- The paper demonstrates effective suppression of refusal behavior by orthogonalizing specific directions, achieving minimal distribution shifts (KL divergence 0.043 to 1.646).
- The paper compares four tools—Heretic, DECCP, ErisForge, and FailSpy—evaluating their speed, compatibility, and impact on benchmarks like MMLU, GSM8K, and HellaSwag.
- The paper highlights trade-offs between rapid processing and capability preservation, providing guidance for selecting optimal abliteration strategies across diverse LLM architectures.
Comparative Analysis of LLM Abliteration Methods
Introduction
The paper "Comparative Analysis of LLM Abliteration Methods: A Cross-Architecture Evaluation" (2512.13655) presents a comprehensive examination of abliteration techniques for LLMs aimed at removing refusal behavior while preserving other capabilities. It evaluates four abliteration tools—Heretic, DECCP, ErisForge, and FailSpy—across sixteen instruction-tuned models ranging from 7B to 14B parameters. The study focuses on measuring tool compatibility and comparative effectiveness through metrics such as KL divergence, refusal rate, and benchmark performance (MMLU, GSM8K, HellaSwag).
Refusal Direction Theory
A foundational aspect of this study is the refusal direction theory, where refusal behavior in LLMs is mediated by specific directions in the residual stream activation space. Identifying and orthogonalizing weight matrices with respect to these directions can effectively suppress refusal responses. The paper builds on previous works, including Arditi et al. [arditi2024refusal], which demonstrated universality in safety-aligned languages and explored multi-directional approaches to outperform single-direction ablation [wang2025refusal].
Heretic
Heretic utilizes Bayesian optimization through Optuna's Tree-structured Parzen Estimator (TPE) to minimize KL divergence alongside refusal rate. It largely showed universal compatibility across all tested models, being able to process Mamba SSM architectures as well. This tool was effective in producing minimal distribution shifts with KL divergence ranging from 0.043 to 1.646 across eight models (Figure 1).
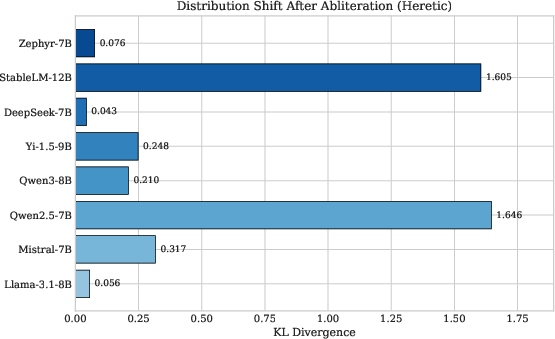
Figure 1: Distribution shift (KL divergence) after Heretic abliteration across eight instruction-tuned models. Lower values indicate better preservation of the original token distribution. DeepSeek-7B achieved the lowest divergence (0.043), while Qwen2.5-7B showed the highest (1.646).
DECCP and ErisForge
DECCP and ErisForge showcased efficient capability preservation with minimal average GSM8K degradation. DECCP, specifically targeted at rapid processing, completed abliteration in approximately 2 minutes per model, outperforming Heretic's 45-minute average per model, while ErisForge provided similar efficiency with added support for refusal direction injection.
FailSpy
FailSpy leverages TransformerLens to cache activations, providing insights into refusal direction across layers, although its dependency on model support limited compatibility to 5 out of the 16 tested models. Despite its interpretability advantages, its limitations on model support restricted broader application compared to the other tools.
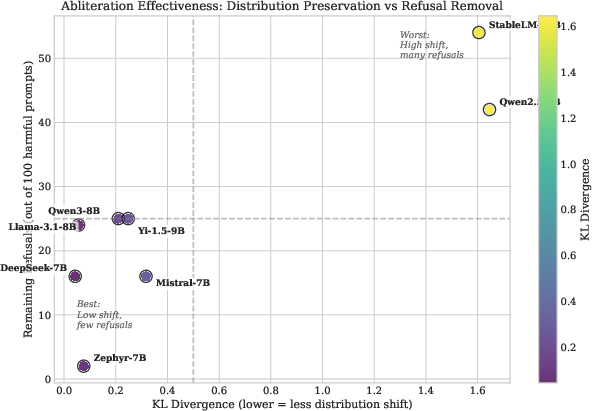
Figure 2: Abliteration effectiveness trade-off: KL divergence (distribution preservation) vs remaining refusal rate. Models in the lower-left quadrant (e.g., Zephyr-7B, DeepSeek-7B) represent optimal outcomes with minimal distribution shift and effective refusal removal.
Benchmark comparisons (MMLU, GSM8K, HellaSwag) confirmed that DECCP and ErisForge maintained near-baseline performance across all benchmarks (Figure 3, Figure 4). Notably, Yi-1.5-9B showed significant GSM8K sensitivity to Heretic, experiencing substantial capability degradation (Figure 5).
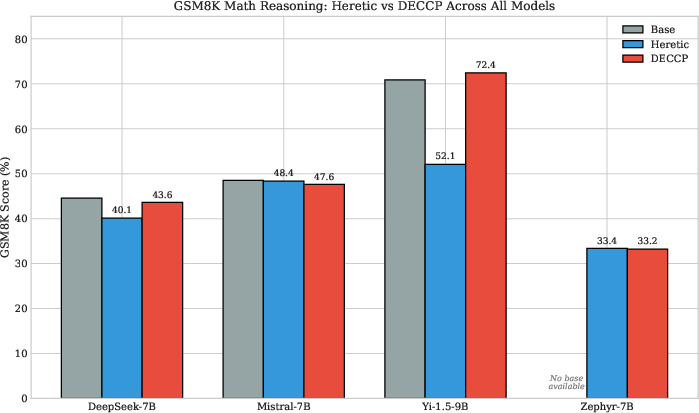
Figure 3: GSM8K math reasoning comparison across all four benchmarked models. DECCP preserved or improved GSM8K performance relative to Heretic on all models, with the most dramatic difference on Yi-1.5-9B (72.40\% vs 52.08\%). Zephyr-7B shows nearly identical scores between tools, lacking a base model for reference.
Heretic achieved universal model compatibility (Figure 6), while DECCP and ErisForge demonstrated significant but not complete coverage. The failings of FailSpy were particularly notable, largely attributed to its architectural dependency. The tools varied in handling of Mamba/hybrid architectures, with Heretic standing out for its universal applicability.
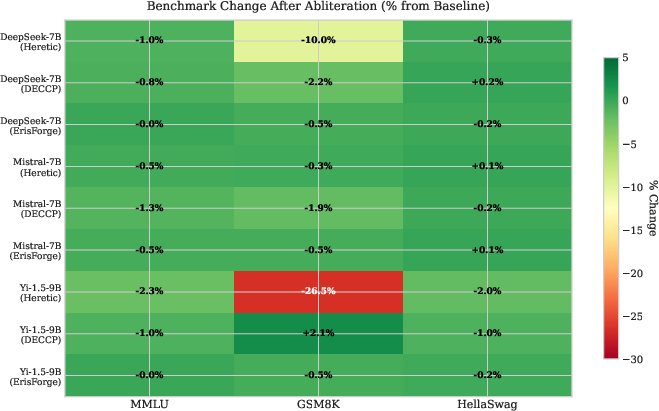
Figure 4: Benchmark change heatmap showing percentage change from baseline for each model-tool combination across MMLU, GSM8K, and HellaSwag. Green indicates improvement or minimal degradation; red indicates significant capability loss. Yi-1.5-9B with Heretic shows notable GSM8K degradation (-26.5\%), while DECCP and ErisForge maintain near-baseline performance.
Discussion
The comparative analysis supports the conclusion that single-pass methods exhibit superior capability preservation, particularly on cognitive benchmarks sensitive to computational perturbations. The tools showed varied effectiveness in altering refusal behavior without disrupting core model capabilities, providing researchers with evidence-based criteria for tool deployment across diverse architectures.
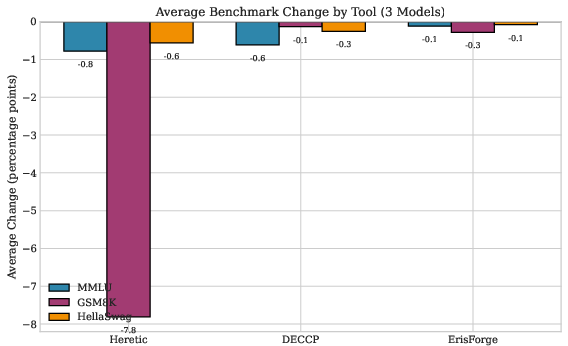
Figure 5: Average benchmark change by tool across three models (DeepSeek-7B, Mistral-7B, Yi-1.5-9B). ErisForge demonstrated the best capability preservation across all benchmarks, followed by DECCP. Heretic showed significant GSM8K degradation on average (-7.81 pp) driven primarily by Yi-1.5-9B results.
Conclusion
The study offers a detailed understanding of LLM abliteration strategies, illustrating the potential and limitations of various tools in preserving or altering safety representations across model architectures. It underscores the importance of balancing refusal suppression with capability preservation while noting the implications of mathematical reasoning sensitivity to directional orthogonalization. The findings guide researchers in selecting appropriate toolsets for different model configurations, contributing to the refinement of LLM alignment methodologies that ensure safety without sacrificing functional capability.
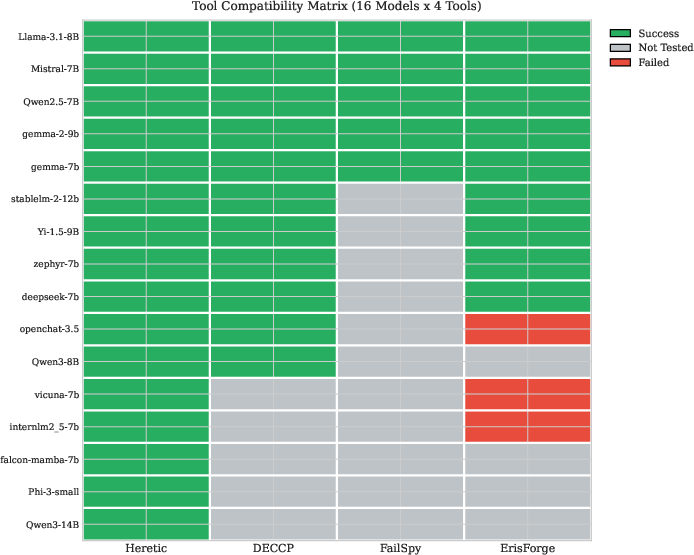
Figure 6: Tool compatibility matrix across sixteen models. Heretic achieved universal compatibility (16/16 models), followed by DECCP (11/16). FailSpy's TransformerLens dependency limited compatibility to 5 models, while ErisForge succeeded on 9 models with some failures on models using non-standard architectures. Gray indicates not tested; Mamba SSM models are architecturally incompatible with transformer-only tools (see Table~\ref{tab:coverage}).

