- The paper demonstrates that LVLMs produce semantically rich multimodal embeddings that outperform traditional late-fusion methods.
- It evaluates various feature extraction techniques on real-world datasets, addressing challenges like data sparsity and cold-start issues.
- LVLM-generated embeddings offer robust, explainable insights, suggesting potential for fine-tuning domain-specific recommendation systems.
Multimodal Content in Recommender Systems
Introduction
The paper "Do Recommender Systems Really Leverage Multimodal Content? A Comprehensive Analysis on Multimodal Representations for Recommendation" addresses a pivotal question in the field of recommender systems (RS): whether multimodal content truly enhances recommendation accuracy or if the perceived improvements are merely a byproduct of increased model complexity. This research explores the role of multimodal embeddings and assesses their semantic richness using a variety of techniques, including Large Vision-LLMs (LVLMs), to generate and evaluate multimodal representations.
Multimodal Recommender Systems
Multimodal Recommender Systems (MMRSs) aim to incorporate diverse content modalities, like images and text, to address common RS challenges such as data sparsity and cold-start issues. While MMRSs have achieved notable empirical success, this study critically examines their capacity for genuine cross-modal understanding as opposed to benefits derived mainly from architecture complexity. The paper underscores that traditional multimodal approaches often rely on late-fusion techniques, which can lack effective mechanisms to ensure the semantic alignment of integrated features.
Methodology
The investigation begins by contrasting classical collaborative filtering methods with multimodal alternatives using controlled experiments that involve noise-infused features to gauge model sensitivity to non-informative content. The study evaluates various feature extraction techniques, including RNet50, ViT, Sentence-BERT, and CLIP, each representing different approaches to obtaining semantic embeddings. Notably, the paper introduces LVLMs as a more principled solution for acquiring multimodal item embeddings without requiring ad hoc fusion of unimodal features. These models, such as Qwen2-VL and Phi-3.5-VI, provide structured, semantically-aligned embeddings via structured prompts.
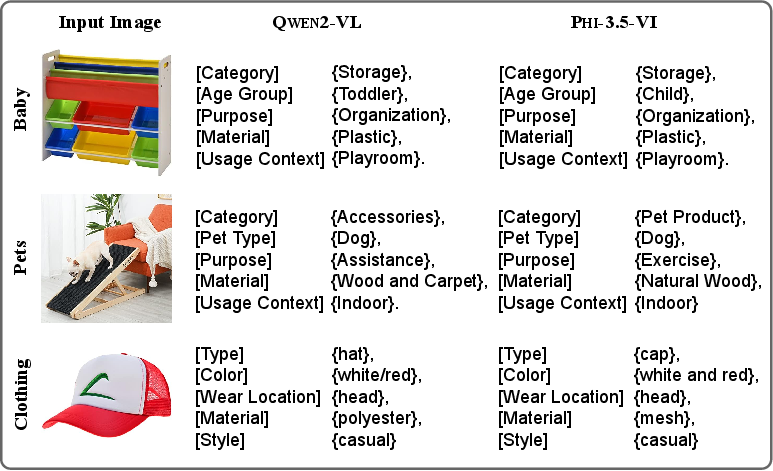
Figure 1: Examples of structured descriptions from LVLMs Qwen2-VL and Phi-3.5-VI for items in the Baby, Pets, and Clothing datasets.
Experimental Setup and Results
The empirical evaluation is conducted across three datasets: Baby, Pets, and Clothing, derived from Amazon Reviews 2023. Each dataset undergoes k-core filtering to maintain a minimum review presence and ensure multimodal richness. LVLMs are tasked with generating multimodal embeddings via vision-question answering (VQA) tasks, facilitating high-quality semantic representation.
The results reveal that LVLMs consistently outperform traditional feature fusion approaches, indicating that the true semantic content captured by these models delivers superior recommendation performance. Notably, models equipped with LVLM-generated embeddings showed consistent gains, underscoring their practicality and robustness. The study also explores LVLM-generated textual descriptions as auxiliary content, further validating their semantic informativeness when integrated into recommendation pipelines.
Conclusion
The research establishes LVLMs as an effective approach for deriving semantically rich multimodal representations, moving beyond typical late-fusion paradigms that fall short in aligning cross-modal information. By corroborating the value of LVLMs in creating aligned and semantically deep representations, the study advocates for leveraging such models to build more robust and meaningful MMRSs. Future research directions could involve fine-tuning LVLMs for better domain-specific application in RSs, as well as investigating their potential to provide explainable recommendations that elucidate the underlying multimodal semantics.

