- The paper introduces a novel certainty-guided reasoning (CGR) framework that balances decision accuracy and computational efficiency in large language models.
- It employs a critic model to periodically assess token-level certainty, enabling early termination when confidence exceeds a 0.97 threshold or forcing further reasoning when needed.
- Results demonstrate significant improvements in accuracy and token savings through multi-seed evaluations and the introduction of a Grade metric.
Certainty-Guided Reasoning in LLMs: A Dynamic Thinking Budget Approach
Introduction
The paper "Certainty-Guided Reasoning in LLMs: A Dynamic Thinking Budget Approach" investigates how Large Reasoning LLMs (LRLMs) can optimize their decision-making processes through the integration of a Certainty-Guided Reasoning (CGR) framework, inspired by GAN architectures. LRLMs perform reasoning tasks within a fixed thinking budget, creating a trade-off between processing capacity and decision accuracy. The novel CGR approach re-evaluates this trade-off by leveraging internal model certainty measures to guide decision-making dynamically, enabling models to adjust the length of their reasoning processes depending on their confidence levels.
In this framework, a critic model periodically assesses the certainty of the model's reasoning. Reasoning halts once the model reaches a pre-set certainty threshold, which indicates sufficient confidence in its current answer. This methodology effectively balances computation efficiency against solution reliability, allowing early termination of reasoning when confidence is high while ensuring continued reasoning in cases of uncertainty, thus preserving computational resources without sacrificing accuracy.
Methodology
Baseline Setup
The baseline model setup involves running several LRLMs, such as DeepSeek-R1-Distill-Qwen-14B and Phi-4-reasoning-plus, across a series of token budgets, with the thinking process stopping only after reaching the designated end-of-thinking token or the sequence's completion. By simulating conditions with various token budgets, the study could grasp performance variance across differing capacities for extended reasoning.
Budget Forcing
Budget forcing serves to circumvent premature reasoning conclusion by replacing the model’s end-of-thinking token with a “Wait” token when certainty is below the threshold. This intervention forces the model to continue reasoning, potentially altering and refining its answers.
Certainty Estimation and Implementation
Certainty is defined as the minimum probability among the model’s top predicted answer tokens. The study performed empirical testing to establish the certainty threshold, pinpointed at 0.97, above which the model could conclude its reasoning with high accuracy. Certainty probing is performed periodically to check if the model's thinking can terminate early due to sufficient confidence.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
def Certainty_Guided_Reasoning(question, model, budget, threshold):
output = ''
token_count = 0
while token_count < budget:
x = model.generate_next_token(question, output)
if x == '</think>':
certainty = calculate_certainty(output)
if certainty >= threshold:
break
else:
x = '\nWait'
output += x
token_count += 1
output += "Final Answer: \boxed{"
return extract_answer(output) |
Multi-Seed Evaluation
CGR's consistency and reliability were validated through extensive multi-seed evaluations, strengthening the robustness of findings by ensuring that accuracy and efficiency improvements are not merely stochastic variations.
Results and Analysis
Accuracy and Token Efficiency
The application of CGR achieved notable accuracy improvements and reduced variance across model evaluations, especially on challenging datasets such as AIME2025. The models demonstrated significant token savings without compromising accuracy, effectively achieving a balance between computational efficiency and reliable decision-making.
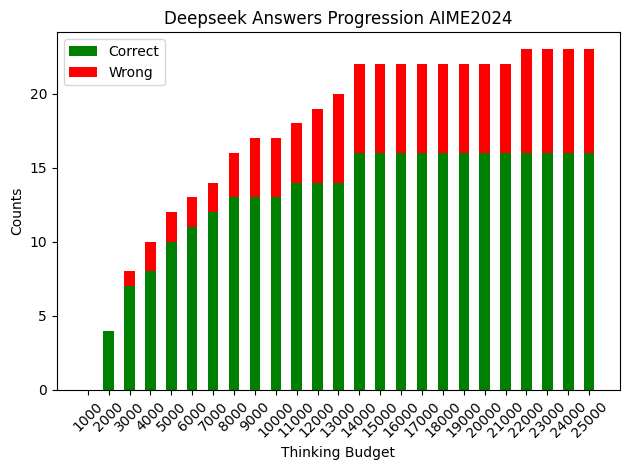
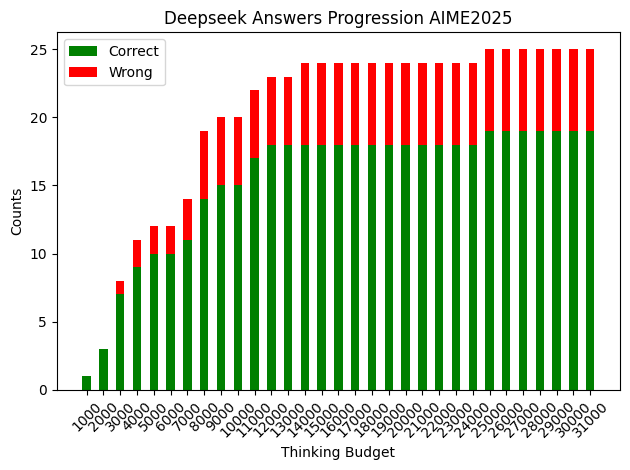
Figure 1: Deepseek accuracy as a function of thinking budgets.
Grade Metric Evaluation
The study introduced the "Grade" metric, accounting for accurate answers and penalizing confident errors. The CGR improved the Grade compared to baseline performance, with consistent results across varied penalty settings. This metric illustrates the quality and suitability of the CGR method for high-expectation environments, exemplifying how a precision-driven approach yields better academic or professional evaluations.
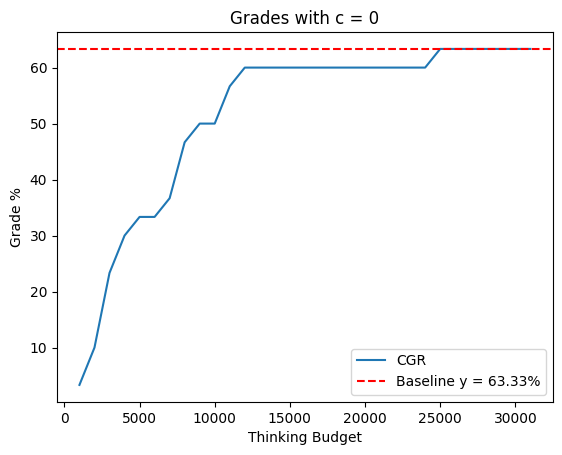
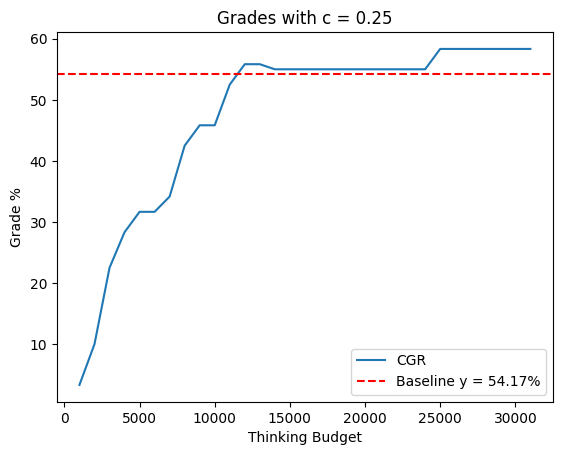
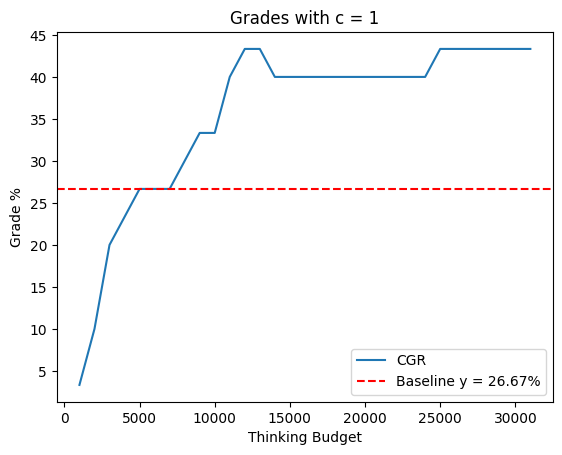
Figure 2: Grade with varying c on the AIME2025.
Token Savings
CGR showed substantial token savings across all thresholds, indicating efficient use of computational resources. The analysis allows tailoring of the certainty threshold based on application contexts: applications requiring higher reliability might choose a higher threshold, whereas scenarios with tight computational constraints might prefer lower thresholds.
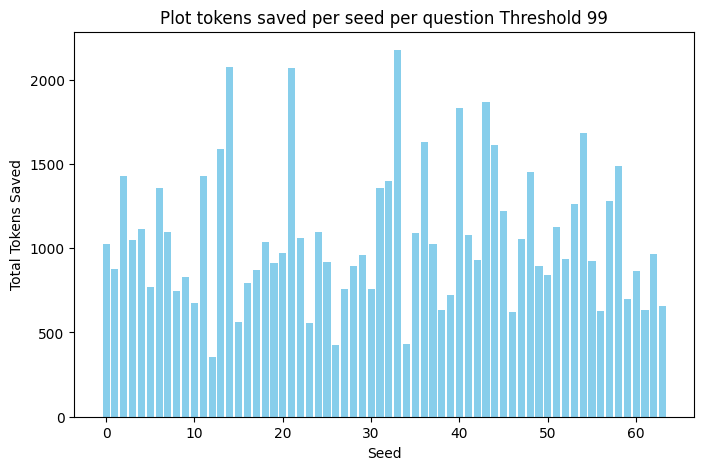
Figure 3: Tokens Saved per Seed per Question Threshold 99.
Conclusion
By integrating certainty into reasoning protocols, the paper proposes a solution that enhances both the adaptive and resource-efficient aspects of LRLM deployment. The CGR approach offers promising avenues for real-world applications, particularly in domains where accuracy and efficiency are paramount. Future work may refine the certainty probes, expand application scopes, and optimize the certainty thresholds to be dynamically responsive to specific problems, further fortifying the promise of smart, certainty-guided LLMs.

