DiG: Differential Grounding for Enhancing Fine-Grained Perception in Multimodal Large Language Model
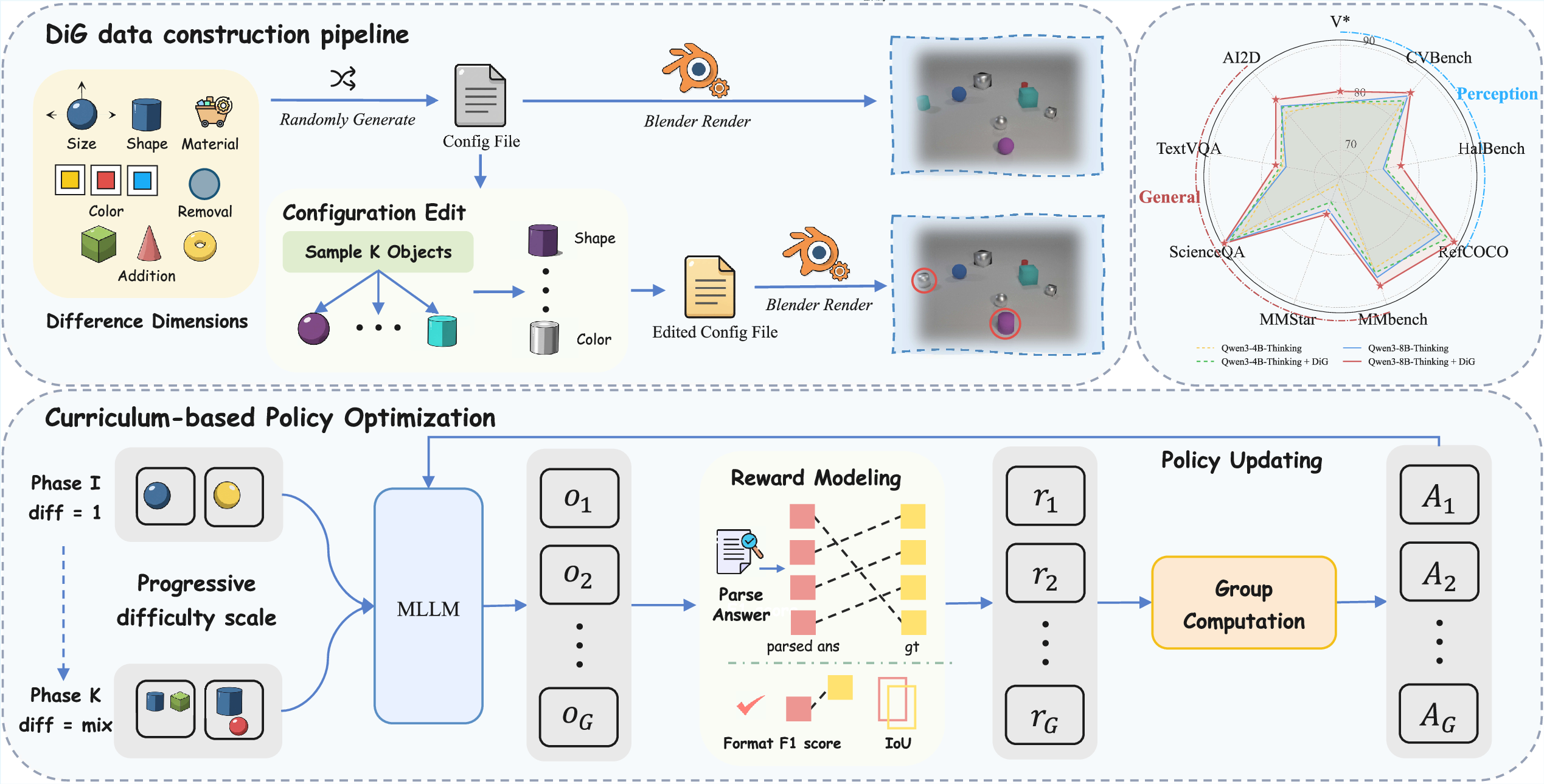
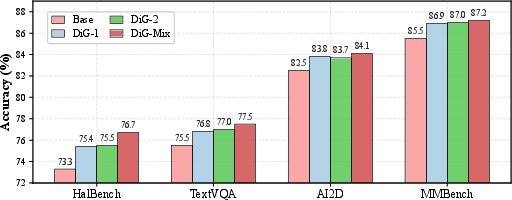
Abstract: Multimodal LLMs have achieved impressive performance on a variety of vision-language tasks, yet their fine-grained visual perception and precise spatial reasoning remain limited. In this work, we introduce DiG (Differential Grounding), a novel proxy task framework where MLLMs learn fine-grained perception by identifying and localizing all differences between similar image pairs without prior knowledge of their number. To support scalable training, we develop an automated 3D rendering-based data generation pipeline that produces high-quality paired images with fully controllable discrepancies. To address the sparsity of difference signals, we further employ curriculum learning that progressively increases complexity from single to multiple differences, enabling stable optimization. Extensive experiments demonstrate that DiG significantly improves model performance across a variety of visual perception benchmarks and that the learned fine-grained perception skills transfer effectively to standard downstream tasks, including RefCOCO, RefCOCO+, RefCOCOg, and general multimodal perception benchmarks. Our results highlight differential grounding as a scalable and robust approach for advancing fine-grained visual reasoning in MLLMs.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.