Evaluating Large Language Models in Scientific Discovery (2512.15567v1)
Abstract: LLMs are increasingly applied to scientific research, yet prevailing science benchmarks probe decontextualized knowledge and overlook the iterative reasoning, hypothesis generation, and observation interpretation that drive scientific discovery. We introduce a scenario-grounded benchmark that evaluates LLMs across biology, chemistry, materials, and physics, where domain experts define research projects of genuine interest and decompose them into modular research scenarios from which vetted questions are sampled. The framework assesses models at two levels: (i) question-level accuracy on scenario-tied items and (ii) project-level performance, where models must propose testable hypotheses, design simulations or experiments, and interpret results. Applying this two-phase scientific discovery evaluation (SDE) framework to state-of-the-art LLMs reveals a consistent performance gap relative to general science benchmarks, diminishing return of scaling up model sizes and reasoning, and systematic weaknesses shared across top-tier models from different providers. Large performance variation in research scenarios leads to changing choices of the best performing model on scientific discovery projects evaluated, suggesting all current LLMs are distant to general scientific "superintelligence". Nevertheless, LLMs already demonstrate promise in a great variety of scientific discovery projects, including cases where constituent scenario scores are low, highlighting the role of guided exploration and serendipity in discovery. This SDE framework offers a reproducible benchmark for discovery-relevant evaluation of LLMs and charts practical paths to advance their development toward scientific discovery.
Sponsor



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
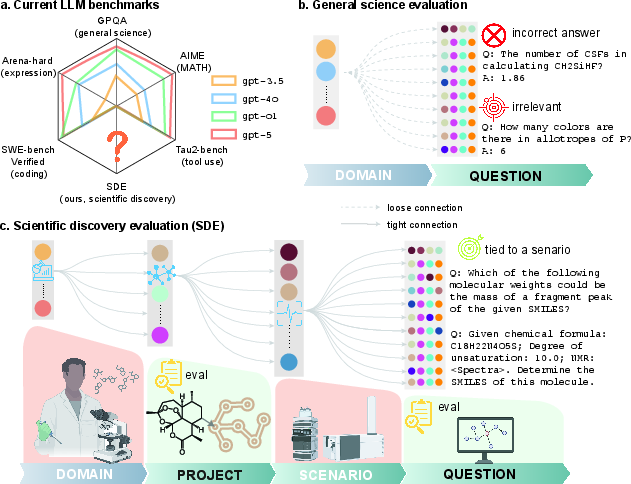
This paper looks at how well “LLMs” (LLMs)—very smart chatbots like GPT, Claude, Grok, and DeepSeek—can actually help scientists make new discoveries. Instead of just testing them on random science quiz questions, the authors built a new way to test LLMs on real research tasks from biology, chemistry, materials science, and physics. They call this the Scientific Discovery Evaluation (SDE).
Key Questions the Paper Asks
- Can LLMs do more than answer science trivia? Can they handle the actual steps of discovery—like forming hypotheses, running tests, and learning from results?
- How do LLMs perform on realistic, context-rich science tasks compared to standard benchmarks (like math or general science quizzes)?
- Does “reasoning mode” (letting the model think step-by-step) or just making the model bigger always improve scientific discovery?
- Do different top models fail in the same ways?
- How do scores on small tasks (“scenarios”) connect to performance on full research projects?
How the Authors Tested the Models
They created a two-part evaluation that resembles the way scientists work in real life:
1) Scenario-Level (Question-Level) Tests
Think of “scenarios” as mini real-world tasks scientists face, like:
- Predicting what happens in a chemical reaction
- Reading lab data (like NMR or X-ray patterns) to figure out a molecule or crystal structure
- Judging if a drug candidate is likely to work in the body
- Estimating properties of materials (like battery electrolytes or metal complexes)
For each scenario, experts wrote or curated sets of questions (1,125 in total across 43 scenarios). These questions are tied directly to real research projects, not random trivia.
2) Project-Level (End-to-End) Tests
This mimics the “science fair project loop,” but at research level:
- The model proposes a testable hypothesis (an idea it wants to check)
- It designs or runs a simulation or experiment (using tools or code)
- It looks at the results and updates its hypothesis
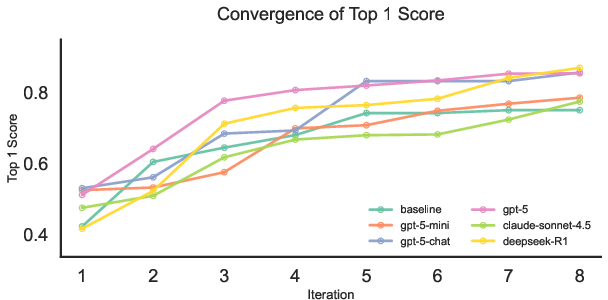
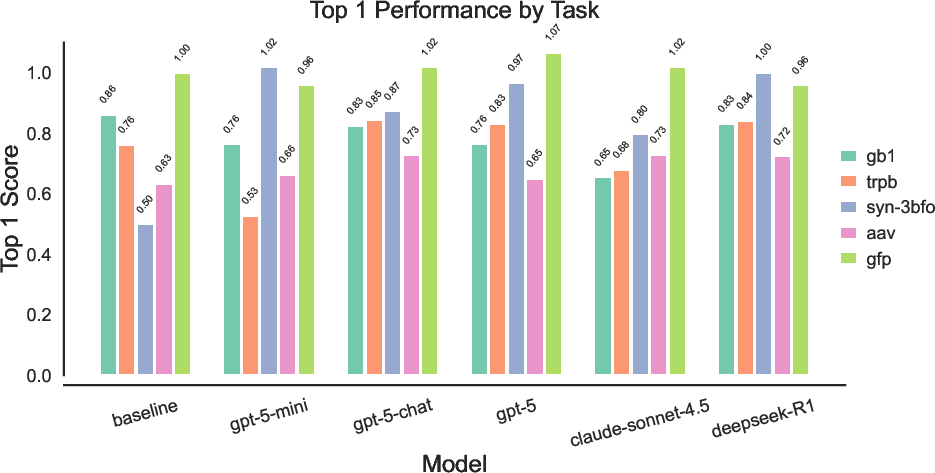
They built a framework called “sde-harness” to run this loop across eight actual projects (e.g., optimizing special metal complexes, designing proteins, discovering equations for complex systems, and building new crystals). The model’s goal is to improve results over several rounds—like getting better at finding high-performing materials by learning from previous tries.
To keep it simple:
- Scenarios are the building blocks (small tasks)
- Projects are full builds (multi-step research challenges)
Main Findings
1) Real Research Tasks Are Harder Than Science Quizzes
- Top models score high on general benchmarks (like GPQA or MMMU) but noticeably lower on SDE’s scenario questions.
- Why? The SDE questions are grounded in real projects and require context, careful thinking, and interpreting imperfect evidence—just like real science.
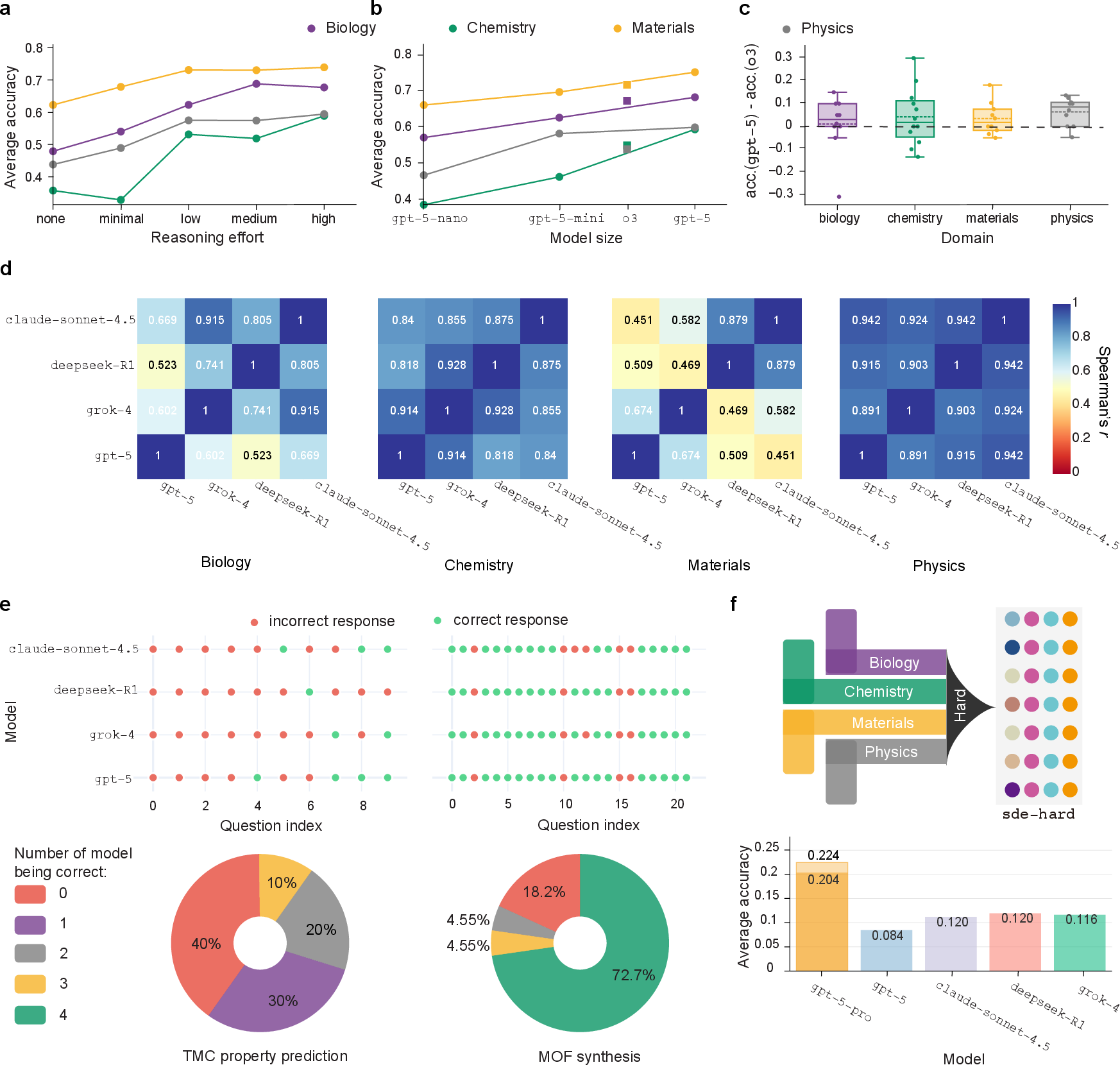
2) Reasoning Helps—but Hits Limits
- Models that “think step-by-step” (like DeepSeek-R1) usually beat similar models without reasoning.
- However, simply turning up “reasoning” or making models bigger doesn’t keep giving big gains. Improvements start to flatten out on these discovery tasks.
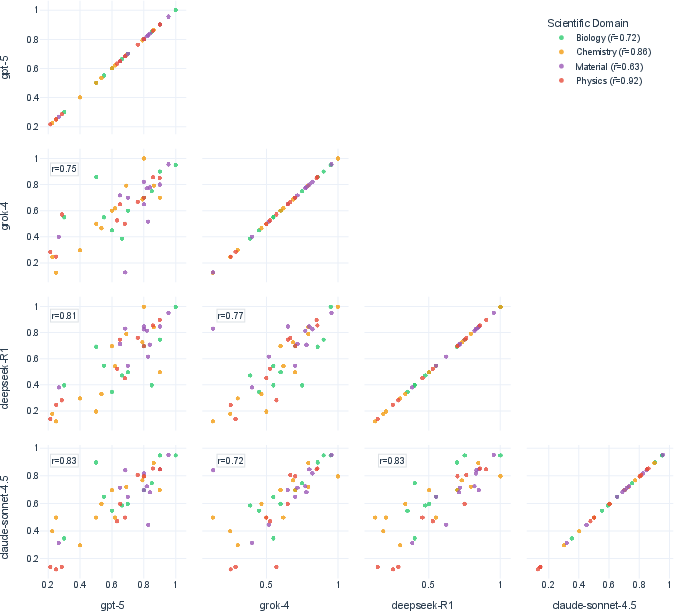
3) Different Models Often Fail the Same Way
- Top models from different companies often make mistakes on the exact same hardest questions.
- This suggests they learned similar patterns from similar data, and share the same weaknesses.
4) A “Hard Mode” Shows Big Gaps
- The authors created SDE-hard: 86 of the toughest questions.
- All models scored very low, though a “pro” version of GPT did notably better on some especially tough items.
- There’s still a long way to go before LLMs become “superintelligent scientists.”
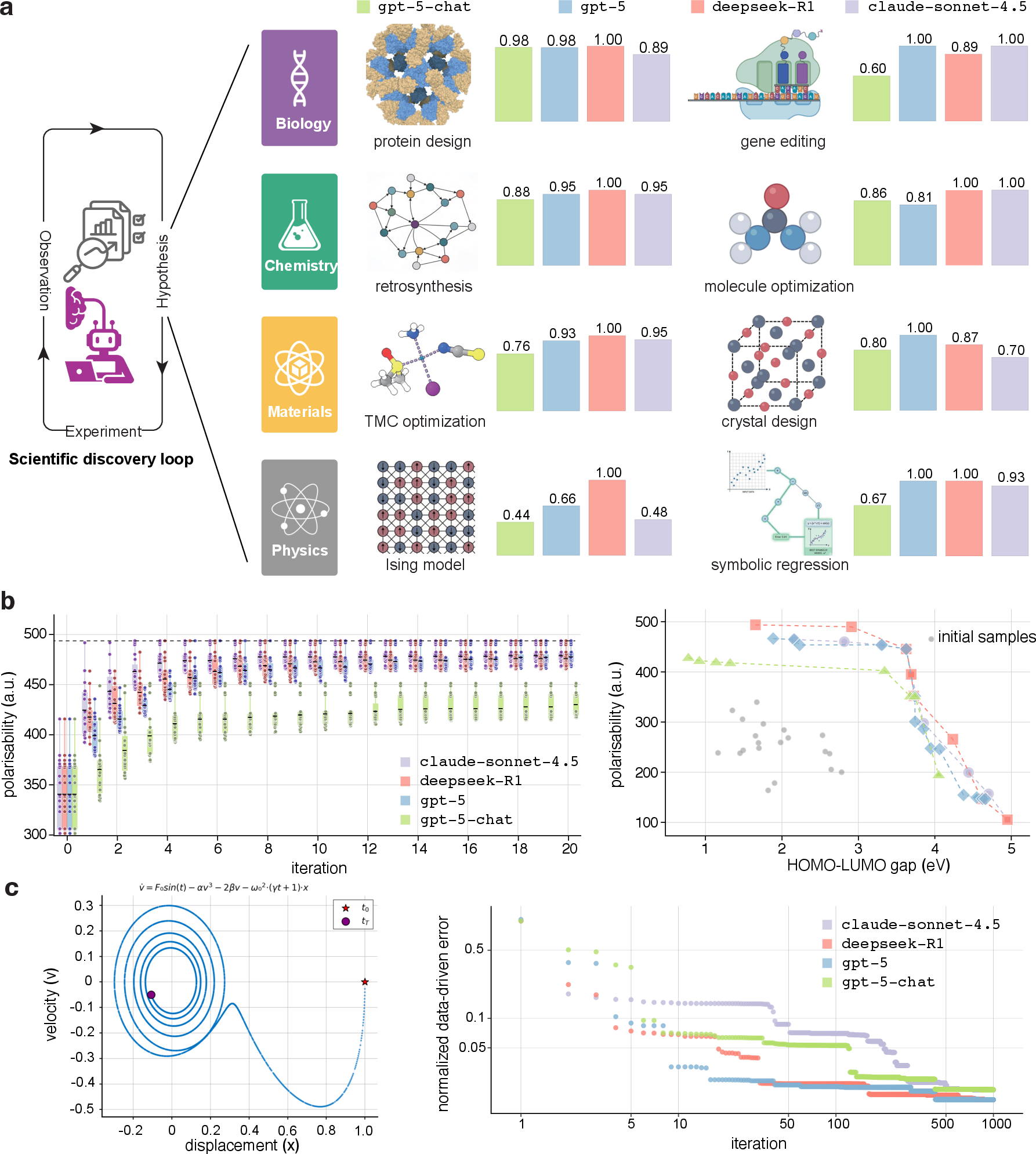
5) Project Results: Serendipity Matters
- In some projects, models did surprisingly well even if they didn’t score great on related scenarios.
- For example, multiple models quickly found metal complexes with very high polarizability from a huge search space, exploring trade-offs effectively.
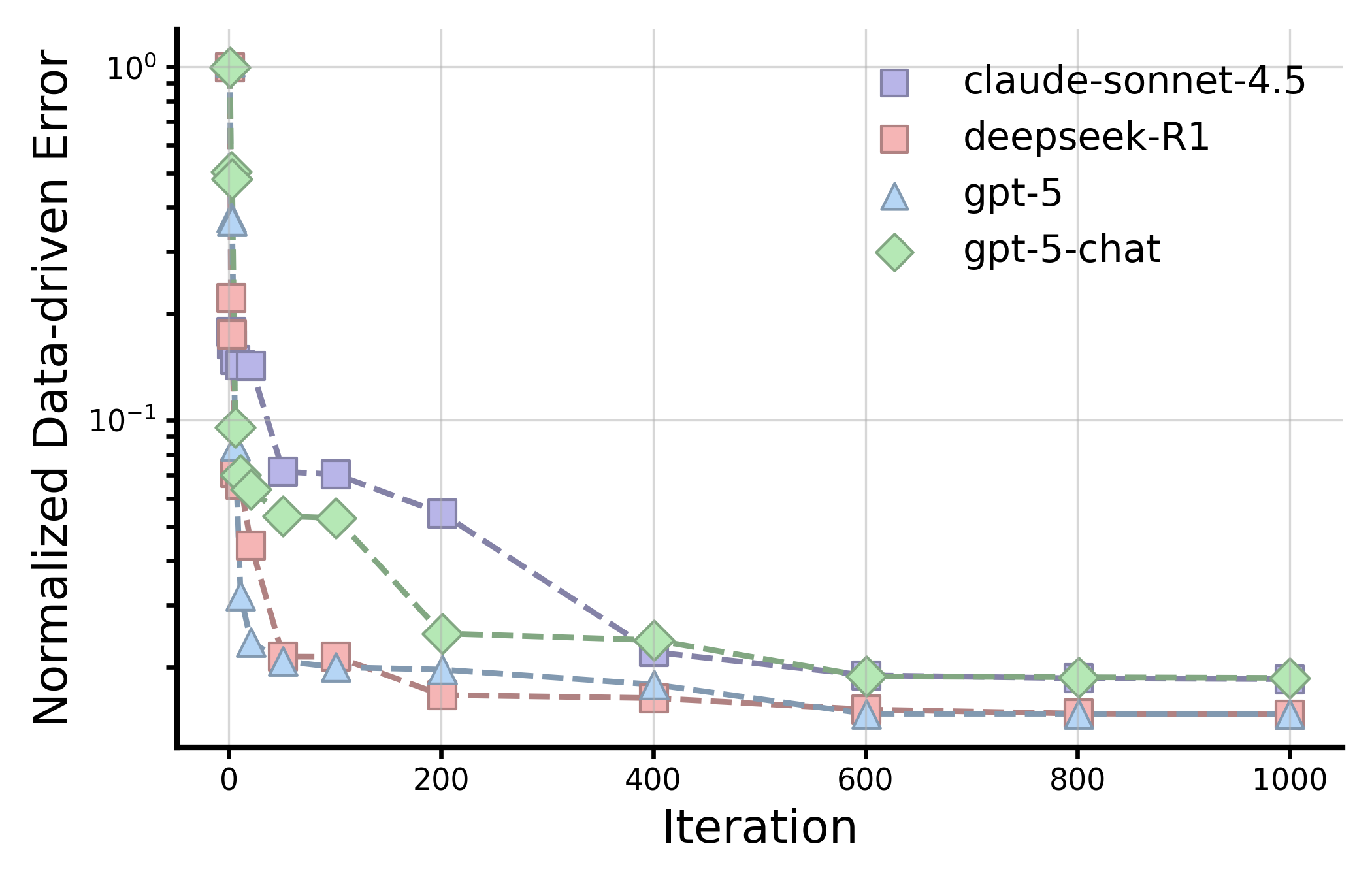
- In symbolic regression (finding equations from data), models with reasoning improved faster and reached lower errors, showing strong “discover-and-refine” behavior.
- But models struggled with long, strict plans like multi-step chemical synthesis (retrosynthesis), often failing validity checks, and not always beating traditional tools.
6) No One Model Wins Everything
- Performance varies by project. One model might shine in materials, another in physics or chemistry.
- Overall, all current LLMs are far from a one-size-fits-all “scientific superintelligence.”
Why This Matters
- Real scientific discovery isn’t just answering facts; it’s about forming ideas, testing them, and learning from messy results. This new benchmark (SDE) tests exactly that.
- The findings show that:
- Models need training that focuses on scientific thinking (problem setup, hypothesis refinement), not just bigger models or longer “reasoning chains.”
- Better data and new training strategies are needed—especially ones that teach models to use tools (simulators, code, lab planners) and fix execution errors.
- Future improvements should target the actual loop of discovery: propose, test, interpret, and iterate.
Final Takeaway
LLMs are starting to help in real science—sometimes even finding good solutions quickly in large search spaces. But they still struggle with complex planning, strict validity checks, and truly hard questions tied to real research. The SDE framework gives scientists and developers a clearer, more honest way to measure progress and figure out what to improve next, nudging AI toward being a reliable partner in scientific discovery.
Knowledge Gaps
Below is a concise, action-oriented list of knowledge gaps, limitations, and open questions the paper leaves unresolved. Each point is intended to inform concrete follow-up studies or benchmark extensions.
- Domain coverage is incomplete: earth sciences, engineering, and social sciences are absent; how well does SDE generalize to these fields and cross-disciplinary problems (e.g., climate–materials, bio–policy)?
- Scenario selection bias: scenarios reflect contributors’ interests and practices; develop protocols for broader community sourcing, inter-rater agreement, and periodic rebalancing to ensure representativeness.
- Limited item counts per scenario (often ≥5 but still small) inflate variance; conduct power analyses, expand item pools, and report confidence intervals/bootstraps to quantify uncertainty.
- Possible pretraining contamination of templated or public-dataset-derived questions was not audited; implement overlap checks, provenance tracing, and contamination-adjusted baselines.
- API non-determinism and A/B testing hinder reproducibility; standardize with local open-weight baselines, fixed seeds, frozen tool/oracle versions, and published inference logs.
- Model coverage is narrow at project level (cost-limited) and focuses on a few frontier models; broaden to diverse open/closed models, ablate temperature/decoding settings, and report cost–accuracy trade-offs.
- Single optimization strategy and prompting protocol in project evaluations; compare Bayesian optimization, MCTS, bandits, active learning, and agentic frameworks with ablations over selection rules and iteration budgets.
- Tool-use capability is not directly benchmarked; add scenarios/projects that require planning, calling, and debugging domain tools (e.g., RDKit, VASP, LAMMPS), with metrics for execution success, recovery, and throughput.
- Question-to-project transfer is only qualitatively assessed; build predictive models that map scenario competencies to project success, and run controlled interventions to identify causal bottlenecks.
- Diminishing returns from scaling and test-time reasoning are observed but not explained; run controlled training studies (scientific RLHF/RLAIF, tool-integrated SFT, curricula on hypothesis formation) to quantify gains.
- Shared failure modes across providers are documented but not dissected; test whether diversifying pretraining corpora, objectives, or inductive biases reduces cross-model error correlation on SDE-hard.
- SDE-hard is small (86 items) and sensitive to “no response” handling; expand with more balanced, multi-domain, adversarially constructed items and define standardized abstention/calibration scoring.
- Evaluation metrics emphasize exact match/accuracy; add partial credit, rationale grading, calibration (ECE/Brier), abstention rewards, and uncertainty-aware scoring to better capture scientific decision quality.
- Multi-modality is limited; incorporate raw instrument/sensor modalities (e.g., NMR/IR/MS spectra, microscopy, PXRD images, time-series traces) instead of only textual/templated representations.
- Long-horizon planning and memory are not stress-tested; add projects requiring multi-stage plans, plan repair, persistent memory, and stateful tool invocation over tens to hundreds of steps.
- Safety and misuse risks (especially in biology) are acknowledged but not evaluated; integrate safety gates, red-team tasks, jailbreak resistance, and safe-abstention metrics into SDE and sde-harness.
- Real-world lab integration is missing; validate end-to-end closed-loop performance with autonomous labs, measuring experimental yield, time/cost, error handling, and physical constraints.
- Human-in-the-loop benefits are not quantified; run controlled user studies comparing human-alone, LLM-alone, and human+LLM conditions across projects and report net productivity/quality gains.
- Novelty and impact of discoveries are not measured; add bibliometric/novelty metrics (e.g., distance from literature), expert panel ratings, and downstream validation (e.g., simulation-to-experiment success).
- Interpretability and mechanistic understanding are unevaluated; score reasoning chains, mechanistic consistency, and causal hypothesis quality beyond final answers.
- Robustness and OOD generalization are lightly probed; systematically introduce domain shifts, noisy/contradictory evidence, and imperfect oracles to assess resilience and error recovery.
- Prompt sensitivity and protocol drift are underexplored; perform prompt ablations, instruction-tuning sensitivity analyses, and standardize prompt/version registries for comparability.
- Cost and sample efficiency are not benchmarked; report tokens-per-gain, optimizer evaluations-per-gain, and compare against classical baselines (e.g., BO) on efficiency fronts.
- Dataset and oracle versioning is not fully specified; provide immutable releases with checksums, semantic versioning, and change logs for questions, scenarios, oracles, and harness code.
- Cross-lingual performance is unassessed; build parallel scenario/question sets in other languages and measure transfer, bias, and accessibility.
These gaps define a concrete roadmap for expanding SDE’s scope, improving methodological rigor, and isolating which training, data, and tool-use interventions most effectively advance LLMs for real scientific discovery.
Glossary
- Artemisinin: An antimalarial natural product used as a target in synthesis planning and pathway discovery. Example: "A project of discovering new pathways for artemisinin synthesis is shown as an example"
- CRISPR: A genome-editing technology that enables targeted modification of DNA sequences. Example: "CRISPR delivery strategy (20)"
- Evolutionary algorithm baseline: A heuristic optimization baseline that evolves candidate solutions via selection, mutation, and recombination. Example: "evolutionary algorithm baseline"
- Forward reaction prediction: Predicting the products of a chemical reaction given the reactants and conditions. Example: "forward reaction prediction (42)"
- GWAS (Genome-Wide Association Study): A statistical approach to identify genetic variants associated with traits or diseases. Example: "GWAS causal gene identification (20)"
- HOMO-LUMO gap: The energy difference between the Highest Occupied and Lowest Unoccupied Molecular Orbitals, relating to electronic and optical properties. Example: "the Pareto frontier defined by polarisability and the HOMO-LUMO gap"
- IR-based structure elucidation: Determining molecular structure using infrared spectroscopy signals. Example: "IR-based structure elucidation (5)"
- Ising model: A mathematical model of interacting spins used in statistical physics and optimization. Example: "all-to-all Ising model"
- LAMMPS: A molecular dynamics simulation package for materials modeling. Example: "LAMMPS/VASP computational workflows (33)"
- Lattice parameter: A constant that defines the unit cell dimensions of a crystal. Example: "lattice parameter prediction (60)"
- Lipinski's rule of five: A heuristic for assessing drug-likeness based on molecular properties. Example: "judge whether an organic molecule satisfies Lipinski's rule of five"
- Mass-to-formula conversion: Inferring a molecular formula from mass spectrometric data. Example: "mass-to-formula conversion (15)"
- Matched molecular pair analysis: Comparing pairs of molecules differing by a small, defined change to analyze property shifts. Example: "matched molecular pair analysis (20)"
- MOF (Metal–Organic Framework): Porous crystalline materials composed of metal nodes and organic linkers. Example: "MOF water stability (20) and synthesis (22)"
- MS (mass spectrometry): An analytical technique measuring mass-to-charge ratios of ions. Example: "MS peak identification (10)"
- NMR (nuclear magnetic resonance): A spectroscopic technique for elucidating molecular structure using nuclear spin properties. Example: "nuclear magnetic resonance (NMR) spectra"
- NMSE (Normalized Mean Squared Error): An error metric normalized by signal magnitude for model accuracy. Example: "significantly higher NMSE"
- OOD (out-of-distribution): Data or conditions that differ from those seen during training, challenging model generalization. Example: "OOD regime"
- Oxidation state: The formal charge of an atom in a compound, indicating its electron loss or gain. Example: "inferring oxidation and spin states solely from a transition metal complex structure"
- Pareto frontier: The set of non-dominated solutions in multi-objective optimization where improving one objective worsens another. Example: "Pareto frontier defined by polarisability and the HOMO-LUMO gap"
- Pearson's r: A measure of linear correlation between two variables. Example: "Spearmanâs r and Pearson's r"
- Phase-space trajectories: Paths tracing a system’s states (positions and momenta or generalized coordinates) over time. Example: "Representative example of phase-space trajectories"
- Polarisability: The ease with which a molecule’s electron cloud is distorted by an electric field. Example: "maximized polarisability"
- PXRD (powder X-ray diffraction): A technique to determine crystal structures from diffraction patterns of powdered samples. Example: "PXRD crystal system determination (60)"
- PySR: A symbolic regression library for discovering analytic expressions from data. Example: "By comparison with PySR~\cite{cranmer2023interpretable}"
- RDKit: An open-source cheminformatics toolkit for molecule representation and property computation. Example: "RDKit\cite{Landrum2025RDKit}"
- Redox potential: A measure of a species’ tendency to gain or lose electrons. Example: "redox potential estimation (8)"
- Retrosynthesis: Planning an overview by iteratively deconstructing a target molecule into simpler precursors. Example: "retrosynthesis (48)"
- SE(3)-equivariant architecture: A model architecture whose outputs transform consistently under 3D rotations and translations. Example: "lack of intrinsic SE(3)-equivariant architecture"
- SMILES: A textual notation for representing molecular structures in a linear string format. Example: "SMILES and gene manipulation"
- Spearman’s r: A rank-based correlation coefficient measuring monotonic association. Example: "Spearmanâs r and Pearson's r"
- Spin state: The total spin configuration (e.g., high-spin, low-spin) of electrons in a molecule or complex. Example: "inferring oxidation and spin states solely from a transition metal complex structure"
- Structure–property prediction: Predicting material or molecular properties directly from structural information. Example: "structure-property prediction"
- Symbolic regression: Automatically discovering explicit mathematical expressions that fit data. Example: "state-of-the-art baseline for symbolic regression"
- TMC (transition metal complex): A compound consisting of a transition metal center bonded to surrounding ligands. Example: "TMC optimization"
- VASP: A plane-wave DFT software for electronic structure calculations of materials. Example: "LAMMPS/VASP computational workflows (33)"
Practical Applications
Immediate Applications
Below are concrete applications that can be deployed now, drawing directly from the paper’s methods (scenario-grounded SDE, project-level sde-harness), empirical findings (performance gaps, shared failure modes, reasoning gains with diminishing returns), and domain instantiations (symbolic regression, TMC optimization, PXRD, MOF synthesis).
- [Industry | Academia | Government Labs] Scenario-grounded model selection and procurement
- Use the SDE scenario matrix to choose the best model for a specific research workflow (e.g., DeepSeek-R1 for reasoning-heavy symbolic regression and TMC Pareto exploration; GPT-5 for PXRD lattice/system predictions; Claude-sonnet-4.5 for fast convergence to top TMC polarizability).
- Tools/workflows: SDE benchmark, sde-harness, lm-evaluation-harness, organization-specific “scenario catalogs” that mirror internal R&D tasks.
- Dependencies/assumptions: Access to model APIs or open weights; stable inference settings; internal mapping from SDE scenarios to team workflows; budget constraints for high-cost inference (e.g., “-pro” tiers).
- [Materials | Pharma/Biotech] LLM-assisted hypothesis generation and iterative optimization “co-pilot”
- Deploy LLMs to suggest candidate hypotheses and refine them using in-house or public simulators/oracles (e.g., maximize TMC polarizability; symbolic regression for system identification; prioritize compounds with drug-likeness filters).
- Tools/workflows: sde-harness loop (hypothesis–simulation–interpretation), RDKit, PySR, domain simulators (DFT/MD pipelines, property calculators).
- Dependencies/assumptions: Well-specified objective functions; reliable oracles approximating lab outcomes; human-in-the-loop oversight to prevent spurious optima.
- [Software | Lab Automation | MLOps] Continuous evaluation for research LLMs (Discovery MLOps)
- Integrate SDE scenarios into CI/CD to gate model updates, track regression in scenario-specific performance, and trigger targeted retraining for failing scenarios.
- Tools/workflows: SDE harness integrated with experiment tracking dashboards; per-scenario scorecards; model registries with “Discovery Readiness” tags.
- Dependencies/assumptions: Internal DevOps support; reproducible scoring (prefer open-weight baselines for stability); alignment between scenario KPIs and business KPIs.
- [Chemistry | Materials | Bioinformatics] Tool-augmented LLM execution
- Couple LLMs to domain tools for code synthesis and execution (e.g., generate/validate LAMMPS or VASP input decks; RDKit pipelines for property filtering; PXRD analysis steps; MOF stability heuristics).
- Tools/workflows: Function/tool calling; adapters to RDKit, LAMMPS, VASP; validators; structured outputs (JSON) and automatic failure recovery.
- Dependencies/assumptions: Sandboxed compute; correct installation/licensing; robust I/O validation; logging for traceability.
- [Academia | Education] Teaching and assessment of scientific reasoning
- Use SDE scenarios (and SDE-hard) in coursework to assess iterative reasoning, hypothesis refinement, and evidence interpretation; stage projects where students run sde-harness loops with safe or simulated oracles.
- Tools/workflows: Course packs built on SDE; safe physics/materials simulators; instructor dashboards showing per-scenario strengths/weaknesses.
- Dependencies/assumptions: Access to benchmark items and simulators; guardrails for bio content; institutional policies for AI use.
- [Policy | Compliance | Biosecurity] Risk gating and safe-use protocols
- Adopt SDE-hard and bio-relevant scenarios as access gates for high-reasoning models; require tool-use guardrails, watermarking, logging, and human approval for sensitive domains (e.g., experimental biology).
- Tools/workflows: Governance playbooks; model cards reporting SDE/SDE-hard results; audit logs; jailbreak monitoring.
- Dependencies/assumptions: Organizational buy-in; legal/privacy frameworks; evolving national biosecurity guidance.
- [Publishing | Funding] Evidence standards for “AI-for-Science” claims
- Require SDE-style, scenario-tied evaluation in methods sections and grant proposals to substantiate discovery claims (beyond generic QA scores).
- Tools/workflows: Submission checklists referencing SDE items and sde-harness outcomes; reviewer templates for scenario relevance.
- Dependencies/assumptions: Community acceptance; availability of open-weight baselines for reproducibility.
- [R&D Management | Portfolio Strategy] Model/approach diversification strategy
- Use the paper’s finding that naive cross-provider ensembling offers limited gains on hard scenarios to justify targeted diversification (different pretraining corpora, tool-use specializations) rather than majority voting.
- Tools/workflows: Scenario-specific A/B tests; diversification scorecards (data, tools, objectives).
- Dependencies/assumptions: Access to diverse models; capacity to run structured ablations.
- [Citizen Science | Informal Learning] Safe-domain discovery coaching
- Deploy LLM-driven hypothesis–test–interpret loops for safe domains (e.g., physics simulations, astronomy datasets), guiding hobbyists and learners through “mini SDE” projects.
- Tools/workflows: PhET-like simulators + LLM tutors; curated public datasets; constraints against biological/chemical synthesis.
- Dependencies/assumptions: Clear safety boundaries; content filtration; explainable feedback.
Long-Term Applications
These opportunities require further research, scaling, standardization, or infrastructure beyond current readiness, building on the paper’s framework (SDE, sde-harness), results (diminishing returns from generic reasoning, shared failure modes), and proposed development directions (tool-use training, RL for scientific reasoning, diversified pretraining).
- [Materials | Pharma | Robotics] Autonomous closed-loop discovery labs
- End-to-end agents that formulate hypotheses, design experiments, control robots, integrate simulations, and adapt based on observations—ground-truthed using sde-harness-like loops.
- Tools/workflows: Robotic platforms; ELN/LIMS integration; multi-modal tool-use (vision, spectra); safety interlocks and audit trails.
- Dependencies/assumptions: Reliable lab automation; robust failure recovery; certification; significant capex/ops budgets; strong biosecurity controls.
- [Standards | Procurement | Regulation] SDE-based certification and policy frameworks
- Establish “Discovery Readiness Scores” with domain/Scenario labels; create ISO-like standards for evaluation, reporting, and safe deployment (esp. in bio).
- Tools/workflows: Public leaderboards; certified test suites (including SDE-hard); procurement templates for agencies and enterprises.
- Dependencies/assumptions: Multi-stakeholder governance; sustained benchmark curation; legal harmonization across jurisdictions.
- [Model Training | Foundation Models] RL for scientific reasoning and tool-centric finetuning
- Develop reinforcement learning objectives that reward correct problem formulation, tool invocation, debugging, and iterative hypothesis refinement; train with mixed textual + executable trajectories.
- Tools/workflows: Trajectory datasets from sde-harness; program-of-thought traces; sandboxed tool-calling during training.
- Dependencies/assumptions: Scalable and safe data collection; computationally heavy training; reliable evaluation oracles; IP/licensing for tools and data.
- [Data | Benchmarks] Scenario marketplaces and extensible SDE ecosystems
- A living repository where labs/companies contribute reusable scenarios, oracles, and evaluation scripts in new domains (e.g., earth sciences, engineering), enabling cross-institution comparability.
- Tools/workflows: Versioned scenario registry; data governance; contributor incentives; testbed compute sharing.
- Dependencies/assumptions: Community maintenance; curation quality; standard schemas for prompts, tools, and metrics.
- [Enterprise R&D | Finance] Discovery trajectory forecasting and portfolio optimization
- Use scenario-grounded performance and early iteration curves (from sde-harness) to forecast discovery timelines, expected ROI, and risk for competing R&D bets; allocate resources accordingly.
- Tools/workflows: Bayesian/ML forecasting using iteration-by-iteration metrics; cost–benefit models incorporating model inference costs.
- Dependencies/assumptions: Historical traces linking SDE-like metrics to real outcomes; access to sensitive R&D data; uncertainty quantification.
- [Pharma/Biotech] AI-first design-to-synthesis pipelines with validity-aware planning
- Combine strong knowledge in reaction prediction with robust long-horizon planning that satisfies strict chemical validity checks, surpassing current LLM retrosynthesis performance.
- Tools/workflows: Hybrid planners (LLM + specialized synthesis planners + graph search); structured reaction representation; synthesis-executability scoring.
- Dependencies/assumptions: High-quality reaction corpora; integration with lab ELNs and procurement; robust error handling for invalid steps.
- [Education | Workforce Development] Accreditation and adaptive training for discovery reasoning
- National/international programs that certify competencies in iterative scientific reasoning, tool-augmented workflows, and safe AI use in laboratories.
- Tools/workflows: SDE-derived assessments; simulator-backed practicals; lifelong learning modules.
- Dependencies/assumptions: Institutional alignment; fair-use of benchmarks; accessibility.
- [Security | Safety] Graded access controls and auditing for high-capability models
- Risk-tiered deployment (especially in biology) with formalized access policies tied to SDE-hard performance, real-time monitoring, red-teaming, and immutable logs.
- Tools/workflows: Policy engines; anomaly detection; watermarking; periodic audits against evolving SDE-hard suites.
- Dependencies/assumptions: Legal frameworks; privacy/security infrastructure; periodic update of hard tasks to prevent overfitting.
- [Cross-Domain Platforms] “Co-Scientist OS” for orchestration
- A unified platform that handles problem scoping, tool selection, hypothesis evolution, error analysis, and reporting across domains, built around sde-harness principles.
- Tools/workflows: Orchestration layer integrating LIMS/ELN, simulators, cloud/HPC; explainability dashboards; compliance hooks.
- Dependencies/assumptions: Vendor interoperability; strong data lineage; sustained integration engineering.
- [Frontier Research] Architectures with new inductive biases and diversified pretraining
- Reduce shared failure modes via diversified corpora (e.g., instrument logs, protocols, code repos), multimodal pretraining (spectra, structures), and architectures with scientific priors (e.g., SE(3)-aware modules).
- Tools/workflows: Data partnerships; data licensing; hybrid architectures (language + graph/geometry).
- Dependencies/assumptions: Data availability and rights; training cost; empirical validation on SDE-hard and real projects.
These applications leverage the paper’s core innovations—scenario-grounded evaluation and project-level closed-loop assessment—to move beyond decontextualized QA and toward measurable, reliable, and safe AI support for scientific discovery. Feasibility hinges on access to domain tools and oracles, robust governance (especially for biology), reproducible open-weight baselines, and sustained community investment in scenario curation and standardization.
Collections
Sign up for free to add this paper to one or more collections.