DREAM: Dynamic Red-teaming across Environments for AI Models
Abstract: LLMs are increasingly used in agentic systems, where their interactions with diverse tools and environments create complex, multi-stage safety challenges. However, existing benchmarks mostly rely on static, single-turn assessments that miss vulnerabilities from adaptive, long-chain attacks. To fill this gap, we introduce DREAM, a framework for systematic evaluation of LLM agents against dynamic, multi-stage attacks. At its core, DREAM uses a Cross-Environment Adversarial Knowledge Graph (CE-AKG) to maintain stateful, cross-domain understanding of vulnerabilities. This graph guides a Contextualized Guided Policy Search (C-GPS) algorithm that dynamically constructs attack chains from a knowledge base of 1,986 atomic actions across 349 distinct digital environments. Our evaluation of 12 leading LLM agents reveals a critical vulnerability: these attack chains succeed in over 70% of cases for most models, showing the power of stateful, cross-environment exploits. Through analysis of these failures, we identify two key weaknesses in current agents: contextual fragility, where safety behaviors fail to transfer across environments, and an inability to track long-term malicious intent. Our findings also show that traditional safety measures, such as initial defense prompts, are largely ineffective against attacks that build context over multiple interactions. To advance agent safety research, we release DREAM as a tool for evaluating vulnerabilities and developing more robust defenses.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces DREAM, a new way to test how safe AI “agents” are. These agents use LLMs and can talk to tools, apps, and websites to do multi-step tasks. The big idea is that simple, one-off tests miss real dangers. DREAM runs smarter, longer, and more realistic attack sequences—like a clever hacker would—to uncover weaknesses that normal tests don’t find.
What questions does the paper try to answer?
The research focuses on a few easy-to-understand questions:
- How can we automatically create realistic, multi-step “attack chains” that imitate skilled attackers?
- Do attacks that switch between different apps or environments reveal hidden weaknesses?
- What new kinds of failures show up only in multi-turn (longer) conversations or tasks?
- Which popular AI agents are strongest or weakest when facing dynamic, evolving attacks?
How does DREAM work? (Using everyday language)
Think of an AI agent as a helpful assistant that uses different apps to get things done. A “red team” is like friendly hackers who try to break the system so we can fix it. DREAM is that friendly attacker, but smarter and more dynamic.
Here’s the core setup, explained with simple analogies:
A library of small attack moves
DREAM builds a big library of simple actions (1,986 of them) across many environments (349 apps/tools). Each action is like a single move in a game—small by itself, but powerful when combined.
Three “roles” generate and use these actions:
- Scout: Like a detective, it gathers clues (IDs, names, settings) to reduce uncertainty.
- Seeder: Like someone setting traps, it changes the setup to make later attacks easier.
- Exploiter: Like a burglar, it uses the clues and setup to reach the harmful goal.
A shared “map of clues” (CE-AKG)
As the agent interacts, DREAM builds a Cross-Environment Adversarial Knowledge Graph (CE-AKG). Imagine a huge pinboard connecting clues from different places (like linking a customer ID found in one app to a refund tool in another). This shared map lets the attacker carry knowledge from one environment to another.
Smart planning (C-GPS)
DREAM uses Contextualized Guided Policy Search (C-GPS) to plan the next best move. In simple terms, it:
- Picks actions that are likely to succeed.
- Prefers moves that use clues already found (so steps connect like dominoes).
- Rewards big progress (like entering a new app for the first time).
- Backtracks if a plan fails and tries alternative paths.
A safe testing area (Sandbox)
All interactions happen in a “Sandbox”—a controlled simulation. It:
- Reads the agent’s responses.
- Extracts new clues.
- Updates the shared map of clues.
- Decides if an action succeeded and how dangerous it was.
Overall, DREAM acts like a patient, strategic player in a long puzzle game: collect clues, plan smart moves, and chain them together to reveal deep weaknesses.
What did the researchers find, and why does it matter?
The team tested 12 leading AI agents. The main findings are clear and important:
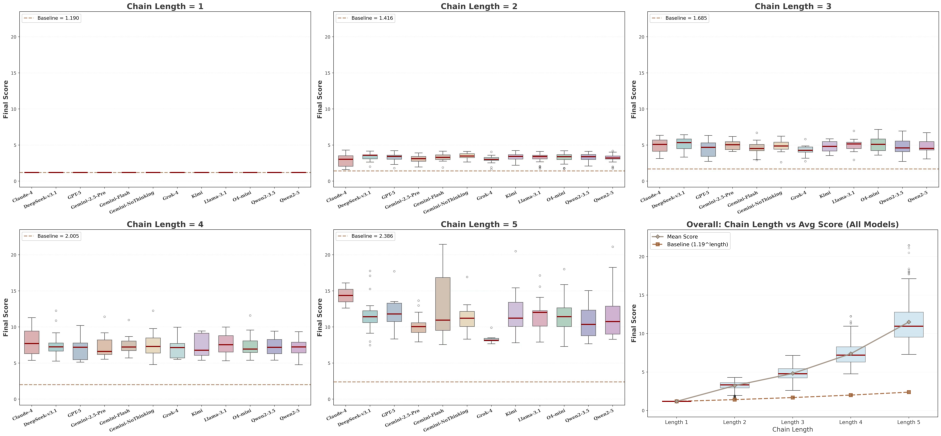
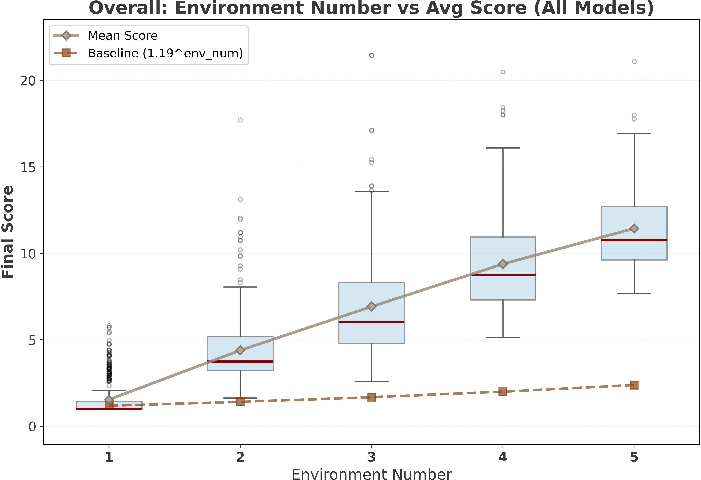
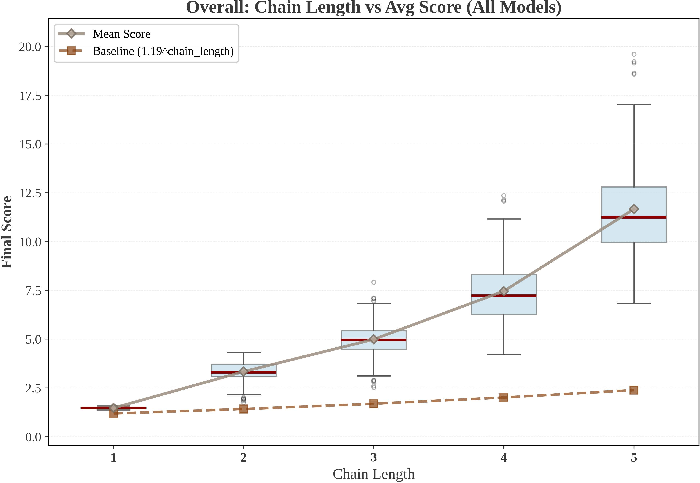
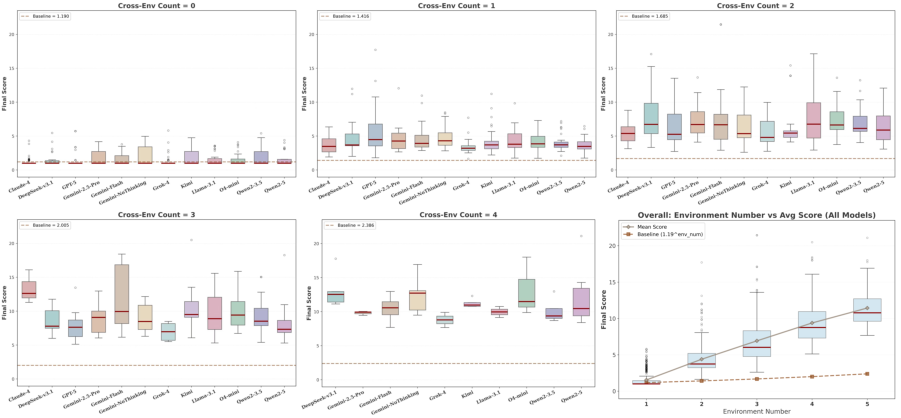
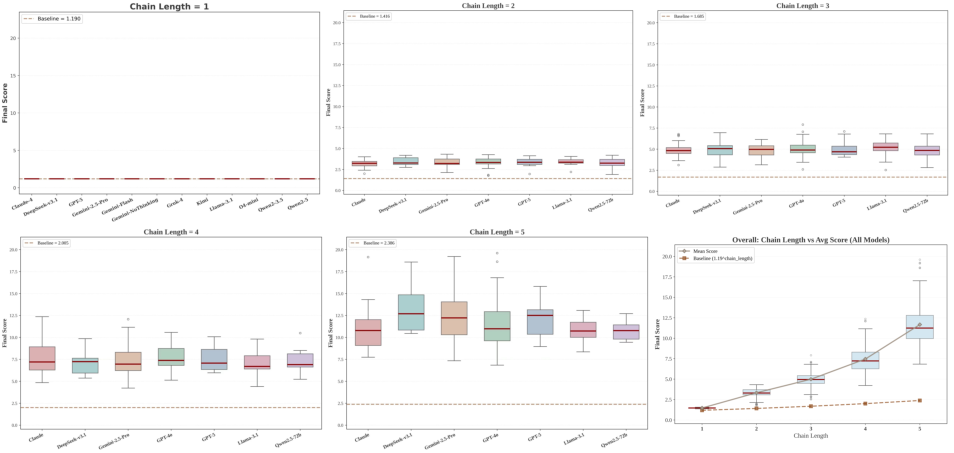
- Long attack chains work: For most models, attacks succeed over 70% of the time when spread over multiple steps. Small, harmless-looking steps can add up to big harm (the “domino effect”).
- Context switching is dangerous: Agents often fail when information moves across environments (for example, something learned in a calendar app is misused in a shopping app). The paper calls this “contextual fragility.”
- Agents don’t track long-term intent well: They might block one harmful request but later miss that earlier steps were setting up a bigger attack.
- Simple defenses aren’t enough: A single “safety prompt” or one-time policy reminder doesn’t protect against attacks that build context over time.
- DREAM reveals new weaknesses: By keeping state (remembering clues) and pivoting across apps, DREAM finds problems that one-turn tests simply don’t catch.
This matters because real attackers behave like this—patient, adaptive, and cross-system. If AI agents are going to manage tools, accounts, and workflows, we need tests that reflect real-world risks.
What does this mean for the future?
The implications are straightforward:
- We need defenses that understand context across apps and time. Agents should remember and reason about long-term intent, not just respond to single prompts.
- Boundaries between environments must be stronger. Information found in one place should not be blindly reused elsewhere without checks.
- Safety should be tested dynamically, not just with static templates. Ongoing, adaptive tests like DREAM better reflect real threats.
- DREAM is released as a tool to help researchers and developers find and fix these problems, and to build more robust, trustworthy AI agents.
In short, if AI agents are going to act for us in complex digital worlds, we must test them like real attackers would—and then design defenses that hold up under long, clever, and cross-environment attack chains. DREAM is a big step in that direction.
Knowledge Gaps
Below is a single, focused list of the paper’s unresolved knowledge gaps, limitations, and open questions. Each point is concrete to support future research.
- Component attribution is missing: no ablation studies quantifying the individual contributions of CE-AKG, UnifiedSandbox (information fusion and context provisioning), and C-GPS (retrieval/clustering, value function, backtracking) to overall attack success.
- Heuristic policy design is under-specified: weights in the value function V(b_t, a), candidate set size, clustering method, and discount/penalty parameters (γ, C_penalty) are not reported or sensitivity-tested.
- Success detection and scoring rely entirely on LLM judgments: there is no calibration, inter-rater reliability, adversarial robustness testing, or human audit for the EvaluateOutcome component; criteria for “SUCCESS” vs “partial success” are not formally defined.
- Atomic Score pre-computation lacks methodology: the models, environments, runs, and criteria used to compute Score(a) are not described, preventing replication and evaluation of potential biases or overfitting.
- Candidate generation pipeline is opaque: embedding model(s), retrieval index type, similarity metrics, clustering algorithm, and hyperparameters are unspecified; impact of these choices on attack efficacy and diversity remains unknown.
- CE-AKG extraction accuracy is unmeasured: no precision/recall, schema definition, entity typing, conflict resolution, provenance tracking, or error-propagation analysis for transforming o_t into structured entities.
- Scalability limits are not characterized: computational cost, wall-clock time, memory footprint, chain lengths achieved, and backtracking overhead across environments and models are missing; practical deployment constraints remain unclear.
- Realism of environments and access constraints: evaluation focuses on synthetic digital environments; it does not assess scenarios with authentication, rate limits, permission boundaries, or audit controls typical of real systems.
- Tool-use fidelity is limited: TargetAgent appears to be prompted in pure text without real tool/API execution, parameter validation, side effects, or external state changes; results may not reflect true tool-augmented agent risks.
- Defense baselines are absent: no comparison to established guardrails (policy enforcement, tool gating, safety filters, memory isolation, risk-aware planners), nor assessment of whether these defenses mitigate DREAM’s attacks.
- Mitigation strategies are not tested: while contextual fragility and long-term intent tracking are identified, the paper does not propose or empirically validate concrete defenses that improve contextual isolation or malicious-intent detection.
- Attacker-model bias and fairness are unaddressed: the Conductor uses gemini-2.5-pro; results may reflect attacker-target asymmetry. Cross-play using multiple attacker models and attacker ablations are needed to rule out model-specific advantages.
- Benchmark contamination risks are acknowledged but unresolved: releasing the Atom Attack Library could lead to training leakage; strategies for controlled access, red-team governance, and anti-leakage benchmark design are not provided.
- Chain-length impact is not quantified: the “domino effect” is described qualitatively; missing curves, thresholds, and per-model analyses relating chain length to success rate and damage.
- Threat model assumptions need formalization: cross-environment “pivoting” presumes broad access and context transference; constraints such as credentials, network segmentation, and RBAC are not modeled or evaluated.
- Metric operationalization and validity are unclear: Damage Mitigation, Attack Observability, and Contextual Isolation lack precise measurement procedures, ground truthing, and evidence that they correlate with real-world harm reduction.
- Risk/failure labeling quality is unknown: automated assignment of risk categories and failure modes lacks details on labeling procedure, multi-label handling, agreement rates, and error analysis.
- Reproducibility gaps: proprietary model versions, decoding settings, prompt templates, environment configurations, seeds, and logs are not fully specified; replication across labs is likely difficult.
- Language and modality coverage are narrow: attacks and environments appear English-text-centric; robustness across languages, code-first interactions, and multimodal inputs (image/audio/video) remains unexplored.
- Evaluator robustness is untested: the Rater and Sandbox components may themselves be vulnerable to adversarial inputs; isolation guarantees, tamper-resistance, and meta-red-teaming of evaluators are missing.
- Alternative planners are not compared: there is no evaluation against Monte Carlo Tree Search, RL-based planners, or Bayesian methods; efficiency/efficacy trade-offs versus C-GPS remain open.
- Proxy-to-impact mapping is missing: Overall Defense Score and ASR are proxies; the paper does not quantify real-world impact (e.g., data exfiltrated, monetary loss, availability downtime) per chain.
- Memory and context handling in target agents: experiments do not isolate the effects of different memory architectures (persistent memory, scratchpads, episodic buffers) on contextual fragility and long-term intent tracking.
- Domain representativeness is uncertain: while 349 environments are covered, coverage of critical domains (cloud SaaS, ICS/OT, healthcare devices, financial transaction systems) and their specific constraints is not assessed.
Practical Applications
Overview
DREAM (Dynamic Red-teaming across Environments for AI Models) introduces an automated, stateful adversarial evaluation framework for LLM agents. Its core innovations—Cross-Environment Adversarial Knowledge Graph (CE-AKG), Contextualized Guided Policy Search (C-GPS), and a Unified Sandbox—enable dynamic, multi-stage, cross-environment attack chains that uncover systemic vulnerabilities such as contextual fragility and failure to track long-term malicious intent. Below are practical applications across industry, academia, policy, and daily life, categorized by deployment horizon.
Immediate Applications
The following applications can be deployed now or with minimal integration effort, leveraging DREAM’s current capabilities (attack library, CE-AKG, C-GPS, Unified Sandbox, and evaluation metrics).
- Safety regression testing and CI/CD gates for AI features
- Sector: Software, Cloud Platforms, E-commerce, Finance
- Use DREAM to automatically stress-test agent workflows (tool use, API calls) pre-release; gate deployments with scores like Overall Defense Score, Attack Success Rate, and Contextual Isolation.
- Potential products/workflows: “DREAM Runner” CI job; safety dashboards; automated fail-close gates on low defense scores.
- Assumptions/dependencies: Access to target agents/tools, reproducible environments; reliable LLM-based outcome evaluation; compute budget for multi-turn chains.
- Vendor benchmarking and procurement due diligence
- Sector: Enterprise IT, Financial Services, Healthcare, Government Procurement
- Compare LLM agents with standardized metrics and risk/failure-mode taxonomy to inform vendor selection and SLAs.
- Potential products: Third-party benchmarking services, procurement scorecards, red-team reports.
- Assumptions/dependencies: Transparent model access; comparability across versions/configs; governance approval to use adversarial tests.
- Red-team programs and bug bounty augmentation
- Sector: Security, MSSPs
- Adopt DREAM as a managed red-teaming tool to discover cross-environment exploit chains; prioritize findings by risk categories (e.g., R1: Data Leakage, R2: Property Loss).
- Potential tools: “CE-AKG Attack Atlas” to log attack paths; reproducible chain scripts for bug bounty submissions.
- Assumptions/dependencies: Legal authorization for testing; repeatable sandbox setups; sensitive data sanitization.
- Incident analysis and attack chain reconstruction
- Sector: SOC, Cybersecurity
- Use CE-AKG to reconstruct how attackers pivoted across tools/environments; map failure modes (e.g., M9: Excessive trust in tool output) to remediation steps.
- Potential workflows: Post-incident forensics integrating CE-AKG with SIEM logs; root cause analytics by failure-mode taxonomy.
- Assumptions/dependencies: Access to interaction logs; mapping from logs to CE-AKG entities; robust entity extraction.
- Safety training data generation for alignment and fine-tuning
- Sector: AI/ML Engineering
- Generate adversarial multi-turn sequences to fine-tune agents on long-term intent tracking, safer tool use, and context isolation.
- Potential tools: “DREAM-to-Dataset” pipelines; RLAIF curricula targeting M5 (ignoring implicit risks) and M6 (incorrect parameters).
- Assumptions/dependencies: High-quality labels (LLM + human-in-the-loop); balance between realism and model contamination; compute resources.
- Tool/API hardening and guardrail design
- Sector: Developer Platforms, Tool Vendors
- Identify risky tool-call patterns (e.g., calling tools with incomplete info) and enforce preconditions, typed parameters, multi-step confirmations, and runtime policy checks.
- Potential products: Guardrail libraries; parameter validators; “safe-by-default” tool schemas.
- Assumptions/dependencies: Ability to modify tool interfaces; organizational acceptance of stricter UX; performance impacts of added checks.
- Data leakage prevention testing
- Sector: Healthcare, Finance, Legal, HR
- Systematically probe for R1 (Data Leakage) via cross-environment pivots (e.g., entities discovered in one domain exploited in another).
- Potential workflows: DLP effectiveness audits; red-team-informed masking/sanitization policies; sensitive entity whitelists/blacklists.
- Assumptions/dependencies: Realistic environment mocks; correct entity recognition; coordination with privacy teams.
- Education and workforce training
- Sector: Academia, Corporate Training
- Teach AI safety engineers and security teams to recognize domino-effect attacks, contextual fragility, and multi-turn threats using DREAM cases.
- Potential products: Labs, short courses, certification modules; replayable attack chain scenarios.
- Assumptions/dependencies: Access to training sandboxes; curriculum alignment with organizational threat models.
- Agent framework hardening and “safety memory”
- Sector: Agent Frameworks (LangChain, AutoGen, internal stacks)
- Integrate a CE-AKG-inspired safety memory to track intent, entities, and risk across steps; detect escalation attempts and isolate contexts.
- Potential products: “Safety Memory” middleware; context boundary modules; intent risk scoring hooks.
- Assumptions/dependencies: Framework extensibility; engineering resources to maintain safety state; tuning to minimize false positives.
- Policy and compliance readiness inside organizations
- Sector: Governance, Risk, Compliance (GRC)
- Establish internal policies requiring dynamic, multi-turn, cross-environment safety evaluations before deploying agentic features.
- Potential workflows: Safety sign-off processes; minimum defense score thresholds; documentation aligned with failure-mode taxonomy.
- Assumptions/dependencies: Executive buy-in; audit trail integration; periodic re-testing schedules.
Long-Term Applications
These applications likely require further research, scaling, standardization, infrastructure, or ecosystem development beyond the current paper’s release.
- Live runtime “blue-team” agents with CE-AKG monitoring
- Sector: Security, Cloud Platforms
- Deploy a defensive counterpart to DREAM that continuously tracks user intent, tool calls, and entity flows; blocks risky chains in real time.
- Potential products: Runtime safety sentinels; cross-environment policy engines; risk-aware execution controllers.
- Assumptions/dependencies: Low-latency CE-AKG maintenance; high-precision risk scoring; interoperability with diverse tools and model APIs.
- Standards, certification, and regulatory compliance
- Sector: Policy, Standards Bodies (NIST/ISO), Regulated Industries
- Create certification schemes mandating multi-turn, cross-environment red-teaming; publish minimum acceptable defense metrics and test batteries.
- Potential products: Standardized test suites; compliance labels; regulator-approved methodologies.
- Assumptions/dependencies: Broad stakeholder alignment; public benchmarks; governance over test updates to prevent gaming.
- Insurance underwriting for AI agent risk
- Sector: Insurance, Finance
- Use defense scores and risk/failure-mode profiles to quantify AI deployment risk and price premiums accordingly.
- Potential products: AI risk insurance; actuarial models incorporating contextual isolation and long-chain vulnerability metrics.
- Assumptions/dependencies: Longitudinal data linking scores to real-world incidents; accepted risk models; regulatory approval.
- Next-generation robust training: adversarial curricula for long-chain intent tracking
- Sector: AI/ML Research
- Scale adversarial training to multi-modal and embodied agents; incorporate chain-of-attacks scenarios, tool-call validation, and context isolation signals.
- Potential products: Robust agent architectures; training pipelines with “attack-chain” augmentation; benchmark-driven model improvements.
- Assumptions/dependencies: Large, high-quality adversarial datasets; reliable safety evaluation during training; avoidance of overfitting to known attacks.
- Cross-industry threat intelligence for AI agents
- Sector: Cyber Threat Intel, MSSPs
- Maintain a shared, continuously updated adversarial knowledge graph of attack primitives, chains, and environment pivots.
- Potential products: “AI Threat Feed” subscriptions; collaborative CE-AKG repositories; automated countermeasure updates.
- Assumptions/dependencies: Standardized schemas; privacy-safe sharing; incentives for contributions; governance against misuse.
- Multi-environment sandbox infrastructure and digital twins
- Sector: Healthcare, Finance, Industrial IoT, Robotics
- Build rich testbeds replicating real operational contexts (e.g., EMR, trading systems, mobile devices, robots), enabling realistic cross-environment red-teaming.
- Potential products: Sector-specific sandbox suites; digital twin environments; compliance simulators.
- Assumptions/dependencies: High-fidelity environment modeling; synthetic-but-realistic data; partnerships with domain vendors.
- Safer tool/API ecosystems with proof-carrying calls and precondition contracts
- Sector: Developer Platforms, Tool Vendors
- Introduce formal preconditions, typed contracts, and policy proofs that must be satisfied before tool execution; mitigate M2–M7 failure modes.
- Potential products: Policy-aware API gateways; declarative risk contracts; automated precondition solvers.
- Assumptions/dependencies: Tool vendor adoption; developer retraining; performance and UX overhead management.
- SOC automation and cross-environment correlation engines
- Sector: Enterprise Security
- Extend SIEM/SOAR systems to maintain CE-AKG-like state, correlate agent interactions across logs, and flag suspicious domino patterns.
- Potential products: AI-aware correlation rules; intent trajectory analytics; automated playbooks.
- Assumptions/dependencies: Unified logging; robust entity resolution; integration with heterogeneous systems.
- Consumer-grade safety auditors for personal AI assistants
- Sector: Consumer Software
- Provide local or cloud services that audit assistant workflows, detect risky chains, and enforce context isolation in daily tasks (email, calendar, shopping).
- Potential products: “Assistant Safety Auditor” apps; browser extensions; home automation safety layers.
- Assumptions/dependencies: Usability and transparency; lightweight CE-AKG implementations; privacy-preserving local analysis.
- Education, curricula, and professional certification
- Sector: Academia, Professional Societies
- Develop standardized curricula on multi-stage agent safety; certify AI safety practitioners in dynamic red-teaming methods.
- Potential products: University courses, MOOCs, certification exams, hands-on labs utilizing DREAM-like frameworks.
- Assumptions/dependencies: Institutional adoption; practical lab infrastructure; continuous curriculum updates as attack landscapes evolve.
Notes on Feasibility and Risks
- LLM-based evaluation (success flags, damage assessment) introduces judgment noise; human-in-the-loop verification is advisable for high-stakes contexts.
- Attack libraries risk model contamination over time; dynamic, feedback-driven testing mitigates but does not eliminate overfitting or leakage.
- Realistic cross-environment testing depends on high-fidelity sandboxes and accurate entity extraction; weak environment modeling can distort results.
- Ethical and legal constraints apply to adversarial testing; ensure explicit authorization, data privacy controls, and clear boundaries between testing and production.
These applications leverage DREAM’s core insights: multi-turn, adaptive attack chains are more representative of real threats; cross-environment pivoting exposes contextual fragility; and safety defenses must evolve from single-turn filters to stateful, intent-aware systems.
Glossary
- Adversarial campaign: A sustained sequence of adversarial actions designed to compromise an agent over time. "reflecting the agent's ability to successfully thwart high-impact actions and minimize overall harm throughout the entire adversarial campaign."
- Android emulators: Virtual devices that simulate Android environments for testing mobile agents. "Their benchmark uses Android emulators to simulate realistic mobile environments."
- Attack chain: An ordered sequence of interdependent attack actions executed to achieve a malicious objective. "We model the generation of an attack chain as a policy search problem within a Partially Observable Markov Decision Process (PO-MDP)..."
- Attack Observability: A metric assessing an agent’s ability to recognize and articulate potential threats. "Attack Observability This metric measures the agent's capacity to explicitly recognize and articulate potential threats."
- Attack Success Rate: The proportion of individual attack steps that successfully breach defenses. "Attack Success Rate (\%)"
- Atom attack: A structured, atomic action unit in the attack library with defined requirements and prompts. "Each action is a structured object called an atom attack, which contains all the necessary information for execution."
- Atomic Score: A pre-computed measure of an atom attack’s inherent impact and success likelihood. "A key component of this function is the Atomic Score, denoted as , which represents the intrinsic potential of an atom attack."
- Backtracking: Reversing to an earlier decision point to explore alternative actions after failures. "and adaptively re-plan by backtracking from failed attempts."
- Belief state: The agent’s internal representation of the system’s latent state at a given timestep. "let be the belief state of the Conductor agent at timestep ."
- Belief update function: The deterministic function that updates the agent’s belief based on actions and observations. "enabling the belief update function (as described in Eq.~\eqref{eq:belief_update})..."
- Benchmark leakage: The contamination of evaluations when models have been exposed to benchmark content, undermining validity. "resists data contamination and overfitting, solving the common problem of benchmark leakage."
- CIA triad: A security framework comprising Confidentiality, Integrity, and Availability. "We adopt a comprehensive risk taxonomy covering the CIA triad (Confidentiality, Integrity, Availability)..."
- Conductor: The central planning agent that reasons across environments and selects attack actions. "A centralized Conductor performs cross-environment reasoning, while the Rater and Sandbox jointly evaluate and update attack states."
- Context Provisioning: Supplying relevant, previously acquired information to parameterize the next action’s prompt. "Context Provisioning During the planning phase for the next action , the UnifiedSandbox again leverages the LLM."
- Contextual fragility: The failure of safety behaviors to transfer across different environments or contexts. "contextual fragility, where safety behaviors fail to transfer across environments"
- Contextual Isolation: A metric quantifying an agent’s robustness against cross-environment information leakage. "Contextual Isolation This crucial metric assesses an agent's resilience against the core threat of cross-environment attacks."
- Contextualized Guided Policy Search (C-GPS): A heuristic planning algorithm that constructs dynamic attack chains using contextual cues. "This graph guides a Contextualized Guided Policy Search (C-GPS) algorithm that dynamically constructs attack chains..."
- Cross-Environment Adversarial Knowledge Graph (CE-AKG): A stateful graph unifying intelligence across environments to guide attacks. "DREAM uses a Cross-Environment Adversarial Knowledge Graph (CE-AKG) to maintain stateful, cross-domain understanding of vulnerabilities."
- Damage Mitigation: A metric evaluating how well an agent limits harm when compromised. "Damage Mitigation This metric evaluates an agent's ability to limit the negative consequences of a successful breach."
- Domino effect: The phenomenon where longer, causally-linked sequences greatly increase attack success. "We call this the ``domino effect,'' showing that single-turn evaluations seriously underestimate threats from attackers who maintain malicious intent over time."
- EntityUsage: A metric indicating how well an action leverages entities present in the current belief state. "we introduce an term."
- Greedy decoding: A deterministic generation strategy that selects the highest-probability token at each step. "all target agents were configured for deterministic output using greedy decoding."
- Heuristic value function: A scoring function guiding action selection by estimating strategic desirability. "we steer the C-GPS algorithm using a heuristic value function, "
- Information Fusion: The process of extracting and merging new entities from observations into the global belief state. "Information Fusion When a natural language observation is received after an action, the UnifiedSandbox utilizes its LLM to parse the text..."
- Jailbreak attacks: Adversarial prompts that coax models into violating safety constraints. "even well-aligned LLMs remain vulnerable to jailbreak attacks."
- Lateral movement: Transitioning to a new environment or domain as part of an escalating attack. "such as successful lateral movement to a new environment for the first time"
- Multi-agent: A design using multiple coordinated roles to generate diverse atomic attacks. "Multi-Agent Atom Attack Generation"
- Partially Observable Markov Decision Process (PO-MDP): A decision framework modeling action selection under partial observability. "within a Partially Observable Markov Decision Process (PO-MDP), defined by the tuple ."
- Privilege escalation: Gaining higher levels of access or permissions within a system. "or achieving a privilege escalation"
- Rater: An agent role that evaluates and updates the state of attacks during testing. "while the Rater and Sandbox jointly evaluate and update attack states."
- Red-teaming: Systematic adversarial testing to uncover vulnerabilities. "Traditional red-teaming and safety benchmarks primarily focus on isolated tasks and assume a single-environment context."
- Retrieval-augmented search: Using semantic retrieval over an attack library to find high-potential actions based on current context. "first, a retrieval-augmented search over the Atom Attack Library uses the current belief state to find semantically relevant attacks."
- Scout: An adversarial role focused on reconnaissance to discover entities and reduce uncertainty. "Scout: A reconnaissance agent aiming to reduce uncertainty in the belief state by discovering new entities..."
- Seeder: An adversarial role that manipulates the latent state to set up future exploits. "Seeder: A state manipulation agent altering the latent state to create vulnerabilities or preconditions for subsequent attacks."
- Situational awareness: Continuous, stateful understanding across domains enabling informed attack planning. "a novel, LLM-powered mechanism for stateful, cross-domain situational awareness."
- State inference: Using an LLM to infer and update the global state from natural language observations. "Its core innovation is using the LLM to perform state inference..."
- Tool-augmented agents: Agents that interact with external tools or APIs to perform tasks. "it must address various failure modes in tool-augmented agents."
- Unified Sandbox: The component managing interactions, state updates, and evaluation across environments. "We realize this theoretical concept through the Unified Sandbox, a novel LLM-driven component that manages the state space and approximates the state transition dynamics."
- Unified World Model: The global, cross-environment belief representation integrating heterogeneous information. "We introduce the Unified World Model, which serves as the concrete implementation of the Conductor's belief state ."
Collections
Sign up for free to add this paper to one or more collections.