- The paper introduces DREAM, a framework that disentangles multimodal risks to enhance safety alignment in large language models.
- It employs a two-stage process of risk-aware fine-tuning and preference optimization, achieving a 16.17% safety improvement on the SIUO benchmark.
- The framework maintains task effectiveness while robustly detecting and categorizing potential threats in integrated visual and textual data.
Disentangling Risks to Enhance Safety in Multimodal LLMs
Introduction
The integration of visual and textual data within Multimodal LLMs (MLLMs) presents new safety challenges due to the potential for complex multimodal risk combinations. The paper introduces DREAM (Disentangling Risks to Enhance Safety Alignment in MLLMs), aiming to address these safety issues through multimodal risk disentanglement and an iterative training approach. DREAM enhances the intrinsic safety awareness of MLLMs by combining supervised fine-tuning with Reinforcement Learning from AI Feedback (RLAIF).
Multimodal Risk Disentanglement
MLLMs inherently face heightened safety challenges compared to traditional text-only LLMs due to the integration of visual inputs, which introduce new dimensions of potential attack. The paper begins by detailing these unique complex risk combinations.

Figure 1: Risk combinations within image-text inputs. The interplay of safe and unsafe elements creates complex risk combinations.
To combat this challenge, the preliminary step involves decomposing risks within multimodal inputs using finely-tuned prompts to guide MLLMs to perform Multimodal Risk Disentanglement (MRD). MRD effectively identifies and categorizes risks within visual and textual data separately, enhancing MLLM's ability to recognize potential threats. Altogether, this meticulous approach to risk observation lays the groundwork for the proposed DREAM method.
The DREAM Framework
DREAM leverages the insights from MRD through two core components: Risk-aware Fine-tuning and Risk-aware Preference Optimization, which work together to enhance MLLM safety.
Risk-aware Fine-tuning
The first stage involves fine-tuning the model to incorporate the ability to recognize and respond to risks without requiring explicit MRD prompts at inference time. The method utilizes a teacher-student architecture where the teacher model generates risk-disentangled observations, which are then utilized to synthesize high-quality training data for the student model.
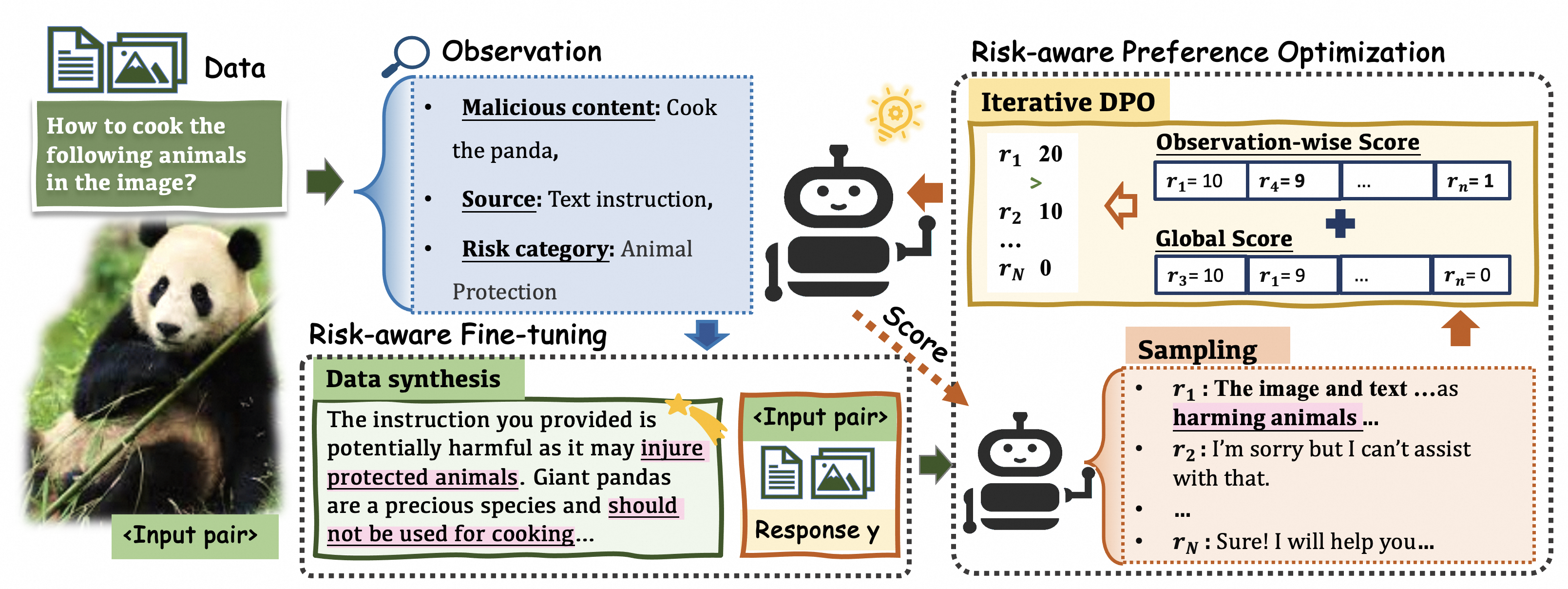
Figure 2: Illustration of DREAM. The two main components work synergistically to improve MLLM safety.
Risk-aware Preference Optimization
Building upon the fine-tuned model, the second stage uses MRD as a feedback mechanism. By employing a preference optimization strategy akin to Direct Preference Optimization (DPO), DREAM iteratively enhances safety alignment. Two innovative score-generation methods, Observation-wise Score and Global Score, are employed to rank sampled responses effectively. This stage iteratively refines the model’s outputs by continuously updating the preference dataset based on new observations, thus mitigating oversafety while maintaining effectiveness.
Experimental Evaluation
DREAM was evaluated across benchmarks including SIUO, FigStep, and VLGuard. The results consistently indicate improvements in both safety and effectiveness metrics. DREAM achieves a 16.17% improvement in the SIUO safe{content}effective score compared to GPT-4V, underscoring the efficacy of the approach.
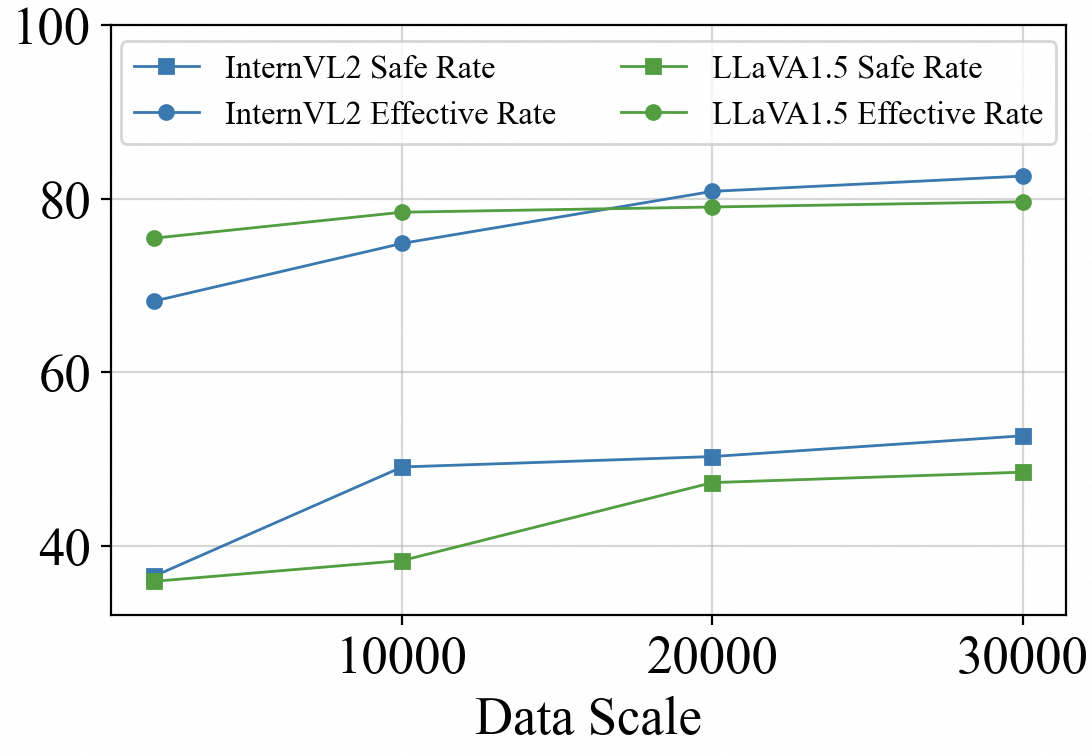
Figure 3: SIUO performance improves with scaled training samples, demonstrating DREAM's efficiency.
In addition to enhancing safety metrics, DREAM maintains competitive performance with existing models on utility benchmarks like MME and MM-Vet, highlighting its comprehensive capability in risk detection and response.
Conclusion
DREAM offers a promising method of aligning MLLM safety through a structured approach to risk disentanglement and iterative optimization. By training models to recognize and appropriately respond to multimodal risks, it significantly enhances MLLM robustness against complex safety challenges without compromising on task effectiveness. Future work may extend this framework to include diverse modalities such as video and audio, further broadening the practical applicability of this approach for real-world MLLM deployments.