Chain-of-Thought Hijacking
Abstract: Large reasoning models (LRMs) achieve higher task performance by allocating more inference-time compute, and prior works suggest this scaled reasoning may also strengthen safety by improving refusal. Yet we find the opposite: the same reasoning can be used to bypass safeguards. We introduce Chain-of-Thought Hijacking, a jailbreak attack on reasoning models. The attack pads harmful requests with long sequences of harmless puzzle reasoning. Across HarmBench, CoT Hijacking reaches a 99%, 94%, 100%, and 94% attack success rate (ASR) on Gemini 2.5 Pro, GPT o4 mini, Grok 3 mini, and Claude 4 Sonnet, respectively - far exceeding prior jailbreak methods for LRMs. To understand the effectiveness of our attack, we turn to a mechanistic analysis, which shows that mid layers encode the strength of safety checking, while late layers encode the verification outcome. Long benign CoT dilutes both signals by shifting attention away from harmful tokens. Targeted ablations of attention heads identified by this analysis causally decrease refusal, confirming their role in a safety subnetwork. These results show that the most interpretable form of reasoning - explicit CoT - can itself become a jailbreak vector when combined with final-answer cues. We release prompts, outputs, and judge decisions to facilitate replication.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper studies a weakness in “reasoning AIs” (systems that write out long, step-by-step thoughts before answering). The authors show that the very thing that makes these AIs smarter—writing long explanations—can also make them easier to trick into breaking safety rules. They call this trick “Chain‑of‑Thought Hijacking.”
The big questions the authors asked
- Does making an AI “think out loud” with a long explanation make it safer, or can that long explanation be used to bypass its safety checks?
- If this trick works, why does it work inside the model? What changes in the model’s “attention” and internal safety signals when the explanation is very long?
How did they test their ideas?
Think of the AI’s safety system like a security guard who checks messages and says “no” to harmful requests. The authors tried a tactic similar to distracting the guard with a long, harmless conversation before quietly slipping in a harmful request at the end.
Here’s the approach, in everyday terms:
- They created prompts that included a long stretch of harmless, puzzle-like reasoning (for example, thinking through a logic puzzle), and then added a harmful instruction near the end.
- They tested this against many strong reasoning AIs from different companies.
- They measured how often the AI followed the harmful request instead of refusing. They called this the “attack success rate” (ASR).
- To understand why this happens inside the AI, they used model interpretability tools:
- Attention analysis: Imagine a spotlight that the model shines on different parts of the text. They checked whether the spotlight stayed on the important (potentially harmful) parts or drifted toward the long, harmless reasoning.
- Safety signal “direction”: Picture an internal safety meter that pushes the model toward refusing harmful content. They looked for a simple “direction” in the model’s internal state that represents this safety pressure.
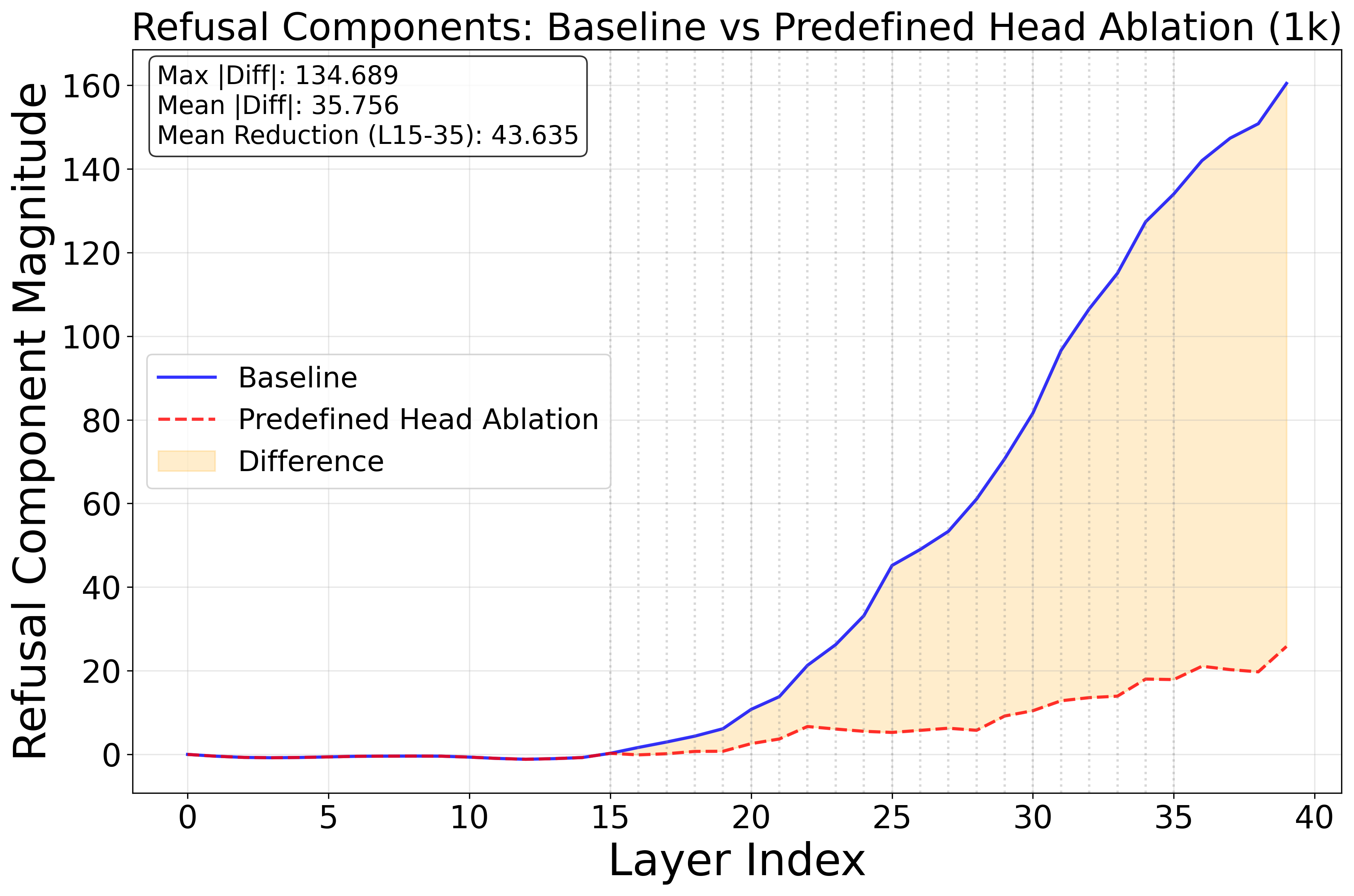
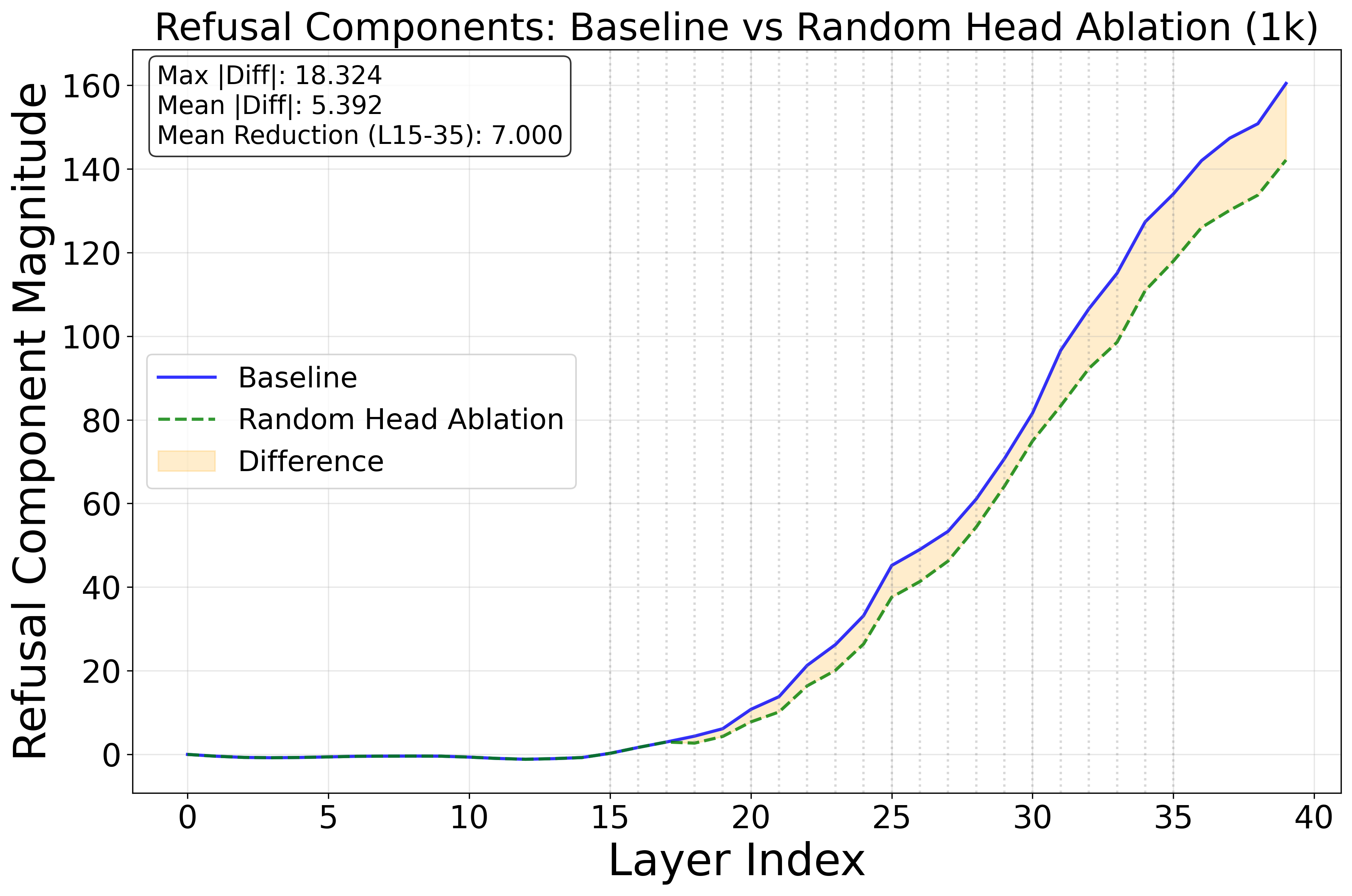
- Controlled edits (“ablations”): Like temporarily muting specific parts of the model’s “circuit,” they turned off certain attention heads to see if refusals dropped—testing which parts are truly doing safety work.
No step‑by‑step instructions or specific prompts are provided here; the goal is to explain the science, not enable misuse.
What did they find, and why is it important?
Key results:
- Very high jailbreak success: On a standard test set (HarmBench), this method got extremely high attack success rates—around 94–100%—on several advanced reasoning AIs (including models from Google, OpenAI, xAI, and Anthropic).
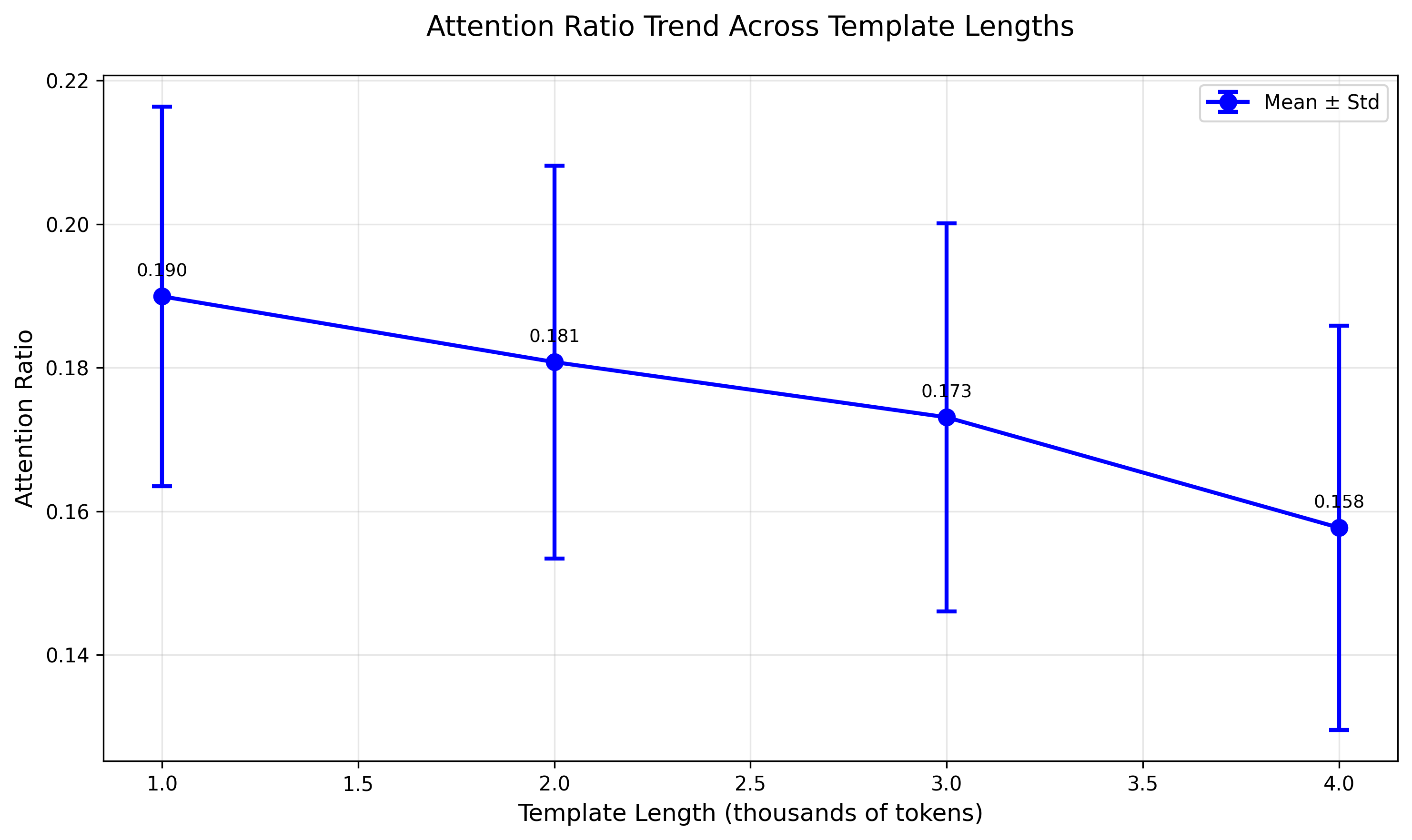
- Longer “thinking” can weaken safety: In controlled tests, making the AI produce longer chains of reasoning made it more likely to comply with harmful requests (for one model, success rose from 27% with minimal reasoning to 80% with extended reasoning).
- The safety signal is fragile and easy to “water down”: Inside the model, there’s a simple, low‑dimensional safety feature (think of a single needle on a meter). Long harmless text before the harmful part “dilutes” this signal, making the needle wobble less clearly toward “refuse.”
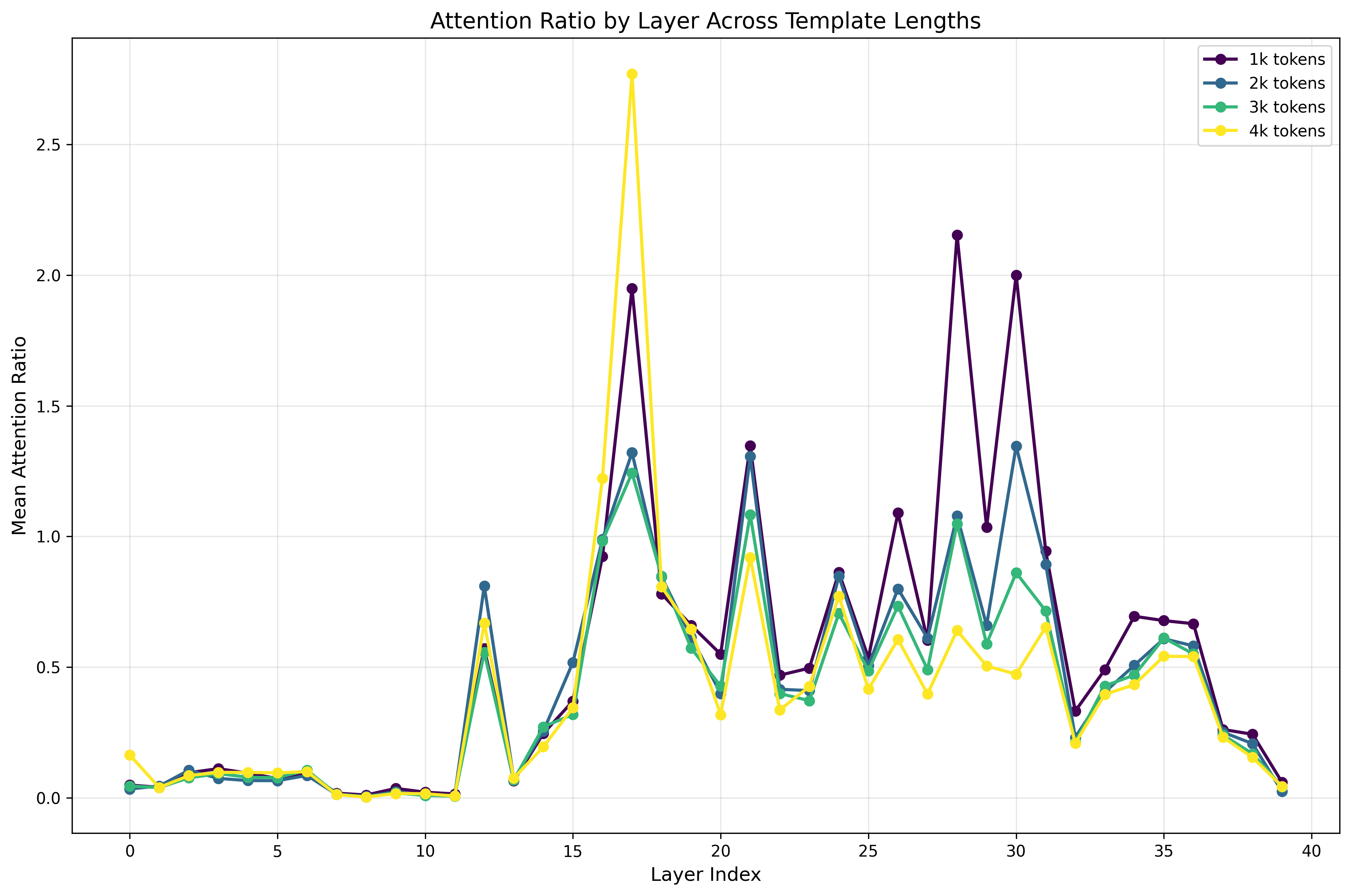
- The spotlight drifts: As the harmless reasoning gets longer, the model’s attention spotlight shifts away from the harmful request. With less attention on the risky part, the safety system misses it more often.
- Specific parts handle safety: When they muted certain attention heads (small components) linked to safety, the model refused less. That shows a real “safety subnetwork” exists—and it can be overwhelmed by long, harmless reasoning.
Why this matters:
- Many people assumed that “more reasoning = more safety.” This paper shows the opposite can happen: long visible chains of thought can be turned into a new attack path.
What does this mean for the future?
- Safety must scale with reasoning: If AIs are trained to write longer and longer explanations, their safety systems need to be designed so they don’t get “distracted” or “diluted” by all that extra text.
- Possible defenses (in simple terms):
- Keep the spotlight on risky parts: Ensure the model always pays enough attention to potentially harmful parts of a prompt, no matter how long the rest is.
- Stabilize the safety meter: Strengthen and monitor the internal safety signal across many layers of the model so it doesn’t fade when the context gets long.
- Build safety into the reasoning itself: Don’t just bolt on a final “refuse” step; make the step‑by‑step thinking continuously check for safety.
- Broader risks: The same distraction/dilution effect could also harm truthfulness, privacy protection, and bias reduction—any behavior that relies on a clear safety signal.
In short: Reasoning AIs are powerful, but their long explanations can be used against them. To keep them safe, we need guardrails that stay strong and focused even when the model is thinking out loud for a long time.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper, phrased to support actionable follow-up research.
- External validity and sample size
- Results on proprietary LRMs are reported on only the first 100 HarmBench items; no stratified analysis by harm category (e.g., cyber, bio, physical harm) to assess differential susceptibility.
- No evaluation on non-HarmBench datasets (e.g., jailbreakbench full, bio/cyber-focused benchmarks), limiting generalizability.
- Judge reliability and measurement uncertainty
- Reliance on automated judges (chatgpt-4o-mini, DeepSeek-v3.1, substring matching) without inter-judge agreement, calibration, or human adjudication; potential systematic bias in ASR estimates remains unquantified.
- No robustness checks for judge manipulation by long prompts (e.g., whether benign prefaces bias judge decisions).
- Inference settings and configuration control
- Temperature, nucleus sampling, system prompts, and safety settings are not standardized or ablated across models; ASR sensitivity to these parameters is unknown.
- For GPT-5-mini “reasoning.effort,” the link to actual CoT length is unclear; no direct instrumentation of internal reasoning tokens for closed models.
- Cost/latency and practical constraints
- No quantification of token overhead, latency, or API cost for the attack; attack success vs. computational budget trade-offs are uncharacterized.
- Feasibility under production constraints (rate limits, max context length, timeouts) is not evaluated.
- Attack component ablations
- No isolation of the contribution of the “final-answer cue” versus CoT length; the marginal effect of phrasing, position, or removal of the cue is unknown.
- No ablation on the benign preface content type: coherence vs. random tokens, domain (puzzles vs. narratives), structure, or linguistic complexity.
- No test of payload placement (e.g., interleaved inside preface vs. appended at end) or position-relative effects on ASR.
- Minimality and scaling laws
- Absence of a dose-response curve for CoT length vs. ASR to estimate minimal effective length and saturation points across models.
- No analysis of how attack efficacy scales with model size, context window length, or architecture variants.
- Transferability and universality
- Cross-model transfer of crafted prompts (one-shot transfer without retuning) is not tested; universality of prefaces across vendors is unknown.
- Cross-lingual and code- or math-only payload generalization is unstudied.
- Interaction with model features/modes
- No evaluation in multi-turn dialogs, tool-use/agentic settings, retrieval-augmented contexts, or system message hardening.
- No tests on multimodal LRMs (image, audio, video) where CoT-like prefixes could be injected via other modalities.
- Mechanistic coverage and causality
- Mechanistic results are centered on Qwen3-14B; replication on other open LRMs (e.g., DeepSeek-R1, Llama-3.1-70B) and proprietary models is missing.
- Focus on attention-head ablations; contribution of MLP blocks, layer norms, and positional encodings (RoPE/ALiBi) to refusal is unexamined.
- Causality methods beyond ablations (e.g., activation patching, causal tracing, interchange interventions) are not applied to validate the proposed “refusal dilution” pathway.
- The claim that “mid layers encode safety checking strength and late layers encode verification outcome” lacks cross-model validation and rigorous localization with multiple methods.
- Attention analyses limitations
- Attention ratio metric may be confounded by head mixing and length effects; no head-weighted or attribution-based alternatives (e.g., attention rollout, integrated gradients) are used.
- Attention analyses are restricted to short CoT ranges (1k–4k) due to GPU limits; extrapolation to very long contexts (10k–200k) is not validated on the same analyses.
- Defense design and evaluation
- Proposed defenses (monitor refusal activations, enforce attention to harmful spans, penalize dilution) are not implemented or empirically validated.
- No comparison against existing defenses (e.g., pre/post-response filtering, adversarial training, refusal steering, system prompt hardening) under the new attack.
- No measurement of helpfulness/utility trade-offs for defenses that strengthen refusal directions (risk of over-refusal not quantified).
- Safety breadth beyond refusal
- Claims that truthfulness, privacy, and bias mitigation may also degrade under long CoT are not tested; no experiments on data exfiltration, sensitive PII, or fairness-sensitive tasks.
- No evaluation against domain-specific, high-stakes safety checks (e.g., biosecurity filters, cyber exploitation detectors).
- Robustness to model and ecosystem changes
- Stability of the attack across model updates, safety patches, and variance across random seeds is not reported.
- Sensitivity to vendor-specific guardrails (e.g., content classifiers, rate throttling, hidden scratchpads) is untested.
- Detection and operational countermeasures
- No study of detection signals for long benign prefaces (e.g., perplexity spikes, repetition patterns, semantic-topic shifts) or deployable heuristics for runtime filtering.
- No exploration of server-side mitigations (context truncation, re-ranking to prioritize harmful-span attention, pre-answer safety passes).
- Benchmarking completeness
- Lack of category-level breakdowns of ASR to identify which harm types are most/least affected.
- No reporting of false refusal rates on harmless prompts under the attack template (i.e., collateral damage to helpfulness).
- Reproducibility and transparency
- Precise procedures for selecting “60 heads” for ablation and the selection criteria are not fully specified; reproducibility of head selection across runs/models is uncertain.
- Some notation/details (e.g., “layer 25, position −4”) are insufficiently clarified for replication across tokenization schemes and frameworks.
- Broader architectural and training factors
- Impact of RLVR, safety fine-tuning variants, and training-time penalties on refusal dilution is unmeasured; no comparison between safety-aligned LRMs (e.g., RealSafe-R1) and baseline LRMs under the attack.
- Differences between visible vs. hidden CoT (scratchpad suppression) on attack efficacy are not systematically tested.
- Real-world adversary modeling
- Attacker constraints (budget, context length availability, prompt auditing) and defender capabilities (pre-/post-hoc filters, ensemble judges) are not modeled; practical risk is not calibrated.
These gaps collectively point to a need for broader, controlled, and defense-aware evaluations; deeper, cross-architecture mechanistic validation; and actionable, low-regret mitigations that preserve utility while resisting chain-of-thought-based jailbreaks.
Practical Applications
Overview
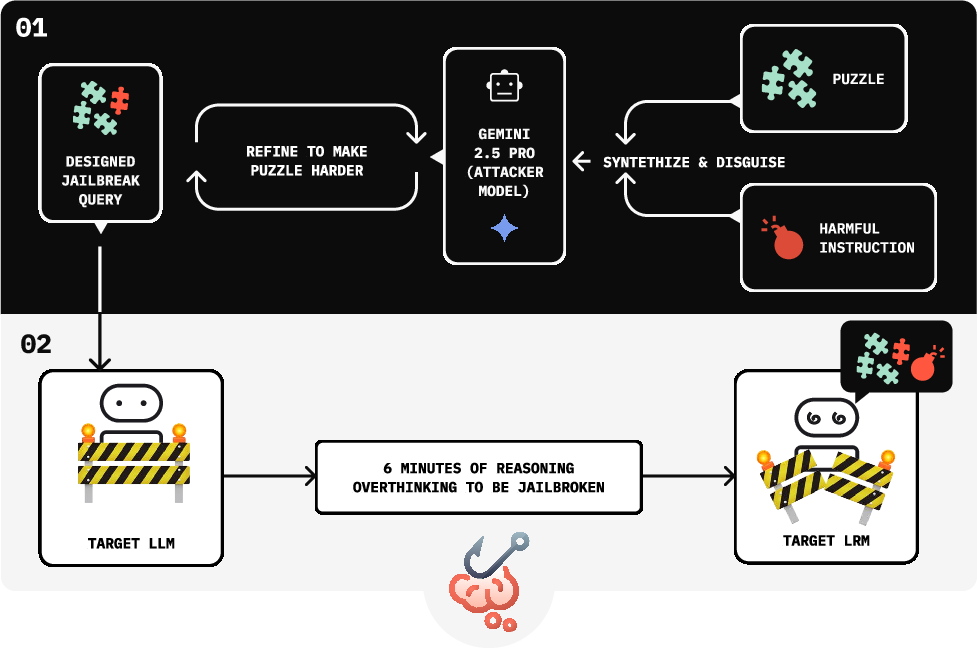
The paper introduces Chain-of-Thought (CoT) Hijacking: a jailbreak technique that prepends long, benign reasoning and a final-answer cue to harmful queries, dramatically reducing refusal rates in large reasoning models (LRMs). Mechanistic analyses show that refusals rely on a fragile, low-dimensional “refusal direction,” with mid-layer safety features and late-layer verification, both diluted by long benign CoT through attention shifting away from harmful tokens. The work also contributes tools and concepts such as an automated prompt-generation and judging loop (“Seduction”), attention-ratio metrics, refusal-component projections, and targeted attention-head ablations that reveal a safety subnetwork.
Below are practical applications derived from these findings, organized by deployment horizon. The emphasis is on defensive, evaluation, and governance uses across industry, academia, policy, and daily life.
Immediate Applications
The following can be deployed now with existing models and tooling (especially for open-source or API-accessible systems). Each bullet notes relevant sectors, potential tools/workflows, and key assumptions or dependencies.
- CoT-aware red-teaming and evaluation suites
- Sectors: AI labs, cloud platforms, enterprise model buyers, security consultancies.
- What: Incorporate CoT-hijacking prompts and long-context stress tests into standard red-team pipelines to uncover reasoning-specific vulnerabilities. Use multi-judge aggregation to reduce judge error.
- Tools/workflows: “CoT Red Team Suite” inspired by the paper’s Seduction pipeline; CI/CD integration that evaluates ASR vs. CoT length and final-answer cues; automated reporting.
- Assumptions/dependencies: Sufficient API budget and rate limits; judge reliability; responsible handling of dual-use attack prompts.
- CoT-length stress testing in model procurement and vendor assessments
- Sectors: Government, regulated industries (healthcare, finance, legal), enterprise procurement.
- What: Add “CoT robustness” checks to evaluation contracts and SLAs; require performance under benign-CoT-prepended harmful prompts; evaluate the relationship between reasoning.effort and refusal rates.
- Tools/workflows: Standardized “CoT-Robustness Scorecards” for RFPs; reproducible benchmark harnesses.
- Assumptions/dependencies: Access to consistent evaluation endpoints; legal permission to red-team vendor models.
- Runtime CoT-aware safety wrappers
- Sectors: SaaS platforms, customer support, education tools, developer assistants.
- What: Safety middleware that re-screens the final segment of the prompt and the model’s last reasoning window; detects final-answer cue patterns; enforces two-pass moderation (check both full context and the answer-near context).
- Tools/workflows: “Answer-Zone Guard” (final-answer-span rescoring), “CoT/Content Ratio Check” (flag anomalously long benign prefaces), segmented moderation pipelines.
- Assumptions/dependencies: Access to the full request/response stream; latency budgets for a second moderation pass; false-positive management.
- Reasoning-effort governance policies
- Sectors: Cloud inference services, enterprise IT, mobile/on-device AI.
- What: Policy controls to cap or adapt reasoning token budgets when safety confidence is low; trigger summarization or truncation of excessively long benign reasoning before answering.
- Tools/workflows: “Reasoning Governor” that adapts reasoning.effort; context summarizers; policy knobs in deployment configs.
- Assumptions/dependencies: Utility-safety trade-offs (caps may hurt quality); telemetry to detect safety risk.
- Refusal-direction steering for open-source deployments
- Sectors: Software, MLOps, research labs with model hooks.
- What: Add the learned refusal direction to residual streams on risky prompts to increase refusals; use subtraction tests for diagnosis.
- Tools/workflows: “Refusal Direction Monitor + Steerer” modules; hooks into residual streams (e.g., through libraries like transformer lens).
- Assumptions/dependencies: Requires access to model activations and hooks; not feasible for closed APIs; risk of over-refusal and utility loss.
- Attention-ratio and refusal-component dashboards for safety QA
- Sectors: Model evaluation teams, academia, internal governance.
- What: Track attention paid to harmful spans vs. benign CoT and monitor refusal-component values across layers during eval to detect dilution under longer CoT.
- Tools/workflows: “Safety Interpretability Dashboard” visualizing layer-wise attention ratios and refusal components; regression tests by CoT length.
- Assumptions/dependencies: Activation/attention access (open models) or telemetry/approximations (closed models); compute overhead.
- Dataset augmentation for safety training and triage
- Sectors: AI training teams, applied research, foundation model fine-tuning providers.
- What: Create “benign-CoT + harmful payload” datasets to train detectors or RLHF/RLVR critics against CoT Hijacking; mine failure modes to improve guardrails.
- Tools/workflows: Data generation scripts; curator guidelines; multi-judge labeling.
- Assumptions/dependencies: Label quality; potential model overfitting to known patterns; privacy and data governance.
- Sector-specific deployment checks
- Sectors: Healthcare, finance, legal, education, robotics.
- What: For high-risk deployments, enforce CoT-off or limited reasoning modes by default; require extra moderation for final-answer segments; lock down user-visible CoT to prevent leakage of refusal criteria.
- Tools/workflows: Policy templates; deployment playbooks; “CoT visibility” toggles in UI.
- Assumptions/dependencies: Domain regulations; acceptable performance with CoT restrictions.
- Red-team bug bounty scopes expanded to reasoning-specific attacks
- Sectors: AI vendors, platforms.
- What: Incentivize discovery of CoT-based jailbreaks and refusal-dilution vulnerabilities with safe disclosure channels.
- Tools/workflows: Bounty program updates; guidelines for reasoning-specific submissions.
- Assumptions/dependencies: Legal and ethical frameworks; triage capacity.
Long-Term Applications
These concepts require further research, access to internals, scaling efforts, or standardization before broad deployment.
- Training-time anti-dilution objectives
- Sectors: AI labs, academic ML research.
- What: Learning objectives that maintain strong refusal components as CoT grows (e.g., penalties for safety-signal decay across layers; contrastive training that emphasizes harmful-span salience under long contexts).
- Tools/products: “Anti-Dilution RLVR” or auxiliary losses; curriculum with variable CoT lengths.
- Assumptions/dependencies: Training compute; robust measurement of safety signals; avoiding utility regressions.
- Architectural guardrails: safety subnetworks and persistent attention to harmful spans
- Sectors: Model architecture research, foundation model developers.
- What: Design dedicated safety heads or cross-layer pathways that persistently attend to harmful tokens regardless of benign CoT; verification layers that re-check payload salience before answering.
- Tools/products: “Safety Head Pack” modules; payload-aware gating blocks; late-stage verification heads.
- Assumptions/dependencies: Requires architecture changes and retraining; evaluation against adaptive adversaries.
- Runtime interpretability monitors with fail-safe actions
- Sectors: Safety-critical deployments (healthcare, robotics, finance), cloud services.
- What: On-the-fly monitors that track refusal-component ranges and attention ratios; trigger safe fallbacks when dilution is detected.
- Tools/products: “SafetyLens” coprocessor; activation-sidecar monitors; policy engines for fallback (refuse, route to human, or reduce reasoning).
- Assumptions/dependencies: Activation access or trustworthy proxies; acceptable latency; robust thresholds.
- CoT-aware standardization and certification
- Sectors: Policy and standards bodies, regulators, third-party auditors.
- What: Establish a CoT-Robustness certification that requires long-context refusal stability, final-answer-span checks, and resistance to benign-CoT padding across modalities.
- Tools/workflows: Public test suites; reference judges; compliance protocols.
- Assumptions/dependencies: Consensus on metrics; industry participation; governance for dual-use benchmarks.
- Safer agentic workflows and tool-use orchestration
- Sectors: Enterprise automation, software agents, DevOps, data engineering.
- What: Agent frameworks that compartmentalize reasoning (summarize or sandbox long CoT), re-scan payloads before tool calls, and enforce answer-zone validation gates.
- Tools/products: “CoT Shield” gateway for agents; tool-call preconditions that pass safety checks independent of prior CoT.
- Assumptions/dependencies: Changes to agent runtimes; potential throughput impacts.
- Multi-modal extensions (vision, code, speech)
- Sectors: Robotics, autonomous systems, code assistants, media platforms.
- What: Apply CoT-dilution insights to VLMs and code LLMs (e.g., long benign commentary or visual context masking payload salience); develop modality-specific attention-ratio metrics and defenses.
- Tools/products: Vision/code “payload salience trackers”; multi-modal answer-zone moderation.
- Assumptions/dependencies: Modality-specific interpretability; larger context windows.
- Safety co-processors and hardware/firmware hooks
- Sectors: AI hardware vendors, cloud providers.
- What: Dedicated accelerators or firmware features that expose safety telemetry (e.g., attention heat maps to harmful spans) and enforce gating without revealing raw internals.
- Tools/products: “Safety Telemetry API” at the inference layer; hardware-backed kill-switch for unsafe answer transitions.
- Assumptions/dependencies: Vendor cooperation; standard APIs; privacy/security implications.
- Watermarking and provenance for reasoning tokens
- Sectors: Platforms, compliance, education.
- What: Watermark or tag reasoning tokens to allow safety systems to weight them differently than user payload tokens, mitigating dilution effects.
- Tools/products: “Reasoning Token Tags” in tokenizer/protocol; downstream safety-aware decoding.
- Assumptions/dependencies: Tokenizer/protocol adoption; robustness to adversarial manipulation.
- Regulatory risk disclosures and reporting
- Sectors: Policy, corporate governance, insurers.
- What: Require periodic reporting on CoT-driven safety regressions, attention dilution, and mitigation efficacy; incorporate into AI risk registers and incident response processes.
- Tools/workflows: CoT risk templates; audit logs linking failures to safety-subnetwork diagnostics.
- Assumptions/dependencies: Legal frameworks; standardized incident definitions.
- Sector-tailored safety configurations
- Sectors: Healthcare (clinical decision support), finance (trading/advice), education (tutoring), robotics (task planning).
- What: Domain-specific preset policies for reasoning limits, final-answer gating, and over-refusal tolerance calibrated to risk.
- Tools/products: “Sector Safety Profiles” for deployment platforms; compliance-aligned defaults.
- Assumptions/dependencies: Domain norms and regulations; validation against real-world workloads.
Notes on Feasibility and Dependencies
- Access constraints: Mechanistic defenses (direction steering, head ablations) require activation access and are mainly feasible for open-source models; closed APIs may only permit wrapper-level defenses.
- Utility trade-offs: Reasoning caps, over-refusal, and extra moderation passes can reduce task performance or increase latency; careful A/B testing is needed.
- Evaluation reliability: Judge model bias/variance can skew measured ASR; multi-judge or human spot checks improve robustness.
- Adaptive adversaries: Defenses must be tested against evolving attacks (e.g., varied cues, multimodal payloads); avoid overfitting to known templates.
- Compute and cost: Monitoring attention/activations and multi-pass moderation increase compute; budget for safety overheads in production SLAs.
- Governance: Dual-use risks require scoped access, safe disclosure processes, and clear red-team ethics.
These applications translate the paper’s key insights—the fragility of low-dimensional refusal signals under long CoT and the causal role of specific attention heads—into concrete tools, policies, and engineering practices to evaluate, harden, and certify reasoning-enabled AI systems.
Glossary
- Ablation: An experimental technique where parts of a model are removed or disabled to test their causal role. "Ablation: remove the refusal direction during harmful instructions."
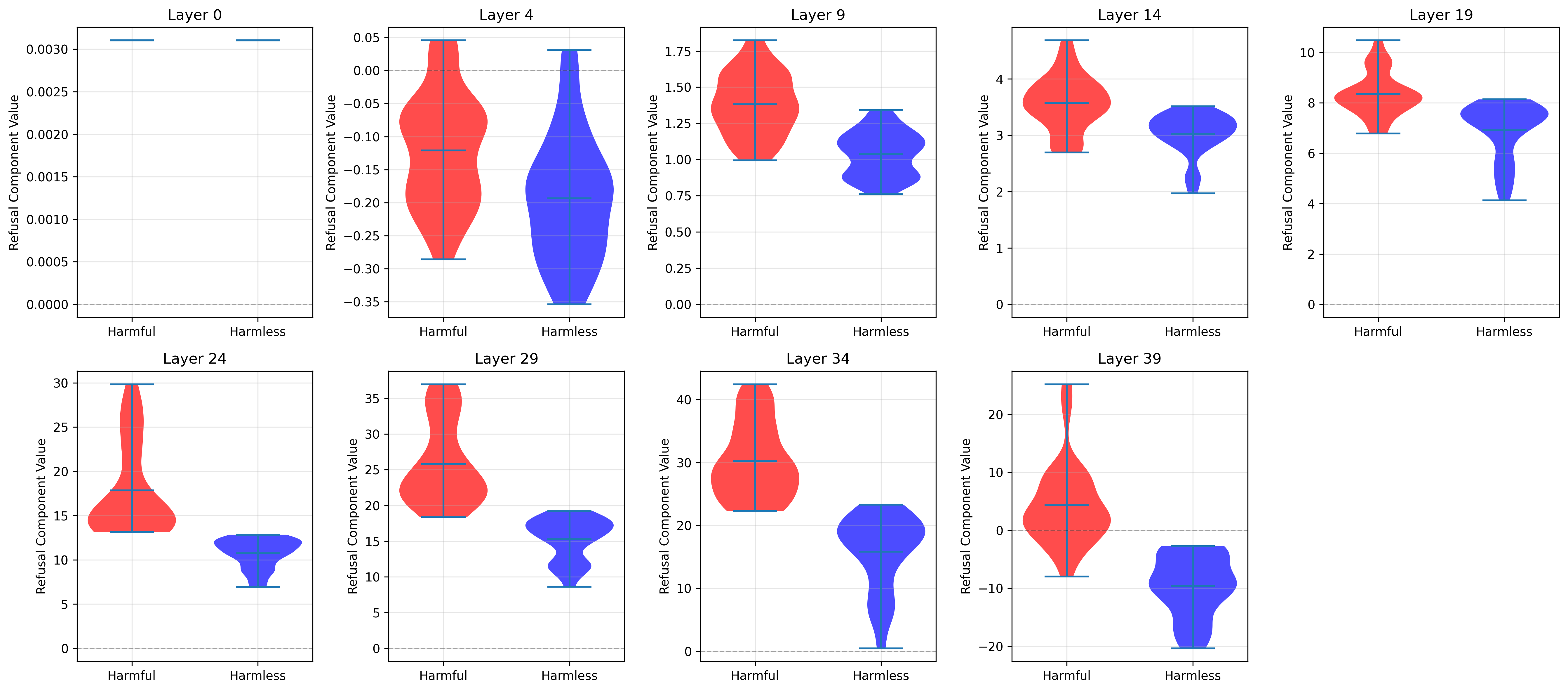
- Activation-space direction: A vector in a model’s internal representation that captures a specific behavior or feature. "We study whether refusal behavior in large reasoning models (LRMs) can also be traced to a single activation-space direction."
- Adversarial robustness: The resilience of models against intentionally crafted inputs designed to cause failures. "Our work complements red-teaming and adversarial robustness efforts such as PoisonBench \citep{fu2024poisonbench}"
- Alignment strategies: Approaches to ensure model outputs follow ethical, safety, or policy constraints. "Addressing them will require alignment strategies that scale with reasoning depth rather than relying on brittle refusal signals."
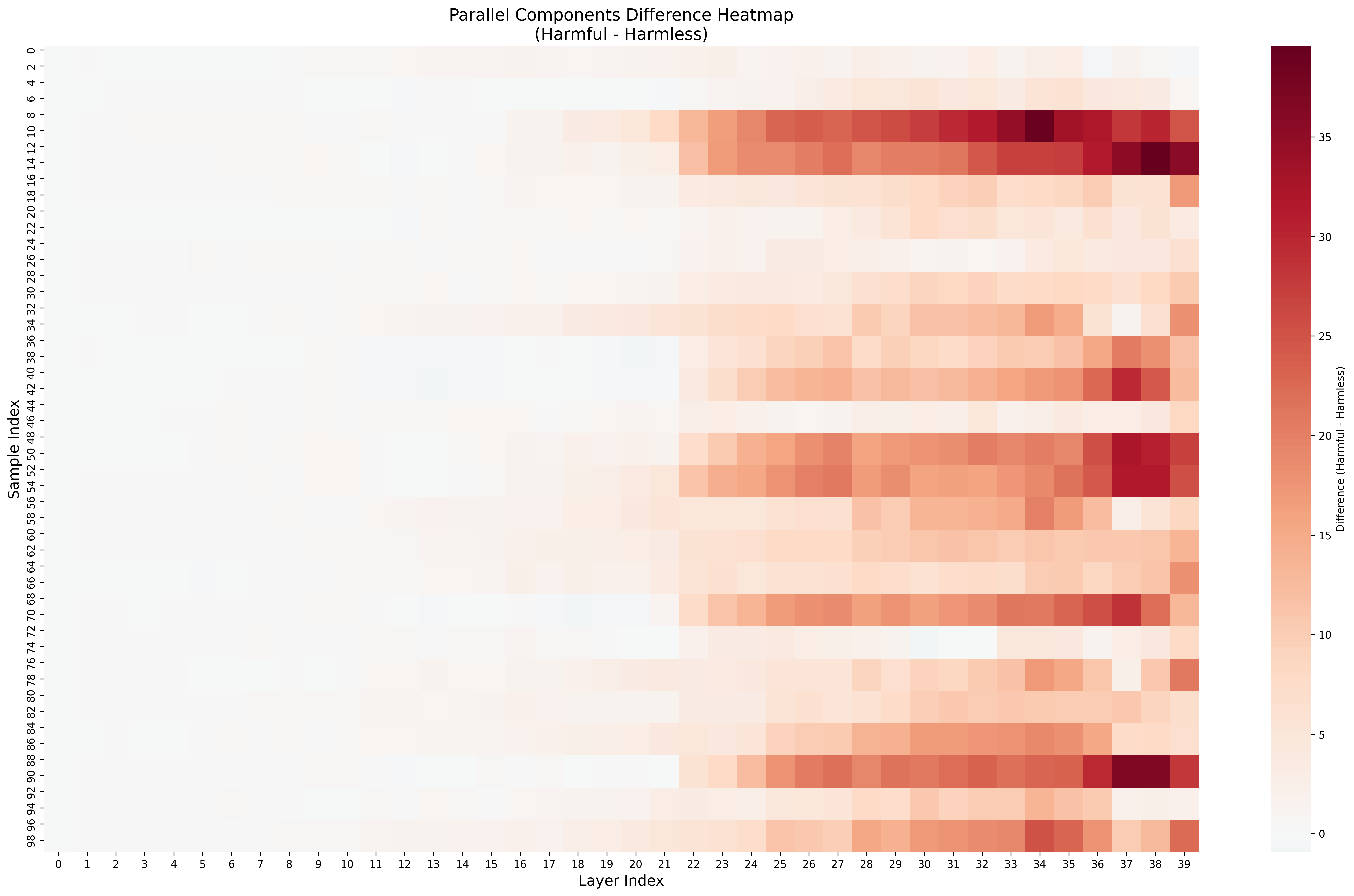
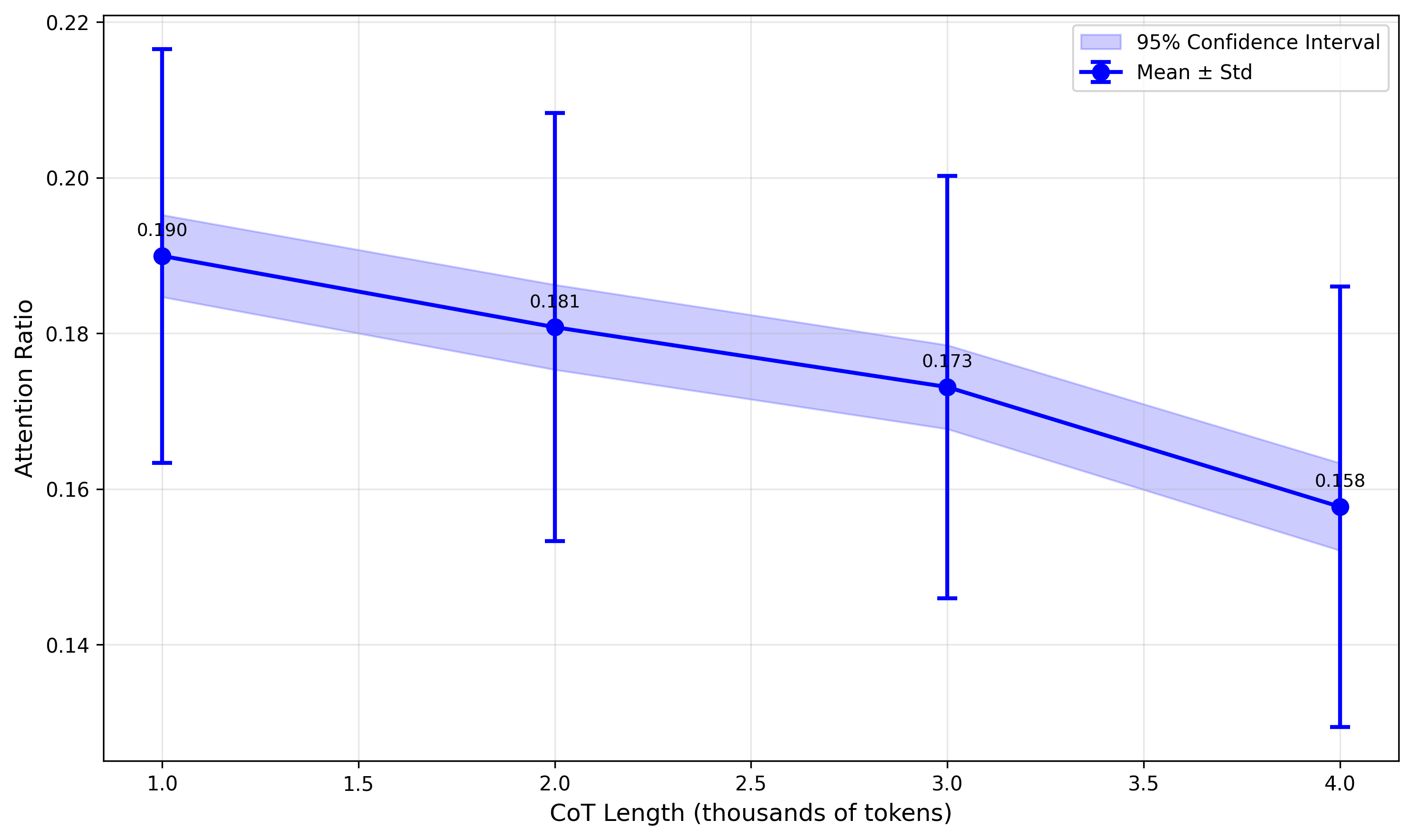
- Attention dilution: The reduction in focus on important tokens when many benign tokens are present, weakening relevant signals. "An important factor could be the decline of instruction-following ability after a long chain-of-thought~\citep{fu2025scaling} due to attention dilution~\citep{li2025thinking}."
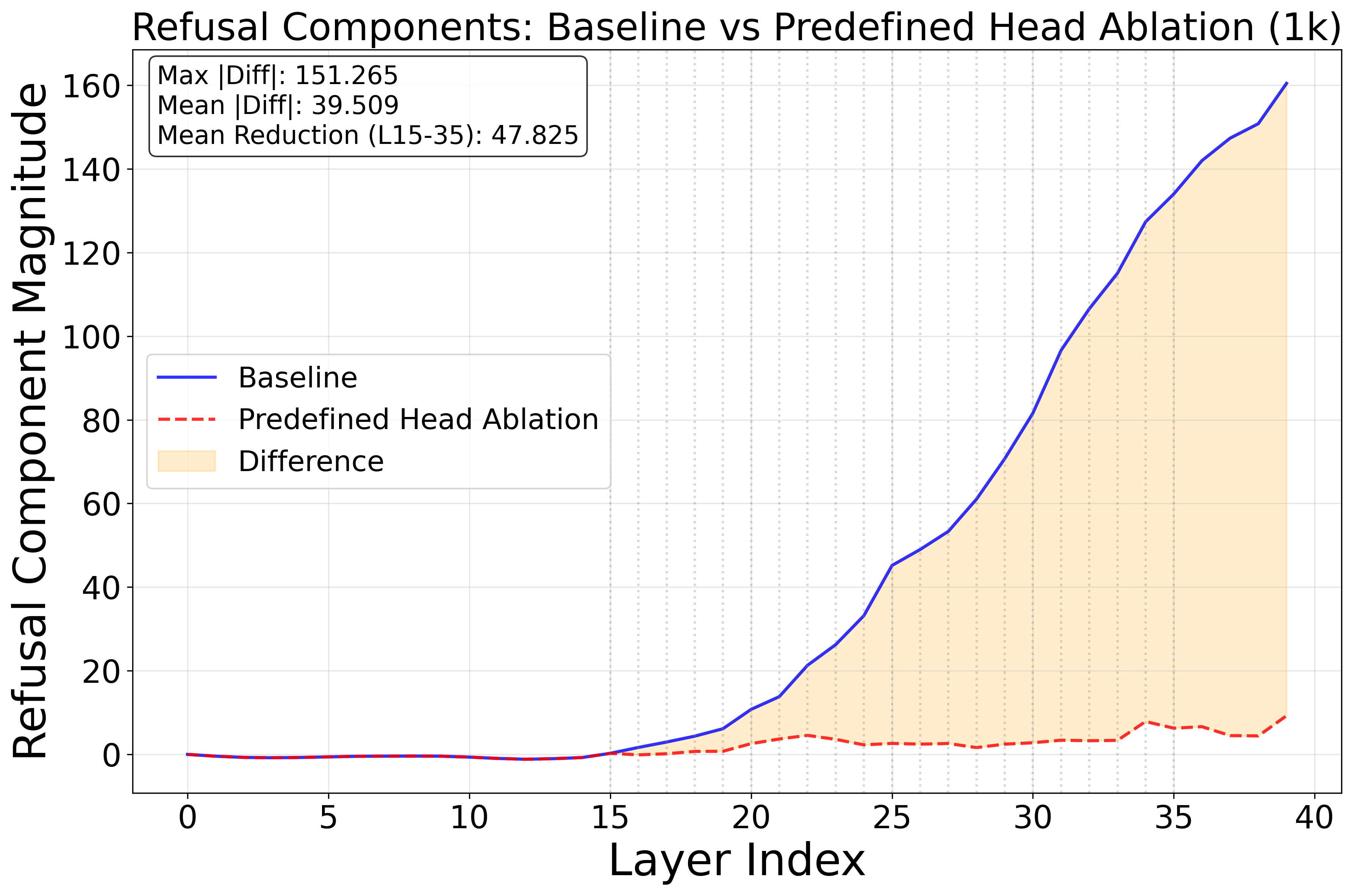
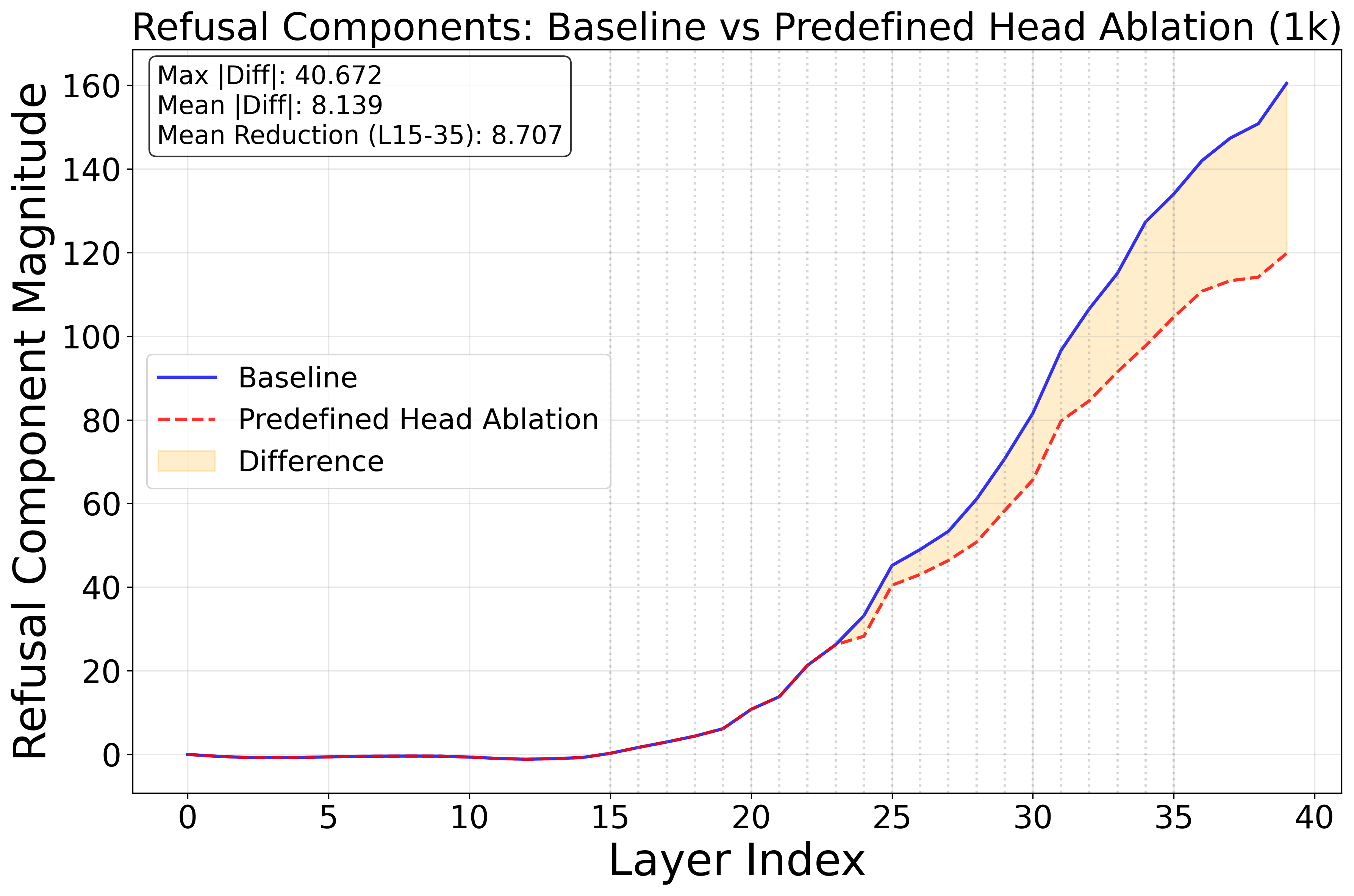
- Attention heads: Subcomponents of transformer layers that compute attention patterns over tokens. "Targeted ablations of attention heads identified by this analysis causally decrease refusal, confirming their role in a safety subnetwork."
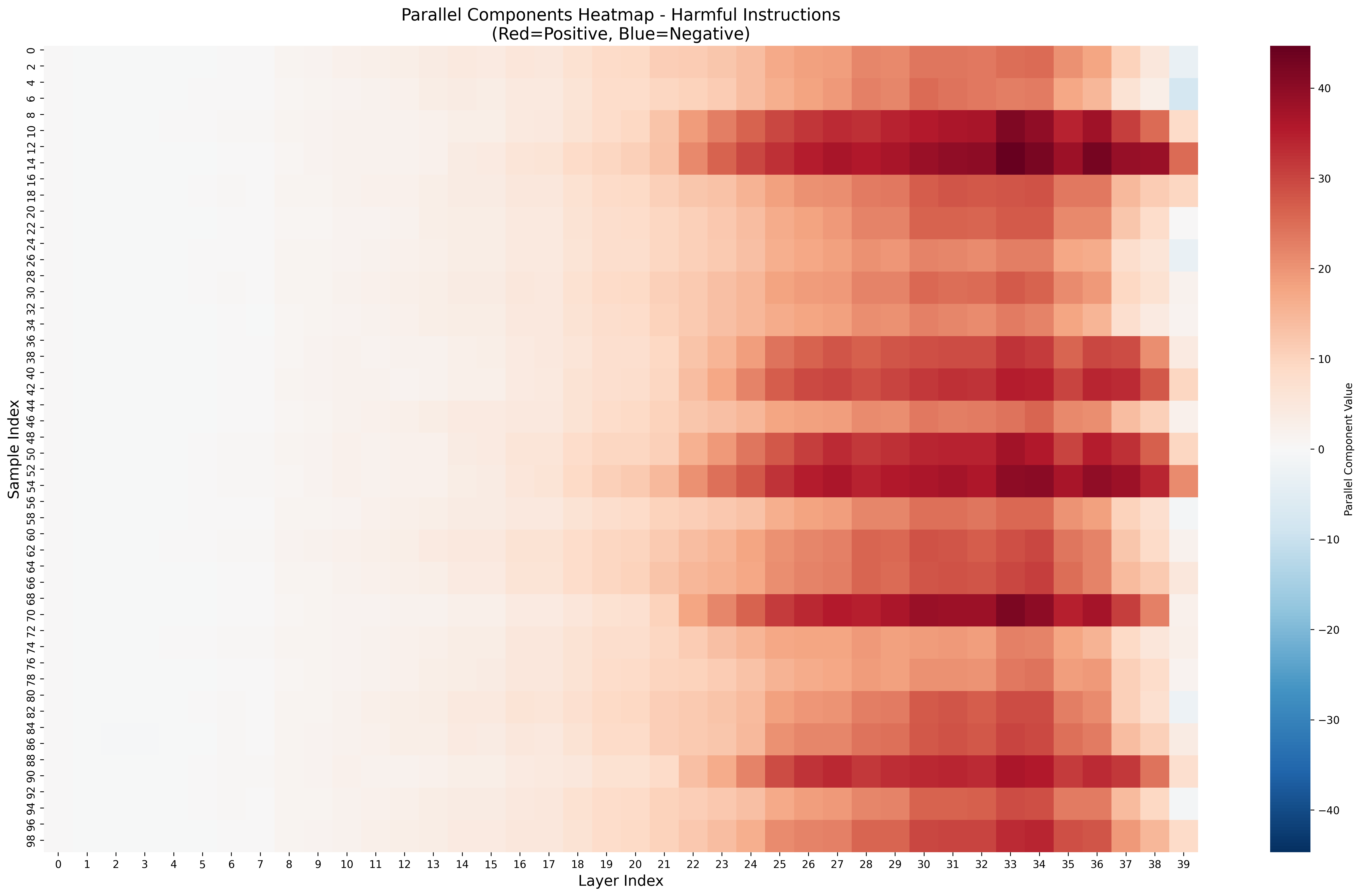
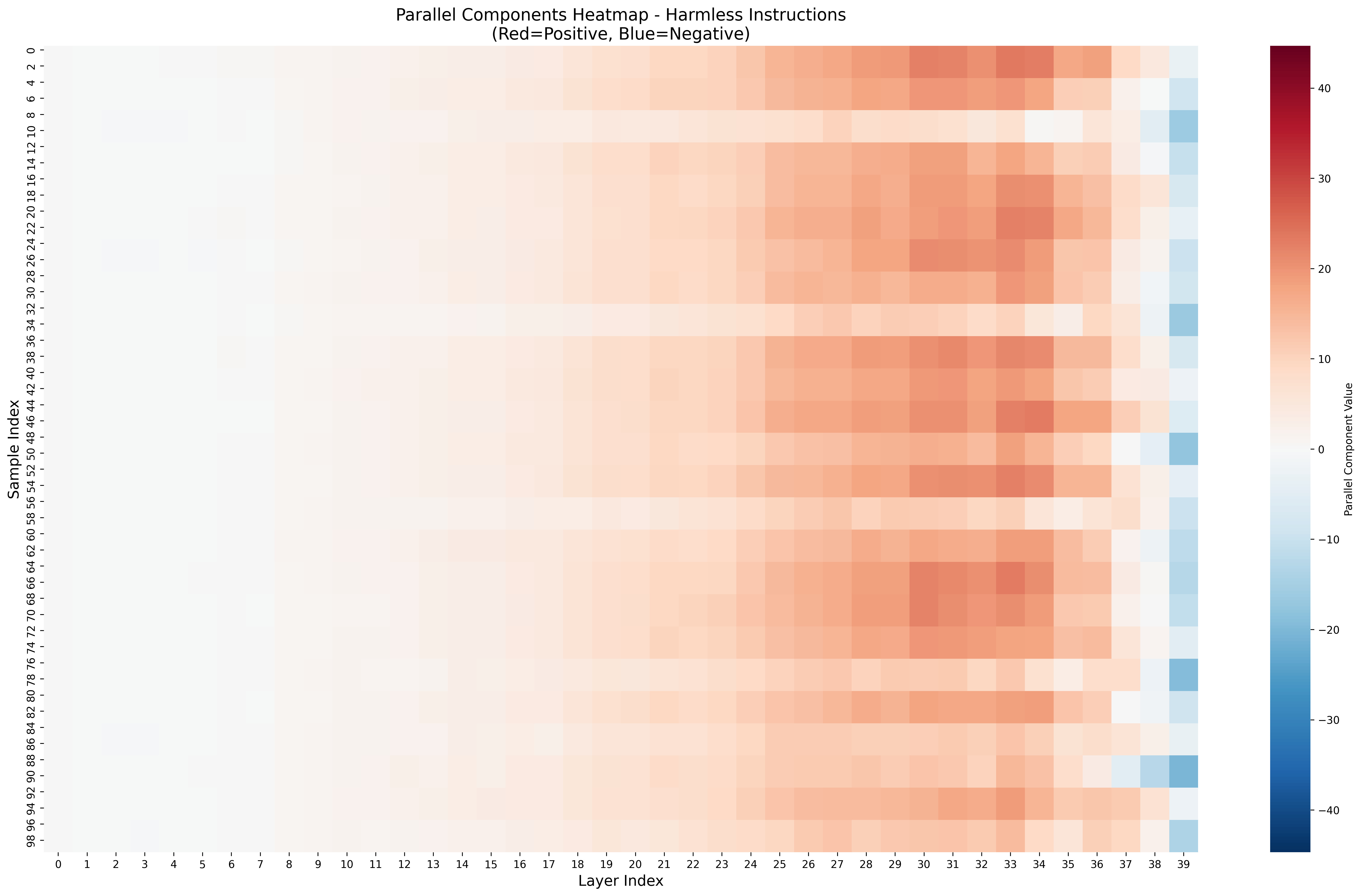
- Attention ratio: A metric comparing attention on harmful tokens versus benign tokens in a prompt. "We define the attention ratio as 'the sum of attention weights on harmful tokens in the prompt' divided by 'those on puzzle tokens in the prompt', thereby eliminating the influence of token length on this metric."
- Attack Success Rate (ASR): The percentage of attempts where a jailbreak successfully bypasses safety mechanisms. "We report Attack Success Rate (ASR) as the primary metric to assess jailbreak effectiveness."
- AutoRAN: A jailbreak method used as a baseline for comparison. "69\% for AutoRAN \citep{chen2023autoran}"
- Benign preface: A harmless reasoning section prepended to a prompt to influence model behavior. "Benign preface: coherent reasoning steps unrelated to the harmful payload."
- Black-box methods: Attacks that interact with a model only via inputs/outputs without internal access. "On the other hand, black-box methods simply rewrite the prompt to into a seemingly benign queries by designing a convoluted scenario~\citep{li2023deepinception}, creating a role-play context~\citep{ma2024visual}, enciphering the query into a cipher text or program coding~\citep{yuan2024gpt,jiang2024artprompt}, translating it into multiple language~\citep{shen2024language}, or simply optimizing sampling strategies \citep{hughes2024best}."
- Causal interventions: Direct changes to model internals to test causal relationships with behaviors. "We analyze why refusal fails under CoT Hijacking, using attention patterns, probes, and causal interventions to show dilution of refusal features."
- Chain-of-Thought (CoT): Explicit, step-by-step reasoning generated before an answer. "CoT is a further subset where those steps are explicitly verbalized."
- Chain-of-Thought Hijacking: A jailbreak attack that pads harmful requests with long benign reasoning to weaken refusal. "We introduce Chain-of-Thought Hijacking, a jailbreak attack on reasoning models."
- Circuit analysis: Method in mechanistic interpretability that identifies interconnected components underlying behaviors. "interpretability studies on LLM safety reveal safety mechanisms through component analysis~\citep{ball2024understanding} or circuit analysis~\citep{chen2024finding}."
- Component analysis: An interpretability approach that examines contributions of individual model parts. "interpretability studies on LLM safety reveal safety mechanisms through component analysis~\citep{ball2024understanding}"
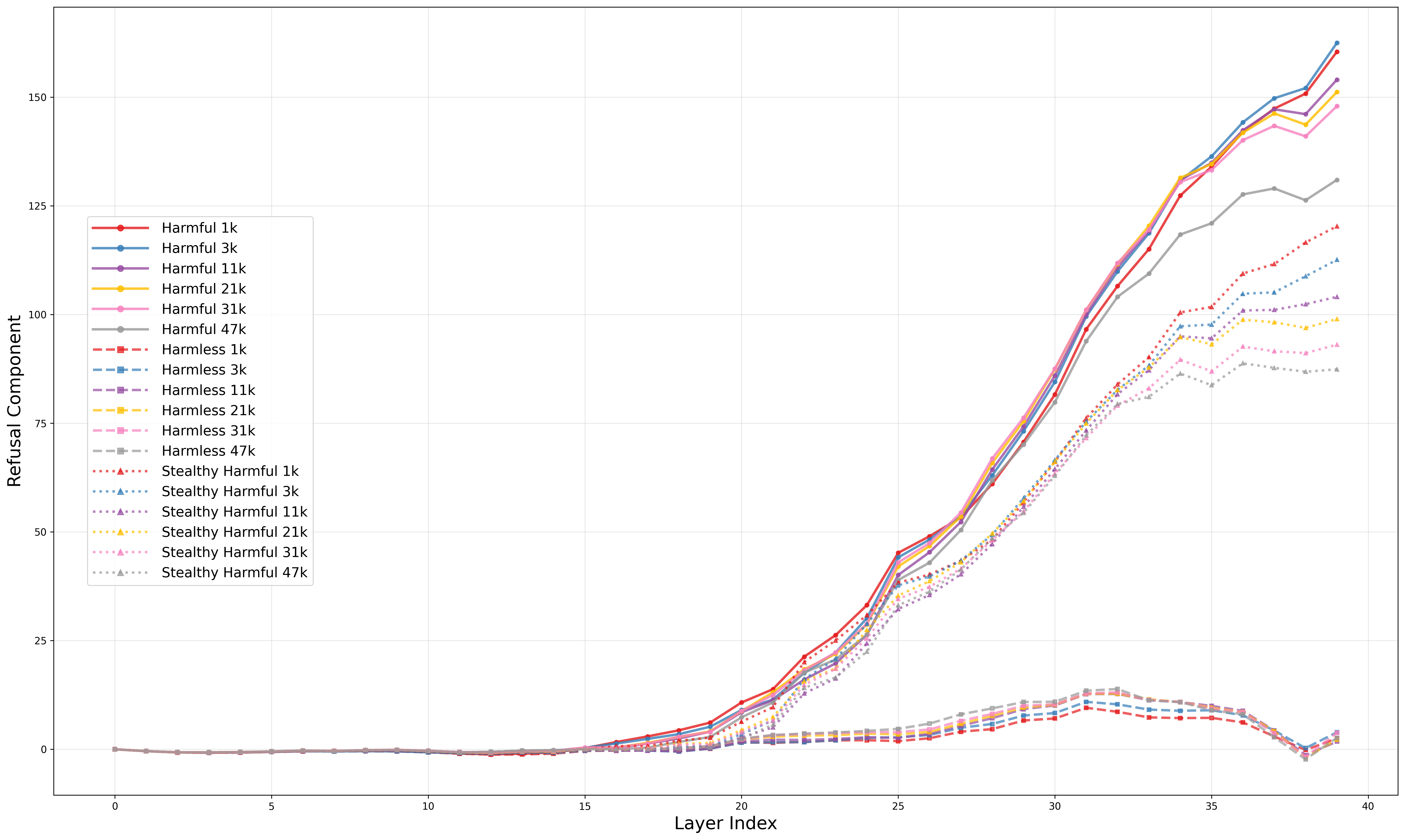
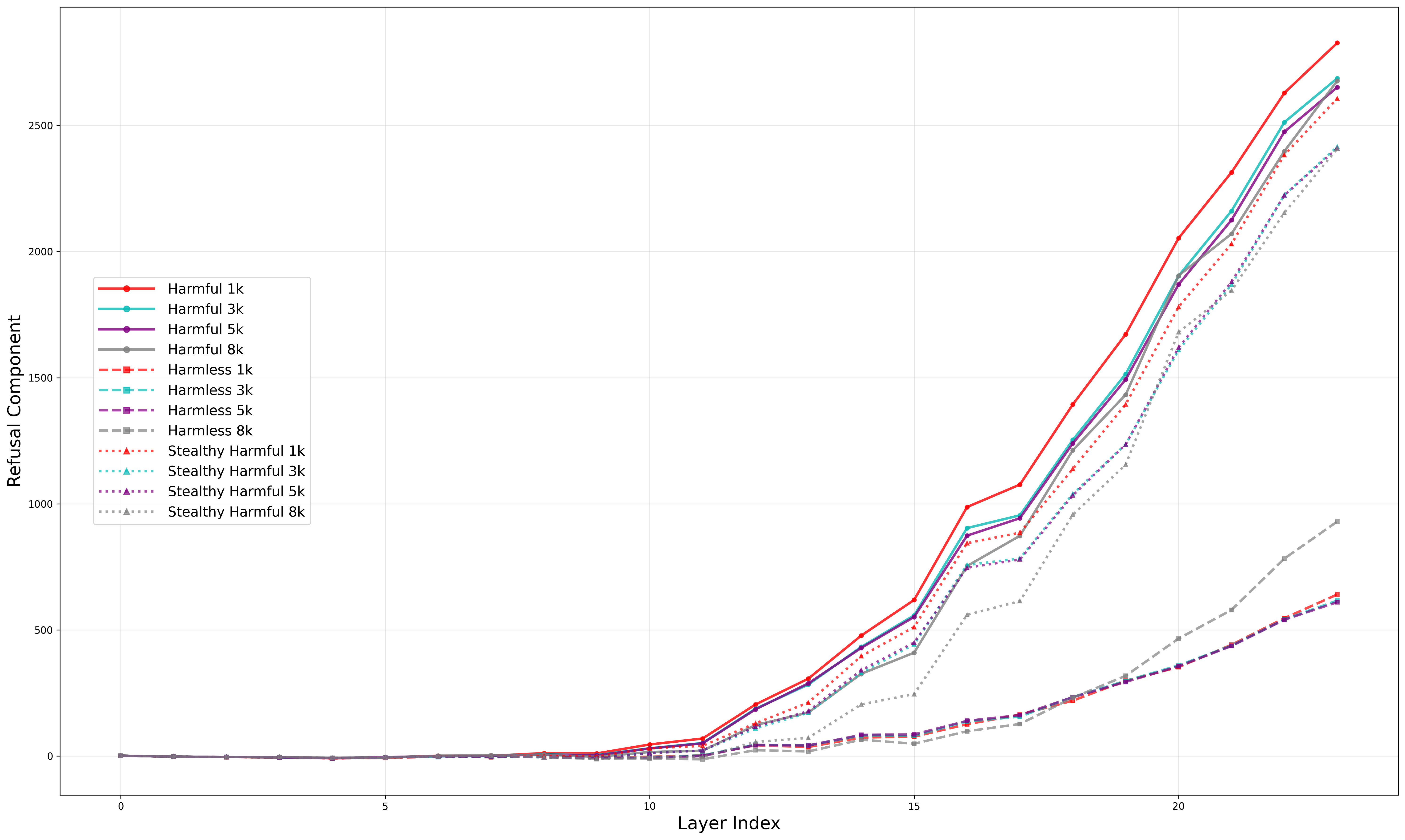
- CoT length: The number of tokens or steps in a chain-of-thought reasoning sequence. "We begin with a controlled experiment on the S1 model (simplescaling/s1-32B) \citep{s1} to test whether CoT length systematically affects refusal reliability."
- Deep-layer heads: Attention heads located in later layers of a transformer model. "Ablating 6 deep-layer heads (layer 23--35)."
- Direction Ablation: Removing a specific behavioral direction in activation space to study its effect. "Direction Ablation"
- Final-answer cue: A prompt instruction that focuses the model on producing the final answer, often weakening safety checks. "such as ``Finally, give the answer:''."
- Guardrails: Built-in safety mechanisms that prevent harmful outputs. "ablating the refusal direction disables guardrails almost entirely: ASR rises from 11\% to 91\% with the DeepSeek judge."
- HarmBench: A benchmark dataset for evaluating jailbreak and harmful content generation. "Across HarmBench, CoT Hijacking reaches a 99\%, 94\%, 100\%, and 94\% attack success rate (ASR) on Gemini 2.5 Pro, GPT o4 mini, Grok 3 mini, and Claude 4 Sonnet, respectively"
- H-CoT: A jailbreak method that exploits safety reasoning in chain-of-thought. "60\% for H-CoT \citep{kuo2025h}"
- Jailbreak: An attack that bypasses a model’s safety mechanisms to elicit harmful content. "We introduce Chain-of-Thought Hijacking, a jailbreak attack on reasoning models."
- JailbreakBench: A dataset for evaluating jailbreak prompts and safety behaviors. "All evaluations use the JailbreakBench dataset, with substring matching and DeepSeek-v3.1 as judges (see Appendix~\ref{app:judge})."
- Judge model: An external model used to assess whether outputs are refusals or harmful. "For each condition, we report the attack success rate (ASR) using chatgpt-4o-mini as the judge model."
- KL-divergence constraints: A regularization criterion using Kullback–Leibler divergence to limit distributional shifts during interventions. "selected based on ablation scores, steering effectiveness, and KL-divergence constraints."
- Large Reasoning Models (LRMs): LLMs that allocate extra inference-time compute to generate and use reasoning traces. "Large reasoning models (LRMs) achieve higher task performance by allocating more inference-time compute"
- Logits: Pre-softmax scores representing unnormalized probabilities over tokens. "white-box methods directly alter the parameters~\citep{sun2024iterative}, activations~\citep{li2025revisiting}, logits~\citep{guo2024cold}, or modify the prompt with gradient information~\citep{zou2023universal}."
- Low-dimensional safety signal: A compact feature in activations that drives refusal behavior. "Our results show that refusal relies on a fragile, low-dimensional safety signal that becomes diluted as reasoning grows longer."
- Malicious-Educator benchmark: An evaluation setup where apparent educational framing exposes safety reasoning that can be hijacked. "Our work is related to H-CoT by \cite{kuo2025h}, where they hijacks visible safety chain-of-thought using the Malicious-Educator benchmark."
- Mechanistic analysis: A study of causal, internal mechanisms explaining model behaviors. "To understand the effectiveness of our attack, we turn to a mechanistic analysis"
- Mechanistic interpretability: Linking internal model representations to behaviors in a causal and interpretable way. "Mechanistic interpretability builds a causal connection between the internal representation and the behavior of LLMs."
- Mousetrap: A baseline jailbreak method used for comparison. "44\% for Mousetrap \citep{chao2024mousetrap}"
- Payload: The harmful request embedded within the larger prompt. "Payload + final-answer cue: the harmful request, followed by a short instruction such as ``Finally, give the answer:''."
- PoisonBench: A benchmark highlighting vulnerabilities from poisoned training data. "Our work complements red-teaming and adversarial robustness efforts such as PoisonBench \citep{fu2024poisonbench}"
- Probes: Diagnostic tools (often linear classifiers) that measure the presence of features in activations. "using attention patterns, probes, and causal interventions to show dilution of refusal features."
- Red-teaming: Stress-testing models with adversarial inputs to uncover safety weaknesses. "Our work complements red-teaming and adversarial robustness efforts such as PoisonBench \citep{fu2024poisonbench}"
- Reinforcement learning with verifiable rewards (RLVR): Training that uses rewards validated by external checks or proofs to improve reasoning. "reinforcement learning with verifiable rewards (RLVR)~\citep{lambert2024tulu}"
- Residual activations: The intermediate representation in the residual stream used to compute next-token logits. "we quantify refusal behavior by projecting residual activations onto the refusal direction vector."
- Refusal component: A scalar projection of activations onto the refusal direction, measuring the safety check strength. "We refer to as the refusal component: a scalar signal representing the modelâs safety check at that position."
- Refusal direction: A specific activation-space direction separating refusal from compliance signals. "we compute a refusal direction by contrasting mean activations on harmful versus harmless instructions."
- Refusal dilution: The weakening of refusal signals when benign reasoning dominates the context. "We call this effect refusal dilution."
- Reasoning-effort settings: Configuration that controls how much reasoning the model performs before answering. "We further test CoT Hijacking on GPT-5-mini with reasoning-effort settings (minimal, low, high) on 50 HarmBench samples."
- Role-play context: A prompting strategy that frames the model in a persona to bypass safety checks. "creating a role-play context~\citep{ma2024visual}"
- Safety subnetwork: A sparse set of components (e.g., attention heads) responsible for safety behaviors. "Targeted ablations of attention heads identified by this analysis causally decrease refusal, confirming their role in a safety subnetwork."
- Steering effectiveness: A measure of how well an intervention moves model behavior in a desired direction. "selected based on ablation scores, steering effectiveness, and KL-divergence constraints."
- Stealthy harmful: Harmful instructions designed to appear benign or less obviously unsafe. "three instruction types (harmless, harmful, stealthy harmful)."
- Substring matching: A judging method that detects target phrases by matching substrings in outputs. "All evaluations use the JailbreakBench dataset, with substring matching and DeepSeek-v3.1 as judges"
- System-1 thinking: Fast, intuitive processing characteristic of standard LLMs. "Traditional LLMs~\citep{touvron2023llama1,touvron2023llama2,dubey2024llama3} rely on intuitive and fast system-1 thinking~\citep{frankish2010dual,li2025system}."
- System-2 thinking: Slow, deliberate, step-by-step reasoning emphasized by large reasoning models. "a surge of large reasoning models has been proposed, focusing on enhancing system-2 thinking ability, or slow, step-by-step thinking with chain-of-thoughts~\cite{wei2022chain,wang2022towards,shaikh2022second}."
- White-box methods: Attacks that modify or inspect a model’s parameters or internals. "white-box methods directly alter the parameters~\citep{sun2024iterative}, activations~\citep{li2025revisiting}, logits~\citep{guo2024cold}, or modify the prompt with gradient information~\citep{zou2023universal}."
Collections
Sign up for free to add this paper to one or more collections.