Vox Deorum: A Hybrid LLM Architecture for 4X / Grand Strategy Game AI -- Lessons from Civilization V
Abstract: LLMs' capacity to reason in natural language makes them uniquely promising for 4X and grand strategy games, enabling more natural human-AI gameplay interactions such as collaboration and negotiation. However, these games present unique challenges due to their complexity and long-horizon nature, while latency and cost factors may hinder LLMs' real-world deployment. Working on a classic 4X strategy game, Sid Meier's Civilization V with the Vox Populi mod, we introduce Vox Deorum, a hybrid LLM+X architecture. Our layered technical design empowers LLMs to handle macro-strategic reasoning, delegating tactical execution to subsystems (e.g., algorithmic AI or reinforcement learning AI in the future). We validate our approach through 2,327 complete games, comparing two open-source LLMs with a simple prompt against Vox Populi's enhanced AI. Results show that LLMs achieve competitive end-to-end gameplay while exhibiting play styles that diverge substantially from algorithmic AI and from each other. Our work establishes a viable architecture for integrating LLMs in commercial 4X games, opening new opportunities for game design and agentic AI research.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper is about making computer opponents in big strategy games (like Civilization V) smarter and more fun to play with. The authors built a new kind of game AI that combines a language-based “thinker” with a fast “doer.” The LLM (the “thinker”) decides high-level plans, and the game’s existing AI (the “doer”) handles detailed moves. They tested this in Civilization V using a popular community mod called Vox Populi.
The main questions the researchers asked
The team focused on three simple questions:
- Can this “hybrid” setup (LLM + existing AI) play full, long games successfully?
- How well do language-model strategists perform compared to the game’s built-in AI?
- Do different LLMs play with different styles (for example, aiming for different kinds of victories)?
How they tested their idea
To see if their approach works in practice, the researchers:
- Plugged a LLM into Civ V so it could act like a high-level coach.
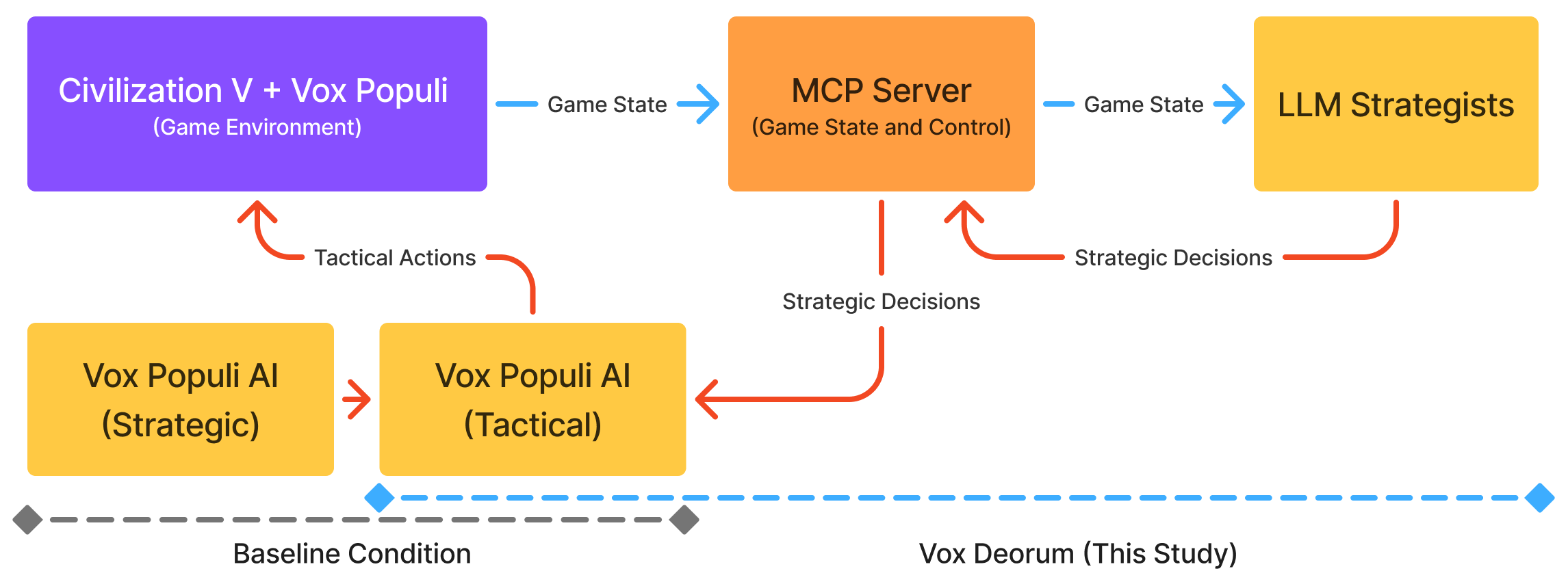
- Let the LLM choose big-picture plans each turn: Which victory to chase (like science or military), what to research next, what policies to adopt, how aggressive to be, and how to behave diplomatically.
- Let the game’s existing AI (from the Vox Populi mod) handle the nitty-gritty: moving units, fighting, managing cities, and improving tiles.
Think of it like a sports team:
- The LLM is the head coach, setting strategy (“We’ll focus on defense and save up for late-game tech.”).
- The game’s AI is the players on the field, making quick decisions moment by moment.
They ran 2,327 complete games of Civ V under three conditions:
- The standard Vox Populi AI (baseline).
- A large open-source model called GPT-OSS-120B.
- Another large model called GLM-4.6.
They checked:
- Who won (win rate) and how strong each player looked (score ratio).
- What kinds of victories happened (like military or cultural).
- How often strategies changed.
- How fast and costly the system was to run.
Quick explanations of key terms
- LLM: A computer program that reads and writes text and can plan in natural language (like giving advice or making step-by-step plans).
- Hybrid architecture: Splitting work so the LLM makes high-level choices while a specialized system handles detailed actions.
- Strategy vs. tactics: Strategy is the long-term plan (“win with science”). Tactics are the small, immediate moves (“move this unit here this turn”).
What they found
Here are the main takeaways from thousands of games:
- The hybrid AI reliably finished full games. Survival rates were around 97% for all groups, including the LLM-led ones. This shows the approach works for long, complex play.
- The LLM-led teams performed competitively. Their win rates and scores were statistically similar to the baseline AI, even though the LLMs only handled high-level decisions.
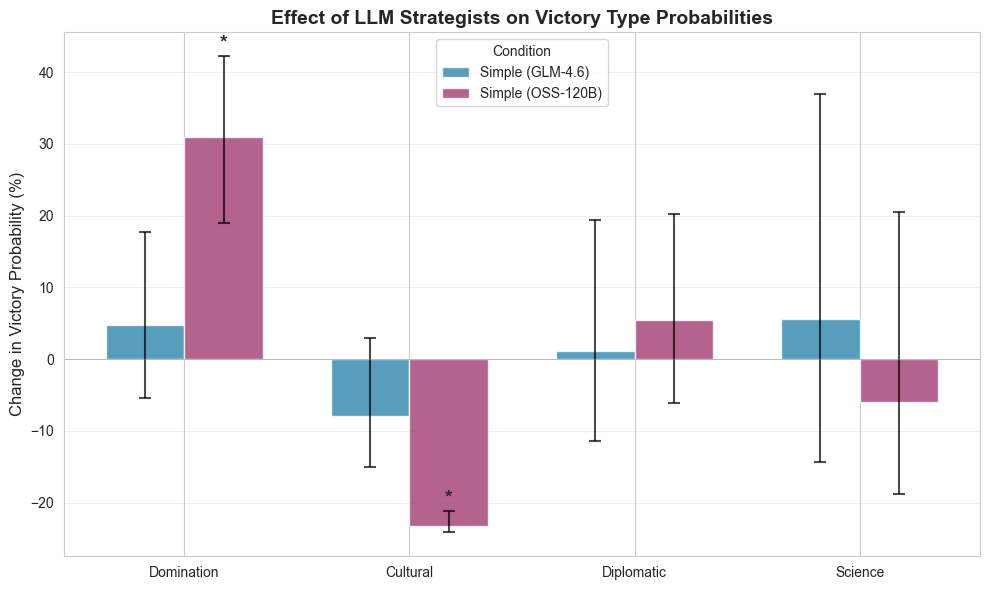
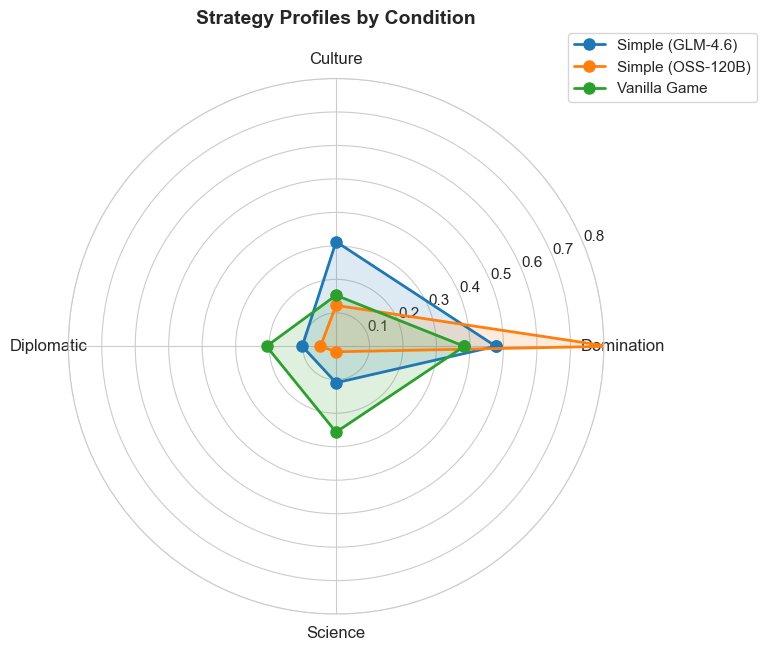
- Different LLMs had different play styles. One model (GPT-OSS-120B) leaned heavily toward military (Domination) victories and spent more time on war-focused plans. The other model (GLM-4.6) was more balanced, with a mix of goals.
- LLMs changed plans less often than the baseline AI. This made them more “stubborn” at times—sometimes sticking with an aggressive plan even when it wasn’t working.
- Policy choices (in-game government/ideology) also differed. LLMs favored certain ideologies (like Order) more than the baseline, which matched their tendency toward military goals.
- Speed and cost looked reasonable for real games. Because the LLM only planned once per turn (instead of micromanaging every action), the system stayed fast enough and affordable. A typical game with one of the models was estimated at under a dollar to run, and the per-turn response fit inside normal multiplayer time limits.
Why this is important:
- It shows that using an LLM as a “coach” can bring smarter, more varied, and more human-like strategy without slowing the game to a crawl.
- It also proves that LLMs can add personality and playstyle differences that make games feel fresher.
Why it matters and what could happen next
This hybrid design opens up exciting possibilities:
- Better opponents and teammates: LLM-led AIs can plan and explain themselves in plain language, making diplomacy, alliances, and negotiations with AI more natural for players.
- More interesting gameplay: Different LLMs can create diverse play styles, so games feel less predictable.
- Practical for developers: It’s fast and cost-effective enough to use in real games, not just experiments.
- A platform for research: The authors released their system so others can build on it, test new ideas (like memory, maps, or multi-agent teamwork), and try it in other strategy games.
In short, the paper shows a clear, working path to smarter strategy game AIs: let a LLM think big, and let a specialized system handle the details. This makes AI opponents more fun and flexible while keeping the game smooth and affordable to run.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Based on the paper, the following unresolved issues merit targeted investigation:
- External validity beyond Civilization V (Vox Populi): does the LLM+X architecture transfer to other 4X/grand strategy titles (e.g., Stellaris, Europa Universalis, Humankind) without game-specific engineering?
- Scaling to real game sizes: how do performance, cost, and latency change on standard/large/huge maps, with 8–12+ players, different map scripts, and slower game speeds?
- Difficulty and handicaps: what happens across Civilization difficulty levels and AI handicap settings; are results robust when AI bonuses are reduced or removed?
- Opponent diversity: do results hold against mixed fields (humans, stronger scripted AIs, different mod versions), not just VPAI-controlled opponents?
- Human-facing evaluation: how do human players perceive fun, challenge, believability, diplomacy quality, and explainability when playing with/against LLM strategists?
- Ablation of LLM contribution: how much of the performance/style difference comes from the LLM versus simpler macro toggling heuristics or randomized strategy schedules?
- Frontier analysis of control granularity: what is the cost–performance trade-off as more control surfaces (e.g., city production, unit composition, build orders, targeted tactical overrides) are handed to the LLM?
- Direct diplomatic control: how does enabling LLM-initiated diplomatic actions (declare war, treaty offers, trades, threats) affect outcomes versus persona-only control?
- Victory execution gap: LLMs showed higher score ratios but not higher win rates—what mechanisms or planning scaffolds help convert advantage into secured victories?
- Strategic pivot efficacy: do LLM strategy/persona changes correlate causally with improved outcomes; when are pivots beneficial vs harmful?
- Memory and long-horizon coherence: how do episodic memory, retrieval-augmented summaries, or reflective planning buffers affect multi-hundred-turn consistency and crisis handling?
- Spatial/geopolitical reasoning: does adding multimodal inputs (mini-maps, heatmaps, graph abstractions) reduce errors like mismanaging “phony wars” or distant threats?
- State representation design: what is the optimal representation (Markdown vs JSON vs graph/relational schemas) and summarization policy to minimize tokens without losing critical information?
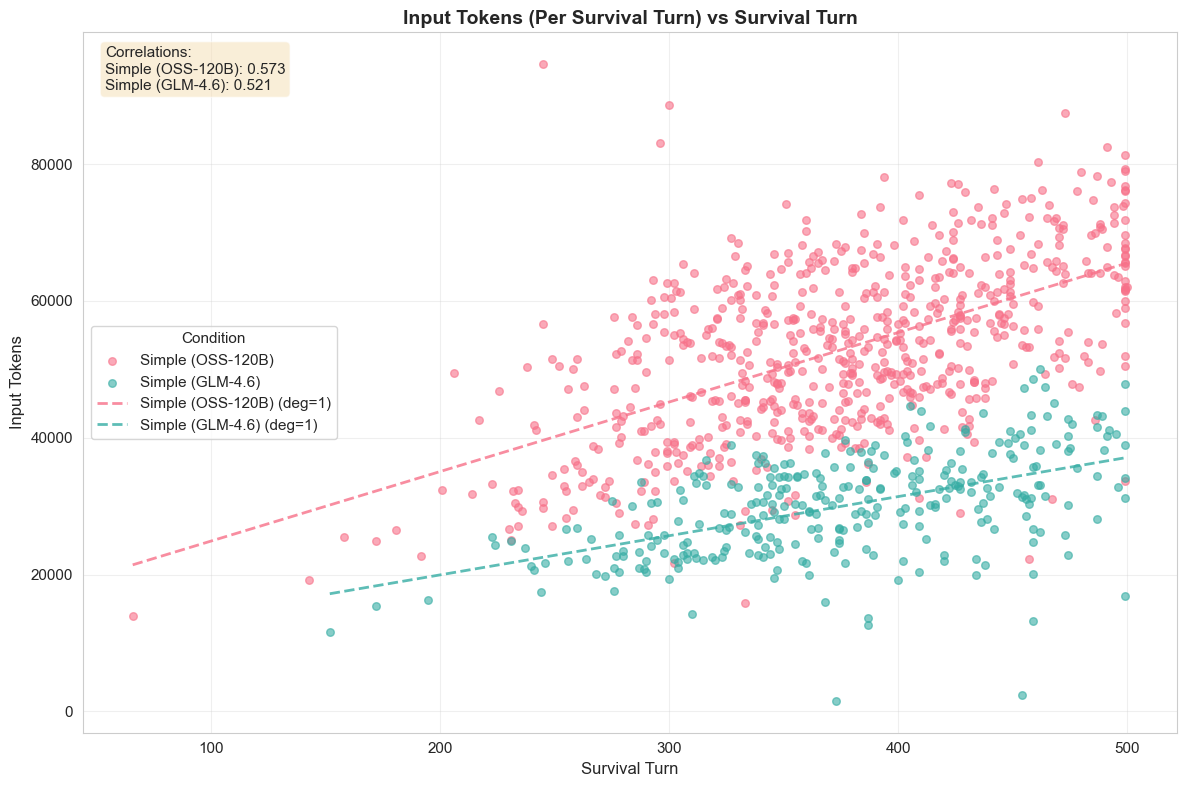
- Token-scaling inconsistency: the paper states both quadratic and linear growth for input tokens; a precise scaling law (and its drivers) needs to be established to forecast context-window pressure.
- Latency and cost measurement in situ: replace benchmark-based estimates with end-to-end, per-turn latency measurements under realistic server loads and parallel multi-LLM play.
- Telemetry completeness: resolve missing token statistics (~30% games) and systematically log failures (API outages, mod crashes) to quantify robustness and recovery strategies.
- Model scaling and selection: why did the larger GLM-4.6 not outperform OSS-120B; do newer/proprietary models or small distilled models change performance, style, or cost curves?
- Tool/function-calling interfaces: does native parallel function-calling (vs sequential tool cycles) materially reduce token usage and improve responsiveness?
- RL as the “X” component: how does replacing or augmenting VPAI tactics with steerable RL modules affect win rate, reliability under distribution shift, and LLM–RL coordination?
- Multi-agent LLM orchestration: can role-specialized agents (e.g., economy, military, diplomacy) coordinated by a chief-of-staff improve outcomes without exploding token cost?
- Event-triggered vs per-turn reasoning: what decision cadence (every turn, only on significant events, or variable frequency) optimizes cost while preserving strategic responsiveness?
- Civilization and map seeding effects: use matched seeds or controlled starting positions to disentangle civilization/map advantages from agent effects more rigorously.
- Policy (civic/ideology) trajectories: which policy choices causally drive success for each victory path; can counterfactual policy planners close the gap in Cultural/Diplomatic wins?
- Endgame planning: what specialized endgame subroutines (win-con execution checklists, threat monitoring) help LLMs switch from buildup to victory sealing effectively?
- Adversarial robustness and exploitability: are LLM strategies predictable or exploitable by scripted/human opponents; can meta-counterstrategies be learned against them?
- Safety and social dynamics: how to constrain deception, collusion, or toxic negotiation while preserving engaging diplomacy in human-facing contexts?
- Generalizability of the interface: what minimal API abstractions are needed to port Vox Deorum to other engines/rulesets without deep code integration?
- Failure mode taxonomy: systematically categorize and quantify errors (wishful “WinningWars,” overcommitment, economic collapse) to target fixes and benchmarks.
- Comparative benchmarks: add baselines such as pure VPAI with stochastic strategy schedules, simple rule-based macro controllers, and LLMs with richer planning (RAG/simulators) for clearer progress signals.
- Cost-aware planning: can budgeting mechanisms (token/compute limits per turn, importance sampling of state) maintain performance under strict cost ceilings?
- Ethical deployment questions: what data, logging, and disclosure practices are appropriate when LLM agents interact with players in live commercial environments?
Practical Applications
Below is a synthesized set of practical applications derived from the paper’s findings, methods, and innovations. Each item includes sector links, indicative tools/products/workflows, and feasibility notes.
Immediate Applications
The following applications can be piloted or deployed now using the paper’s open-source implementation, demonstrated costs/latency, and engineering patterns.
- Game AI modernization for 4X/grand strategy titles (Sector: software/games)
- What: Drop-in “LLM strategist + existing tactical AI” to deliver more human-like opponents and allies without AI handicaps.
- Tools/workflows: Vox Deorum’s LLM+X pattern; structured state summaries in compact Markdown; turn-synchronous LLM calls; “flavor” knobs to steer existing tactical modules.
- Dependencies/assumptions: Access to a tactical AI layer with steerable parameters; API hooks into game state and decision points; stable inference endpoints; cost targets (~$0.86/game and ~14.8s/turn tested) compatible with monetization or server budgets.
- Co-op AI teammate and natural-language negotiation (Sector: software/games; education)
- What: Enable players to plan and coordinate with an AI teammate that reasons at macro level and executes reliably via tactical AI.
- Tools/workflows: In-game chat/voice → LLM strategist → VPAI tactical execution; persona sliders (aggression, deception, friendliness).
- Dependencies/assumptions: Clear mapping from language intent to strategic “flavors”; moderation of player-AI dialogue; latency hiding via off-turn compute.
- Dynamic tutorials and in-game strategy advisors (Sector: software/games; education)
- What: LLM summarizes situational context and explains strategic recommendations using the same macro reasoning used to control AI.
- Tools/workflows: Structured state reports; rationale logs from the strategist; “why now?” tooltips; replay debriefs.
- Dependencies/assumptions: High-quality state summarization; lightweight prompts; consistent persona to avoid confusing advice swings.
- Player-configurable AI personas and difficulty without artificial bonuses (Sector: software/games)
- What: Ship persona packs (e.g., domination-focused, balanced, pacifist) that materially change playstyle, leveraging the paper’s observed divergence in victory-type preferences.
- Tools/workflows: Prompt templates per persona; sliders mapped to “flavor” weights; A/B tests for engagement.
- Dependencies/assumptions: Guardrails to prevent extreme stubbornness; telemetry to detect unfun stalemates.
- Automated playtesting and balance at scale (Sector: software/games; QA)
- What: Run thousands of AI-vs-AI games to stress-test rules, map scripts, and balance changes before release.
- Tools/workflows: Batch orchestration; outcome tracking (win rate, score ratio, victory-type distributions); regression dashboards.
- Dependencies/assumptions: Reliable headless runs; handling of mod/game crashes (paper notes rare alpha-mod crashes); compute budget for token costs.
- Research testbed for long-horizon, multi-agent AI (Sector: academia)
- What: Use the open-source Civ V integration as a reproducible environment to study planning, ToM, memory, and LLM+RL hybrids.
- Tools/workflows: MCP-based API exposure; plug-in memory/ToM modules; ablations on prompt complexity.
- Dependencies/assumptions: Continued community maintenance of the mod and interfaces; IRB considerations for human-in-the-loop experiments.
- Engineering pattern for latency hiding in LLM agents (Sector: software)
- What: Schedule LLM macro decisions during other agents’ turns or background windows to mask inference time.
- Tools/workflows: Turn-synchronous invocation; prefetch/prefill pipelines; staggered parallel inference per player.
- Dependencies/assumptions: Clear “decision clock” in the application; bounded worst-case inference time; fallback defaults.
- Token-efficient state representation for complex simulations (Sector: software/games; enterprise software)
- What: Apply structured Markdown summaries to compress complex states (cities, units, events) by 2–3× while preserving key signals.
- Tools/workflows: Schema-driven summarization pipelines; significance pruning; domain-specific glossaries.
- Dependencies/assumptions: Careful curation to avoid dropping critical context; validation against downstream decision quality.
- Replay analytics and explainability (Sector: software/games; education; analytics)
- What: Pair strategist rationales with outcomes to create explainable replays for players, coaches, and designers.
- Tools/workflows: “Vox Deorum Replay Player”-style viewers; rationale timelines; pivot-rate metrics; policy trajectory graphs.
- Dependencies/assumptions: Storage of rationale and decisions; privacy-safe logging; UX to avoid spoilers in live games.
- Classroom simulations for strategic thinking (Sector: education)
- What: Run Civ-like sessions where students face or partner with LLM-driven civilizations; use rationales for reflective learning.
- Tools/workflows: Instructor dashboards; scenario presets; post-game debrief prompts; measurable learning objectives.
- Dependencies/assumptions: Classroom hardware/network capacity; content alignment to curricula; moderation policies.
- Rapid AI design prototyping in studios (Sector: software/games)
- What: Iterate on AI behavior with prompt/persona changes rather than code; reduce hardcoded logic.
- Tools/workflows: Prompt libraries; persona catalogs; “flavor” autotuning against KPIs (engagement, difficulty).
- Dependencies/assumptions: Internal buy-in to replace parts of legacy AI; version control for prompts; evaluation harness.
- Cross-functional pattern: LLM sets macro-policy, optimizers execute (Sector: operations/supply chain; scheduling)
- What: Pilot the LLM+X pattern in enterprise sandboxes: LLM proposes weekly policies (e.g., expansion vs. conservation), existing solvers handle day-to-day routing/scheduling.
- Tools/workflows: Digital twin or simulator as “X”; parameterized optimization knobs (service levels, risk tolerance).
- Dependencies/assumptions: Strict guardrails and human-in-the-loop oversight; auditable rationales; safety checks before execution.
Long-Term Applications
These applications require further research, scaling, or ecosystem development (e.g., RL “X” modules, multimodal inputs, longer contexts, or cross-domain validation).
- Steerable RL tacticians under LLM macro-control (Sector: software/games; robotics)
- What: Replace algorithmic “X” with RL agents tuned by LLM-set objectives/constraints for superior micro execution.
- Tools/workflows: Policy APIs that accept strategic weights; online adaptation; curriculum learning driven by LLM scenario generation.
- Dependencies/assumptions: Robust steerability; avoidance of reward hacking; compute for training; interpretability tooling.
- Multimodal spatial reasoning for geopolitics and map awareness (Sector: software/games; robotics)
- What: Add mini-maps/screenshots to improve spatial judgments (e.g., avoid “phony wars”).
- Tools/workflows: Vision-LLMs; map graph encodings; spatial memory.
- Dependencies/assumptions: Efficient multimodal inference; UI/UX to visualize maps; validation to prevent hallucinated terrain.
- Long-horizon memory and reflective planning (Sector: software/games; academia)
- What: Introduce role-specific memory, belief tracking, and DAG-structured strategic plans to reduce “stubbornness” and wishful thinking.
- Tools/workflows: Episodic memory stores; ToM prompts; reflection checkpoints; plan-vs-outcome critics.
- Dependencies/assumptions: Context window management; cost-aware memory retrieval; overfitting safeguards.
- Cross-game AI broker and interface standardization (Sector: software/games)
- What: Generalize the MCP-based interface to multiple engines (e.g., Paradox/Stellaris-like) for plug-and-play LLM strategists.
- Tools/workflows: Open schema for state/action; adapter kits; certification tests.
- Dependencies/assumptions: Publisher adoption; IP/licensing constraints; sustained open-source governance.
- “AI without handicaps” for expert-level play (Sector: software/games; esports)
- What: Deliver AI that challenges high-skill players via advanced long-horizon reasoning and precise tactics.
- Tools/workflows: Hybrid LLM+RL; adaptive personas; exploit detection and patching (anti-cheese).
- Dependencies/assumptions: Extensive playtesting; fairness guardrails; performance budgets on consumer hardware.
- Marketplace for AI personas and narrative packs (Sector: software/games; creator economy)
- What: Sell curated, moderated AI personas (e.g., aggressive conqueror, cultural aesthete) that reliably express distinct playstyles.
- Tools/workflows: Persona distillation; prompt+weight bundles; ratings and safety reviews.
- Dependencies/assumptions: Content moderation; IP/brand consistency; monetization aligned with inference cost.
- Human-AI diplomacy and social mechanics research (Sector: academia; UX)
- What: Study cooperation/competition dynamics with adjustable AI personas across hundreds of-turns games.
- Tools/workflows: Experimental protocols; survey instruments; reproducible seeds/datasets.
- Dependencies/assumptions: Ethical review; standardized reporting; storage of long-run logs.
- Automated exploit and balance regression for live-service games (Sector: software/games; QA)
- What: Use diverse LLM personas to discover patch-breaking strategies before players do.
- Tools/workflows: Fuzzing over prompts/personas; anomaly detection on win rates and pivot patterns.
- Dependencies/assumptions: Scalable compute; repeatable seeds; continual retraining against evolving metas.
- Digital twin decision support in complex systems (Sector: energy, logistics, urban planning, finance)
- What: LLM proposes high-level strategies (e.g., demand response posture, growth vs. defense), simulators/optimizers execute and verify.
- Tools/workflows: Domain-specific state summarization; explainable policy diffs; counterfactual scenario runs.
- Dependencies/assumptions: High-stakes safety constraints; regulatory compliance; strict human oversight; rigorous backtesting.
- Safety and governance benchmarks for long-horizon agentic AI (Sector: academia; policy)
- What: Use 4X-like environments to probe specification gaming, collusion, and emergent behaviors over thousands of steps.
- Tools/workflows: Standardized scenarios; risk metrics (e.g., reward hacking, unsafe escalation); red-teaming.
- Dependencies/assumptions: Shared datasets; community standards; funding for compute.
- Voice-first negotiation and tutoring experiences (Sector: software/games; education)
- What: Natural language negotiation with AI civs; voice tutors that contextualize strategic decisions and ethics.
- Tools/workflows: ASR/TTS pipelines; conversation memory; sentiment and deception detectors.
- Dependencies/assumptions: Real-time speech latency; content moderation; accessibility compliance.
- On-device or edge deployment via model compression (Sector: software; consumer hardware)
- What: Distill strategist models to run locally for privacy and reduced recurring cost.
- Tools/workflows: LoRA/QLoRA; mixture-of-experts gating; caching of steady-state turns.
- Dependencies/assumptions: Quality retention under compression; memory budgets; device heterogeneity.
- Personal strategic planners for long-term goals (Sector: daily life; productivity)
- What: LLM sets high-level goals (e.g., learning plan, fitness macro-cycle), existing apps execute micro schedules/tasks.
- Tools/workflows: Calendar/task tool “X”; weekly reflection cadence; plan-adjustment heuristics.
- Dependencies/assumptions: Robust adherence tracking; avoidance of overconfidence; privacy and consent.
- Policy training via multi-agent simulations (Sector: public policy; defense/civics education)
- What: Simulate long-term policy/diplomacy scenarios to teach negotiation, coalition-building, and tradeoffs.
- Tools/workflows: Stakeholder persona libraries; outcome dashboards; structured debriefing guides.
- Dependencies/assumptions: Model bias auditing; careful scoping to avoid prescriptive misuse; domain validation.
Notes on Cross-Cutting Assumptions and Dependencies
- Tactical “X” availability: Success depends on existing reliable micro-execution modules (algorithmic or RL) with steerable parameters (“flavors” or equivalent).
- Interface access: Games and simulators must expose state and action hooks (e.g., via MCP/REST); licensing and IP constraints may require publisher cooperation.
- Latency and cost envelopes: The paper’s reference point (~$0.86 per full game; ~14.8s per turn) is promising but depends on model choice, hosting, and prompt design; parallelization can mitigate multi-AI latency.
- Context growth: Input tokens scale with game complexity; multimodal compression, memory retrieval, or selective summarization will be needed for very large maps or longer campaigns.
- Safety and UX: Guardrails against deception, griefing, or unfun stubbornness; moderation for player-facing dialogue; transparency via rationales and replays.
- Generalization: Porting beyond Civ V/VP requires mapping strategic intents to each game’s “flavor” knobs and retuning prompts; domain-specific validation for non-game sectors is essential before production use.
Glossary
- 4X: A subgenre of strategy games defined by eXplore, eXpand, eXploit, and eXterminate mechanics over long horizons. "4X and grand strategy games are among the most complex environments for human players."
- Activated parameters: The subset of a model’s parameters actually used during a forward pass (e.g., in sparse/MoE setups), often reported alongside total parameters. "GPT-OSS-120B (983 games; 117 billion parameters; 5.1 billion activated; hosted by Jetstream2); and GLM-4.6 (425 games; 355 billion parameters; 32 billion activated; hosted by Chutes.ai)."
- Algorithmic AI: Hand-crafted, rules/search-based game AI (non-learning) responsible for tactical decision-making. "Vox Populi's algorithmic AI (VPAI) baseline."
- Context window: The maximum number of tokens an LLM can condition on; limits how much state or memory can be provided at once. "placing pressure on context windows."
- Deviation (sum) coding: A categorical regression coding scheme that centers levels so coefficients sum to zero, estimating effects relative to the grand mean. "We used deviation (sum) coding, which centers estimates relative to the mean civilization effect."
- Fixed-effects regression: A regression approach controlling for entity-specific constants (e.g., per-civilization effects) to isolate treatment effects. "we conducted fixed-effects regression analyses to further control for Civilization V's civilization-dependent effects."
- Flavor (AI): Weighted preference coefficients that bias search-based tactical AI toward certain actions or priorities. "the ``flavor'' numbers - i.e., weight modifiers in the search algorithms."
- General-sum game: A game where players’ payoffs are not strictly opposed and total utility is not fixed, allowing mixed incentives. "general-sum game dynamics."
- Grand strategy: A high-level, long-term plan or targeted victory path that guides lower-level tactics. "The LLM sets the grand strategy (the victory type that the AI player targets)"
- Grand strategy adoption: The proportion of time an agent spends pursuing each grand strategy across a game. "grand strategy adoption (proportion of game time spent targeting each victory type)"
- Imperfect information: A setting where agents lack full knowledge of the environment state or others’ actions/intentions. "Under conditions of imperfect information and multilateral competition,"
- L1 regularization: A sparsity-inducing penalty (Lasso) used in regression to reduce collinearity and select features. "we used logistic regression with regularization to reduce collinearity."
- LLM+X architecture: A hybrid design where an LLM handles high-level strategy while a complementary module (“X”) executes tactics. "a hybrid LLM+X architecture"
- Logistic regression: A statistical model for binary outcomes that estimates log-odds as a linear function of inputs. "we used logistic regression with regularization to reduce collinearity."
- MCP (server/client): A server–client tooling interface used here to expose high-level game functions to the LLM strategist. "we created a downstream MCP server to expose high-level functionalities"
- Multimodal: Incorporating multiple input/output modalities (e.g., text and images) to perceive and act in environments. "through both text and multimodal observations."
- Named pipe (Windows): An interprocess communication mechanism on Windows used to shuttle data between the game and external services. "from a Windows Named Pipe into a REST API."
- Ordinary least squares (OLS) regression: Linear regression that minimizes the sum of squared residuals for continuous outcomes. "we used ordinary least squares regression."
- Partially observable: An environment property where agents observe only part of the true state at any time. "In high-dimensional, partially observable real-time environments,"
- Polynomial regression: Regression that models nonlinear relationships by including polynomial terms of predictors. "Token usage growth patterns were analyzed through polynomial regression to characterize scaling behavior across game progression."
- Prefill: The time/step to process the input prompt tokens before generation during LLM inference. "1.98 seconds to prefill 52,854 tokens,"
- Retrieval-augmented generation (RAG): Supplying retrieved documents/context to an LLM to ground its outputs. "incorporating tool usage, retrieval-augmented generation (RAG), and self-reflection mechanisms"
- Score ratio: A relative performance metric comparing a player’s best score to the highest score in a game. "score ratio, which measured Player 0's highest score relative to that of all players."
- Self-play: Training or evaluating agents by having them play against themselves to improve performance. "Self-play deep RL and search agents attain beyond human play"
- Simultaneous tool calling: The ability for an LLM to invoke multiple tools/functions within a single turn or step. "does not have built-in support for simultaneous tool calling,"
- Vassal (diplomatic): A game-defined subordinate state bound by diplomatic status/mechanics. "the introduction of diplomatic vassals"
- Vox Populi: A community Civilization V mod that expands game systems and improves the AI. "Vox Populi (aka Community Patch Project) is a popular Civilization V mod"
- VPAI: The Vox Populi algorithmic AI responsible for tactical execution in this study’s baseline. "Vox Populi's algorithmic AI (VPAI)"
- Zero-sum game: A game where one player’s gains equal others’ losses, keeping total payoff constant. "fixed-team, zero-sum games,"
Collections
Sign up for free to add this paper to one or more collections.

