- The paper introduces a training-free approach for zero-shot 6D object pose estimation using geometric filtering and foundation model features.
- It achieves sub-second inference on a commodity GPU by bypassing expensive training, offering competitive accuracy in real-time robotic applications.
- Ablation studies confirm that optimizing template sampling and applying a Weighted Alignment Error metric significantly enhance performance, even in cluttered scenes.
Overview of Geo6DPose: Fast Zero-Shot 6D Object Pose Estimation
Geo6DPose presents a novel approach in the field of 6D object pose estimation, targeting zero-shot scenarios while prioritizing efficiency and practicality in robotic applications. Unlike large pretrained models that suffer from latency and compute demands, Geo6DPose offers a training-free pipeline that capitalizes on geometric filtering strategies and visual features from foundation models to deliver competitive accuracy with real-time capabilities.
Methodology
Geo6DPose employs a streamlined approach combining static visual features and geometric filtering, bypassing expensive training steps. The onboarding phase involves rendering pose templates from CAD models offline, where DINO descriptors and 3D patch coordinates are extracted. At inference, segmentation masks are used to crop input frames, and mutual correspondences are established in 3D, leveraging feature similarity and RANSAC for pose hypothesis generation. The final candidate pose is determined by a metric that weights geometric alignment precision against spatial support, addressing clutter and partial visibility effectively.
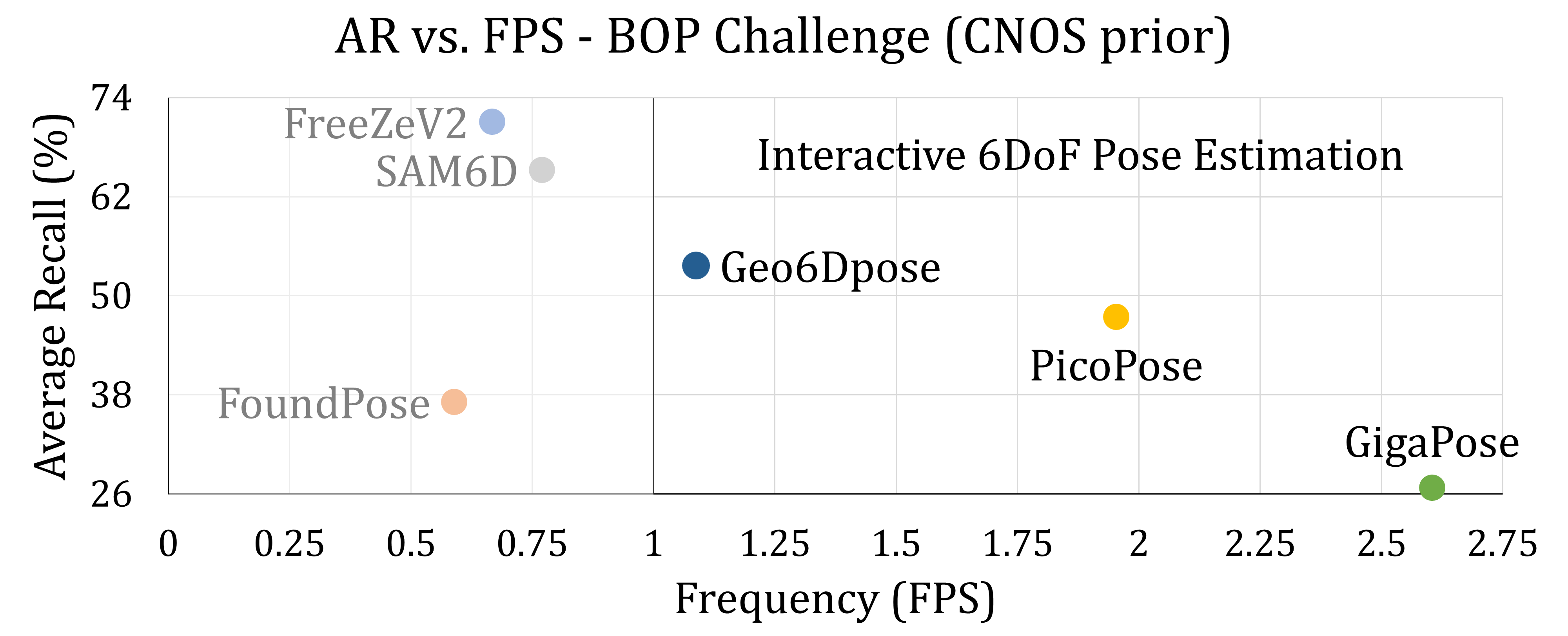
Figure 1: Geo6DPose compared against state-of-the-art zero-shot 6D pose estimation methods using CNOS as the localization prior.
This method ensures sub-second inference on a single commodity GPU, achieving high accuracy without requiring network access or fine-tuning. The pipeline sustains adaptability to evolving backbone models, broadening its utility in dynamic robotic environments.
Experiments and Results
The experimental evaluation of Geo6DPose adhered to the BOP Challenge protocols, assessing the model's performance on diverse datasets. These evaluations reveal Geo6DPose's capability to achieve high average recall across various domains, outperforming many real-time capable training-based models, as illustrated in the accompanying figure.
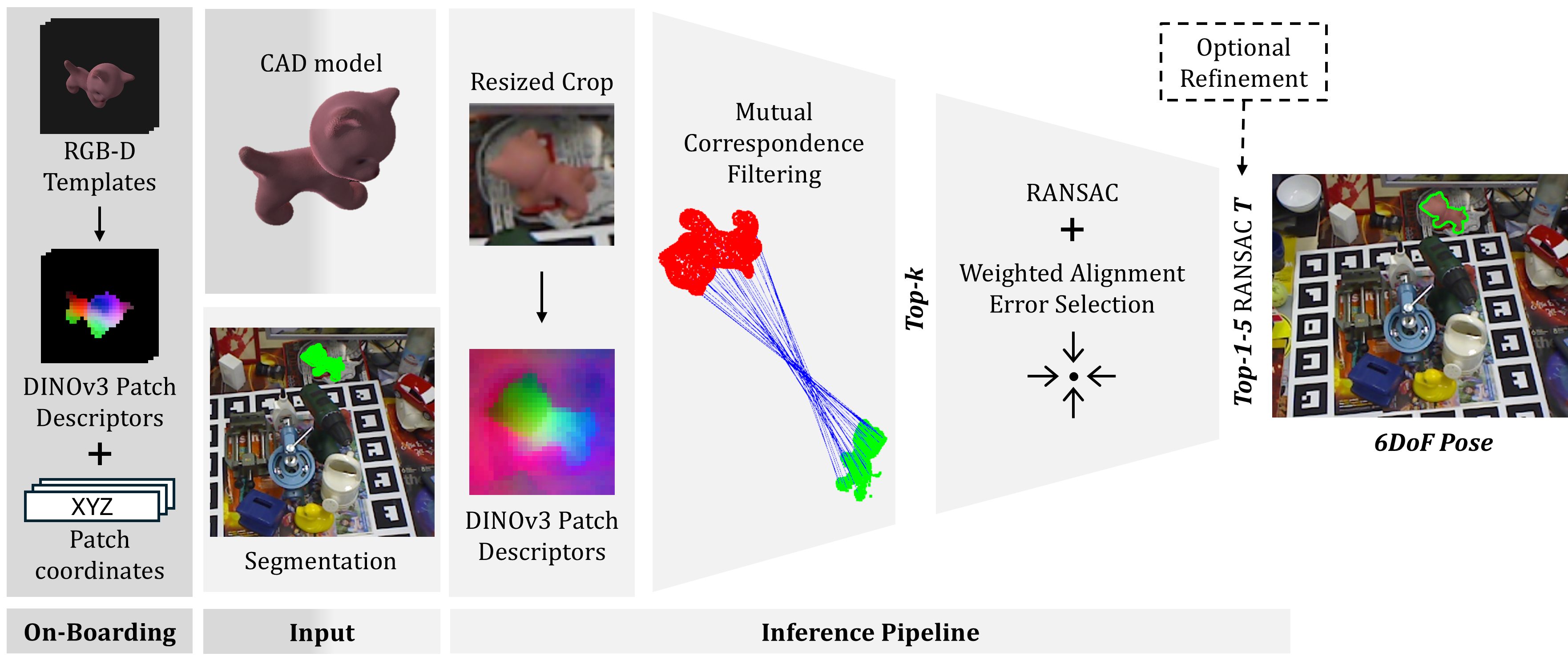
Figure 2: Geo6DPose pipeline. The onboarding stage is executed offline: given a CAD model, pose templates are rendered, and DINO patch descriptors are extracted.
Ablation studies highlight the efficiency improvements by optimizing feature extraction, fine-tuning template sampling density, and streamlining correspondence filtering stages. Notably, the implementation of a Weighted Alignment Error (WAE) metric enhanced pose selection criteria, providing robust performance without significant computational overhead.
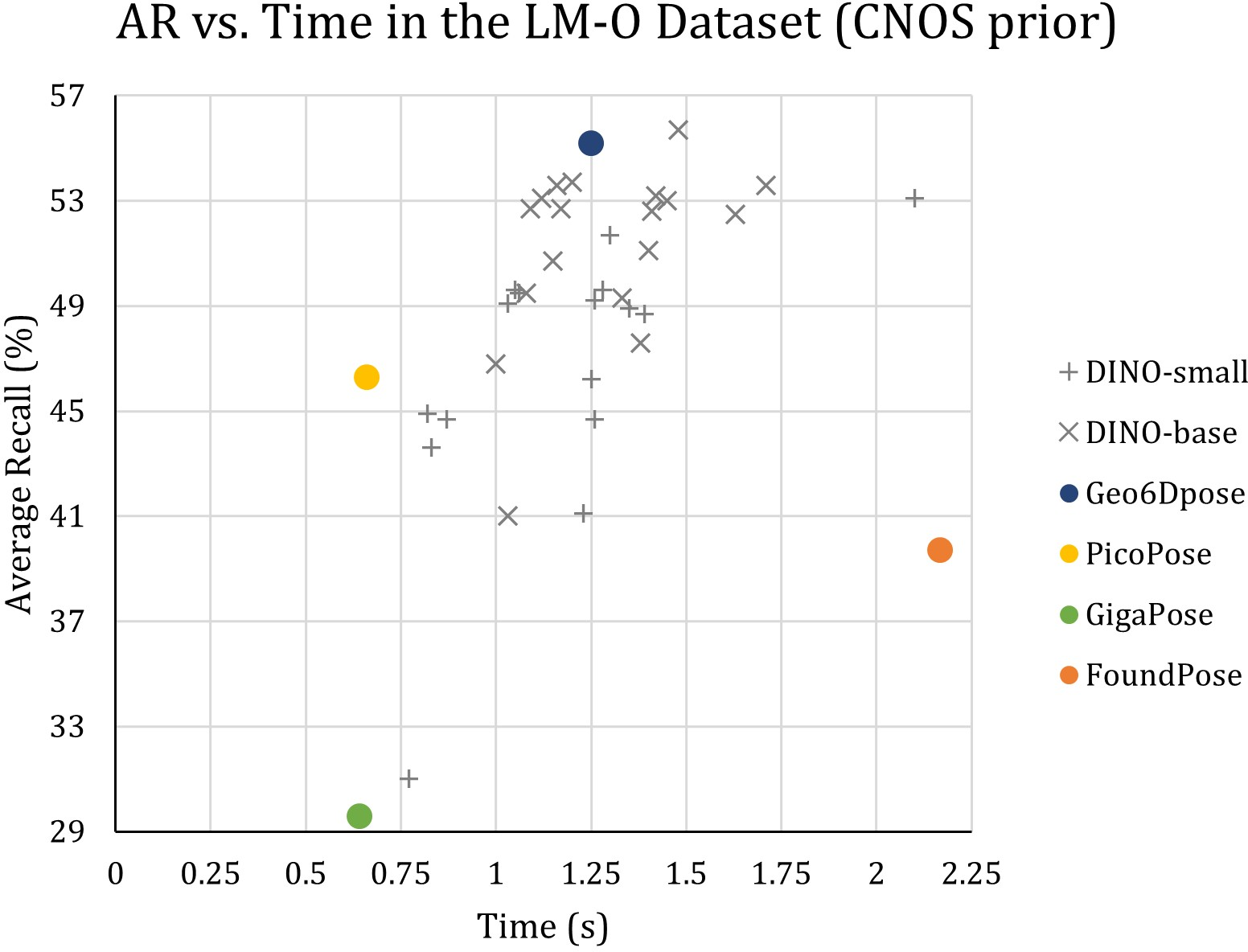
Figure 3: Geo6Dpose ablation studies showcasing performance trade-offs and optimization paths considered during development.
Implications and Future Directions
Geo6DPose fills a critical gap in zero-shot 6D object pose estimation by demonstrating that effective geometric filtering can compensate for the absence of exhaustive training. Its real-time execution and full adaptability make it a strong candidate for deployment in vision-based robotic applications, potentially inspiring further research into training-free methods.
While Geo6DPose currently excludes a learned refinement stage, expanding this framework to incorporate efficient real-time refinement poses an intriguing future research avenue. Further, translating these innovations to support articulated robotic systems and real-time environments will likely broaden its influence in AI-driven robotics.
Conclusion
Geo6DPose represents a forward-thinking approach to zero-shot object pose estimation, harmonizing high precision with computational efficiency. By harnessing foundation models and geometric reasoning without the burden of extensive training, Geo6DPose sets a new benchmark for practical, on-device inference in the domain of robotic vision applications.

