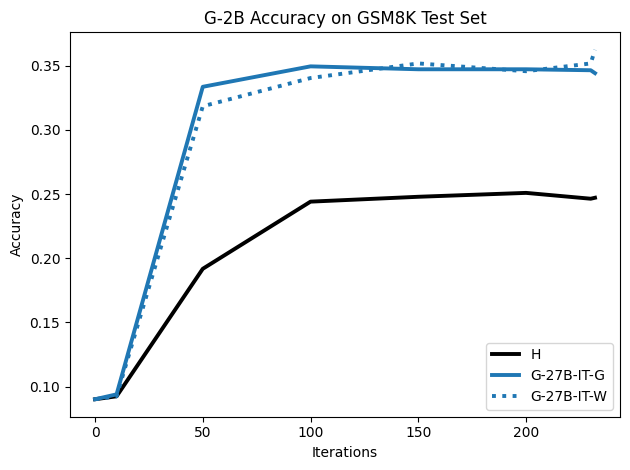
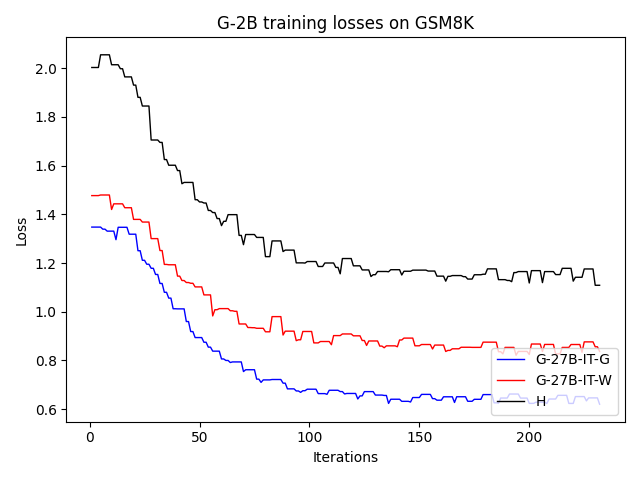
Figure 3: For GSM8K, SFT on synthetic G and W CoTs significantly surpasses human traces on accuracy over training iterations.
Synthetically generated traces start with lower training loss, indicating closer proximity to the student LLM's native output distribution, therefore reducing the inductive burden associated with adapting to human style or idiosyncrasies.
Utility of “Wrong” CoT Traces
The W dataset (synthetic traces ending in an incorrect answer) not only provides competitive performance with G, but in several settings surpasses training on H, especially on GSM8K and MBPP:
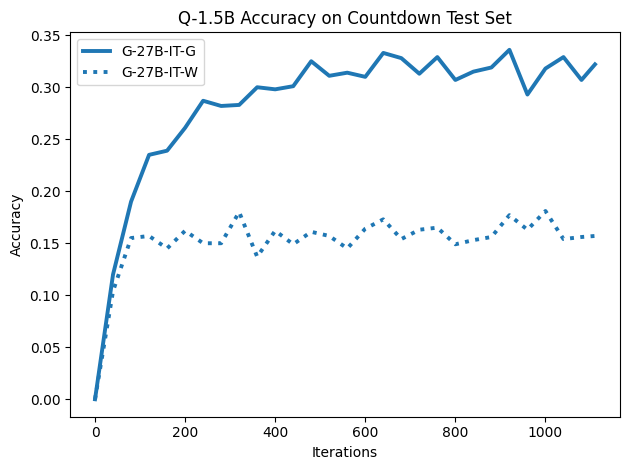
Figure 4: On harder arithmetic tasks (Countdown), even W CoTs significantly improve learning, but G CoTs provide greater performance gains.
Analysis of stepwise correctness in CoT traces reveals that W traces are rarely globally flawed—localized errors are common, but the overall structure and sub-step decomposition often mirror those of correct traces (see qualitative examples in the appendix of the paper).
Paraphrasing and Distributional Bridging
Paraphrasing H traces via a teacher LLM, thereby moving their syntax and stylistics nearer to model output, yields marked performance improvements over canonical H, even with preserved correctness:
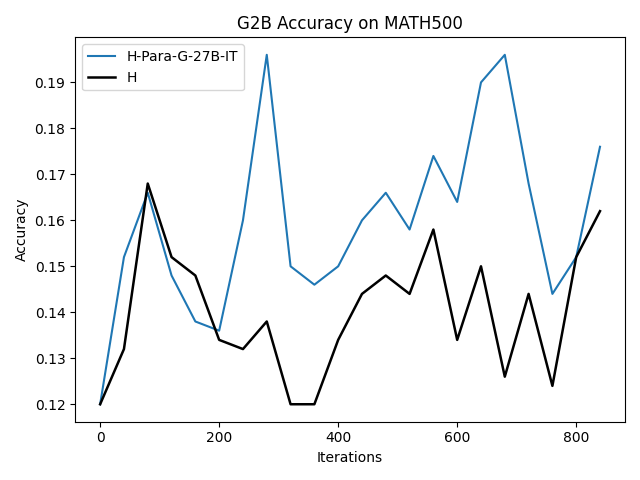
Figure 5: Paraphrased human CoTs by G-27B-IT yield superior performance to pure H when used for SFT on G-2B.
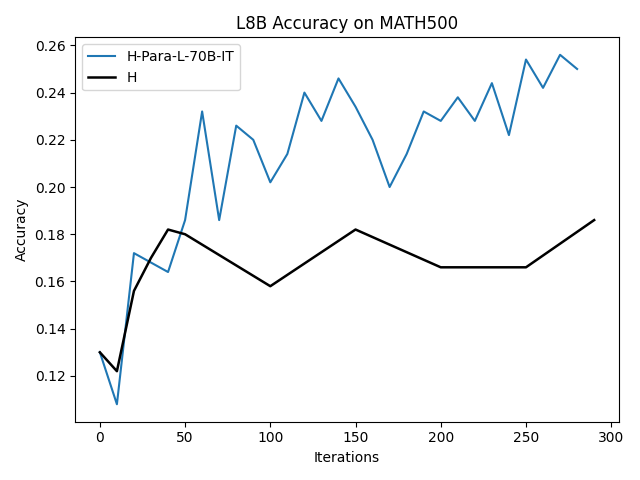
Figure 6: Paraphrased H traces by L-70B-IT yield consistent improvements for L-8B finetuning.
This establishes that distributional mismatch—rather than intrinsic human “superiority”—accounts for much of the historical shortfall in H-based SFT utility.
Error Tolerance and Signal Extraction
Controlled error-injection experiments incrementally replace G traces with completely flawed CoTs, quantifying the failure tolerance of SFT. Up to 25% of the dataset being entirely flawed only marginally reduces test accuracy; beyond this, stronger degradation sets in:
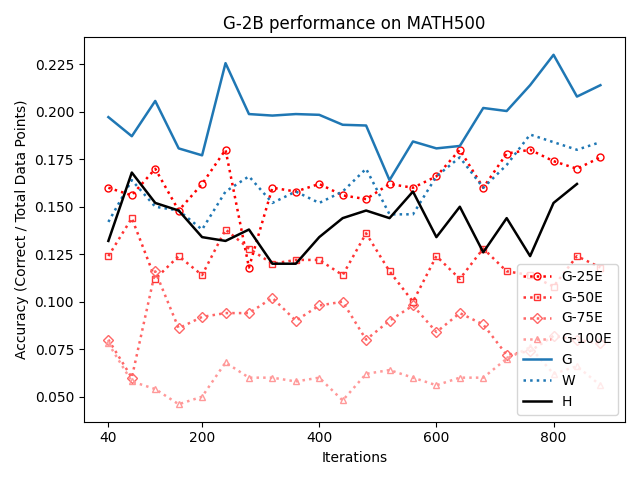
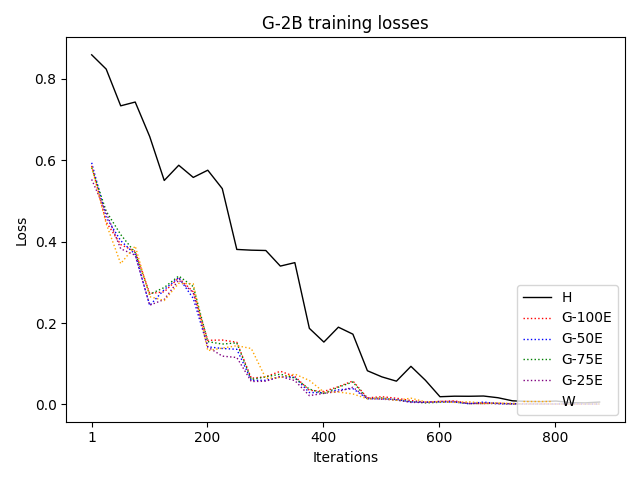
Figure 7: Model accuracy as a function of increasing fraction of fully incorrect CoTs: clear inflection point after 25% erroneous data.
Even an all-W dataset (100% flawed) outperforms H in terms of training loss and is competitive with H on accuracy, due to distributional proximity and preserved microstructure in many W traces.
Robustness, Scaling, and Ablations
Model scaling experiments (Gemma-2-2B vs. Gemma-2-9B) confirm that the findings persist with increased capacity. Across hyperparameter sweeps, the performance advantages of G and W over H remain robust.
Theoretical and Practical Implications
Inductive Bias in Overparameterized LMs
The results align with the observation that deep networks first absorb low-frequency, “consistent” signal before eventually fitting noise (memorization phase). As W traces predominantly manifest localized and non-catastrophic errors, SFT is able to extract reusable decomposition patterns and algebraic schema, discarding noise through implicit regularization.
Data Curation and Annotation Protocols
The imperative to construct datasets with maximum human correctness is challenged; instead, model trainers should prioritize generation pipelines that ensure the output distribution matches the target student as closely as possible, whether or not the final answer is correct. Curation methods that filter only by final-answer correctness fail to optimize for what actually drives generalization.
Metrics for CoT Faithfulness
The use of final answer correctness as a sole proxy for reasoning competence is revealed to be insufficient. Step-level or structural metrics that more directly interrogate CoT “shape” are needed for both dataset verification and model evaluation.
Extending to Other Training Paradigms
While these results are established for SFT, they suggest revisiting reward modeling and RLHF pipelines: synthetic preferences and reward traces mislabeled at the final step may yet provide invaluable intermediate signal for policy shaping and bootstrapping efficient RL inner loops.
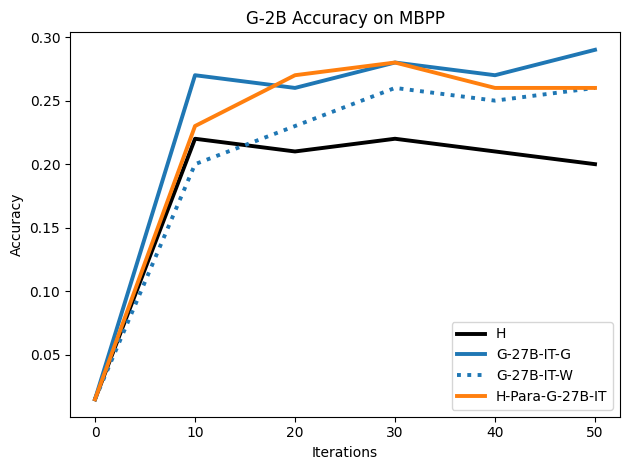
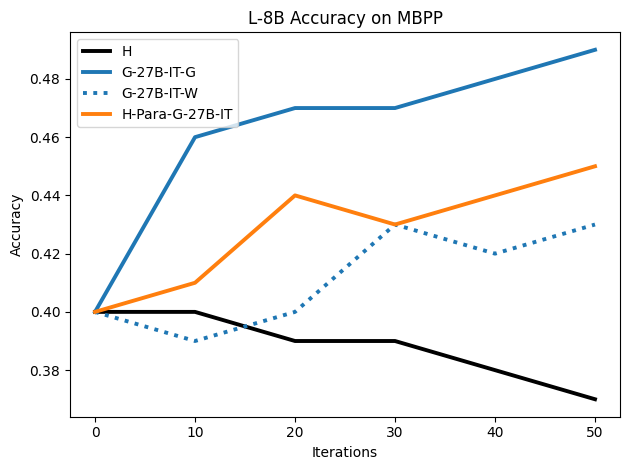
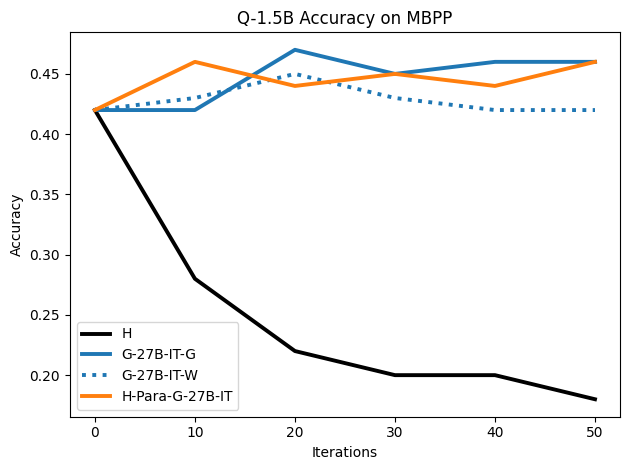
Figure 8: Results of SFT on Gemma-2-2B for MBPP code generation; G and W synthetic traces both outperform H.
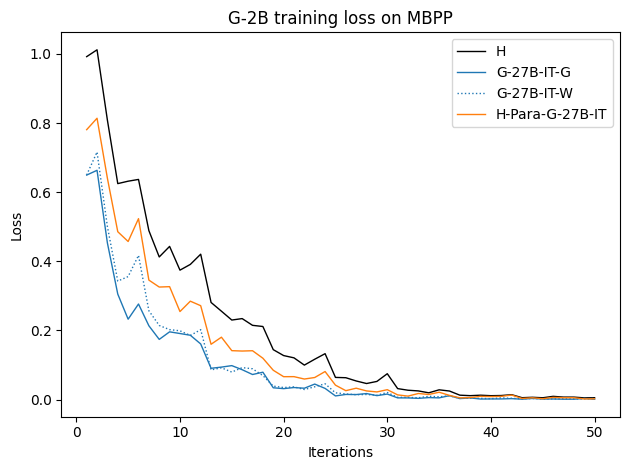
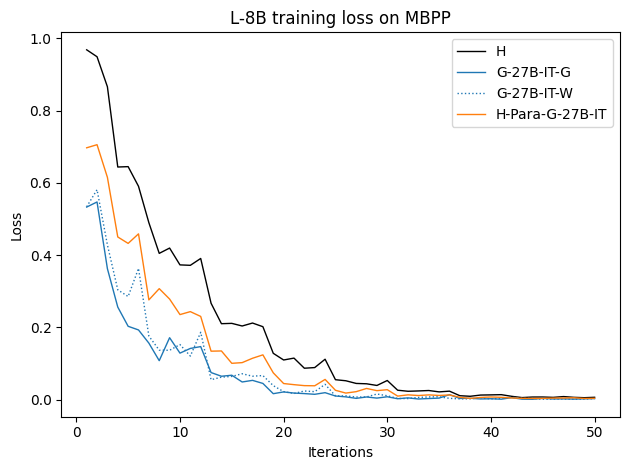
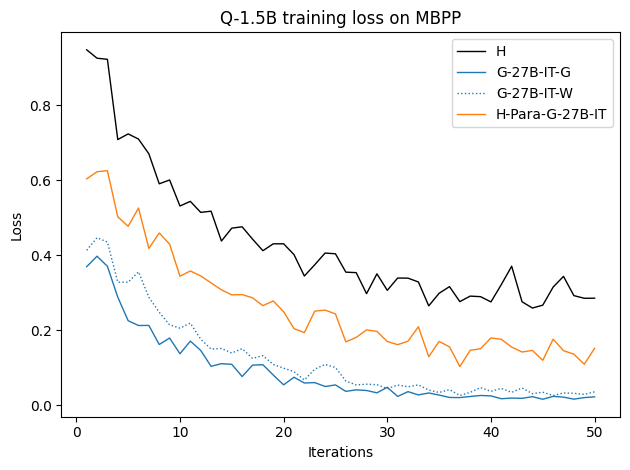
Figure 9: Training loss curves for various datasets; H traces yield higher (slower) convergence, confirming their distributional misalignment.
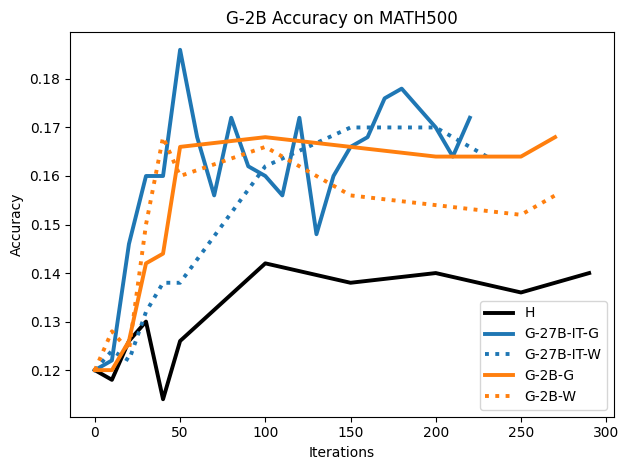
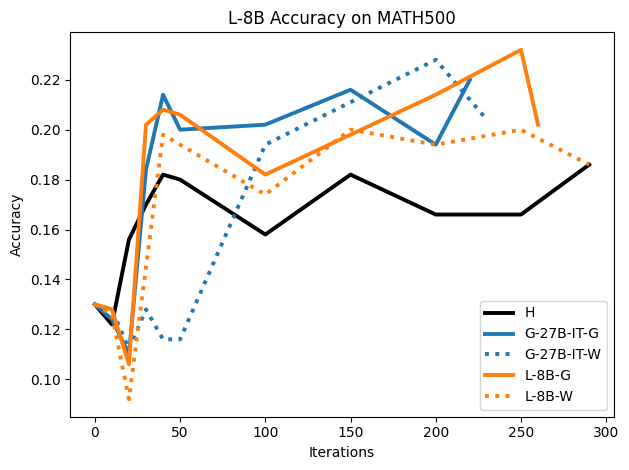
Figure 10: SFT on G-2B: synthetic datasets (G/W) outperform human traces at various training checkpoints.
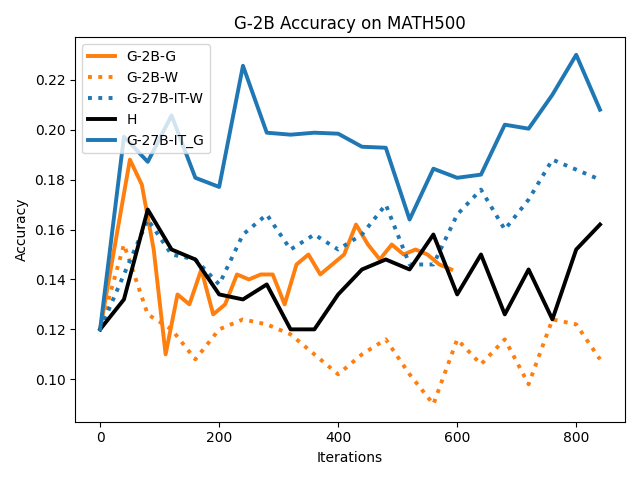
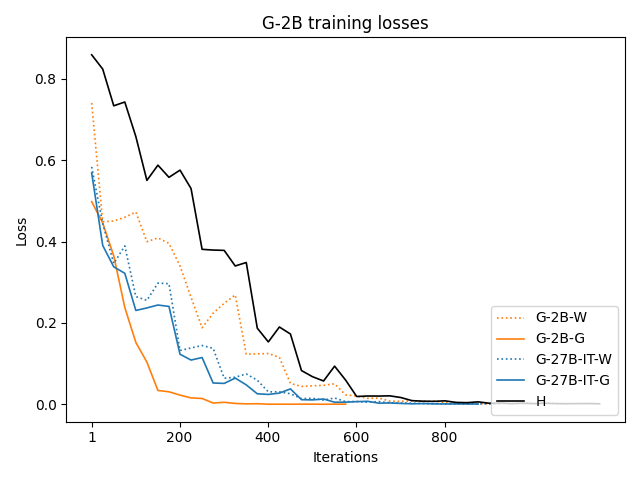
Figure 11: Training curve evolution on G-2B: G and W lead to higher test accuracies and faster convergence across training iterations.
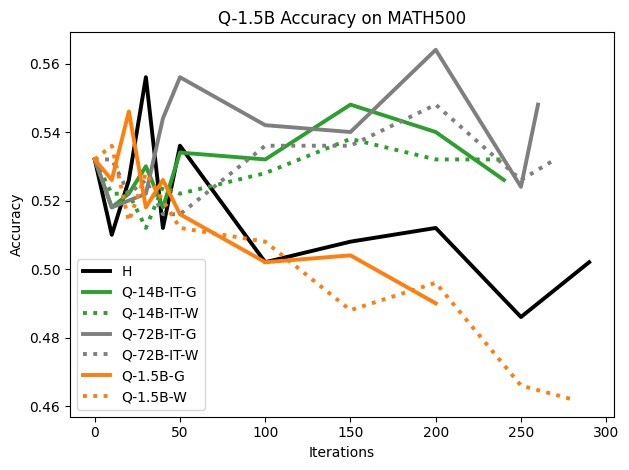
Figure 12: Qwen-2.5-1.5B on MATH500: negligible gains from SFT indicate a saturation point when the model baseline is already high.
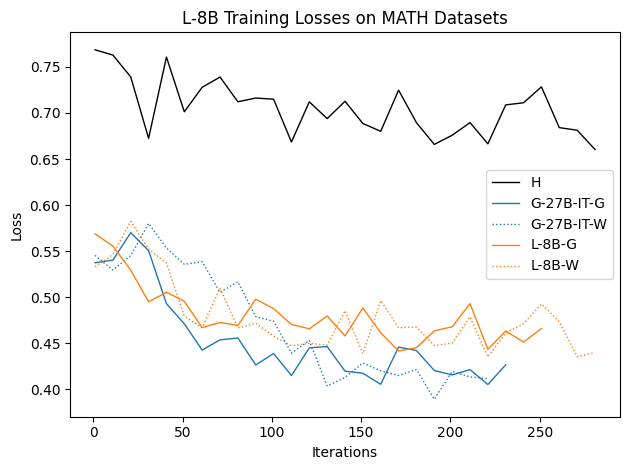
Figure 13: L-8B performance on MATH500: consistent superiority of synthetic G/W traces for fine-tuning.
Limitations and Avenues for Further Research
- The error injection study suggests SFT’s robustness primarily holds for local, non-compounding errors. Mass introduction of global logical errors remains detrimental.
- The analysis is limited to models up to 9B; distributional effects may manifest differently at higher scales, where emergent generalization and compositionality effects are more pronounced.
- The present work focuses on SFT; extension to RL-based finetuning should be pursued.
- Step-level verification for CoTs, or a structural measure of “reasoning faithfulness,” remains an open challenge.
Conclusion
"Shape of Thought" (2512.22255) demonstrates that for SFT in reasoning-centric LLMs, distributional similarity between training data and target model is a more reliable predictor of effective generalization than correctness of the final CoT answer. Incorrect model-generated traces, often discarded, are shown to offer substantial training signal. These results advise a paradigm shift in data curation: rather than prioritizing filtered human-written correctness, align training data distribution with what the student model “expects,” regardless of localized imperfections. Theoretical, empirical, and engineering efforts should reorient toward measuring and closing distributional gaps and formalizing stepwise evaluation.
This work redefines best practices for distillation, annotation, and SFT protocol design, pointing to new directions in LLM training and automated reasoning research.