- The paper demonstrates how integrating foundation models as both world simulators and decision agents enhances sample efficiency in text-based grid environments.
- It introduces two approaches: using Foundation World Models for simulated environment dynamics and Foundation Agents for direct action selection with varied prompt strategies.
- Empirical results reveal that larger LLMs perform best in deterministic settings, while FWM-pre-trained RL agents excel in stochastic scenarios.
Foundation Models in Text-Based GridWorlds
The paper "Foundation Models as World Models: A Foundational Study in Text-Based GridWorlds" (2509.15915) explores how Foundation Models (FMs), particularly LLMs, can integrate into the reinforcement learning framework to improve sample efficiency in sequential decision-making tasks. This study examines two strategies: using Foundation World Models (FWMs) for interaction simulation and employing Foundation Agents (FAs) for direct decision-making. The investigation is conducted within text-based grid-world environments, providing a systematic analysis of their abilities without the complexities of visual perception.
Introduction to Foundation Models
Foundation Models hold vast pre-trained knowledge and reasoning capabilities, making them natural candidates for enhancing sample efficiency in reinforcement learning applications. The paper focuses on integrating FMs directly as world models and decision-making agents, contrasting previous approaches that utilized them as auxiliary components such as reward shaping or skill controllers.
The research is conducted in simplified text-based grid-world environments, emphasizing fundamental dynamics simulation and action selection abilities of FMs. By eliminating intermediate abstractions like planners, the authors aim to provide a benchmark for the zero-shot capabilities of these models.
GridWorld Environments
The grid-world environments used are simple yet adaptable, defined as square grids of size n×n. Each environment comprises deterministic and stochastic settings, testing agent capabilities in fully observable and partially observable scenarios.
Deterministic Setting
In the deterministic setting, the reward location is fixed and known to the agents, while the stochastic setting features a randomly sampled reward location unknown to the agents, introducing significant challenges in terms of exploration and stochastic simulation.
Foundation World Models
Foundation World Models leverage the generative and reasoning abilities of LLMs to simulate environment dynamics.
Simulating Environment Dynamics
FWMs consist of a transition function and a reward function. They utilize prompt templates with key components of the environment fed into the model to generate interactions data for pre-training RL agents.
Prompt Templates
Two types of prompt templates for transition functions are considered: Tminimal—a brief description—and T—an extensive set of constraints guiding the model through reasoning. This allows analysis of how abstraction levels affect model performance.
Temperature Setting
Deterministic environments require deterministic function simulation, set by a temperature parameter τ to encourage high-probability token selection. Stochastic settings, conversely, require τ settings that introduce variability for simulating non-deterministic elements.
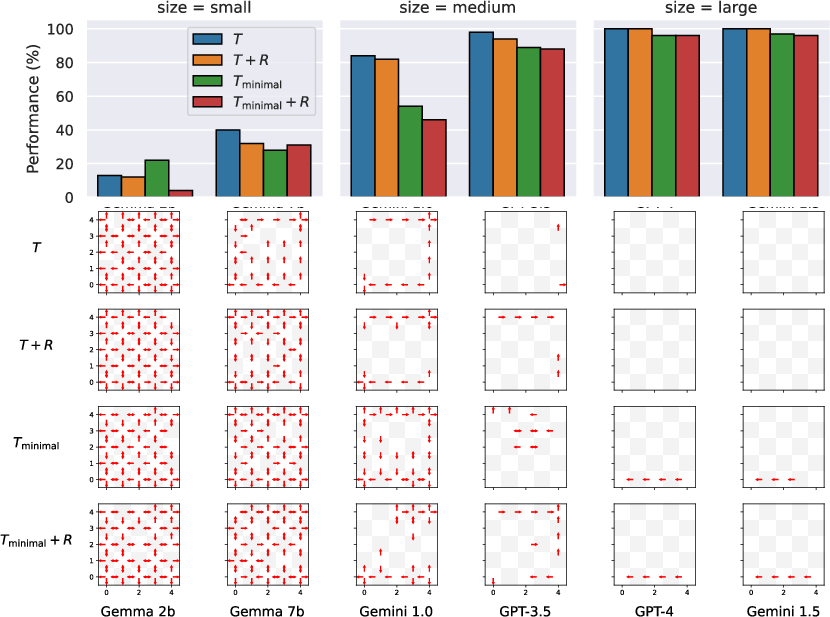
Figure 1: Simulation performance for LLMs with various prompt approaches. Different models demonstrate variance in simulation ability depending on the complexity of the prompts.
Decision-Making Agents
Foundation Agents (FAs) utilize LLMs directly for low-level action selection via different prompt strategies, assessing how effectively these prompts encourage systematic planning and memory utilization.
FWM-Based Reinforcement Learning
FWM-RL agents leverage simulated data for policy pre-training, adapting reinforcement learning algorithms to harness FWM simulations before fine-tuning in the true environment, demonstrating substantial sample efficiency improvements.
Foundation Agents
FA strategies investigate how well different prompt types—Action Only, Simple Plan, and Focused Plan—encourage strategic reasoning and action in different environments.
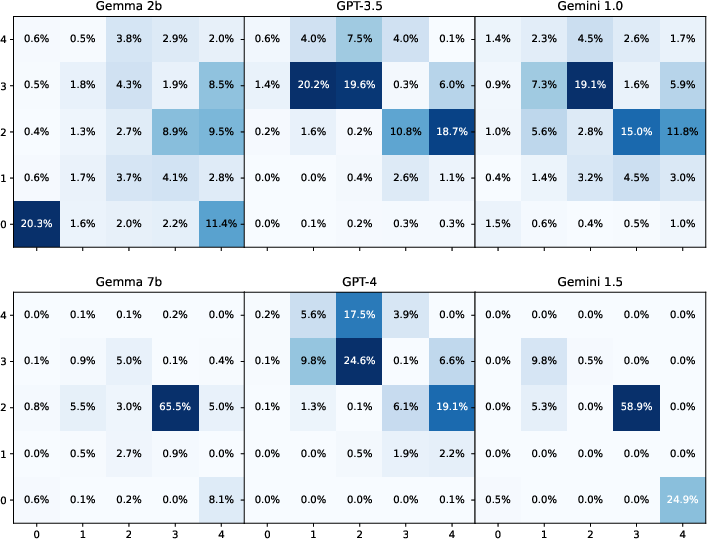
Figure 2: Decision-making results illustrating learning curves for reinforcement learning agents. The best approach per FA model is shown as a horizontal bar.
Experiments
Empirical experiments examine the simulation of environment dynamics and decision-making performances.
Simulation Results
Large models like GPT-4 perform better in simulating deterministic environments and stochastic elements. Larger models excel with detailed prompts, while smaller models show proficiency with increased variability in responses.
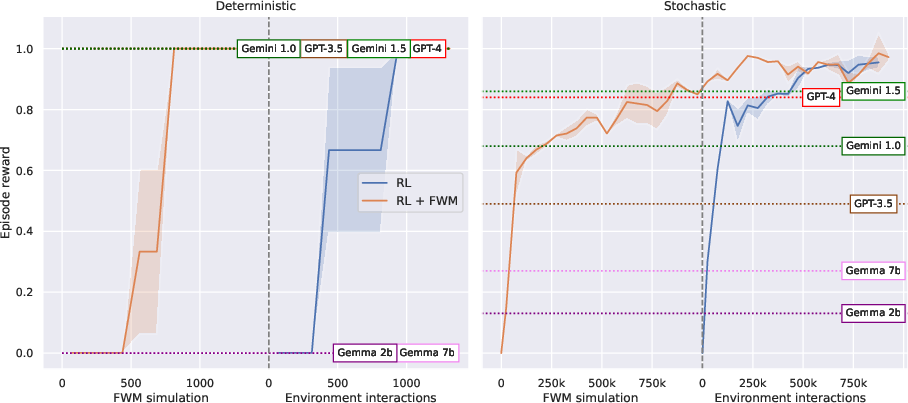
Figure 3: Visualization of LLM-generated random reward locations, exploring their efficacy in simulating uniform distributions.
Decision-Making Results
Deterministic environments see FAs outperform RL agents, leveraging the reasoning abilities of FMs. In stochastic settings, FWM-pre-trained RL agents show superior sample efficiency, while FAs struggle due to increased complexity.
Conclusion
The paper highlights promising integration pathways for foundation models directly within reinforcement learning, providing substantial efficiency gains and establishing benchmarks for zero-shot capabilities. It emphasizes the potential of FMs to serve as world simulators and decision-makers, advancing beyond auxiliary uses into core components of RL frameworks.
Future research directions could further explore optimizing FWMs, leveraging language-driven optimization, and extending foundation models to visual-based environments.
Limitations
The study limits its scope to text-based environments, circumventing visual complexities for focused analysis. Future work should address interleaving integration schemes for real-world applications beyond pretrain-finetune setups.

