- The paper presents a unified framework for 6D object pose estimation that integrates transformer-based feature extraction with explicit 3D geometric encoding.
- It utilizes DINOv2 foundation features refined through a Weight Adapter and extends 2D RoPE to 3D, enhancing template-image correspondence and matching robustness.
- Experimental results on BOP benchmarks demonstrate state-of-the-art accuracy and efficiency, notably in model-free scenarios via NeRF-based onboarding.
Introduction and Problem Setting
The paper "OPFormer: Object Pose Estimation leveraging foundation model with geometric encoding" (2511.12614) presents a unified framework for 6D object pose estimation, tackling both model-based and model-free paradigms. The core challenge addressed is robust pose estimation in scenarios where target objects may be entirely novel, not covered during training, and where either a 3D CAD model or only a collection of multi-view images is available. Such requirements are crucial for scalable robotic manipulation, augmented reality, and other applications that demand efficient onboarding of unseen objects.
Traditional approaches often rely on object-specific training or assume CAD model availability, limiting their generalization capability. OPFormer overcomes these limitations with a versatile onboarding process and a transformer-based architecture which leverages large-scale vision foundation models (specifically, DINOv2) coupled with explicit 3D geometric encoding.
Pipeline Overview
OPFormer comprises three main components: rapid object onboarding, robust 2D detection, and transformer-driven pose estimation.
Upon receiving either a CAD model or a set of multi-view images with annotated poses, the onboarding module generates a suite of geometric-aware templates—specifically, RGB, depth, and NOCS (Normalized Object Coordinate Space) maps. For cases lacking CAD models, high-fidelity neural object representations are synthesized using an efficient NeRF pipeline.
Given a test RGB image, the CNOS detector produces object crops. Pose estimation proceeds as a correspondence search between image features and generated templates. The architecture harnesses the representation power of DINOv2, refined through a custom Weight Adapter (WA), and a transformer encoder that bridges semantic and geometric knowledge using cross-template attention and 3D-aware positional encoding.
Figure 1: Pipeline schematic: Onboarding from a CAD model or image set (with NeRF training if necessary), template rendering, feature extraction using ViT-L DINOv2, geometric embedding with NOCS, and 6D pose estimation via transformer and PnP.
Weight Adapter (WA)
The WA module is critical for adapting DINOv2's multi-layer patch descriptors. By aggregating the outputs of all 24 transformer layers and processing them via dilated convolutions, the module enhances local context capture and generates robust, high-capacity feature maps suitable for template-image correspondence. This fusion achieves superior representation versus single-layer selection or non-adaptive pooling.
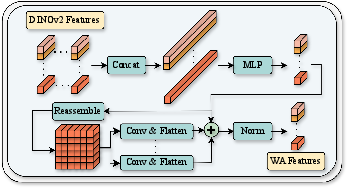
Figure 2: WA module—dimensionality reduction and enrichment through dilated convolutions and summation across layers.
Encoder and 3D Rotary Positional Embedding
Template features are passed to a transformer encoder which, unlike classical methods that examine each view in isolation, jointly encodes all template views. To impart geometric priors and positional awareness, descriptors are augmented with 3D-coordinate embeddings based on NOCS. The authors extend 2D Rotary Position Embedding (RoPE) to 3D: query and key vectors in self-attention are rotated in subspaces determined by local X, Y, Z NOCS coordinates before forming attention scores, ensuring that the encoder internalizes object geometry alongside appearance.
Decoder and Bi-directional Matching
The decoder stacks self-attention on image descriptors and deploys double cross-attention: templates-to-image and image-to-templates. By constructing 2D-3D correspondences via cosine similarity of normalized descriptors, robust inlier filtering is performed using a dual-softmax mutual nearest-neighbor scheme. This process selects the optimal template and its six neighbors; a RANSAC-based PnP solver yields the 6D pose.
Training Regime
The approach uses large-scale synthetic data, rendering 2M+ images from GSO and ShapeNet models, to train using a contrastive patch-level loss—balancing template-image and image-template sampling. Critically, focal loss is employed to emphasize hard negatives, and positive matches are selected to allow for symmetries and ambiguities common in pose estimation. The architecture is frozen with DINOv2 weights, and the rest is trained with AdamW to convergence.
Experimental Results
OPFormer is evaluated on BOP benchmarks for both model-based and model-free (NeRF-based) tasks. The method achieves state-of-the-art or competitive performance in both accuracy and efficiency, demonstrating:
- Near-SOTA average recall (AR) scores on multi-dataset benchmarks, e.g., 56.8 AR on BOP Core datasets, rivaling or surpassing Co-op [moon2025co], FoundPose [ornek2024foundpose], GigaPose [nguyen2024gigaPose], and others while being consistently the fastest among top methods.
- When provided with only images and not CAD models, the method sets a new baseline for model-free 6D object detection, demonstrating robustness of the NeRF onboarding and geometric encoding pathway.
- The architecture generalizes effectively across diverse datasets, including textureless, symmetric, and heavily cluttered scenes.
Qualitative results confirm accurate alignment of predictions with ground-truth in both 2D projections and 3D visualizations.








Figure 3: HANDAL dataset—2D projection overlays for predicted 6D poses and segmentation masks.









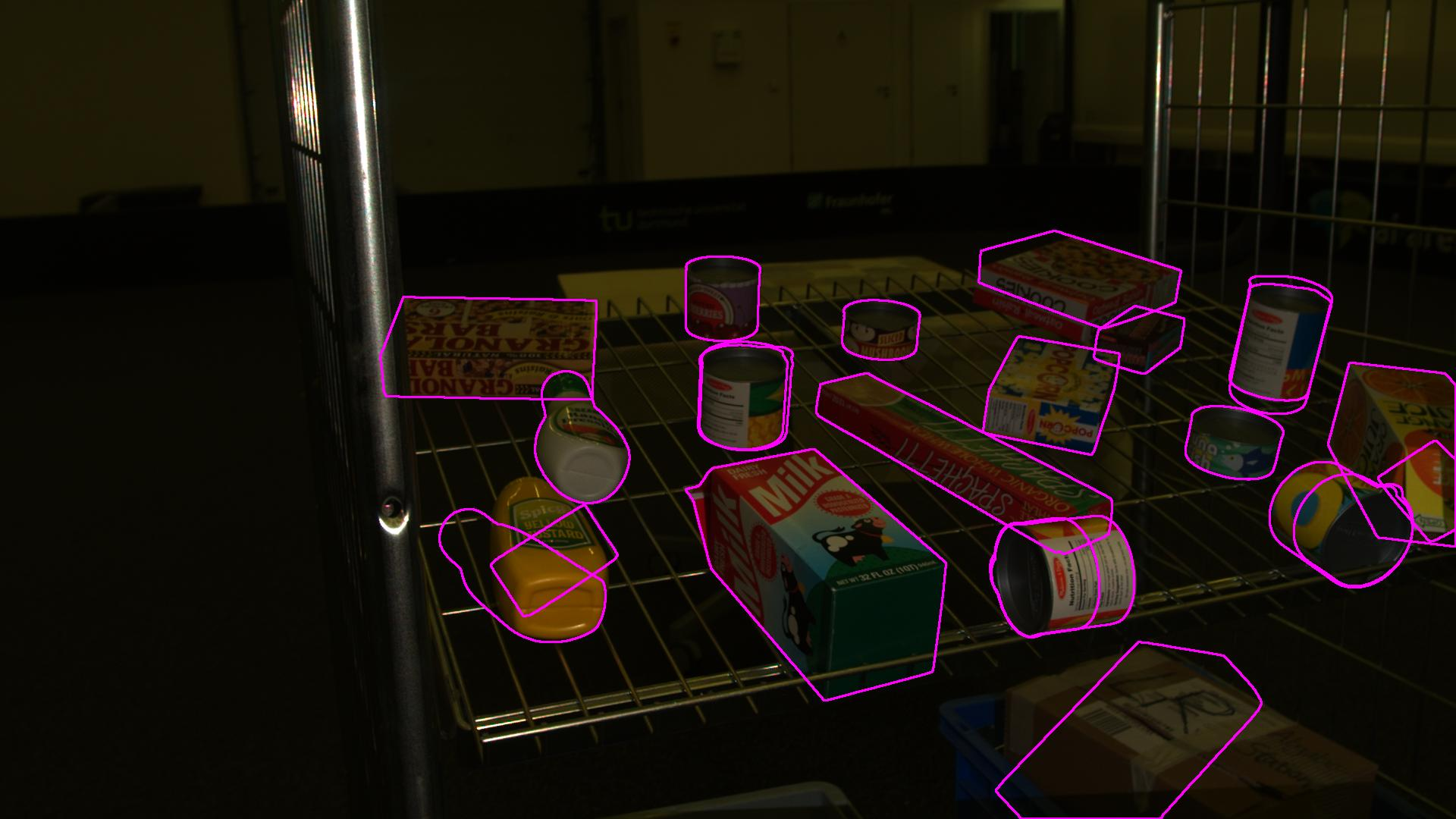
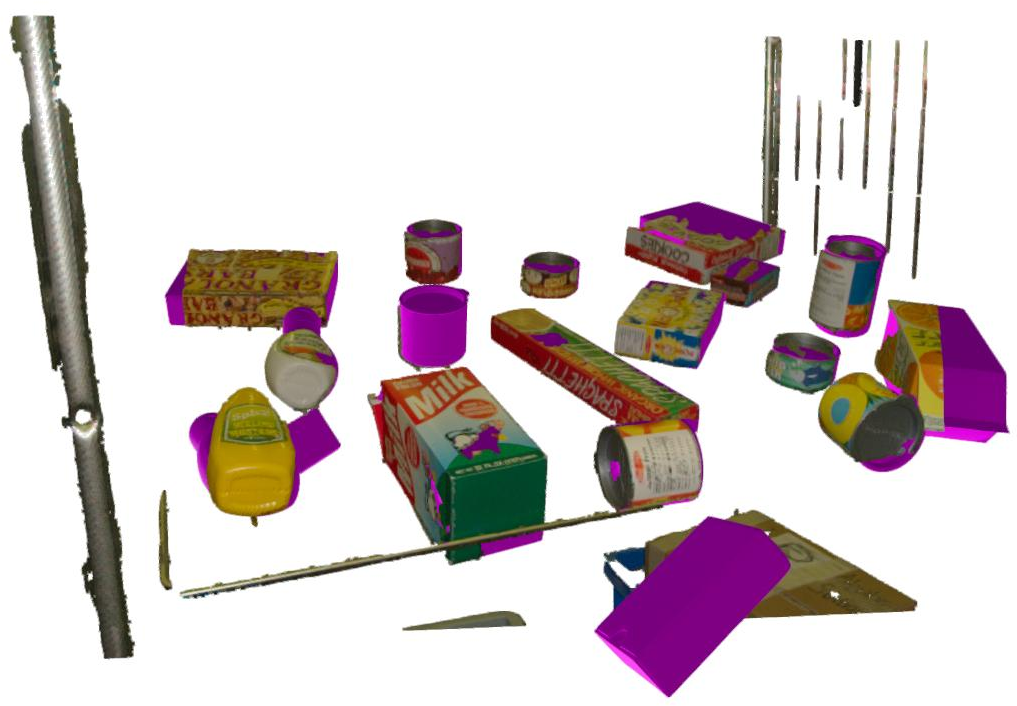
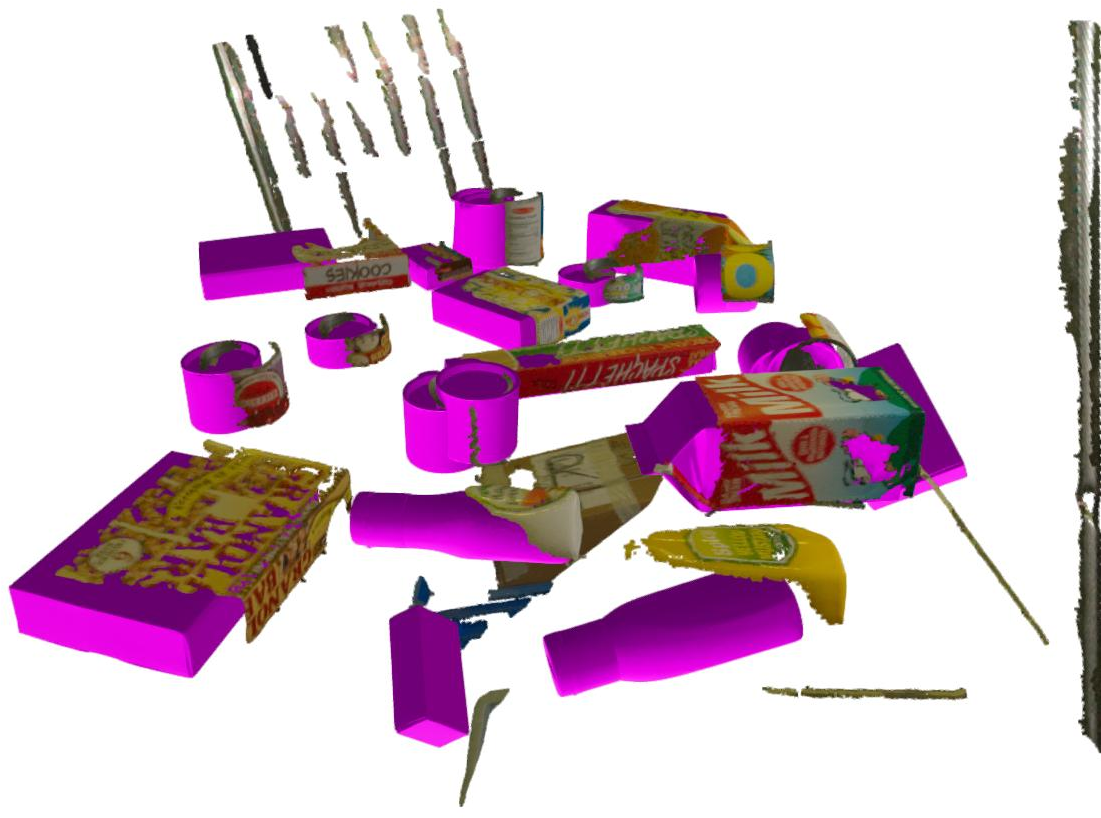



Figure 4: HOPEv2 dataset—3D visualization of predicted mesh alignment under varied viewpoints.
Ablative Analysis
A detailed ablation study deconstructs the architectural choices:
- The WA module's multi-layer and multi-dilation aggregation notably improves descriptor quality for textureless or symmetrical objects.
- Joint encoding across templates (as opposed to per-template isolation) is essential for high-recall matching.
- The 3D RoPE positional embedding improves matching robustness without introducing additional trainable parameters compared to prior works' pointnet-style embeddings.
- A bi-directional decoder further boosts performance, confirming the utility of context propagation between image and template streams.
Inference-time parameters such as template count, neighbor inclusion, and image resolution display predictable trade-offs between computational load and recall.
Limitations and Discussion
Main failure modes arise from errors in the initial 2D detection (bounding box or object class misidentification) and the inherent ambiguity in textureless or symmetric objects, which produces ill-conditioned correspondence fields. Model-free NeRF onboarding is sensitive to the quality and completeness of multi-view image inputs.
Despite these, OPFormer demonstrates that high-accuracy 6D pose estimation is feasible at practical speeds for both model-based and model-free scenarios, substantially narrowing the gap towards deployable, scalable object pose pipelines.
Implications and Future Directions
The OPFormer architecture bridges foundation models with explicit geometric priors for instance-level object pose estimation, significantly relaxing the dependency on object-specific training and CAD models. Its efficiency and robustness position it as a strong candidate for real-world, dynamic object onboarding pipelines required in industrial, AR, and robotics settings.
Future work may include:
- Integrating improved open-vocabulary 2D detectors to further reduce catastrophic failure cases from the detection stage.
- Exploring multi-view or temporal extensions to resolve remaining ambiguities for symmetric or textureless objects.
- Automatic adaptation of NeRF training and geometry refinement for better model-free onboarding under poor image conditions.
Conclusion
OPFormer demonstrates that transformer-based models augmented with foundation visual features and explicit 3D geometric encoding can achieve robust, accurate, and efficient 6D object pose estimation with minimal prior object knowledge. The architecture’s modular onboarding, high-capacity feature extraction, and geometric reasoning represent substantive steps towards practical, scalable solutions for robotic perception and other computer vision applications requiring rapid adaptation to novel objects.
References:
- "OPFormer: Object Pose Estimation leveraging foundation model with geometric encoding" (2511.12614)
- "Co-op: Correspondence-based Novel Object Pose Estimation" [moon2025co]
- "FoundPose: Unseen Object Pose Estimation with Foundation Features" [ornek2024foundpose]
- "GigaPose: Fast and Robust Novel Object Pose Estimation via One Correspondence" [nguyen2024gigaPose]
- "DINOv2: Learning Robust Visual Features without Supervision" [oquab2023dinov2]

