- The paper presents an RL framework where attacker LLMs generate diverse harmful prompts, boosting attack success rates from 0.07% to 31.28%.
- It employs periodic safety fine-tuning of the victim LLM to force attackers into exploring new adversarial vulnerabilities and prevent mode collapse.
- The adaptive exploration strategy reduces reliance on manual prompt engineering and offers scalable improvements in LLM safety assessment.
Active Attacks: Red-teaming LLMs via Adaptive Environments
Introduction
The paper "Active Attacks: Red-teaming LLMs via Adaptive Environments" (2509.21947) addresses the challenge of generating diverse and harmful prompts for LLMs to enhance safety fine-tuning. Manual prompt engineering for red-teaming is prevalent but limited in scope and expensive. The authors propose an automated method using reinforcement learning (RL) to train attacker LLMs to generate harmful prompts using a toxicity classifier as a reward function. This approach is inspired by active learning, facilitating adaptive exploration to discover diverse attack modes.
Rather than a fixed environment, the algorithm periodically fine-tunes the victim LLM with existing attack prompts, diminishing the reward of already exploited regions and pushing the attacker LLM to unexplored vulnerabilities, creating an easy-to-hard exploration curriculum.
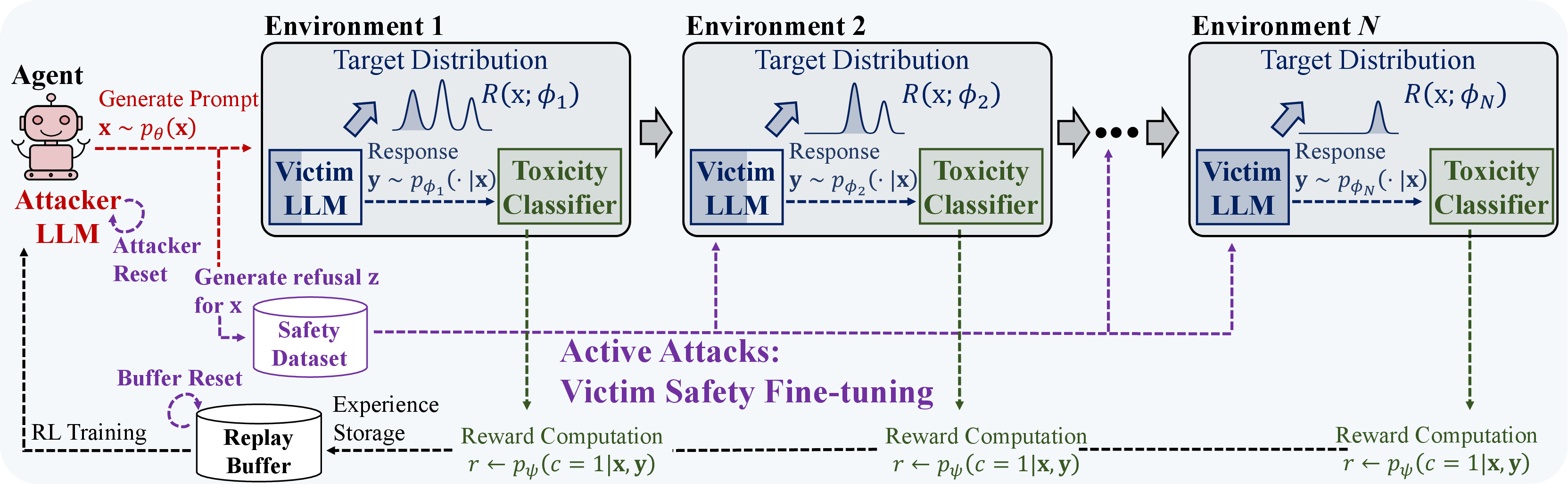
Figure 1: Red-teaming LLMs via adaptive environments. Prior works train an agent (attacker LLM) with a fixed environment (victim LLM and toxicity classifier). In Active Attacks, we periodically safety fine-tune the victim LLM to make the environment adaptive and reinitialize the attacker LLM and replay buffer.
Methodology
The red-teaming framework consists of two main components:
- Victim LLM (pϕ): Model producing responses to prompts.
- Attacker LLM (pθ): Agent generating candidate prompts to elicit harmful responses.
The RL process involves generating prompts, receiving responses, evaluating with a toxicity classifier, and updating the attacker policy. The primary goal is to discover not just harmful but diverse prompts across different reward landscape modes. Standard RL often collapses to optimizing a few easy-to-exploit modes.
The proposed Active Attacks framework integrates active learning principles with GFlowNet multi-mode sampling. This involves adaptive modifications through periodic safety fine-tuning of the victim LLM, prompting the attacker to explore new vulnerabilities. Re-initialization of the attacker prevents overfitting to previously learned modes.
The attacker optimization uses a trajectory balance objective to enable off-policy training, improving mode coverage significantly.
Results
Active Attacks demonstrate substantial improvements over previous RL methods in red-teaming, notably boosting cross-method attack success rates to unprecedented levels. The approach showed a remarkable increase from 0.07% to 31.28% in success rates against GFlowNets, highlighting its efficiency.
The experiments further validate the approach's capability to generate diverse, effective, harmful prompts within computational constraints. Active Attacks showed minimal increases in computational time compared to other state-of-the-art methods.

Figure 2: Cross-model attack success rate between GFlowNet and GFlowNet + Active Attacks. Experimental results for other red-teaming approaches are presented in \Cref{app:main-cross.
Implications and Future Work
The adaptive environment significantly enhances exploration depth, indicating broader implications for improving automated red-teaming processes and LLM safety fine-tuning. It reduces reliance on human-crafted datasets and manual intervention, paving the way for more autonomous, scalable approaches to capturing a wider range of adversarial inputs.
Future research may focus on extending Active Attacks to diverse LLM architectures and exploring its applications in real-world deployment scenarios. Given its success, further investigation on combining active learning with other RL formulations may unlock additional improvements in safety measures for AI models.
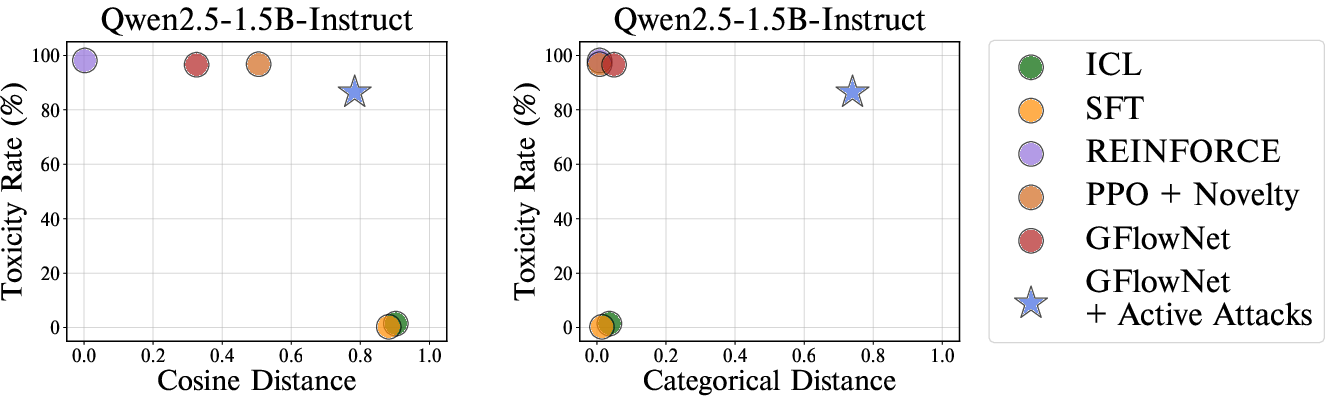
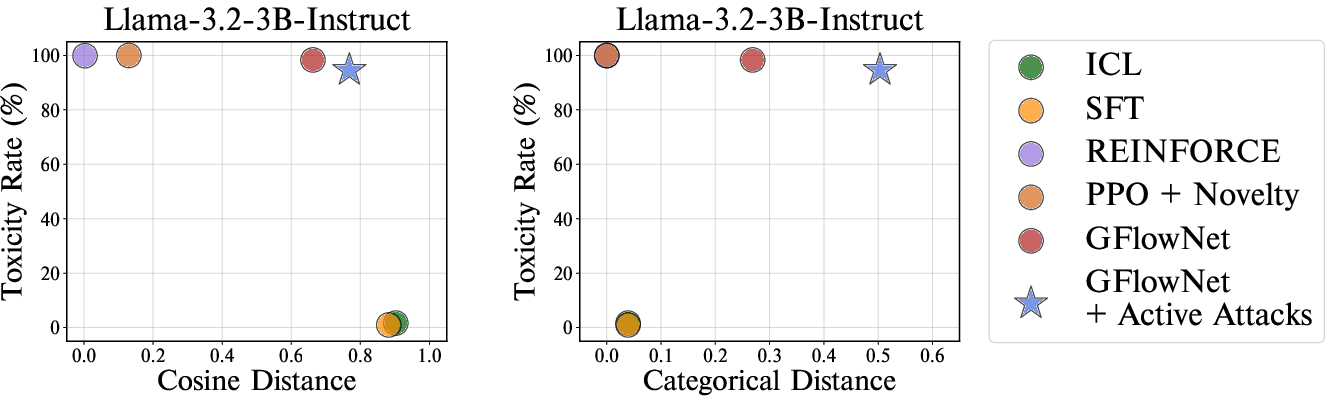
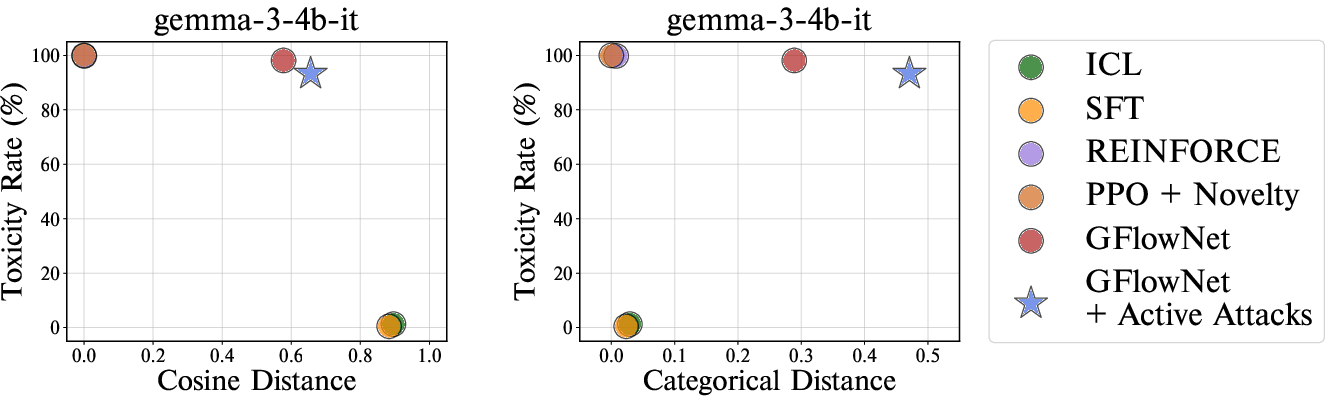
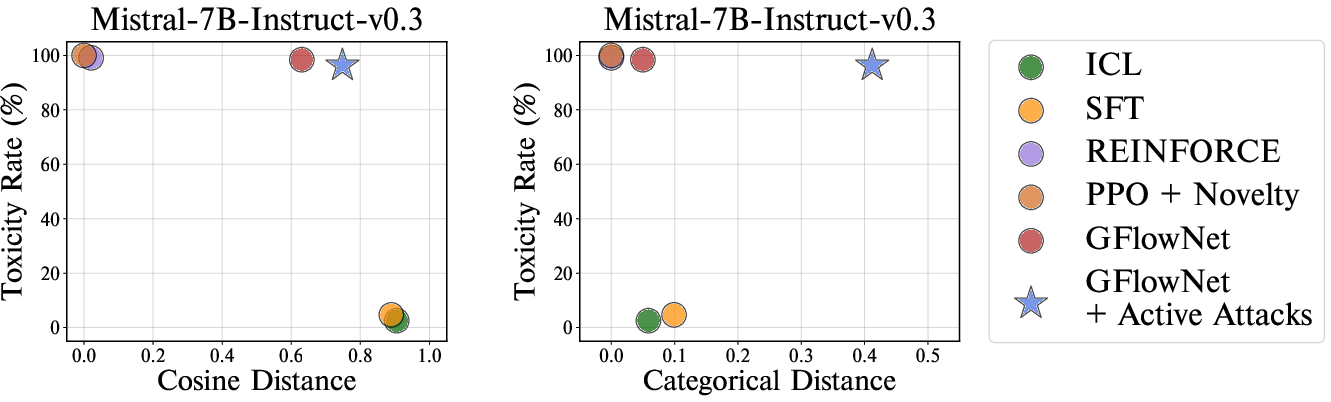
Figure 3: Toxicity-diversity trade-off of different red-teaming approaches on various victim LLMs. Active attacks successfully generate diverse prompts in terms of categorical distance.
Conclusion
Active Attacks presents a novel, efficient, and effective method for automated red-teaming of LLMs, achieving significant performance gains through adaptive exploration strategies. The methodology offers promising directions for future research in enhancing AI safety mechanisms without extensive computational overhead, marking substantial progress in LLM security practices.

