- The paper presents a novel approach by defining the Reasoning Completion Point (RCP) to terminate LLM reasoning early, reducing token usage by over 30%.
- It outlines a three-stage reasoning framework and employs heuristic rules with a lightweight CatBoost model for dynamic, real-time RCP detection.
- Experimental results on benchmarks like AIME24 and GPQA-D demonstrate that the method conserves computational resources while maintaining or improving accuracy.
Stop Spinning Wheels: Mitigating LLM Overthinking via Mining Patterns for Early Reasoning Exit
This paper addresses the significant issue of overthinking in LLMs by defining a systematic approach to mitigate redundant reasoning, ultimately conserving computational resources without sacrificing accuracy. The authors conceptualize the reasoning process into three distinct stages and introduce a novel Reasoning Completion Point (RCP) to optimize reasoning termination.
Reasoning Stages and Overthinking
The paper identifies three critical stages within the reasoning process of LLMs:
- Insufficient Exploration Stage: Here, the model's reasoning is limited, resulting in short content and low accuracy.
- Compensatory Reasoning Stage: At this stage, there is a compensatory mechanism where reasoning becomes more coherent, and content length increases inversely with thinking length.
- Reasoning Convergence Stage: After reaching the RCP, further reasoning does not enhance accuracy and often leads to overthinking.
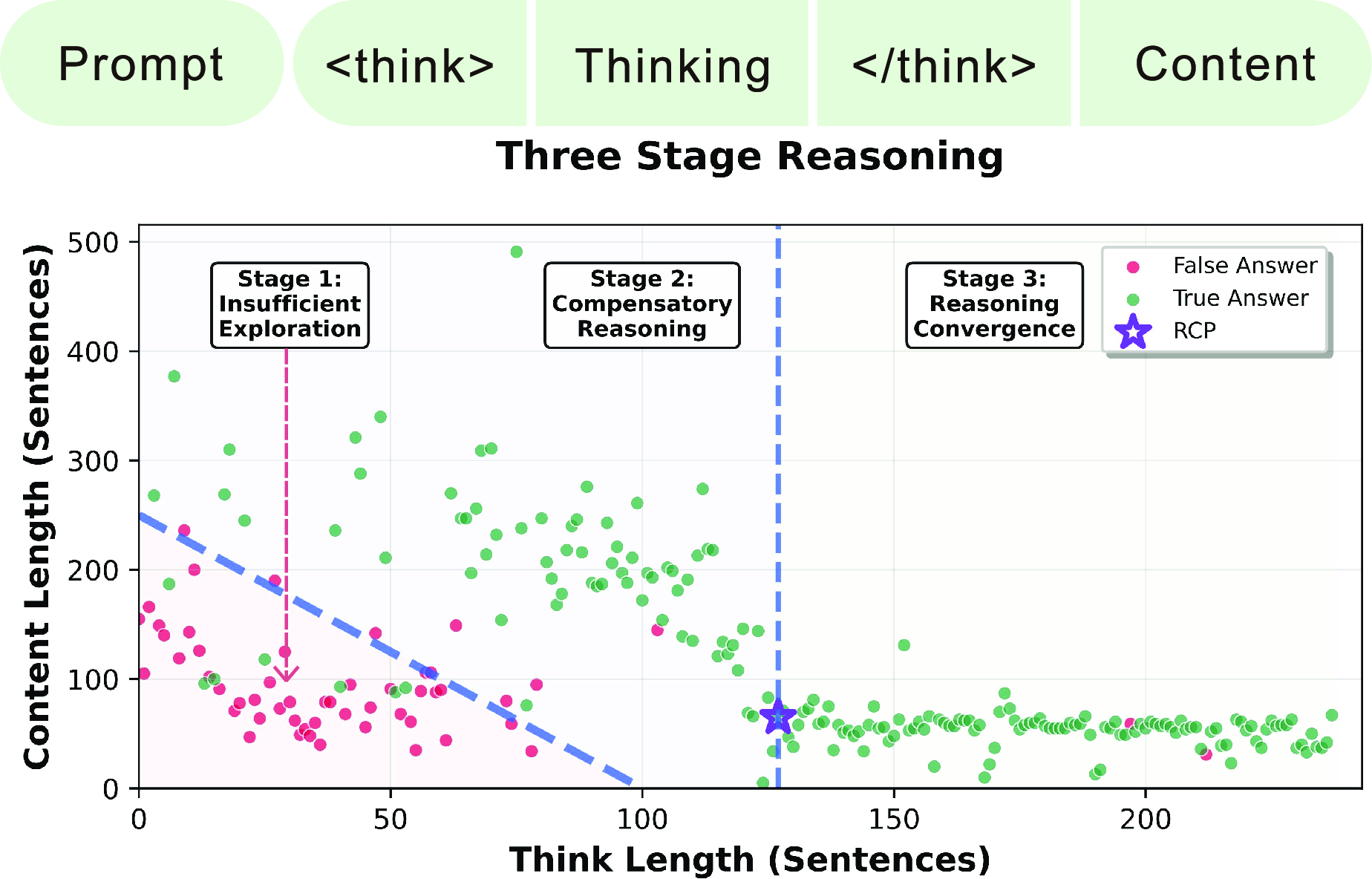
Figure 1: The stages of reasoning in LLMs, showing the point at which reasoning can be optimally terminated.
Identifying the Reasoning Completion Point (RCP)
The RCP is defined as the juncture at the end of the compensatory reasoning stage, where additional reasoning fails to yield improvements. Identifying the RCP is crucial for minimizing token usage while maintaining accuracy. The authors propose heuristic rules and a lightweight CatBoost model to predict the RCP accurately, balancing computational efficiency and detection precision.
Experimental Evaluation
Experiments were conducted on reasoning benchmarks like AIME24, AIME25, and GPQA-D, revealing that the proposed Reasoning Completion Point Detection (RCPD) strategy significantly reduces token usage (by over 30%) while maintaining or improving accuracy. The performance enhancements were evident across all tested LLM variants.
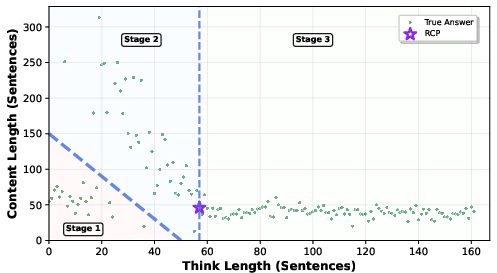
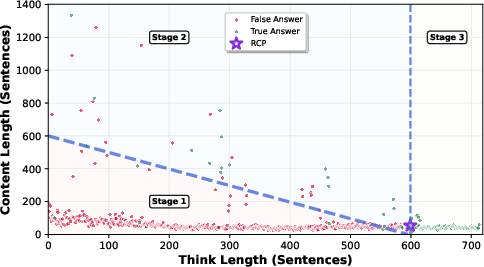
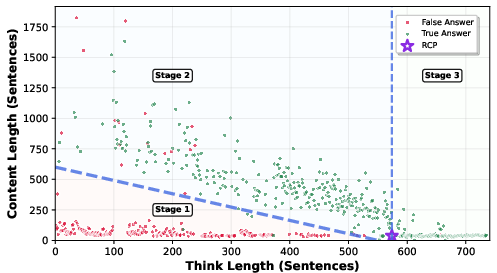
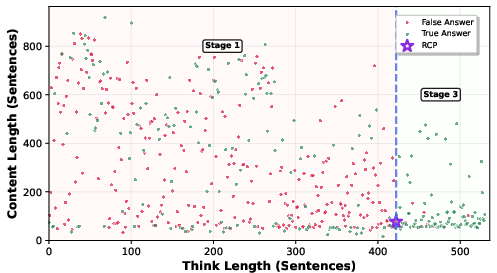
Figure 2: AIME24 Question 1 Three Stage Reasoning; illustrating the transition from compensatory reasoning to reasoning convergence.
Methodology for Early Termination
The paper introduces a method that dynamically adapts to each problem by identifying RCP in real-time. This approach surpasses fixed-budget methods or template-based triggering (e.g., Budget Force, No-Think, Deer) by identifying the RCP with high precision across diverse problem contexts.
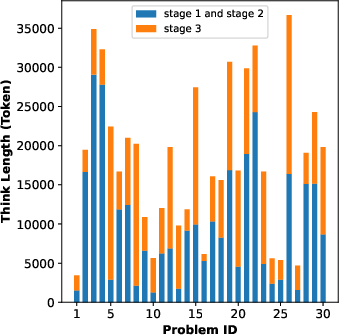
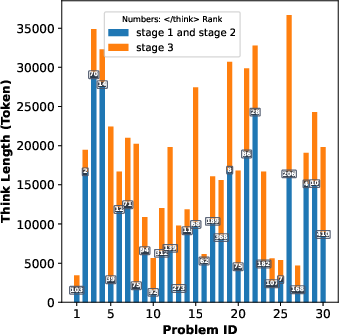
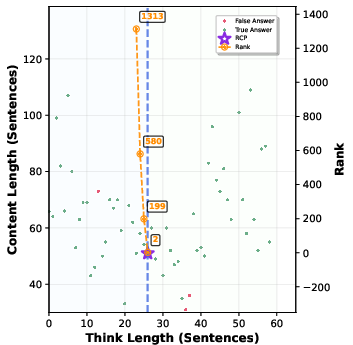
Figure 3: Token usage in DeepSeek-R1-0528, indicating considerable savings achieved by RCPD methods.
Conclusion
This research offers a systematic framework to address overthinking in LLMs, providing a practical solution that optimally balances computational resources and reasoning performance. Future work may explore deeper reflective mechanisms in LLMs to ensure that post-RCP reasoning genuinely contributes to accuracy without unnecessary repetition or over-extension.
The findings highlight the potential for further optimization in LLM reasoning processes, emphasizing the practical importance of efficient token usage in real-world applications.
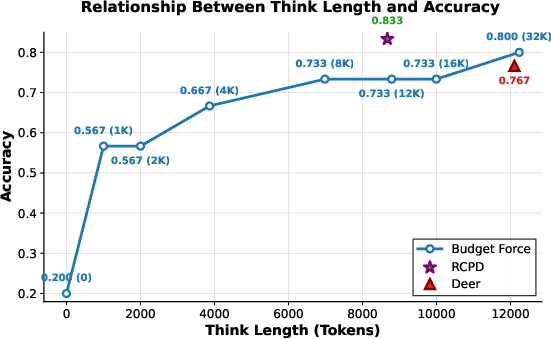
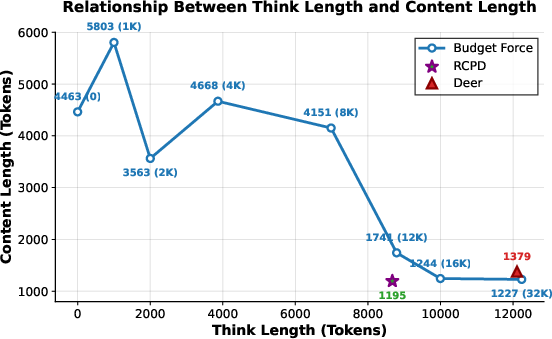
Figure 4: Relationship between think length and answer accuracy, showing the impact of identifying RCP on performance outcomes.