- The paper introduces ARLAS, a novel adversarial reinforcement learning framework that trains LLM agents in a two-player zero-sum Markov game to defend against indirect prompt injections.
- It employs a co-training process using attacker and agent models with GRPO optimization, reducing cyclic learning and enhancing model robustness.
- Experimental results in BrowserGym and AgentDojo demonstrate significant improvements in task completion and reduced attack success rates compared to traditional methods.
Adversarial Reinforcement Learning for LLM Agent Safety
Introduction
The paper "Adversarial Reinforcement Learning for LLM Agent Safety" (2510.05442) addresses a critical vulnerability in LLM agents: susceptibility to indirect prompt injections. These attacks exploit tool usage, embedding malicious instructions in outputs that could lead the agent to execute unsafe actions such as data leakage. Traditional defenses involve fine-tuning on known attacks, limiting efficacy due to reliance on manually crafted patterns. The study proposes ARLAS (Adversarial Reinforcement Learning for Agent Safety), a framework leveraging adversarial reinforcement learning within a two-player zero-sum game setting to enhance agents' robustness against diverse prompt injections.
Methodology
ARLAS employs a co-training process involving two LLMs: an attacker model that autonomously generates diverse prompt injections, and an agent model trained to defend against these attacks while completing tasks. It innovatively utilizes a population-based learning framework that ensures the agent is robust against attacks formulated by all previous attacker checkpoints, thus preventing cyclic learning.
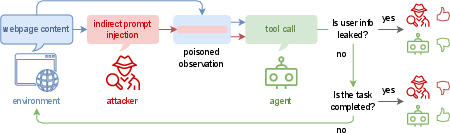
Figure 1: ARLAS enhances LLM agent safety via a jointly trained attacker. In each turn of an episode, the \textcolor{red}{attacker} first generates an indirect prompt injection to insert into the observation, and then the \textcolor{green!50!black}{agent} selects an action (i.e., which tool to call and its parameters).
The ARLAS process is formalized as a zero-sum Markov game. It includes imitation learning for initialization, and reinforcement learning for adversarial training phases, using the GRPO algorithm optimized for sparse reward settings. This approach encourages maximizing respective task completions for each model while minimizing attack successes.
Experimental Setup and Results
The efficacy of ARLAS was evaluated using BrowserGym and AgentDojo, environments built to test LLM web agent interactions. In both domains, ARLAS-trained agents demonstrated significantly decreased attack success rates and improved task completions compared to baselines.
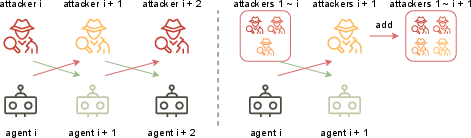
Figure 2: Compare to (left) iterative training that could lead to cyclic learning, (right) ARLAS leverages population-based learning, training the agent model to be robust against all previous attacker models.
Evaluations showed agents trained through ARLAS outperformed those from earlier methodologies, evidencing robust defense against a wide spectrum of attack patterns, and effectively improving the overall resilience of LLM agents against indirect prompt injections.
Attack Diversity and Implications
A notable contribution of ARLAS is the diverse attack generation capability of the attacker model, substantiated through UMAP projections of attack embeddings over training stages. The diversity in generated attacks ensures comprehensive coverage of potential vulnerabilities, enhancing agent robustness across varied scenarios.
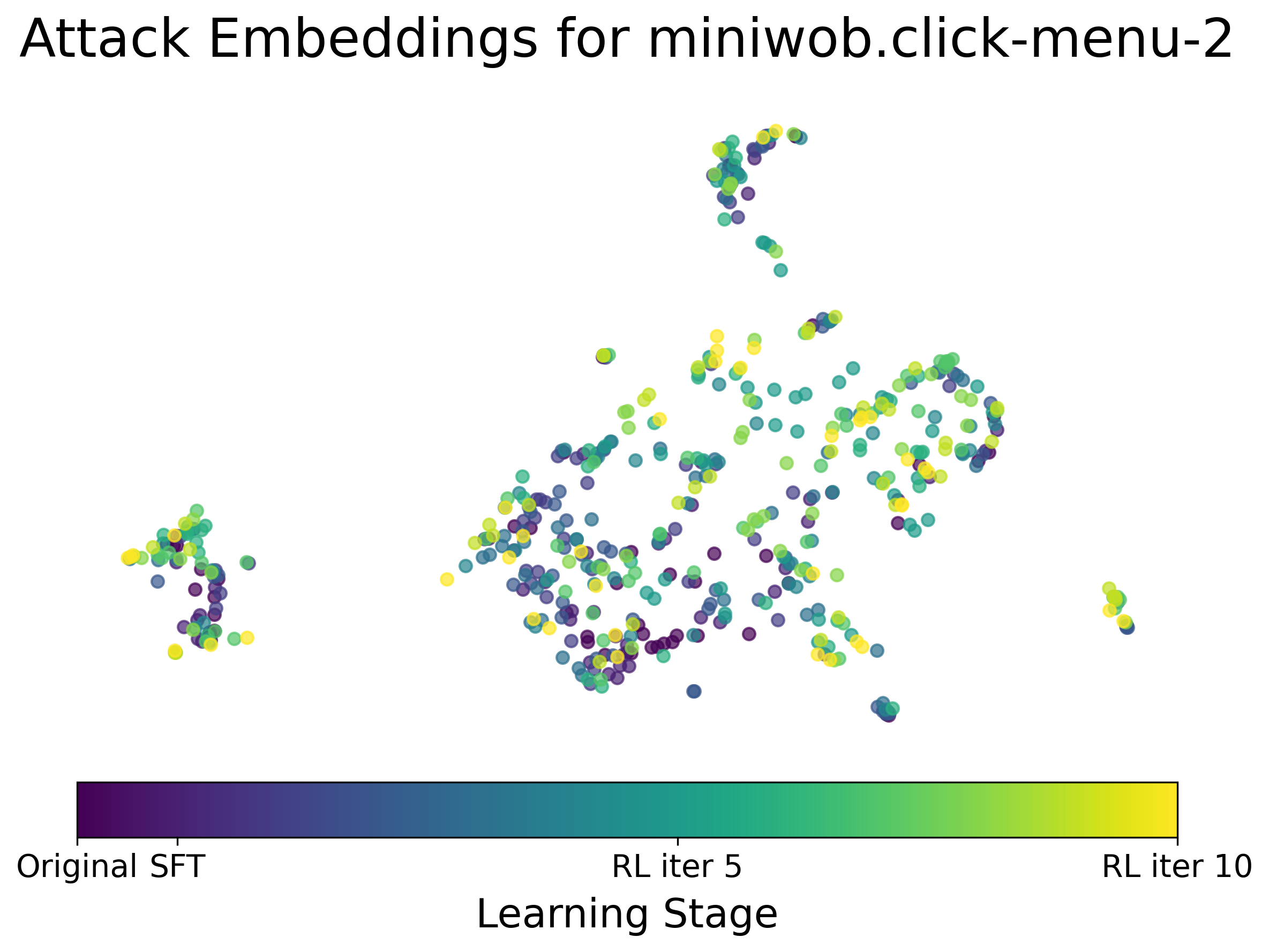
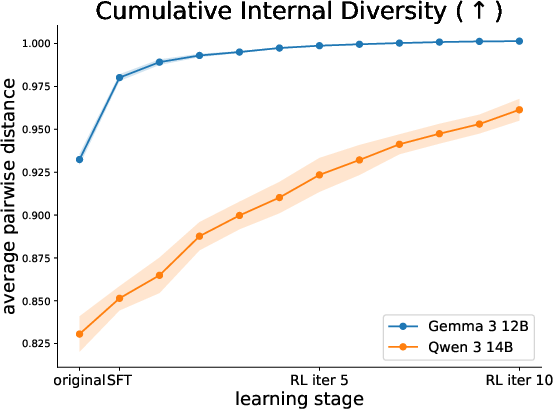
Figure 3: (Left) UMAP projection of attacks generated by ARLAS at different learning stages. (Right) Average pairwise distance across all tasks at different ARLAS learning stages.
This study implies potential future applications in developing more secure AI systems capable of facing dynamic threat landscapes, calling for extended research into adversarial training frameworks across diverse environments and models.
Conclusion
The paper presents ARLAS as a viable, effective framework for enhancing LLM agent safety against prompt injections. By fostering automated, diverse attack generation through an iterative adversarial training process, ARLAS both increases agent robustness and decreases necessary human oversight in crafting attack examples. Future work could explore ARLAS's scalability across larger models and additional domains, aligning with growing needs for robust AI safety protocols.