- The paper introduces the Text2World benchmark to evaluate LLMs in generating symbolic world models from detailed textual descriptions.
- It employs a rigorous dataset construction with 103 diverse PDDL domains and uses execution-based metrics for precise evaluation.
- Evaluations on 16 LLMs reveal that reinforcement learning and iterative error correction significantly enhance model performance.
Overview of Text2World Benchmark
The paper "Text2World: Benchmarking LLMs for Symbolic World Model Generation" introduces a benchmark designed to evaluate the capability of LLMs to generate symbolic world models from textual descriptions. Symbolic world models are formal representations of environments, capturing dynamics and constraints essential for tasks like planning and autonomous machine intelligence. Text2World, based on Planning Domain Definition Language (PDDL), offers a diverse set of domains and employs execution-based metrics for robust evaluation without relying on indirect feedback.
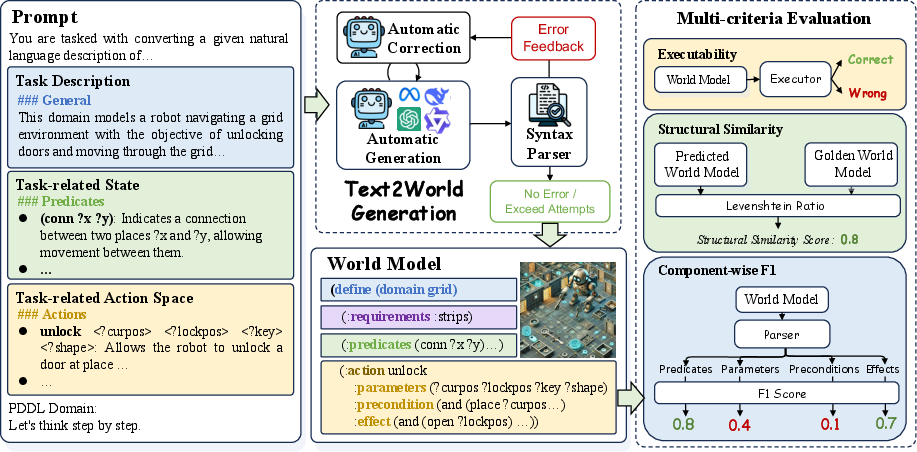
Figure 1: Overview of Text2World.
Benchmark Design and Dataset Construction
The construction of Text2World involved collecting PDDL files from public repositories, followed by a rigorous filtering and manual annotation process. This ensured high quality and diverse representation across domains. The dataset comprises 103 domains with detailed annotations, aiming to cover a broad spectrum of environments where LLMs can potentially excel in generating world models.
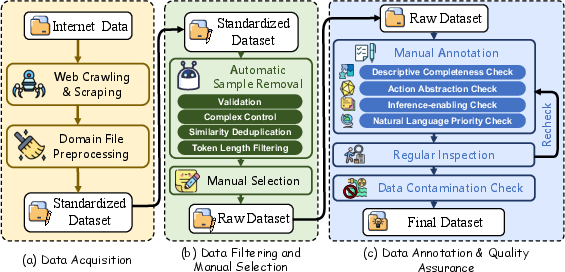
Figure 2: Left: Dataset construction process including: (a) Data Acquisition; (b) Data Filtering and Manual Selection; (c) Data Annotation and Quality Assurance. Right: Key statistics of Text2World.
A significant aspect of the benchmark involves assessing data contamination rates to ensure the evaluation reflects domain understanding rather than memorization. Text2World exhibits a lower contamination rate compared to prior works, thereby establishing the benchmark as a reliable tool for evaluating LLM capabilities.
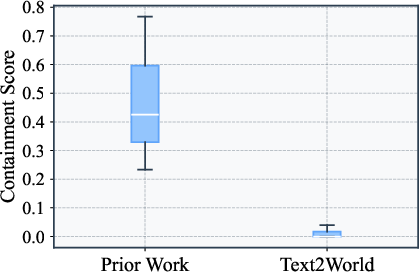
Figure 3: n-gram contamination rate of Text2World and prior works.
Evaluating LLMs
The study evaluates 16 different LLMs, encompassing both open-source and proprietary models, to gauge their proficiency in world modeling tasks. The evaluation employs execution-based metrics, examining executability, structural similarity, and component-wise F1 scores for predicates, parameters, preconditions, and effects.
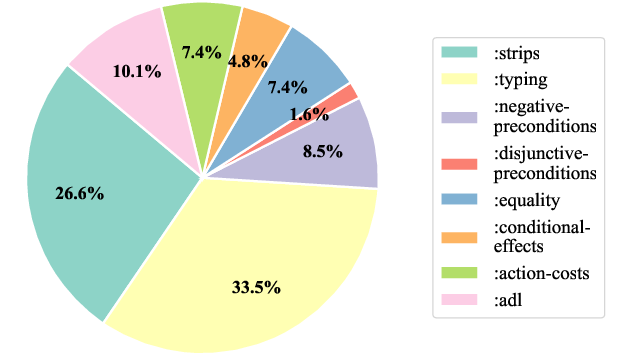
Figure 4: Top: The frequency of requirements distribution. Bottom: Word cloud of concepts in Text2World.
The results indicate that even state-of-the-art LLMs struggle with complex world modeling tasks inherent in Text2World. Models trained with reinforcement learning demonstrate superior performance, suggesting the potential of reinforcement learning in enhancing world modeling capabilities.
Error Analysis
Error analysis reveals a varied distribution of syntax and semantic errors encountered by LLMs. Syntax errors are predominantly due to undefined domain elements, while semantic errors largely stem from incomplete or incorrect action modeling. Error correction attempts significantly improve model performance, highlighting the importance of iterative refinement processes in addressing limitations.
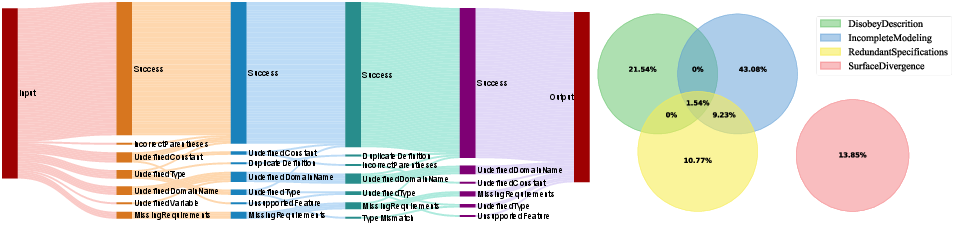
Figure 5: Left: The distribution of syntax error types during the progression of correction. Right: The distribution of semantic error types.
Exploration of Enhanced Modeling Strategies
The paper also explores strategies to augment LLM performance, such as test-time scaling, in-context learning, supervised fine-tuning, and agent training. These strategies demonstrate varying levels of improvement, underscoring the importance of context-rich learning environments and fine-tuning techniques in developing robust LLMs capable of accurate world modeling.
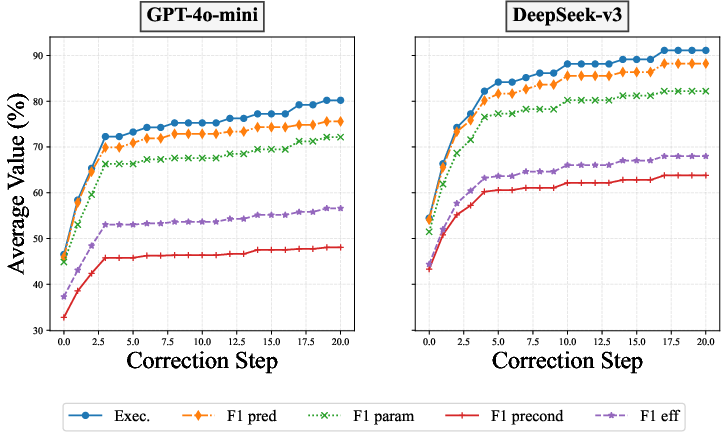
Figure 6: The performance of gpt-4o-mini (left) and deepseek-v3 (right) under different test-time compute budgets, showing consistent improvement with increased compute.
Furthermore, experiments with concrete descriptions versus abstract ones show marked improvements when LLMs are provided with detailed task-specific descriptions. This indicates the critical role of clear, explicit information in enhancing LLM inference capabilities.
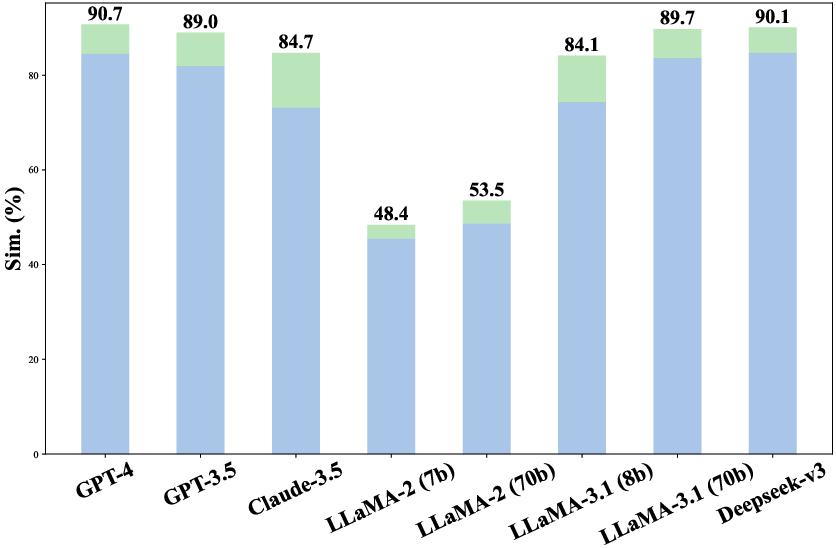
Figure 7: Comparison of model performance on abstract versus concrete domain descriptions, showing the base score for abstract descriptions and the improvement gained from concrete descriptions.
Conclusion
Text2World serves as a critical benchmark for evaluating the world modeling capabilities of LLMs. Despite promising advancements, the limitations highlighted in current models underscore substantial opportunities for future research. Enhancing LLM capabilities through refined training techniques and rigorous evaluation frameworks may lead to the development of more proficient world models, paving the way for improved autonomous systems and intelligent agents in complex domains.