UniFusion: Vision-Language Model as Unified Encoder in Image Generation
Abstract: Although recent advances in visual generation have been remarkable, most existing architectures still depend on distinct encoders for images and text. This separation constrains diffusion models' ability to perform cross-modal reasoning and knowledge transfer. Prior attempts to bridge this gap often use the last layer information from VLM, employ multiple visual encoders, or train large unified models jointly for text and image generation, which demands substantial computational resources and large-scale data, limiting its accessibility.We present UniFusion, a diffusion-based generative model conditioned on a frozen large vision-LLM (VLM) that serves as a unified multimodal encoder. At the core of UniFusion is the Layerwise Attention Pooling (LAP) mechanism that extracts both high level semantics and low level details from text and visual tokens of a frozen VLM to condition a diffusion generative model. We demonstrate that LAP outperforms other shallow fusion architectures on text-image alignment for generation and faithful transfer of visual information from VLM to the diffusion model which is key for editing. We propose VLM-Enabled Rewriting Injection with Flexibile Inference (VERIFI), which conditions a diffusion transformer (DiT) only on the text tokens generated by the VLM during in-model prompt rewriting. VERIFI combines the alignment of the conditioning distribution with the VLM's reasoning capabilities for increased capabilities and flexibility at inference. In addition, finetuning on editing task not only improves text-image alignment for generation, indicative of cross-modality knowledge transfer, but also exhibits tremendous generalization capabilities. Our model when trained on single image editing, zero-shot generalizes to multiple image references further motivating the unified encoder design of UniFusion.




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What’s this paper about?
This paper introduces UniFusion, a new way for computers to create and edit images from text and pictures. Instead of using one system to understand text and a different one to understand images, UniFusion uses a single “brain” (a vision-LLM, or VLM) to understand both. This makes it better at following instructions, using reference images, and doing complex edits, all in one model.
What questions were the researchers trying to answer?
They focused on a few simple questions:
- Can using one shared encoder for both text and images make image generation and editing more accurate and flexible?
- How can we best extract useful information from a big vision-LLM without retraining it?
- Can this approach work well even with less training data and computing power than other cutting-edge systems?
- Will skills learned for editing help with regular image generation (and vice versa)?
How did they do it? (Methods in plain language)
Think of image generation like cooking:
- The “recipe” is your prompt (text and possibly reference images).
- The “chef” is a diffusion model (a kind of generator that turns noise into pictures step by step).
- The “translator” that explains your recipe to the chef is the encoder.
Most systems use two translators: one for text and one for images. UniFusion uses a single translator—a Vision-LLM (VLM)—for both, so text and images live in the same “language” inside the model. This helps the chef understand the full story consistently.
Key ideas they introduced:
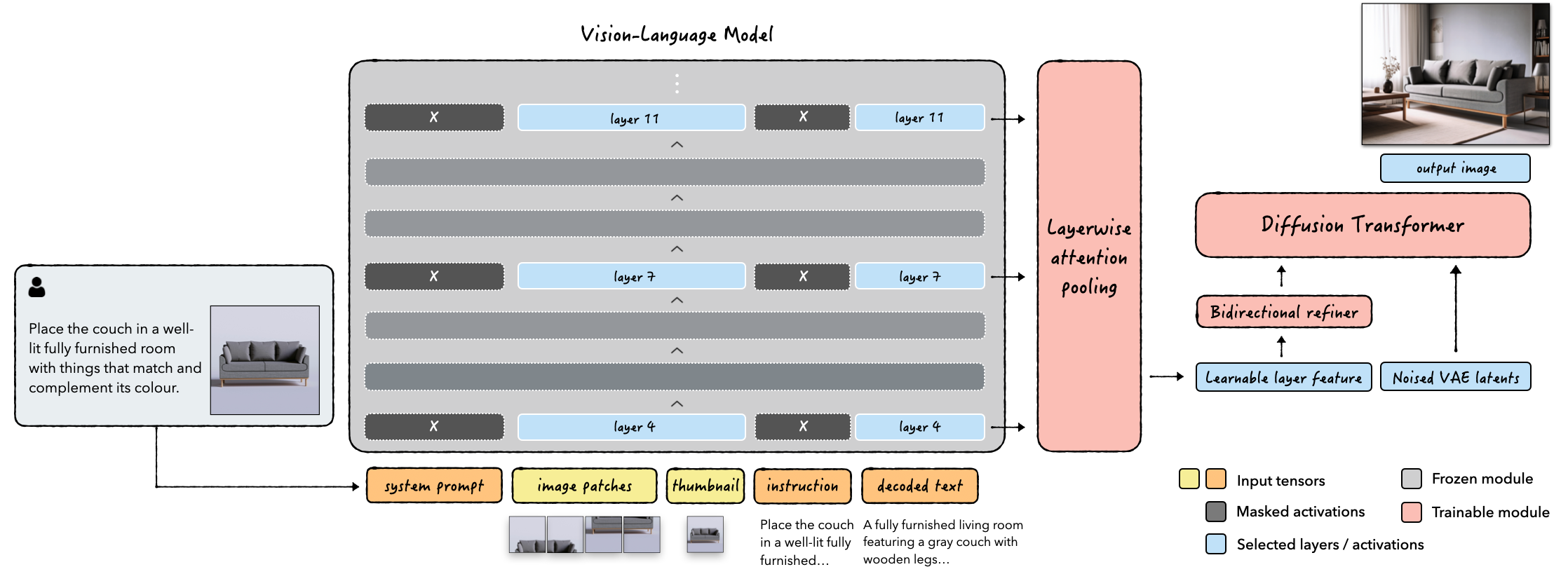
- Layerwise Attention Pooling (LAP)
- What it is: The VLM has many layers, like pages in a book. Early layers notice fine details (edges, textures); later layers understand big ideas (what objects are, how they relate). LAP “listens” to several layers at once and smartly combines them, so the model gets both details and meaning.
- Why it matters: Using only the last layer (just the big ideas) often loses small but important details; using multiple layers keeps both.
- Verifi (VLM-Enabled Rewriting)
- What it is: The VLM rewrites your prompt into a clearer, more detailed version during the same forward pass. It’s like asking a helpful assistant to restate your request more precisely, then giving that version to the image generator.
- Why it matters: This helps the model follow instructions better, use its built-in knowledge, and handle tricky prompts (like multiple subjects or long descriptions).
- Frozen VLM, light add-ons
- They don’t retrain the VLM (it’s “frozen”)—they just read from it. They add a small “refiner” (two transformer blocks) to fix a known issue where models that read left-to-right can miss important words that come late in the prompt (called position bias).
- More image “tiles” for fine details
- When encoding a reference image, they split it into multiple tiles so the VLM sees more detail. More tiles = better preservation of tiny features like hair strands or fabric patterns.
- Injection strategy
- Instead of injecting VLM features into every layer of the image generator, they pool everything once (with LAP) and feed it at the beginning. This turned out simpler and more effective.
- Practical training
- They show you can start from an existing model (trained with a text encoder like T5), switch to UniFusion’s unified VLM setup mid-training, and still end up just as good as training UniFusion from scratch—saving compute.
What did they find, and why is it important?
Main results:
- Better instruction following with fewer resources
- With an 8B VLM and an 8B diffusion transformer, UniFusion beats or matches strong models (like Flux.1 [dev] and BAGEL) on an alignment benchmark (DPG-Bench), using less than 1 billion training samples.
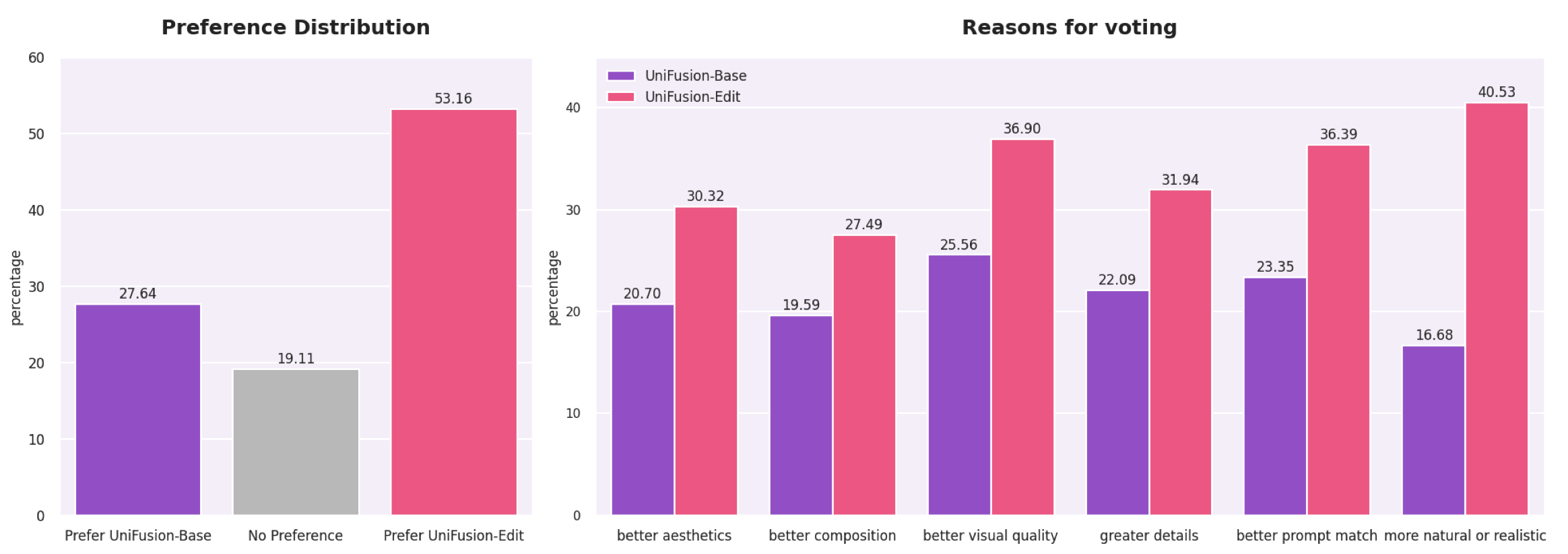
- Strong editing without extra post-training
- It compares favorably to specialized editing models (like Flux.1 Kontext [dev] and Qwen-Image-Edit) even without extra tuning after training.
- Keeps fine details from reference images
- By using multiple image tiles through the VLM and aggregating multiple layers with LAP, UniFusion preserves small visual details well—crucial for high-quality edits.
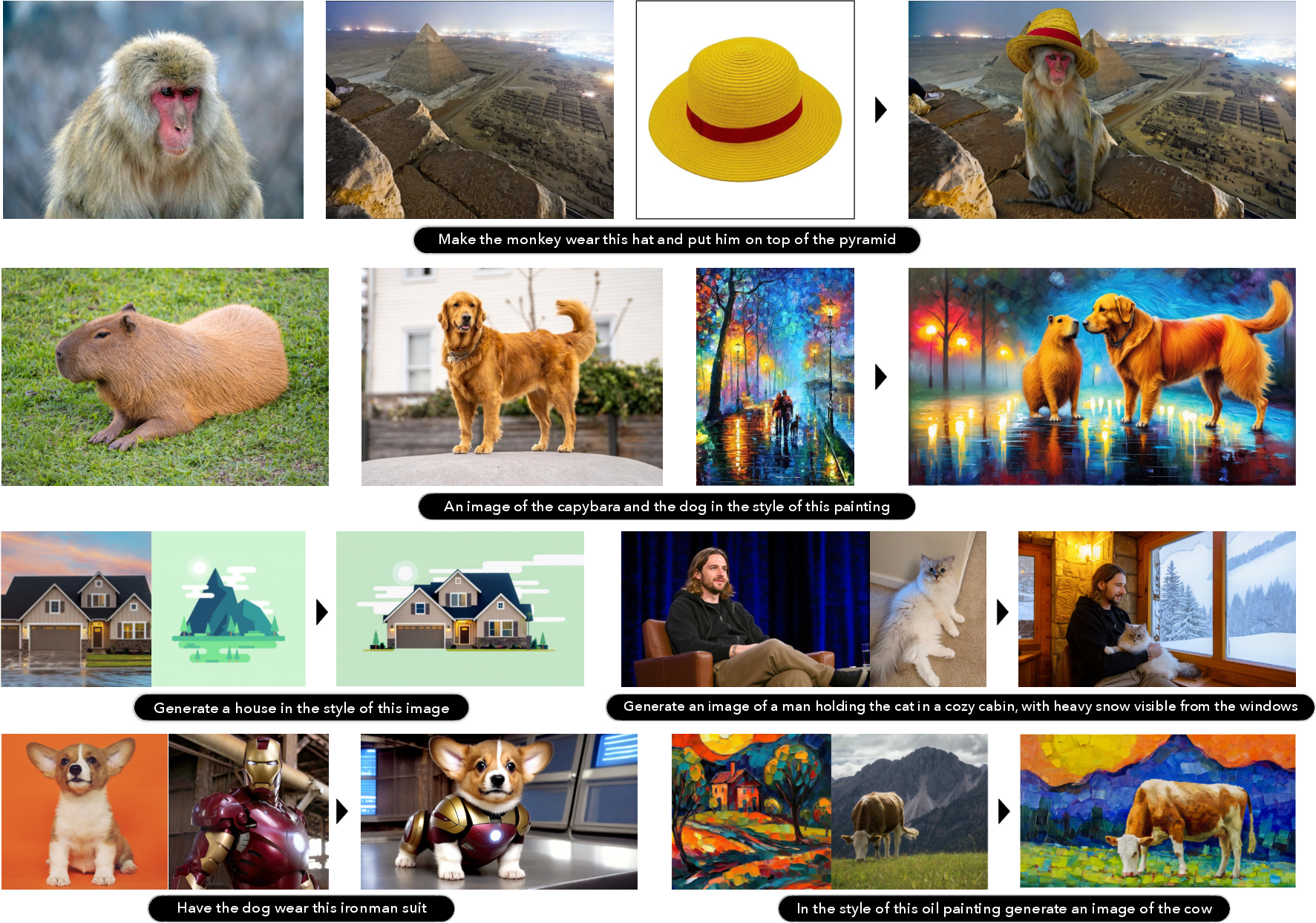
- Zero-shot superpowers (works on things it wasn’t directly trained for)
- It can use multiple reference images even though it was only trained with single references.
- It can do image-to-image variations even if trained mainly on text-to-image.
- Cross-task positive transfer
- Training on editing actually improved plain text-to-image results—evidence that sharing one encoder helps knowledge transfer across tasks.
- Simpler, more flexible design
- LAP (multi-layer pooling) clearly outperformed other ways of fusing VLM features (like using only the last layer, or doing tight layer-by-layer fusions that restrict architecture choices).
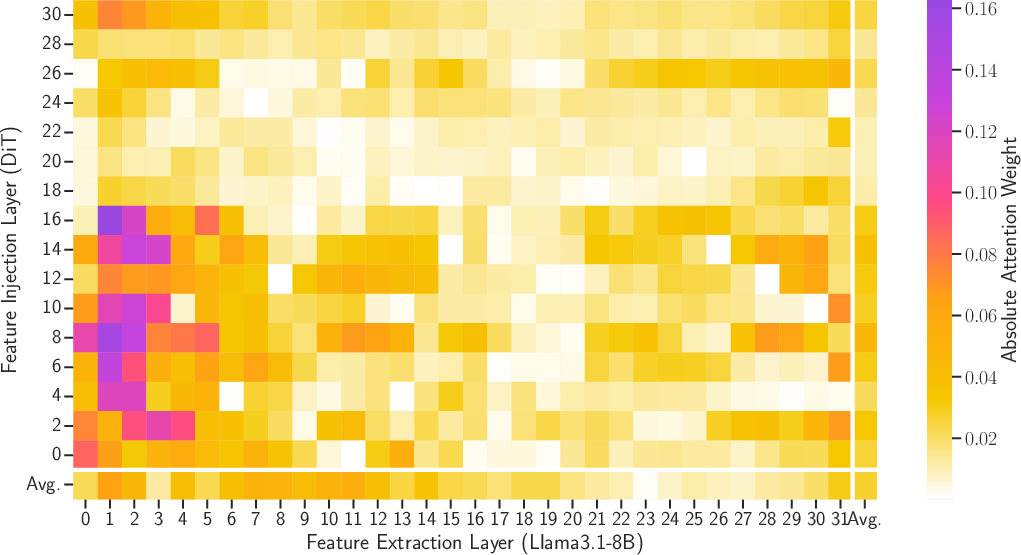
- Sampling every third VLM layer captured the needed information while cutting redundancy and memory.
Why this matters:
- Using one shared encoder reduces the “mismatch” problem where text and image encoders don’t agree (one focuses on meaning, the other on pixel detail). A shared space makes reasoning and editing smoother and more faithful.
- Verifi’s in-context rewriting uses the VLM’s world knowledge and improves prompt adherence, especially for complex prompts with multiple subjects.
- The approach is compute-friendly: reuse a frozen VLM, add a lightweight pooling and refiner, and you can even switch from an existing model mid-training.
What’s the bigger impact?
- Easier, more capable creative tools
- One model can handle text-to-image, image editing, and multi-reference composition with strong reasoning and detail—useful for artists, designers, and everyday users.
- Better generalization with less data
- The model inherits the VLM’s understanding of the world and language, so it can tackle new tasks without special training.
- A cleaner path forward
- Instead of building and maintaining separate pipelines for text and images, a unified encoder simplifies design and often boosts quality.
- The method encourages modularity: keep a strong VLM frozen, add smart adapters (LAP + refiner + Verifi), and you get a powerful, flexible system.
In short, UniFusion shows that using a single, shared “translator” for both words and pictures—carefully pooled across layers and paired with smart prompt rewriting—can make image generation and editing more accurate, detailed, and versatile, all while staying efficient.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of concrete gaps and open questions that remain unresolved and could guide future work.
- Quantify the compute and memory overhead of UniFusion’s unified encoding, especially with LAP plus high image tile counts (e.g., 10 tiles): end-to-end latency, throughput, GPU memory, and cost vs. quality trade-offs.
- Systematically evaluate Verifi (VLM-enabled rewriting) for instruction faithfulness: when does rewriting omit, add, or distort user intent; what are failure modes on multi-subject, compositional, or very short prompts; how does it behave under adversarial inputs?
- Measure safety, bias, and fairness implications inherited from the frozen VLM when used as a unified encoder: demographic biases in generated images, stereotype amplification, toxicity propagation through rewritten prompts, and safety filter effectiveness.
- Assess multilingual robustness: does Verifi and LAP maintain instruction fidelity and visual grounding for non-English prompts, code-switching, and low-resource languages?
- Explore partial unfreezing or lightweight adaptation (e.g., LoRA, adapters) of the VLM to reduce position bias and improve low-level detail preservation without sacrificing generalization; compare against the current “frozen VLM + refiner” approach.
- Ablate and generalize the “every third layer” selection rule: identify whether optimal layer sampling depends on task, VLM family, or model size; test dynamic, per-token layer selection, gating, or mixture-of-experts over layers.
- Investigate alternative LAP architectures: vary the number of transformer blocks, attention patterns (e.g., cross-layer cross-token), pooling functions (e.g., attention pooling vs. FC), and normalization to optimize quality vs. compute.
- Compare unified encoding across different VLM families and architectures (decoder-only, encoder-decoder, bidirectional): quantify the impact of causal vs. bidirectional attention, pretraining corpus, and instruction tuning on prompt adherence and editing fidelity.
- Develop metrics that capture unified encoder strengths (cross-modal consistency, grounded reasoning, image-detail preservation) beyond saturated benchmarks; propose standardized evaluations for zero-shot multi-reference composition and reasoning-heavy prompts.
- Provide a rigorous, quantitative evaluation of editing performance: disentangle content preservation vs. instruction strength, identity preservation (especially faces), style transfer fidelity, and localized vs. global edits across diverse datasets.
- Clarify and control multi-reference composition: introduce weighting mechanisms or user controls to resolve conflicts among multiple references, and evaluate consistency across varying numbers of references and conflicting attributes.
- Design dynamic image tiling strategies: adaptive tile counts based on image resolution, content complexity, and small-object density; study how tile placement and patch sampling affect fine-grained preservation and efficiency.
- Examine injection strategies for localized control tasks (e.g., inpainting, masked edits, spatial layout control): does late-layer injection, cross-attention, or per-region conditioning offer advantages over single-sequence input injection?
- Assess robustness to out-of-distribution inputs: crowded scenes, occlusions, extreme aspect ratios, high resolutions, noisy or low-quality references, and complex relational prompts with multiple constraints.
- Expand safety and privacy analyses for image inputs: risks of PII leakage in references, watermark handling, copyright enforcement, and consistency of safety behaviors between original and rewritten prompts.
- Compare hybrid conditioning (VLM features + VAE image tokens) vs. VLM-only for ultra-fine details: identify regimes where adding VAE tokens improves fidelity without harming unified reasoning or flexibility.
- Evaluate alternative generative objectives (e.g., EDM, rectified flow, SDXL-style objectives) under unified conditioning: training stability, sample quality, and alignment dynamics relative to InstaFlow.
- Quantify the benefits and risks of changing the system prompt at inference: reproducibility, predictability, and user control; characterize distribution shifts introduced by different templates or personas.
- Report detailed data composition and caption quality: how dataset diversity, instruction style, and licensing constraints affect unified conditioning performance and generalization; provide replicable training recipes.
- Establish scaling laws for unified encoders: performance as a function of DiT size, VLM size, LAP capacity, number of tiles, and training tokens to guide resource allocation.
- Investigate compression and deployment: distillation of unified representations to smaller encoders, quantization, or pruning of LAP and refiner for edge/mobile use while maintaining reasoning and detail preservation.
- Analyze sequence length and truncation effects: how long chat templates and rewritten prompts interact with memory limits; strategies for summarization or hierarchical rewriting without losing critical details.
- Perform human preference studies for high-quality regimes: side-by-side evaluations against strong baselines across generation and editing, since automated metrics are claimed to saturate.
- Develop explicit controllability interfaces within the unified encoder paradigm: negative prompts, layout/segmentation/depth guidance, style locks, and per-reference attribute control without breaking unified conditioning.
- Explore temporal and 3D extensions: can unified VLM features support video generation, temporal consistency, or 3D scene synthesis; what modifications to LAP or injection are needed?
- Characterize adversarial resilience: how do jailbreaks or instruction attacks affect Verifi and downstream image behavior; propose defenses and auditing tools.
- Formalize reproducibility: release code/weights or detailed pseudo-code for LAP/refiner, training schedules, and Verifi prompts to ensure independent verification and facilitate adoption.
Practical Applications
Immediate Applications
Below is a set of actionable, sector-linked use cases that can be deployed now, leveraging the paper’s findings on unified VLM conditioning, Layerwise Attention Pooling (LAP), and Verifi (VLM-enabled prompt rewriting).
- Creative software: unified, high-fidelity text-driven image editing and reference composition
- Sectors: software, media/entertainment, advertising
- What: Ship an “UniFusion Editor” feature that uses VLM-only image tokens with LAP for fine-detail preservation; enable single-checkpoint workflows for text-to-image, style transfer, and image edits (including multi-reference moodboards).
- Tools/workflows: LAP-conditioned DiT plugin; Verifi-powered prompt-rewrite pane; multi-reference canvas; tile-aware image input.
- Assumptions/dependencies: Access to a frozen 8B-class VLM (e.g., InternVL3-8B) and ~8B DiT; GPU inference; sufficient image tiling (up to 10 tiles) for fine details; guardrails for prompt rewriting; licensing-compliant training data.
- E-commerce and advertising: brand-consistent asset generation at scale
- Sectors: retail, marketing, design ops
- What: Batch-generate product visuals from structured specs + reference photos; use Verifi to standardize and densify prompts; single model handles both generation and editing (no separate checkpoints).
- Tools/workflows: Prompt Rewriter API (Verifi), brand style tokens, reference composition tool, asset QA loop using VQA/DreamSim.
- Assumptions/dependencies: Reliable system prompts; brand safety rules integrated into rewriting; image rights and provenance tracking.
- Interior design and architecture: moodboard-to-render concepts
- Sectors: AEC, real estate
- What: Compose room/layout renders from multiple reference images (materials, textures, styles) and long textual briefs; zero-shot multi-reference generalization reduces custom training needs.
- Tools/workflows: Multi-reference composer, tile-aware input for texture fidelity, scenario-specific system prompts.
- Assumptions/dependencies: High-resolution tiling for fine-grained patterns; domain-specific prompting; human review.
- Social media and everyday photo editing: identity-preserving edits and stylistic transformations
- Sectors: consumer apps, prosumer tools
- What: Text-driven edits (background changes, color/texture tweaks) that preserve subjects; apply consistent styles across photo sets via references.
- Tools/workflows: Mobile/desktop editor with Verifi-based “explain my intent” rewrite; batch style application; history of edits as prompts.
- Assumptions/dependencies: Likely server-side inference initially; privacy-safe handling of personal images; content safety policies.
- Education and publishing: accurate, instruction-following illustrations
- Sectors: education, editorial
- What: Generate didactic visuals from complex, long prompts; Verifi improves adherence and reduces “missed subject” failures.
- Tools/workflows: Classroom illustration generator; curriculum-aware system prompts; editorial QA with VQA metrics.
- Assumptions/dependencies: Safety filters (e.g., age-appropriate content); alignment to curriculum standards.
- ML engineering: drop-in unified encoder adoption for existing T5-conditioned pipelines
- Sectors: software/ML tooling
- What: Convert T5-based image generation systems to unified VLM conditioning without retraining from scratch; adopt LAP and refiner to mitigate position bias.
- Tools/workflows: “Unified Encoder Toolkit” (LAP module + refiner + Verifi integration), continued pre-training (10–20k steps) from existing checkpoints.
- Assumptions/dependencies: Access to frozen multimodal VLM; modest compute for finetuning; adherence to chat templates during rewriting.
- Synthetic data generation for vision model training
- Sectors: robotics, automotive, retail analytics
- What: Create controlled variations (textures, lighting, backgrounds) from references while preserving fine details (hair, fabrics, small objects) via tile-aware VLM encoding.
- Tools/workflows: Data factory pipeline with LAP-conditioned DiT, policy-controlled rewriting for safe variation, automated labeling.
- Assumptions/dependencies: Data licensing and consent; labeling and validation loops; quality gates (LPIPS/DreamSim targets).
- Content safety and moderation via controlled prompt rewriting
- Sectors: policy, platform governance
- What: Use Verifi to normalize, sanitize, or deny unsafe requests while preserving user intent; align conditioning distributions across modalities.
- Tools/workflows: Safety prompt templates; refusal/redirect flows; audit logs of rewrites.
- Assumptions/dependencies: Robust safety prompts; adversarial testing; oversight for edge cases.
- Publication and documentation illustrations from technical text
- Sectors: academia, technical writing
- What: Convert long sections into figures/diagrams with prompt rewriting for clarity; leverage unified encoder for nuanced semantics.
- Tools/workflows: “Figure-from-text” pipeline; editorial checks; provenance tagging.
- Assumptions/dependencies: Domain prompt engineering; human-in-the-loop.
- MLOps simplification: one checkpoint for both generation and editing
- Sectors: software, platform engineering
- What: Reduce model sprawl and maintenance by deploying UniFusion as a single model for T2I and IE; unified encoder avoids separate VAE/image encoders.
- Tools/workflows: Model registry updates; CI/CD for one artifact; common evaluation suite (GenAI Bench, DPG-Bench, editing tests).
- Assumptions/dependencies: Performance parity in production contexts; monitoring for drift; clear rollback plans.
Long-Term Applications
The following use cases require further research, scaling, integration, or domain adaptation before broad deployment.
- Multimodal creative agents with iterative, in-context editing
- Sectors: software, media, productivity
- What: Agents that reason over text+images, rewrite prompts, perform multi-step edits, and negotiate constraints (brand, safety, aesthetic goals).
- Tools/workflows: Conversational memory, planning/RL for multi-turn tasks, Verifi-driven scene understanding.
- Assumptions/dependencies: Reliable multi-turn alignment; agent safety frameworks; user experience design for co-creation.
- Unified-encoder video generation and editing
- Sectors: entertainment, education, advertising
- What: Extend unified VLM conditioning and LAP to temporal models for frame-consistent video synthesis and edits from complex instructions.
- Tools/workflows: Video DiT with temporal attention; tile-aware video encoding; prompt rewriting across time.
- Assumptions/dependencies: Large-scale video training; temporal consistency metrics; compute and data scale.
- CAD/3D and scene synthesis from multi-modal briefs
- Sectors: manufacturing, AEC, robotics
- What: Condition 3D diffusion/implicit models on unified text+image representations for assembly layouts, product concepts, and scene graphs.
- Tools/workflows: 3D-aware LAP; mesh/point-cloud integration; multimodal spec parsing via Verifi.
- Assumptions/dependencies: Domain datasets and metrics; geometry-aware training; expert validation.
- Healthcare and medical education visuals
- Sectors: healthcare, med-ed
- What: High-fidelity, anatomy-preserving educational images and de-identification edits from text requirements and reference scans.
- Tools/workflows: Medical VLMs; compliance-aware rewriting; clinical review pipelines.
- Assumptions/dependencies: Strict regulatory compliance (HIPAA, GDPR); domain VLM fine-tuning; risk management and provenance.
- Policy compliance and provenance-by-design
- Sectors: governance, standards
- What: Use VLM reasoning and rewriting to enforce policy constraints (copyright, safety, fairness) and attach provenance/watermarking to outputs.
- Tools/workflows: Policy templates for Verifi; integrated watermarking; audit trails; compliance dashboards.
- Assumptions/dependencies: Standardized policy schemas; cross-platform provenance protocols; independent audits.
- On-device and edge deployment through model compression
- Sectors: mobile, embedded, creator tools
- What: Distill/quantize UniFusion (VLM + DiT + LAP + refiner) for local inference (privacy, latency) with scaled-down tile strategies.
- Tools/workflows: Quantization-aware training; adaptive tiling; resource-aware Verifi.
- Assumptions/dependencies: Acceptable quality under compression; hardware acceleration; robust safety on-device.
- Retail virtual try-on and personalized product visualization
- Sectors: fashion, retail tech
- What: Multi-reference conditioning (user photos + catalog images) to create realistic try-ons and personalized product renders.
- Tools/workflows: Identity-preserving conditioning; garment/material tokens; feedback loops.
- Assumptions/dependencies: Privacy and consent; domain-specific validation; real-world generalization.
- Robotics simulation and domain randomization
- Sectors: robotics, autonomous systems
- What: Generate rich synthetic environments with precise, instruction-followed edits to accelerate perception and planning model training.
- Tools/workflows: Scenario libraries; safety-aware prompt rewriting; sim-to-real validation.
- Assumptions/dependencies: High-fidelity scene diversity; label consistency; transfer efficacy.
- Cultural heritage restoration and curation
- Sectors: museums, archives
- What: Reference-guided restoration, style-constrained reconstructions, and exhibit visuals from textual descriptions and fragment images.
- Tools/workflows: Curator-in-the-loop; provenance-preserving pipelines; ethical guidelines.
- Assumptions/dependencies: Domain expertise; ethical and legal frameworks; data authenticity.
- Financial services design automation
- Sectors: finance, corporate communications
- What: Brand-compliant visual report generation and campaign assets from detailed briefs, with Verifi enforcing constraints.
- Tools/workflows: Compliance prompts; brand tokens; review workflows.
- Assumptions/dependencies: Stringent compliance integration; risk controls; approval hierarchies.
Cross-cutting assumptions and dependencies (applicable across many use cases)
- Model components: A frozen, instruction-tuned multimodal VLM (with chat template usage), LAP pooling across every third layer, a bi-directional refiner to mitigate position bias, and an ~8B DiT.
- Data and licensing: Training/finetuning on permissive datasets; ongoing provenance and content rights management.
- Performance constraints: Adequate tiling (up to 10 tiles) for detail preservation; GPU/accelerator access; monitoring of prompt adherence and editing fidelity.
- Safety and governance: Robust Verifi system prompts; content filters; auditability of prompt rewrites; mitigation of misuse (e.g., deepfakes).
- MLOps: Single-checkpoint maintenance for generation + editing; evaluation suites (VQA, DPG-Bench, editing benchmarks); drift and reliability monitoring.
Glossary
- AdamW: An optimizer with decoupled weight decay commonly used for training deep neural networks. "AdamW optimizer \cite{Loshchilov2019decoupled}"
- Attention heads: Parallel attention mechanisms in multi-head attention that allow a model to focus on different aspects of the input. "32 attention heads"
- Auto-regressive model: A model that generates outputs sequentially, where each token depends on previous tokens via causal masking. "strong auto-regressive model"
- Bi-directional refiner: A small transformer module with bidirectional attention used to mitigate position bias in representations. "combines Layerwise Attention Pooling with a bi-directional refiner"
- Causal attention masking: An attention constraint where tokens can only attend to past tokens, introducing positional bias. "causal attention masking of auto-regressive models"
- Cross-attention: An attention mechanism where queries attend to a different set of keys/values (e.g., text conditioning in image models). "text-latent cross-attention in U-Nets"
- DiT: Diffusion Transformer; a transformer-based architecture for diffusion image generation. "diffusion transformer (DiT)"
- Diffusion-based generative model: A generative model that synthesizes data by denoising from noise through a diffusion process. "a diffusion-based generative model conditioned on a frozen large vision-LLM (VLM)"
- Distribution shift: A mismatch between training and inference input distributions that can degrade performance. "reduces distribution shift between different input prompt formats"
- DreamSim: A perceptual similarity metric used to evaluate visual fidelity. "DreamSim metric \cite{fu2023dreamsim}"
- Flan T5 XXL: A large instruction-tuned T5 LLM used for text embeddings/conditioning. "Flan T5 XXL \cite{chung2024scaling}"
- GenAI Bench: A benchmark used to assess text-to-image generation quality, often via VQA-based scoring. "GenAI Bench performance"
- Hidden State Injection (HSI): A fusion technique that injects encoder hidden states into decoder layers, typically by adding to the residual stream. "it outperforms HSI and last hidden layer approaches"
- InstaFlow: A training objective for diffusion-like models that improves convergence efficiency. "InstaFlow training objective \cite{liu2023instaflow}"
- InternVL: A family of vision-LLMs used as unified encoders for text and images. "InternVL3-8B \cite{zhu2025internvl3}"
- Key-Value Fusion: A fusion method that concatenates attention keys/values from the encoder and generator at corresponding layers. "Layerwise Key-Value Fusion"
- Keys and Values: Components of attention; keys determine which information to attend to and values contain the content to aggregate. "concatenate the Keys and Values of the DiT with the respective Keys and Values of the encoder"
- LAP (Layerwise Attention Pooling): A module that attends across encoder layers to aggregate multi-depth features into a pooled representation. "Layerwise Attention Pooling (LAP)"
- Latent space: A compressed representation space (e.g., from a VAE) where generation or transformation is performed. "operates on a VAE latent space with a compression factor of $16$"
- Llama 3.1-8B: A specific LLM variant used as an encoder for text conditioning. "Llama3.1-8B \cite{grattafiori2024llama3}"
- LPIPS: A learned perceptual metric for image similarity used in reconstruction/variation evaluations. "LPIPS \cite{zhang2018perceptual}"
- Multimodal: Refers to models or training that jointly handle multiple modalities like text and images. "joint multimodal training"
- Patchification: Splitting an input (often latents) into patches for transformer processing. "2x2 patchification"
- Penultimate layer: The second-to-last layer of a neural network, often used to extract rich representations. "use the penultimate layer instead of the last one"
- Position bias: A tendency caused by causal attention where tokens earlier or later in the sequence are represented unevenly. "position bias due to causal attention"
- Query-Key norms: Norm-based diagnostics of attention queries/keys used to analyze which layers/tokens are emphasized. "Query-Key norms for individual tokens"
- Refiner: A transformer module applied after pooling to counteract attention biases and improve representation quality. "A subsequent refiner counteracts the VLM's position bias due to causal attention."
- Residual stream: The main representation pathway in transformers that is added across blocks, into which features can be injected. "residual stream between transformer blocks"
- RMSNorm: A normalization technique based on root mean square used to stabilize training. "RMSNorm layer \cite{zhang2019rmsnorm}"
- Self-attention: An attention mechanism where tokens attend to other tokens within the same sequence. "full self-attention"
- System prompt: An initial instruction provided to a VLM to guide rewriting or reasoning behavior. "use a dedicated system prompt to instruct the VLM to generate a target prompt"
- Tiles (image tiles): Subdivisions of an input image used to increase token count and preserve fine-grained details during encoding. "We compared different numbers of image tiles used in the image encoding of the VLM."
- U-Net: A common encoder-decoder CNN architecture used in diffusion models, often with cross-attention for conditioning. "text-latent cross-attention in U-Nets"
- VAE (Variational Auto-Encoder): A generative model that compresses images into latents and reconstructs them, used for image conditioning. "variational auto-encoder (VAE) latents for images"
- VAE latents: Compressed continuous representations produced by a VAE used as input to generation models. "variational auto-encoder (VAE) latents for images"
- Verifi: VLM-Enabled Rewriting Injection with Flexible Inference; a method that conditions DiT on rewritten tokens from the VLM. "VLM-Enabled Rewriting Injection with Flexible Inference (Verifi)"
- Vision-LLM (VLM): A model jointly trained or designed to process both visual and textual inputs. "vision-LLM (VLM)"
- VQA score: A metric derived from visual question answering used to quantify prompt adherence in generations. "VQA score on GenAI bench \cite{li2024genaibench}"
- Zero-shot: Performing tasks without explicit training or fine-tuning for those tasks. "Zero-shot reasoning."
Collections
Sign up for free to add this paper to one or more collections.

