- The paper introduces RLVR-World, a post-training paradigm that uses verifiable rewards to fine-tune world models for enhanced prediction accuracy.
- It employs autoregressive sequence modeling across modalities, directly optimizing task-specific metrics for both language and video applications.
- Experimental results show up to +30.7% text game accuracy and improved video perceptual quality with fewer gradient steps than traditional MLE training.
RLVR-World: Training World Models with Reinforcement Learning
Introduction
The paper introduces RLVR-World, a framework that enhances world models through Reinforcement Learning with Verifiable Rewards (RLVR). Standard training methods often misalign with task-specific objectives like transition prediction accuracy or perceptual quality. To address this, RLVR-World utilizes RLVR to fine-tune world models, leading to improved performance in diverse applications such as language-based text games and video-based robotic manipulations.
Background and Motivation
World models are pivotal for predicting state transitions under action interventions. Typically, these models are pre-trained with Maximum Likelihood Estimation (MLE), which emphasizes data distribution over real-world utility. This misalignment often results in suboptimal task-specific performance, such as blurry predictions in video models or repetition in LLMs. RLVR-World seeks to address these shortcomings by leveraging autoregressive sequence modeling across modalities and directly optimizing verifiable task-specific metrics as rewards, rather than surrogate objectives (Figure 1).
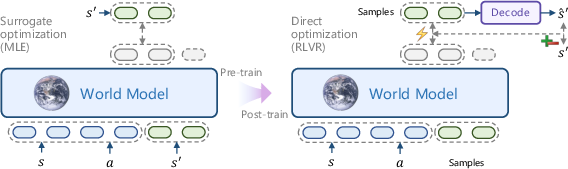
Figure 1: Training world models with reinforcement learning. (Left) World models are typically pre-trained using surrogate objectives like MLE, which misalign with task-specific prediction metrics. (Right) We propose post-training world models with RLVR to directly optimize these metrics.
RLVR-World Framework
The task involves world models that predict state transitions in an environment described as a Markov Decision Process (MDP). RLVR-World casts this as a sequence modeling task, leveraging tokenized inputs and outputs to represent state-action pairs and predictions. It subsequently fine-tunes models on task-specific metrics, which serve as verifiable rewards rather than relying solely on generative probabilities.
Sequence Modeling
RLVR-World unifies language, video, and other modalities under an autoregressive token-based framework. This involves encoding current states and actions into question tokens and next states into response tokens. The process aligns well with transformer architectures and enables efficient joint optimization across diverse domains.
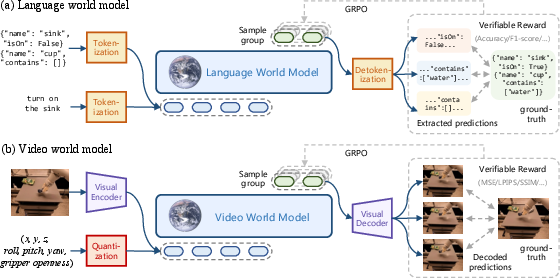
Figure 2: Illustration of RLVR-World framework. World models across various modalities are unified under a sequence modeling formulation, and task-specific prediction metrics serve as verifiable rewards. (Top) Language-based world models predict verbal state transitions in response to verbal actions. (Bottom) Video-based world models, equipped with a visual tokenizer, predict future visual observations conditioned on action vectors.
Experimental Evaluation
Language World Models
The framework was tested on language world models using datasets from text-based games and web navigation tasks. RLVR-World demonstrated substantial accuracy improvements over supervised fine-tuning alone, achieving up to +30.7% accuracy in text game predictions and +15.1% F1 score in web state predictions. This highlights the framework's efficacy in fine-tuning LLMs directly on the prediction metrics of interest.
Video World Models
In the domain of robotic manipulation, RLVR-World was applied to video world models using the RT-1 dataset. The results showed enhanced perceptual quality and accuracy in trajectory predictions, surpassing models pre-trained with traditional objectives. Notably, RLVR-World required significantly fewer gradient steps than MLE training, illustrating the efficiency of the RLVR approach (Figure 3).
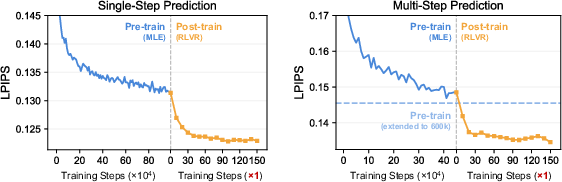
Figure 3: Learning curves of video world models. Note the significant difference in the x-axis scale between the pre-training and post-training stages.
Model Analysis
Key metrics such as LPIPS, MSE, PSNR, and SSIM showed significant improvements across the board. RLVR-World effectively mitigated repetition issues inherent in generative models and demonstrated robust performance scalability with an increasing number of generated samples. This implies that RLVR-World could serve as a more effective post-training paradigm than traditional methods, especially when task-oriented evaluation is critical.
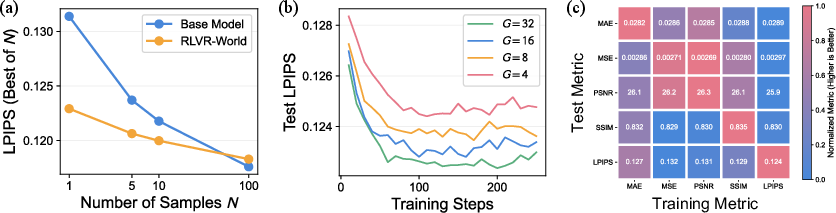
Figure 4: Model analysis. (a) Test-time scaling: best performance among different numbers of generated samples. (b) RL training scaling: learning curves using different group sizes in GRPO. (c) Metric-oriented optimization: RLVR-World trained and tested on different visual metrics.
Applications and Implications
Beyond performance improvements, RLVR-World models facilitated enhanced policy evaluation in real-world scenarios, such as robotic manipulation, bridging simulation and real-world tasks by reducing sim-to-real discrepancies. These findings introduce RLVR as a promising strategy for enhancing generative world models, suggesting expansions into multimodal applications and robust generative policies.
Conclusion
RLVR-World offers a refined post-training paradigm for world models, addressing prevalent shortcomings of conventional training objectives by focusing on real-world task metrics. The framework's adaptability across language and video tasks highlights its potential as a general method for improving generative model efficacy in prediction-centric applications. Future work should explore customizable reward functions tailored to specific domains and enhance out-of-distribution generalization for complex sequential decision-making.

Figure 5: Qualitative analysis: multi-step video prediction and policy evaluation on RT-1.

