The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery
Abstract: One of the grand challenges of artificial general intelligence is developing agents capable of conducting scientific research and discovering new knowledge. While frontier models have already been used as aides to human scientists, e.g. for brainstorming ideas, writing code, or prediction tasks, they still conduct only a small part of the scientific process. This paper presents the first comprehensive framework for fully automatic scientific discovery, enabling frontier LLMs to perform research independently and communicate their findings. We introduce The AI Scientist, which generates novel research ideas, writes code, executes experiments, visualizes results, describes its findings by writing a full scientific paper, and then runs a simulated review process for evaluation. In principle, this process can be repeated to iteratively develop ideas in an open-ended fashion, acting like the human scientific community. We demonstrate its versatility by applying it to three distinct subfields of machine learning: diffusion modeling, transformer-based language modeling, and learning dynamics. Each idea is implemented and developed into a full paper at a cost of less than $15 per paper. To evaluate the generated papers, we design and validate an automated reviewer, which we show achieves near-human performance in evaluating paper scores. The AI Scientist can produce papers that exceed the acceptance threshold at a top machine learning conference as judged by our automated reviewer. This approach signifies the beginning of a new era in scientific discovery in machine learning: bringing the transformative benefits of AI agents to the entire research process of AI itself, and taking us closer to a world where endless affordable creativity and innovation can be unleashed on the world's most challenging problems. Our code is open-sourced at https://github.com/SakanaAI/AI-Scientist


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces “The AI Scientist,” a system that uses advanced AI to carry out the entire scientific research process on its own. Instead of just helping humans with parts of research (like writing code or summarizing papers), this AI can:
- come up with new research ideas,
- write and run experiments,
- analyze and plot results,
- write a full scientific paper,
- and even “review” the paper using another AI reviewer.
The goal is to make scientific discovery faster, cheaper, and more open-ended, so AI can keep learning and improving its ideas over time—much like a real scientific community.
What questions did the researchers ask?
The paper explores three simple questions in an easy-to-understand way:
- Can an AI do the full cycle of scientific research by itself, from idea to paper?
- Will the AI’s papers be good enough to meet common standards in machine learning research?
- Can AI reviewing be accurate and fair enough to judge the AI’s own papers?
How did they do it?
To make the AI act like a scientist, the team built a step-by-step workflow. Think of it like a smart robot scientist following a recipe:
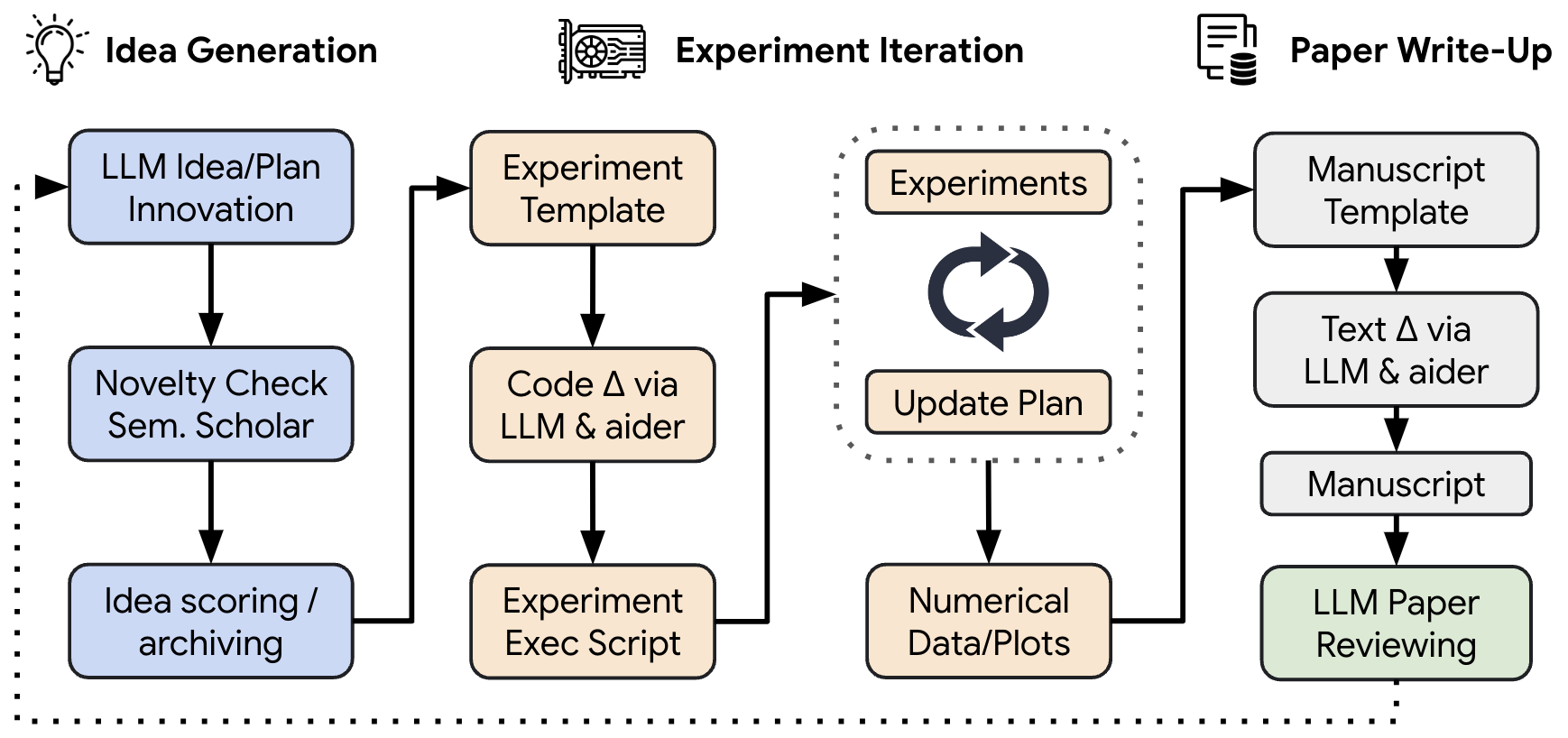
The AI Scientist’s workflow
- Idea generation: The AI brainstorms many research ideas. It uses “chain-of-thought” (writing out its thinking steps) and “self-reflection” (checking and improving its own ideas). It also searches online (via the Semantic Scholar API) to avoid repeating existing work.
- Experiment iteration: The AI uses a coding assistant called Aider to edit a small, starter code project, run experiments, fix errors, and repeat. After each experiment, it takes notes like a lab journal and plans the next test.
- Paper write-up: The AI writes a full scientific paper in LaTeX (the format scientists use), adds real figures and tables from its experiments, and cites related work it found online. It compiles the paper and fixes formatting issues automatically.
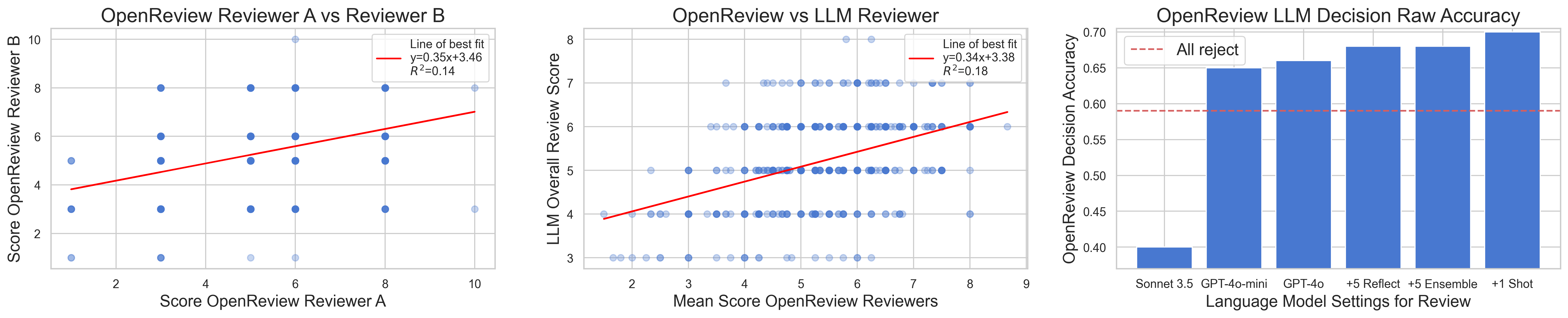
- Automated reviewing: A separate AI reviewer (based on GPT-4o) reads the paper PDF and gives scores similar to real conference reviews (e.g., “soundness,” “contribution,” and overall decision). It uses guidelines like those from the NeurIPS conference and improves its decisions with techniques like self-reflection, few-shot examples, and ensembling (combining multiple review attempts).
What tools and terms mean in everyday language
- LLM: An AI that predicts the next word in a sentence very well, making it great at writing, explaining, and coding.
- Chain-of-thought: The AI “shows its work,” writing down its reasoning steps before giving an answer.
- Self-reflection: The AI re-reads its own output and asks, “Can I make this better?”
- Aider: A tool that helps the AI edit programs in real code projects, fix bugs, and add features.
- Diffusion model: A generative model that creates new data (like images or points) by starting with noise and gradually “denoising” it into something meaningful—like sharpening a blurry picture.
What did they find?
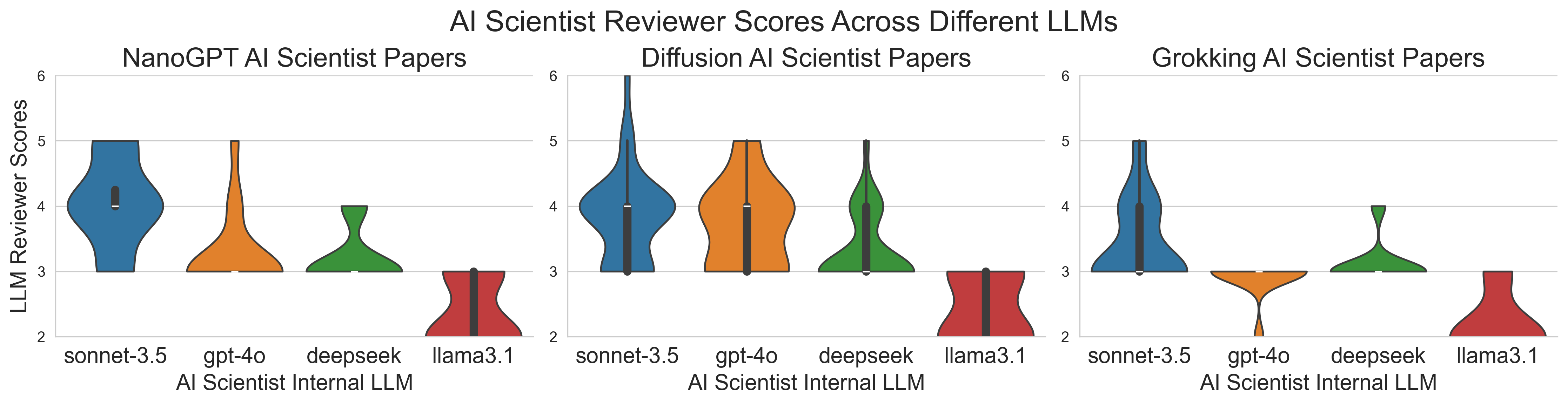
The team applied The AI Scientist to three areas of machine learning:
- Diffusion modeling (for generating data),
- Transformer-based language modeling (like small text generators),
- Learning dynamics (including “grokking,” a phenomenon where models suddenly start generalizing well after a long time).
Here are the key results, explained simply:
- Full papers, end-to-end: The AI created complete research papers with experiments, figures, and references—without human intervention. Many ideas were novel according to the AI’s own search checks.
- Low cost: Each paper cost under about $15 in API usage, making research much more affordable.
- Scale: The AI can generate hundreds of “medium-quality” papers in about a week.
- Automated reviewing was solid: The AI reviewer reached near-human performance when judging real papers (from ICLR 2022), with balanced accuracy around 65% (humans in a similar setup were ~66%). Reviews cost roughly $0.25–$0.50 each.
- Some AI-generated papers would pass: According to the AI reviewer’s thresholds, some of the AI’s papers exceeded the acceptance bar for a top conference.
- A case study showed real creativity and useful results: One paper proposed “Adaptive Dual-Scale Denoising,” where the diffusion model uses two branches—one focusing on global structure and one on local details—and learns how to mix them over time. It achieved better sample quality on simple 2D datasets and created insightful new plots. However, the paper also had some typical mistakes, like guessing the wrong hardware and putting a positive spin on a negative result—reminding us the AI still needs oversight.
Why are these results important?
- Speed and affordability: If an AI can handle many steps of research quickly and cheaply, scientists can explore more ideas faster. This lowers the barrier for students, small labs, and researchers in places with fewer resources.
- Open-ended discovery: Because the AI stores its ideas, papers, and reviews, it can build on what it learned and keep improving—like a growing scientific team.
- Better reviewing support: AI reviewing could help catch issues, provide consistent feedback, and reduce workload for human reviewers while staying close to human-level accuracy.
What are the implications and potential impact?
- Democratizing research: Low-cost, automated papers could let more people participate in science and test ideas, even with limited funding.
- Faster progress in AI and beyond: While this paper focuses on machine learning, the same framework could be adapted to fields that have robotic labs or cloud-based experiment platforms, like biology, chemistry, or materials science.
- Human-AI teamwork: The AI is about as capable as an early-stage researcher who can run solid experiments but doesn’t always interpret results perfectly. Humans can guide it, validate claims, and steer it toward deeper insights.
- Responsible use and limits: The current system sometimes makes mistakes (like subtle code bugs, optimistic phrasing, or limited references). The reviewer AI has its own biases too (it was more likely to incorrectly accept some weak papers). Careful human oversight, better tools, and future multi-modal models (that “see” figures and data) can reduce these issues.
- Long-term questions: As AI gets smarter, evaluating its ideas may become harder. This points to “superalignment”—making sure we can safely supervise and trust very capable AI systems.
In short, this paper shows the first complete, practical path to AI-driven scientific discovery. It’s not perfect yet, but it’s a big step toward a future where AI helps unlock new knowledge quickly, cheaply, and at scale—and where human scientists set goals, provide judgment, and ensure quality. The authors have open-sourced the code, making it easier for others to build on this work.
Collections
Sign up for free to add this paper to one or more collections.

