- The paper introduces the JointThinking approach, integrating Thinking and Nothinking modes to improve reasoning accuracy by up to 6.21%.
- It employs a robust dual-mode consistency check and a second-thinking step to mitigate overthinking and refine outputs.
- Experiments demonstrate enhanced out-of-distribution performance and scalability, underscoring the practical benefits of calibration in LLMs.
Thinking with Nothinking Calibration: A New In-Context Learning Paradigm in Reasoning LLMs
In this essay, we explore the comprehensive methodology, implementation, and experimental validation of "Thinking with Nothinking Calibration," a paradigm for In-Context Learning (ICL) in Reasoning LLMs (RLLMs). This paradigm leverages the structural differences between two reasoning modes—Thinking and Nothinking—to enhance performance on reasoning tasks.
Introduction
Reasoning LLMs (RLLMs) such as DeepSeek-R1 and Qwen3 have emerged as pivotal entities in handling complex problem-solving scenarios, primarily due to their structured inference paradigms. However, these models frequently suffer from "Overthinking," where excessive reasoning can obfuscate simple solutions. The paper introduces a method termed JointThinking that employs parallel generation in two modes, subsequently calibrated to use consistency checks for determining the necessity of further reasoning.
Methodology
Thinking and Nothinking Modes
The JointThinking framework outlines two parallel reasoning approaches:
- Thinking Mode: This mode facilitates comprehensive reasoning by generating a detailed thought process from the problem statement.
- Nothinking Mode: Conversely, this mode directly seeks solutions by bypassing intermediate reasoning steps, reducing the chance of getting entangled in complex layers unnecessarily.
The integration of these modes allows models to operate optimally across varying complexities of tasks by selecting the appropriate reasoning strategy for the problem at hand.
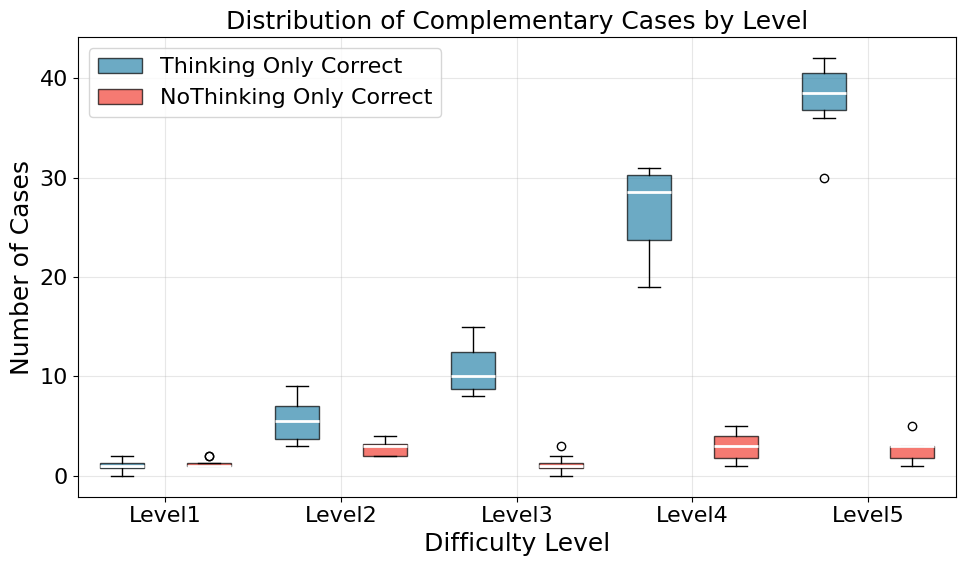
Figure 1: Comparison of R1-7B using Thinking and Nothinking on MATH500. Each mode reliably compensates for the other's failures across all difficulty levels.
Consistency Check and Second Thinking
The method implements a consistency check mechanism to compare outputs from both modes. If the outputs disagree, a second round of targeted and reasoned thinking (termed Second Thinking) is triggered. This is operationalized using both outputs as prompts for deeper reasoning, ensuring thorough verification.
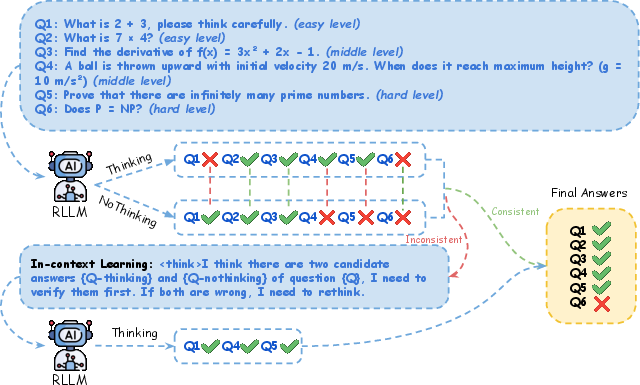
Figure 2: Thinking with Nothinking Calibration (JointThinking). Given one question, the reasoning LLM generates two outputs in parallel.
Experiments and Results
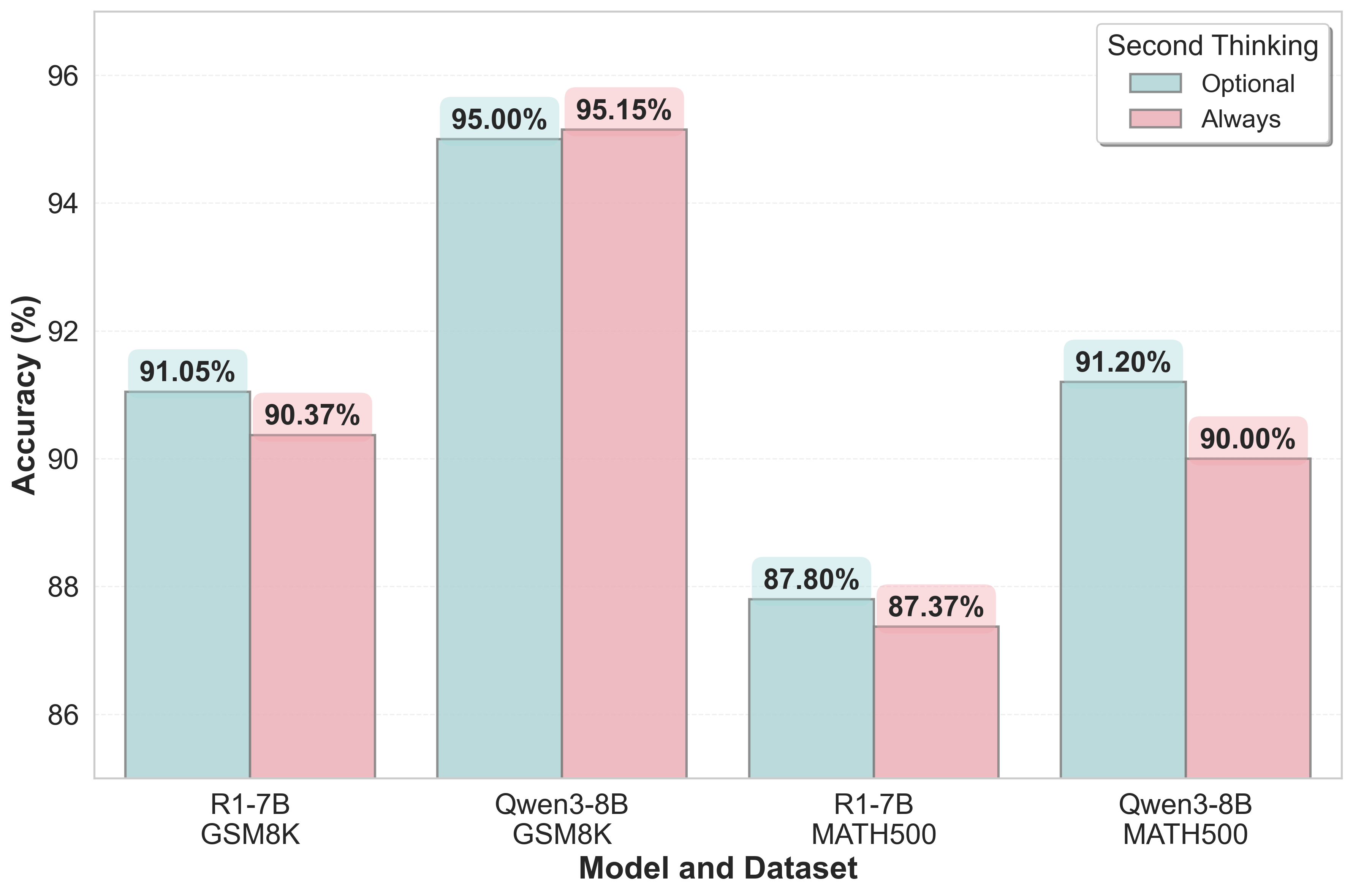
The proposed paradigm was evaluated comprehensively against existing methods like few-shot Chain of Thought (CoT) and majority voting baselines across diverse mathematical reasoning benchmarks. Data reveals that JointThinking consistently outperforms these methods, with empirical results showing enhanced performance on both in-distribution tasks (e.g., GSM8K, MATH500) and notable gains on out-of-distribution benchmarks.
Across several model sizes, JointThinking demonstrated robust effectiveness:
Calibration and Scalability
Significantly, the consistency calibration has lowered error rates, proving effective cross-mode calibration benefits. The scalability was demonstrated with increasing model sizes further narrowing the gap between predicted outcomes and ideal solutions, indicating potential for even larger models.
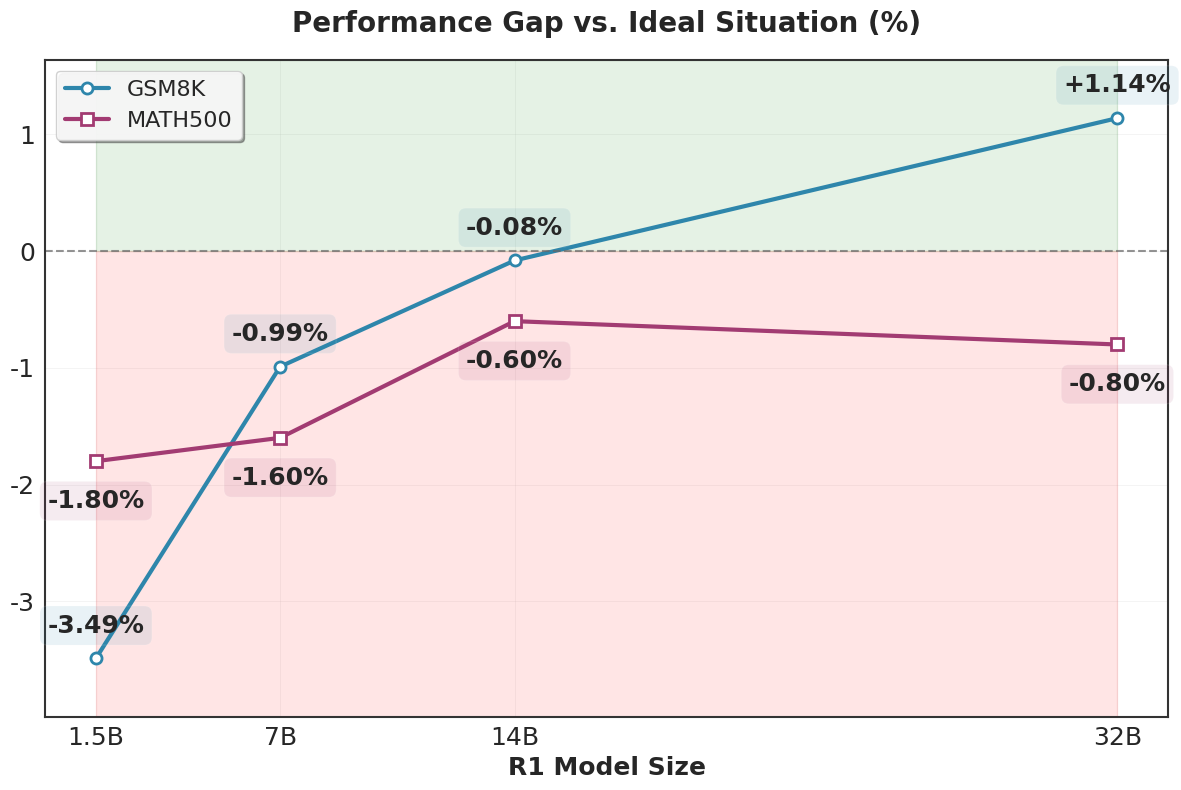
Figure 4: Scaling trend of second-thinking performance. The reduction in performance gap from the ideal situation indicates the strong scalability of jointthinking.
Discussion
JointThinking introduces a compelling approach to mitigate the pitfalls of overthinking by effectively harnessing simplicity when possible. The evident improvement in applying mixed-mode calibration hints at structural shortcomings in existing RLLMs, suggesting future explorations into multimodal learning approaches where reasoning capacities can be contextually optimized.
Conclusion
JointThinking offers a distinctive strategy in RLLMs to tackle diverse reasoning challenges through a balanced approach, effectively combining detailed and direct reasoning modes. The methodology not only enhances current performance paradigms but also paves the way for future advancements in scalable, context-aware language systems, presenting a holistic improvement in computational reasoning capabilities.