SVG-T2I: Scaling Up Text-to-Image Latent Diffusion Model Without Variational Autoencoder
Abstract: Visual generation grounded in Visual Foundation Model (VFM) representations offers a highly promising unified pathway for integrating visual understanding, perception, and generation. Despite this potential, training large-scale text-to-image diffusion models entirely within the VFM representation space remains largely unexplored. To bridge this gap, we scale the SVG (Self-supervised representations for Visual Generation) framework, proposing SVG-T2I to support high-quality text-to-image synthesis directly in the VFM feature domain. By leveraging a standard text-to-image diffusion pipeline, SVG-T2I achieves competitive performance, reaching 0.75 on GenEval and 85.78 on DPG-Bench. This performance validates the intrinsic representational power of VFMs for generative tasks. We fully open-source the project, including the autoencoder and generation model, together with their training, inference, evaluation pipelines, and pre-trained weights, to facilitate further research in representation-driven visual generation.









Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces SVG-T2I, a new way to make images from text by working directly inside a “feature space” learned by powerful vision models, instead of using the usual VAE (Variational Autoencoder) compression. The goal is to show that the same kind of features used to understand images can also be used to generate high-quality images, and to do it at large scale and high resolution.
The big questions the paper tries to answer
- Can one shared “feature space” support many things at once—like seeing, understanding, reconstructing, and generating images—without getting worse at any of them?
- Can these features (from Visual Foundation Models, or VFMs) handle big, real-world text-to-image training at high resolutions, like modern image generators do?
How does it work? (Methods explained simply)
Think of an image as a story. Different tools summarize that story in different ways:
- A VAE compresses the story into a small code focused on reconstruction (turning code back into pixels).
- A VFM (Visual Foundation Model, like DINOv3) turns an image into a rich set of “features” that capture what’s in the picture—objects, textures, layouts—great for understanding.
SVG-T2I chooses the VFM route:
- It takes the VFM’s features as its “latent space” (the place where it learns and generates), not a VAE’s compressed space. This helps link understanding and generation more closely.
Key parts:
- Autoencoder-P (“Pure”): Uses frozen DINOv3 features and a decoder to turn features back into pixels. No extra tweaks—simple and clean.
- Autoencoder-R (“Residual”): Adds a small extra encoder branch to fix fine details (like sharp edges or colors) when needed.
- DiT backbone (Diffusion Transformer): A large transformer that treats text and image features as one long sequence, so words and visual features can interact naturally.
- Flow Matching training: Imagine you start with pure noise and need a smooth “path” to a real image’s features. Flow matching teaches the model the velocity (direction and speed) to move step-by-step from noise to those features, like following a carefully planned route from A to B.
Training in stages (like leveling up in a game):
- Train the autoencoders at lower resolution, then fine-tune at higher resolutions.
- Train the DiT model at low and medium resolutions to learn text–image alignment.
- Move to high resolution to learn fine details.
- Fine-tune on a smaller, very aesthetic dataset to polish the look.
What did they find, and why is it important?
Main results:
- Strong performance: SVG-T2I reaches about 0.75 on GenEval and 85.78 on DPG-Bench, which are widely used tests for text-to-image quality and alignment. That’s competitive with modern, popular diffusion models that use VAEs.
- High-resolution generation works: The model can generate images at 1024×1024 and above with good detail.
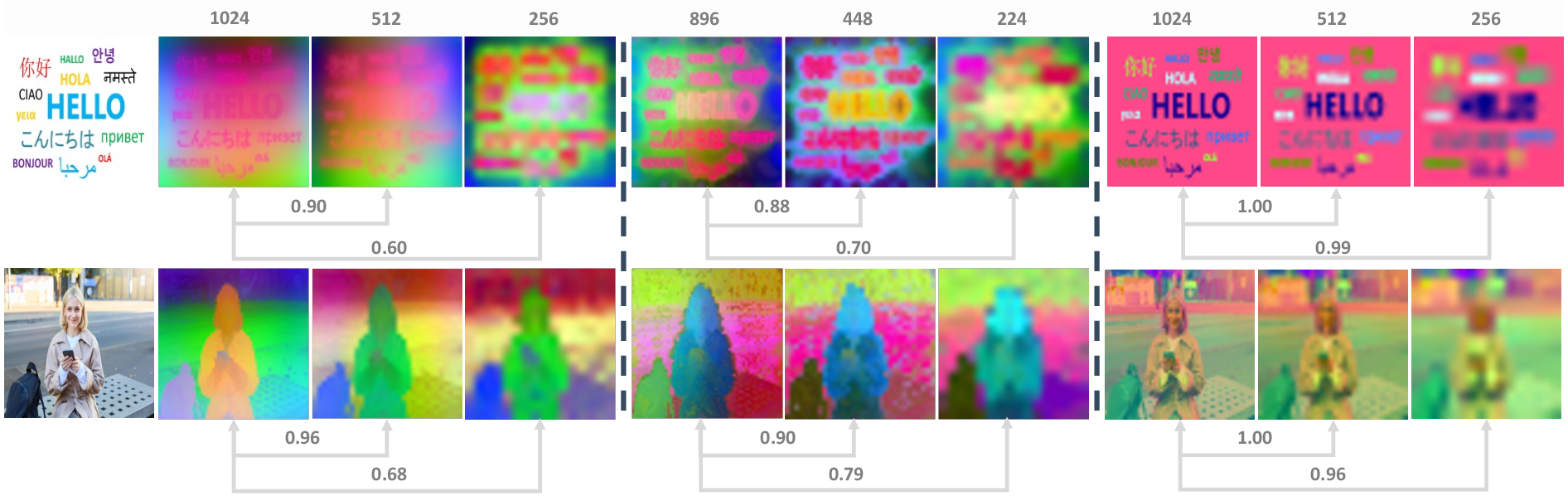
- Features matter with resolution: DINO features carry more detail at higher resolutions, and reconstructions look much better when the input is bigger. However, these features change more with scale than VAE latents do, which can make training across many sizes trickier.
Why this matters:
- It shows you don’t need a VAE to get great text-to-image results. You can generate images inside the same feature space used for understanding images.
- It moves the field toward a “unified” vision model: one encoder (like DINO) could someday handle understanding, reconstruction, and generation, instead of having separate tools for each task.
- The team open-sourced the code and models, which helps others build on this work quickly.
Limitations (what’s still hard):
- Very detailed human faces and hands (especially fingers) can be messy.
- Rendering accurate text in images (like signs or logos) is still unreliable.
- These issues usually need more specialized data and more training compute.
What’s the potential impact?
- Toward one shared vision backbone: Using VFM features as the place where generation happens could simplify future systems—fewer separate encoders for different tasks.
- Better efficiency and alignment: Working in a rich, semantic feature space may improve how text and image ideas connect, making generation more faithful to prompts.
- A new research direction: The paper highlights a key challenge—VFM features change with image scale more than VAE latents do. Making these features more “scale-invariant” could make training across many resolutions smoother and improve quality.
- Open tools for the community: With training, inference, evaluation pipelines, and weights released, others can test, adapt, and extend this representation-driven approach.
In short, SVG-T2I shows that powerful image-understanding features can also power high-quality image generation—bringing the field closer to a single, unified vision model that can see, understand, reconstruct, and create.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of the paper’s unresolved issues and opportunities for future work, written to be concrete and actionable.
- Unified multi-task encoder remains unevaluated: systematically test whether a single VFM feature space can jointly support reconstruction, perception, high-fidelity generation, and semantic understanding without performance regressions or catastrophic forgetting.
- Cross-resolution instability of VFM features is identified but unaddressed: design and evaluate training objectives and architectures that enforce scale-invariant feature geometry (e.g., multi-scale tokenizers, adaptive patch sizes, scale-aware positional embeddings, cross-scale contrastive/distillation losses).
- Autoencoder variants lack ablation: quantify the trade-offs between autoencoder-P (pure) and autoencoder-R (residual) across resolutions, including reconstruction fidelity, downstream generation quality, transferability, and compute/memory.
- Efficiency claims vs VAE-based LDMs are not measured: provide head-to-head comparisons on training speed, inference latency, memory footprint, and total compute cost at matched quality and resolution.
- Sampling and guidance in flow models are under-specified: ablate ODE solvers, step counts, and guidance schemes (e.g., classifier-free guidance, CFG-Zero*) to characterize alignment–diversity trade-offs in VFM feature space.
- Evaluation coverage is narrow: expand to T2i-compbench, long-prompt adherence, human preference studies, and robustness tests (OOD prompts, compositional complexity, adversarial prompts).
- Dataset composition and caption pipeline are opaque: release or detail the sources, licenses, filtering, aesthetic scoring, and domain coverage of Data C/D/E; run ablations on caption-length sampling ratios and language mixtures.
- Multilingual capability is not validated: measure performance across languages (Chinese vs English), code-switching, and non-Latin scripts; analyze failure patterns and caption quality effects.
- Known failure modes (faces, hands, text) lack targeted remedies: evaluate specialized datasets, architectural priors (face/hand modules), pose-aware objectives, and OCR/text-rendering heads or losses to improve anatomical and typographic accuracy.
- Counting remains weak (GenEval: 0.49): investigate detection-aware objectives, compositional curricula, multi-object grounding, and numeracy-specific datasets to improve object counting.
- Claim that DINOv3 suffices at high resolution is untested at extremes: benchmark the residual branch and alternative decoders at 2K–4K resolutions and for fine textures/reflections to confirm or refute the claim.
- VFM encoder choices and patch sizes are unexplored: compare DINOv2/DINOv3/SigLIP and variable patch/receptive fields; study multi-scale backbones and scale-aware RoPE to reduce semantic–texture drift across resolutions.
- No joint fine-tuning of the VFM encoder: assess end-to-end training effects on semantic discrimination, reconstruction fidelity, and downstream task transfer vs keeping the encoder frozen.
- Decoder design is not analyzed: ablate decoder depth/width, multi-scale/feature-pyramid decoding, and regularization to mitigate color cast and improve high-frequency detail.
- Single-stream transformer choice lacks comparison: test dual-stream and cross-attention designs for parameter efficiency, alignment robustness, and memory scaling.
- Numerical stability and solver choice are unexamined: evaluate Euler/Heun/DPM-Solver variants and adaptive step sizing for speed–quality improvements in VFM-space generation.
- Controllability is not demonstrated: integrate and evaluate controls for layout, depth, segmentation masks, sketches, and style in the VFM latent domain; measure their reliability.
- Safety and fairness are not audited: assess biases, harmful content generation, watermarking, and multilingual moderation; document mitigation strategies and prompt filtering.
- Reproducibility is limited by private data: provide public or synthetic substitutes, data curation recipes, and detailed preprocessing pipelines to enable end-to-end reproduction.
- Feature diagnostics are informal: develop formal probes/metrics for “semantic structure” and “resolution invariance,” and correlate them with generation quality across scales and domains.
- Ultra-high-resolution scalability is unknown: test ≥2048×2048 generation, extreme aspect ratios, tiling/pyramids, and progressive latent strategies in VFM space.
- Compute footprint is unreported: disclose training/inference energy and compute for the 2.6B model; explore parameter-efficient variants (LoRA, MoE, distillation) for resource-constrained settings.
- LLM rewriter usage is ambiguous in evaluation: clarify rewriter pipeline (if any), quantify its contribution, and report raw model performance without prompt rewriting.
- Domain generalization is untested: evaluate medical/scientific diagrams, charts, UI mockups, and text-heavy scenes; adapt the pipeline for domain-specific constraints and metrics.
Practical Applications
Practical Applications of SVG-T2I
Below are actionable, real-world applications derived from the paper’s findings, methods, and innovations. Each item is categorized as Immediate Application or Long-Term Application, mapped to relevant sectors, and includes potential tools/products/workflows and key assumptions or dependencies.
Immediate Applications
- Text-to-image content creation for creative industries
- Sectors: software, media/entertainment, marketing/advertising
- Tools/products/workflows:
- Integrate SVG-T2I into design tools (e.g., a plugin for Photoshop/Figma/Blender)
- Use the open-source weights and training/inference pipelines to deploy an internal T2I service for campaign ideation, mood boards, and scene layout visualization
- Multilingual prompt support via Gemma2 embeddings for international workflows
- Assumptions/dependencies:
- Adequate GPU resources for inference with a 2.6B-parameter DiT backbone
- Acceptance of current limitations (faces, fingers, text rendering) and use of iterative filtering/human curation
- Domain-specific generative fine-tuning for enterprises
- Sectors: e-commerce, gaming, industrial design, fashion
- Tools/products/workflows:
- Fine-tune SVG-T2I on proprietary product catalogs or stylized assets using the progressive, multi-resolution recipe
- Rapid style transfer and catalog expansion (e.g., “generate new colorways/contexts” for products)
- Assumptions/dependencies:
- Access to high-quality, legally compliant domain datasets and captions
- Adherence to the paper’s anchor resolutions (512→1024) for best fidelity
- Synthetic data generation for computer vision training
- Sectors: robotics, autonomous driving, retail analytics, manufacturing inspection
- Tools/products/workflows:
- Use SVG-T2I to generate diverse scenes with controllable compositions (validated on GenEval/DPG benchmarks), then train detection/segmentation models that share the same VFM encoder family (DINO) to reduce domain gap
- Build a “feature-aligned” data pipeline: generate in DINOv3 space, reconstruct to pixels, and ensure consistency between generation and perception stacks
- Assumptions/dependencies:
- Prompt engineering and filtering policies to avoid pathological samples
- Care with resolution choice due to the noted cross-resolution feature instability
- Representation-first generative stack consolidation
- Sectors: software engineering, MLOps
- Tools/products/workflows:
- Replace fragmented encoder stacks (e.g., separate VAE, CLIP/SigLIP, geometry encoders) with a single VFM encoder (DINOv3-based autoencoder-P) across understanding and generation tasks
- Standardize internal feature formats to simplify data flow and model interchange
- Assumptions/dependencies:
- Willingness to accept current VFM resolution sensitivity and optional residual encoder (autoencoder-R) for fidelity when needed
- Engineering investment to harmonize downstream task heads in a single-stream DiT
- Educational and communication visuals
- Sectors: education, non-profit, publishing
- Tools/products/workflows:
- Classroom content generation (illustrations, diagrams, scene examples) with multilingual captions for global curricula
- Lightweight internal content tools for teachers and editors using the prebuilt inference pipeline
- Assumptions/dependencies:
- Human review for text fidelity and anatomical correctness in sensitive topics
- Prefer fixed anchor resolutions (1024×1024) for highest consistency
- Evaluation and benchmarking adoption
- Sectors: academia, policy, standards organizations
- Tools/products/workflows:
- Use the open-source evaluation pipeline and public benchmarks (GenEval, DPG-Bench) to compare generative systems
- Establish internal QA gates for T2I deployments based on object alignment and compositional fidelity metrics
- Assumptions/dependencies:
- Agreement on benchmark coverage relative to deployment domain
- Clear reporting and documentation practices
- Cost-aware training/inference workflows
- Sectors: cloud/compute, startups building T2I services
- Tools/products/workflows:
- Leverage the VFM latent space for improved training/inference efficiency over pixel space and for easier reuse of encoders across tasks
- Progressive curriculum (256→512→1024) to control compute while scaling quality
- Assumptions/dependencies:
- Access to distributed training infrastructure for batch sizes described in the paper
- Monitoring of quality plateaus versus compute budgets
- Feature-space editing and variations
- Sectors: creative tooling, photo/video post-production
- Tools/products/workflows:
- Inversion-free, flow-based editing (inspired by cited FlowEdit) using SVG-T2I’s flow-matching model; implement prompt-based variations, minor style edits, and composition tweaks without full pixel-level pipelines
- Assumptions/dependencies:
- Additional engineering to adapt existing flow-edit methods to the SVG-T2I feature space
- Validation against failure modes (text, hands, faces)
Long-Term Applications
- Unified vision foundation model spanning perception, reconstruction, and generation
- Sectors: software, robotics, AR/VR/XR, general AI agents
- Tools/products/workflows:
- A “single encoder” ecosystem: one VFM backbone supports object recognition, geometry reasoning, text-to-image generation, inpainting, and reconstruction
- Cross-task training where understanding and generation share tokens and positional embedding strategies in a single-stream DiT
- Assumptions/dependencies:
- Advances in scale-invariant VFM encoders (addressing resolution-dependent feature shifts)
- Larger, more diverse training corpora and additional compute
- On-device and edge generative systems
- Sectors: mobile, embedded, consumer electronics
- Tools/products/workflows:
- Model compression/quantization strategies that maintain quality in the VFM space
- Edge pipelines that cache feature latents for quick render-on-demand in apps
- Assumptions/dependencies:
- Further architectural optimizations (smaller DiTs, distillation from 2.6B models)
- Hardware acceleration for transformer-based diffusion and flow matching
- Representation-based image codecs and data lakes
- Sectors: cloud storage, MLOps, data governance
- Tools/products/workflows:
- Store DINO-like features as compact, semantically structured latents; reconstruct pixels only when necessary
- Feature-centric dataset versioning and retrieval for training at scale
- Assumptions/dependencies:
- Resolving cross-resolution instability to ensure reliable reconstruction across sizes
- Careful privacy and compliance review (features are reconstructable)
- High-fidelity human rendering and typography
- Sectors: advertising, film/TV, gaming, publishing
- Tools/products/workflows:
- Specialized fine-tuning with curated human datasets and font/text corpora; hybrid modules for vector text rendering integrated into the DiT stream
- QA pipelines for anatomical correctness, pose realism, and legible typography
- Assumptions/dependencies:
- Access to ethically sourced, diverse human datasets and increased compute
- Safety alignment and bias auditing procedures
- Synthetic environments for autonomy and simulation-to-reality transfer
- Sectors: autonomous driving, robotics, urban planning
- Tools/products/workflows:
- Generate high-resolution, compositional scenes with controllable entities and relations (validated by DPG-Bench metrics) to train perception stacks
- Feature-level consistency between synthetic and real data via shared VFM encoders
- Assumptions/dependencies:
- Scale-invariant representation learning to maintain consistency across camera resolutions
- Policy-compliant synthetic data usage standards
- Cross-modal generative search and personalization
- Sectors: e-commerce, media platforms, personalization engines
- Tools/products/workflows:
- Retrieval-augmented generation: index catalogs in VFM feature space and generate personalized visuals conditioned on retrieved features plus text
- Interactive shopping assistants that render variations on the fly
- Assumptions/dependencies:
- Robust alignment between search embeddings and generation latents
- Guardrails for misrepresentation and transparency
- Safety, watermarking, and accountability in feature space
- Sectors: policy, compliance, platform governance
- Tools/products/workflows:
- Watermarking or provenance signals embedded at the feature level
- Standardized reporting using open benchmarks (e.g., GenEval compositional fidelity scores) for auditing generative services
- Assumptions/dependencies:
- Community standards for watermarking across VFM feature formats
- Collaboration with regulators on disclosure and labeling norms
- Encoder-agnostic generative ecosystem
- Sectors: open-source, research, platforms
- Tools/products/workflows:
- Generalize SVG-T2I to other VFM encoders (DINOv2, future self-distilled models) with stable feature geometry across scales
- Interchangeable “encoder plugs” with unified autoencoder decoders and single-stream DiTs
- Assumptions/dependencies:
- Advances in training objectives that enforce cross-resolution consistency
- Shared evaluation suites and open datasets for reproducible comparisons
Notes across all applications:
- The open-source code and weights on GitHub/Hugging Face make immediate prototyping and deployment feasible; however, training a 2.6B DiT remains compute-intensive.
- Limitations called out by the authors (faces, fingers, text rendering) should guide scoping, QA, and human-in-the-loop review in production.
- Legal, ethical, and licensing considerations for datasets and model usage are critical, particularly for domain-specific fine-tuning and human-centric content.
- For best practical outcomes, prefer fixed high-resolution anchors (e.g., 1024×1024) until scale-invariant VFM features are improved.
Glossary
- Autoencoder-P (Pure): An autoencoder variant that uses frozen DINOv3 features directly without a residual branch. "The first, autoencoder-P (Pure), utilizes frozen DINOv3 features directly."
- Autoencoder-R (Residual): An autoencoder variant with a residual branch to compensate high-frequency details and color artifacts. "The second, autoencoder-R (Residual), retains the residual branch design from SVG as an optional choice."
- Cross-modal interactions: Interactions between text and image tokens within a unified sequence for joint modeling. "which treats text and image tokens as a joint sequence, enabling natural cross-modal interactions and allowing seamless task expansion."
- DINOv3: A self-supervised visual encoder whose features serve as a high-dimensional latent space for generation. "we use the DINOv3-ViT-S/16+ encoder, which maps an image to a feature representation."
- DiT (Diffusion Transformer): A transformer architecture tailored for diffusion-based generative modeling. "We use the Unified Next-DiT architecture as our backbone"
- Distribution-matching strategy: A training technique to align the generated feature distribution with the target representation distribution. "autoencoder-R is optimized with both reconstruction losses and distribution-matching strategy on its residual branch and decoder following~\citep{svg}."
- DPG-Bench: A benchmark assessing diverse capabilities of text-to-image models, including entities, attributes, and relations. "reaching 0.75 on GenEval and 85.78 on DPG-Bench."
- Flow matching: A training method that learns a velocity field interpolating between Gaussian and data distributions. "we adopt the widely used flow matching method~\citep{rectifiedflow, lipman2023flowmatching, sd3} for training~SVG-T2I."
- GenEval: An object-focused evaluation framework for text-to-image alignment. "reaching 0.75 on GenEval and 85.78 on DPG-Bench."
- Latent diffusion model (LDM): A diffusion approach operating in a lower-dimensional latent space, typically via a VAE. "An enhanced approach, the latent diffusion model (LDM)~\citep{ldm,dit,sit,rectifiedflow}, incorporates a VAE~\citep{vae} into the diffusion pipeline to operate within a lower-dimensional latent space"
- Latent manifold: The semantic feature space within which generation is performed. "the VFM semantic space as an effective latent manifold for high-resolution synthesis."
- MAR: An autoregressive image generation paradigm trained without vector quantization. "trained under MAR~\citep{mar} or MetaQueries-style paradigms~\citep{metaqueries}"
- MetaQueries: A training paradigm for coupling self-distilled VFMs with decoders for reconstruction and generation. "trained under MAR~\citep{mar} or MetaQueries-style paradigms~\citep{metaqueries}"
- M-RoPE: A positional embedding scheme (multi-dimensional rotary positional embeddings) used in the DiT configuration. "Pos. Emb. M-RoPE"
- Probability flow ODE: The differential equation enabling deterministic sampling in flow-based generative models. "Sampling from a flow-based model can be achieved by solving the probability flow ODE."
- RAE (Representation Autoencoder): A framework combining representation learning with autoencoding to support diffusion transformers. "SVG~\citep{svg} and RAE~\citep{rae} take a further step by training diffusion models directly in the high-dimensional VFM feature space"
- Residual Encoder: An auxiliary encoder branch added to a VFM encoder to improve high-fidelity reconstruction. "we optionally augment the DINO encoder with a Residual Encoder to achieve high-quality reconstruction and preserve transferability."
- Scale invariance: The property of features remaining stable across different input resolutions. "VAE features exhibit limited semantic structure, yet demonstrate stronger scale invariance compared to DINO features."
- Self-supervised learning: Representation learning from unlabeled data via pretext objectives, providing robust perceptual features. "Large-scale self-supervised learning~\citep{webssl} has demonstrated that expanding model capacity and training data yields strong perceptual robustness"
- Single-stream design: An architecture that processes text and image tokens together in one transformer stream for efficiency. "We adopt this single-stream design to achieve greater parameter efficiency and to jointly process text and DINO features."
- Text-to-image (T2I): Generating images conditioned on textual prompts using a diffusion pipeline. "training a text-to-image diffusion model directly within the VFM feature space."
- Unified Next-DiT: A single-stream DiT backbone enabling joint processing of text and VFM features. "We use the Unified Next-DiT~\citep{lumina2} architecture as our backbone"
- Variational autoencoder (VAE): A latent-variable generative model used to encode images into a continuous latent space. "incorporates a VAE~\citep{vae} into the diffusion pipeline to operate within a lower-dimensional latent space"
- VFM (Visual Foundation Model): Large-scale pretrained vision models providing transferable representations for perception and generation. "Visual generation grounded in Visual Foundation Model (VFM) representations offers a highly promising unified pathway"
- ViT (Vision Transformer): A transformer-based architecture for images using patch tokenization. "built on a Vision Transformer~\citep{vit}, is designed to compensate for high-frequency details and color cast artifacts"
Collections
Sign up for free to add this paper to one or more collections.