- The paper introduces the short-#1@k{m} method, showing that shorter chains can boost LLM reasoning accuracy by up to 34.5%.
- It demonstrates a reduction in token usage by approximately 50% and decreases inference wall time by up to 33% compared to longer chains.
- Fine-tuning LLMs on shorter reasoning data (S1-short) yields enhanced performance, underscoring the benefits of efficient chain design.
Preferring Shorter Thinking Chains for Improved LLM Reasoning
Introduction
LLMs are often employed in complex reasoning tasks, where the prevailing methodology leverages extensive chains of thought (CoT) to achieve higher accuracy in problem-solving. This practice, although effective, is computationally expensive due to the increased inference time required for generating these long thinking chains. The paper "Don't Overthink it. Preferring Shorter Thinking Chains for Improved LLM Reasoning" challenges the conventional wisdom that longer thinking chains lead to improved reasoning capabilities. Through empirical evaluation across multiple reasoning LLMs and mathematical benchmarks, the study uncovers that shorter reasoning chains can surpass longer ones in accuracy, suggesting a paradigm shift in the approach to LLM reasoning.
Methodology
The research introduces a novel inference method named short-#1@k{m}. This method involves executing k parallel generations and halting computation once the first m thinking trajectories complete. The final answer is determined using majority voting among these m chains, which effectively reduces computational costs and inference time. The performance of LLM models on several competitive benchmarks is analyzed by comparing the accuracy of different inference strategies, including standard majority voting and the proposed short-#1@k{m}.
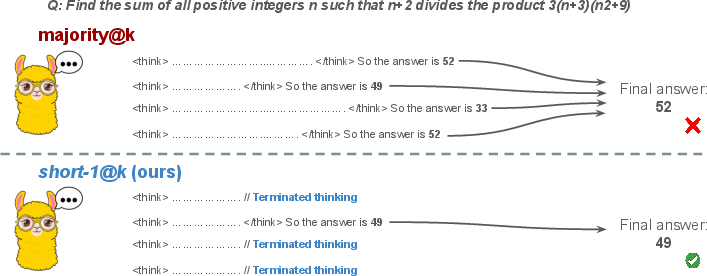
Figure 1: Visual comparison between majority voting and our proposed method short-#1@k{m} with m=1.
Experiments and Results
Shorter Chains vs. Longer Chains
The study evaluates three top-tier reasoning LLMs across three complex mathematical benchmarks: AIME 2024, AIME 2025, and HMMT February 2025. It is observed that selecting the shortest reasoning chain yields a significant improvement in accuracy, with increases reaching up to 34.5% compared to the longest chain for the same question. Additionally, this approach naturally reduces the number of tokens by about 50%, demonstrating both performance and efficiency benefits.
Implementation of short-#1@k{m}
The proposed short-#1@k{m} method achieves superior performance across various compute budgets compared to standard majority voting. In low-compute scenarios, short-#1@k{1} outperforms other methods while using up to 40% fewer tokens. In high-compute regimes, short-#1@k{3} consistently exceeds majority voting efficiency, reducing wall time by up to 33%.
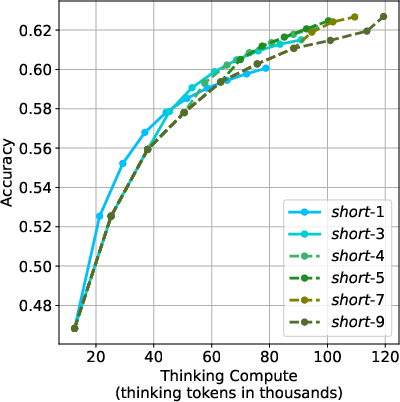
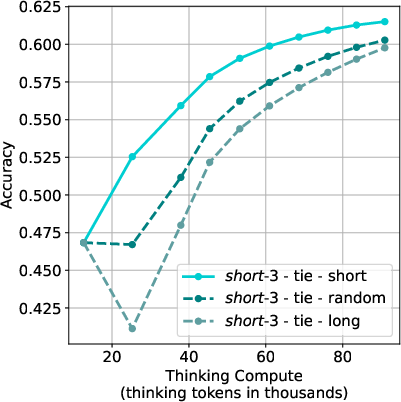
Figure 2: m values ablation of short-#1@k{m}.
Fine-tuning with Shorter Reasoning Chains
To further investigate the impact of shorter reasoning chains, the researchers fine-tuned an LLM (Qwen-2.5-32B) using different S1 dataset variations—S1-short, S1-long, and S1-random. Results indicate that models fine-tuned on shorter reasoning chains (S1-short) not only reduced the length of thinking trajectories but also improved accuracy compared to models trained on longer or randomly sampled chains. This highlights the potential efficacy of supervised fine-tuning on shorter CoT data.
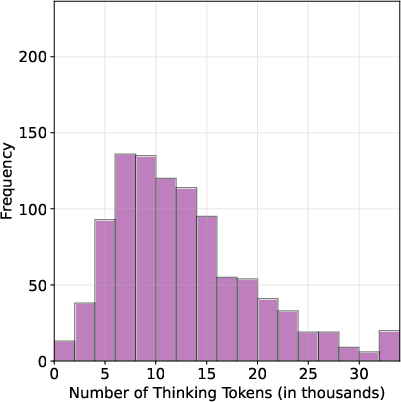
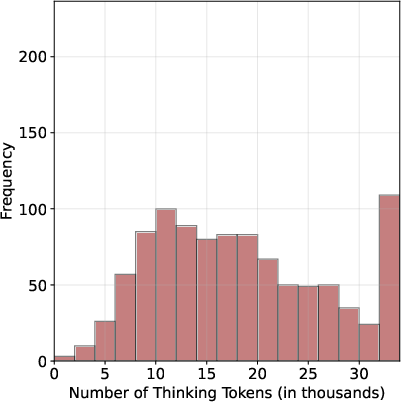
Figure 3: S1-short dataset variant leading to enhanced performance upon fine-tuning.
Implications and Future Directions
The findings suggest reevaluating current practices in test-time compute for reasoning LLMs, with an emphasis on balancing reasoning efficiency and performance. Shorter thinking chains not only mitigate computational demands but can also enhance the reasoning capabilities of LLMs. Future research may explore the integration of these insights into more extensive LLM training regimes, potentially bolstering the development of models that are both computationally efficient and adept at complex reasoning tasks.
Conclusion
The paper presents compelling evidence that challenges the assumption that longer thinking chains inherently enhance LLM reasoning. By leveraging shorter reasoning chains, the proposed methods demonstrate that improved performance can be attained with reduced computational overhead, paving the way for more efficient reasoning strategies in LLM applications. This research provides significant insights into the optimization of LLM reasoning processes, with potential implications for broader applications requiring efficient computational resource management.