- The paper demonstrates that adaptive fusion of frozen LVLM features with traditional ID embeddings yields superior recommendation performance.
- The study shows that intermediate decoder hidden states, especially when aggregated across layers, preserve crucial visual semantics over caption-based features.
- The research introduces the Dual Feature Fusion (DFF) framework, achieving state-of-the-art results with high training efficiency without updating LVLM parameters.
Systematic Integration of Frozen LVLMs for Micro-Video Recommendation
Introduction
The proliferation of micro-video platforms necessitates robust recommendation engines capable of leveraging both collaborative signals and rich multimodal content. This paper presents a rigorous empirical evaluation of integrating frozen Large Video LLMs (LVLMs) into micro-video recommendation systems, focusing on representation extraction and fusion strategies. The investigation is centered on two key design axes: (1) the paradigm for video feature extraction from LVLMs, contrasting LVLM captions with intermediate decoder hidden states; (2) the integration strategy for blending LVLM-derived features with traditional item ID embeddings, either by replacement or adaptive fusion.
Decomposed Framework for LVLM Integration
The methodological setup maintains LVLM parameters frozen, confining learning to the downstream recommender architecture. The feature extraction pipeline is modularized into: (i) ϕ(⋅), the LVLM-based extractor; and (ii) ψ(⋅), the integrator that combines content features with ID-based collaborative representations. This formal decomposition clarifies and isolates the impact of each component in the recommendation process.
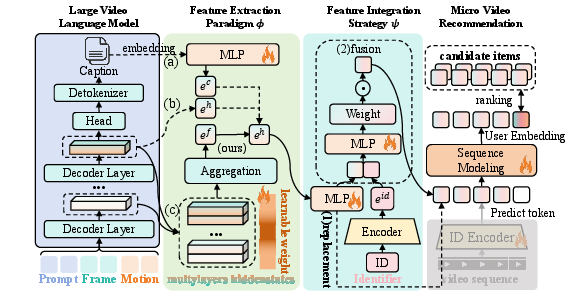
Figure 1: LVLM integration framework highlighting axes for feature extraction (caption vs. hidden state, multi-layer aggregation) and adaptive fusion versus ID replacement strategies.
Empirical Analysis of Feature Extraction and Fusion
Integration Strategies
Empirical results unequivocally demonstrate the necessity of ID embeddings. When LVLM-derived features replace IDs, recommendation quality deteriorates below baseline IDRec performance, indicating that collaborative signals encoded in IDs are indispensable and cannot be subsumed by multimodal content alone. Conversely, an adaptive fusion strategy leveraging a gating mechanism to blend LVLM features and ID embeddings results in strictly superior performance across metrics, outperforming both content-only and fine-tuned video encoders.
Comparison between caption-centric and hidden-state-centric paradigms shows consistent superiority of intermediate decoder hidden states. Caption generation introduces bottlenecks, discarding discriminatory visual semantics required for accurate recommendations. Direct extraction of dense hidden states, bypassing textual projection, preserves multimodal semantic richness.
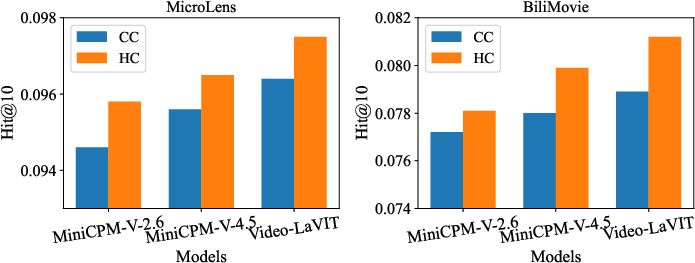
Figure 2: Performance comparison between caption-centric and hidden-state-centric feature extraction, demonstrating the advantage of direct hidden state usage.
Layer-Wise Feature Analysis
A systematic probe of decoder layers in Video-LaVIT reveals significant variance in their efficacy for recommendation. Middle layers yield optimal representations, balancing abstraction and visual grounding. Moreover, uniform aggregation of hidden states across layers further boosts performance compared to any single layer, capitalizing on the complementarity of hierarchical semantic signals.
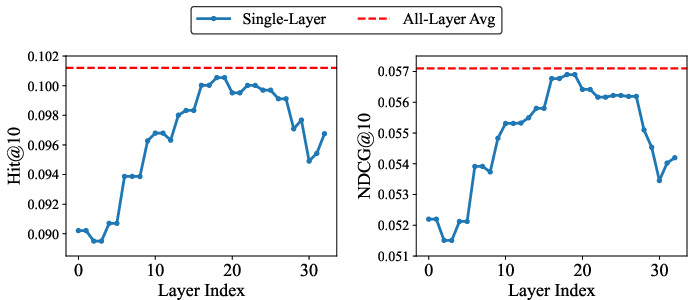
Figure 3: Hit@10 and NDCG@10 for Video-LaVIT’s decoder layers on MicroLens, illustrating peak performance at middle layers and gains from multi-layer averaging.
Dual Feature Fusion (DFF) Framework
The insights above motivate the proposal of Dual Feature Fusion (DFF): a lightweight, plug-and-play model for frozen LVLM integration. DFF aggregates multi-layer hidden states via learnable global weights, projecting them into a shared semantic space. An adaptive gating mechanism then dynamically combines this content-rich LVLM representation with trainable item ID embeddings. The full pipeline is jointly optimized by the recommendation loss, achieving state-of-the-art performance without LVLM parameter updates.
Experimental Results
DFF establishes new SOTA on MicroLens and Bili_Movie datasets, exceeding leading baselines and single-layer LVLM variants. On MicroLens, DFF achieves Hit@10 of 0.1020 and NDCG@10 of 0.0577, representing a 4.61% and 5.87% relative improvement over the best hidden-state-centric baseline. This validates the efficacy of multi-layer LVLM feature aggregation and adaptive ID fusion.
Training Efficiency
Despite higher accuracy, DFF retains exceptional training efficiency. Per-epoch time on a single RTX 4090 is 23.4 seconds, substantially faster than end-to-end fine-tuned approaches (e.g., VideoRec >589s/epoch on two A800s) while maintaining superior accuracy.
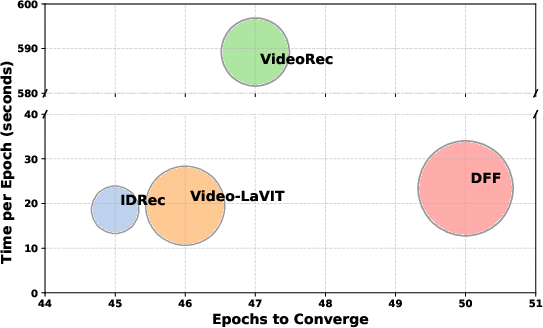
Figure 4: Convergence speed and training efficiency across methods; DFF achieves highest performance at low computational cost.
Task-specific prompt design—explicitly instructing LVLMs for micro-video recommendation—yields consistent improvements in extracted representations and downstream metrics. Further, input modality analysis shows raw video signals enable far more discriminative representations than either covers or textual titles, underscoring the importance of providing full temporal and multimodal input to LVLMs.
Theoretical and Practical Implications
This work establishes principled guidelines for deploying frozen LVLMs in micro-video recommendation. It empirically debunks claims that multimodal foundation models can supplant collaborative ID signals, underscoring the necessity of adaptive fusion. The fine-grained analysis of layer-wise representations demonstrates hierarchical semantic diversity, providing actionable design principles for system architects. Practically, DFF delivers SOTA results with low computational cost, making it highly deployable in real-world applications where resource constraints preclude fine-tuning of massive LVLMs.
Future Directions
Several open problems remain. Principled selection and dynamic weighting of LVLM layers—potentially conditioned on item modality, interaction sparsity, or user intent—may further improve efficiency and interpretability. There is scope to investigate hybrid regularization schemes marrying hierarchical LVLM semantics with collaborative ID signals, potentially closing gaps between semantic fidelity and behavioral personalization. Continued research into prompt optimization and modality-specific aggregation will further refine the interface between foundation models and targeted recommendation systems.
Conclusion
The presented systematic evaluation clarifies core principles for integrating frozen LVLMs into micro-video recommendation: (1) intermediate decoder states outperform caption-based and single-layer approaches; (2) collaborative ID signals are irreplaceable, with fusion necessary for optimal results; and (3) multi-layer LVLM aggregation yields substantial performance gains. The DFF framework operationalizes these insights in a practical, high-performing plug-and-play method applicable across platforms and datasets, setting the stage for next-generation multimodal recommendation engines.
Reference: "Frozen LVLMs for Micro-Video Recommendation: A Systematic Study of Feature Extraction and Fusion" (2512.21863).

