SingRef6D: Monocular Novel Object Pose Estimation with a Single RGB Reference
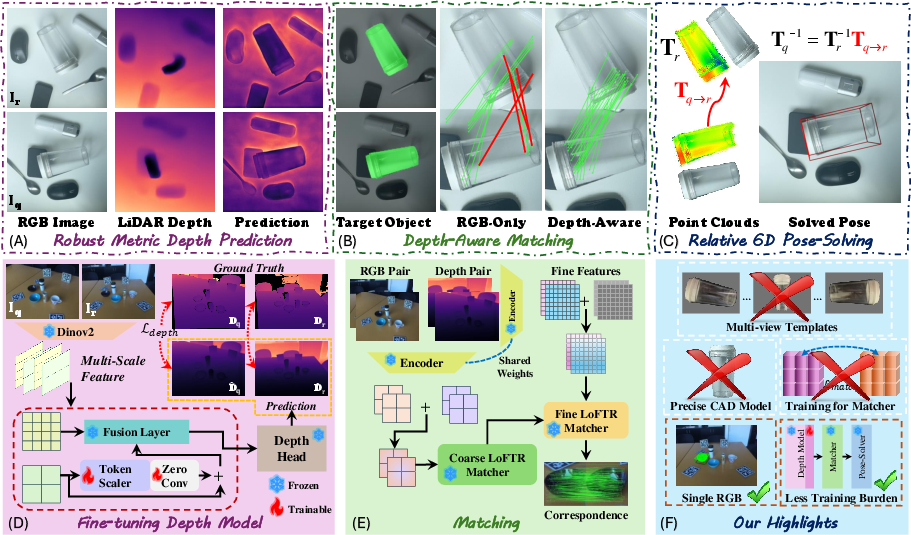
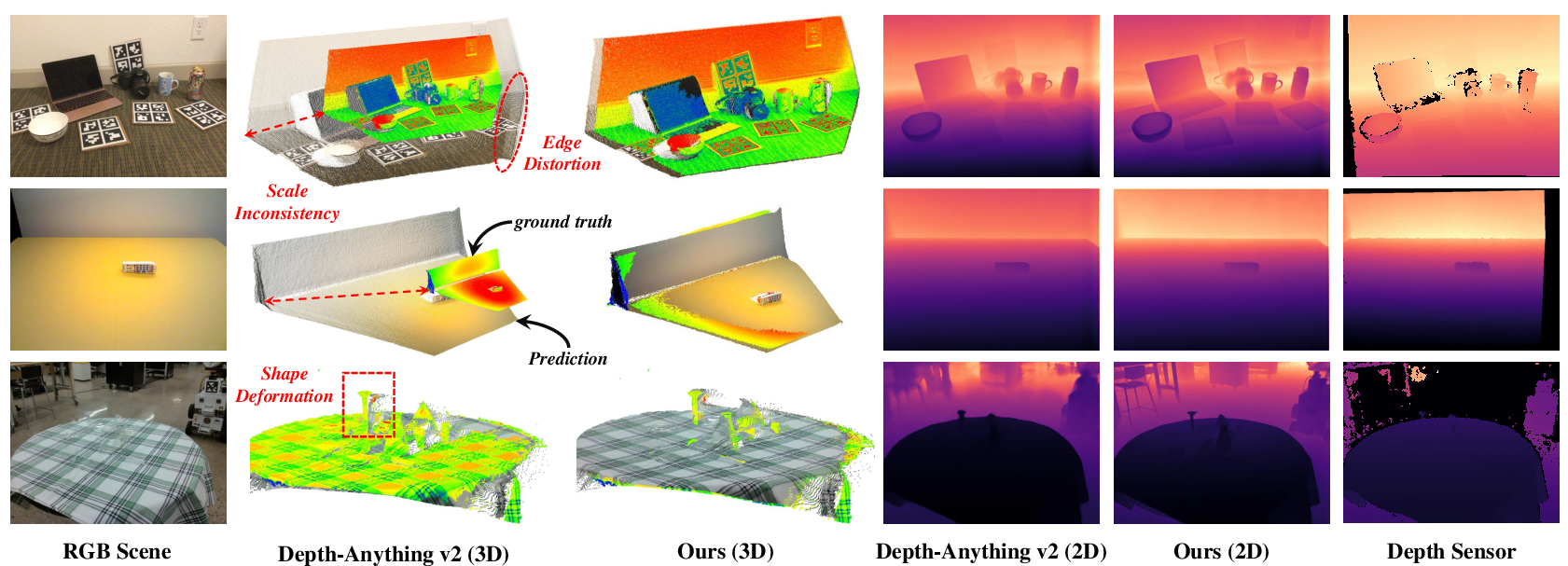
Abstract: Recent 6D pose estimation methods demonstrate notable performance but still face some practical limitations. For instance, many of them rely heavily on sensor depth, which may fail with challenging surface conditions, such as transparent or highly reflective materials. In the meantime, RGB-based solutions provide less robust matching performance in low-light and texture-less scenes due to the lack of geometry information. Motivated by these, we propose SingRef6D, a lightweight pipeline requiring only a single RGB image as a reference, eliminating the need for costly depth sensors, multi-view image acquisition, or training view synthesis models and neural fields. This enables SingRef6D to remain robust and capable even under resource-limited settings where depth or dense templates are unavailable. Our framework incorporates two key innovations. First, we propose a token-scaler-based fine-tuning mechanism with a novel optimization loss on top of Depth-Anything v2 to enhance its ability to predict accurate depth, even for challenging surfaces. Our results show a 14.41% improvement (in $\delta_{1.05}$) on REAL275 depth prediction compared to Depth-Anything v2 (with fine-tuned head). Second, benefiting from depth availability, we introduce a depth-aware matching process that effectively integrates spatial relationships within LoFTR, enabling our system to handle matching for challenging materials and lighting conditions. Evaluations of pose estimation on the REAL275, ClearPose, and Toyota-Light datasets show that our approach surpasses state-of-the-art methods, achieving a 6.1% improvement in average recall.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of issues the paper leaves unresolved or only partially addresses. Each point is phrased to guide actionable follow-up work.
- Dependence on object masks: the pipeline assumes access to reliable object segmentation (e.g., SAM). The impact of mask noise, partial masks, or missed detections on pose accuracy is not quantified. Robustness to imperfect masks (e.g., via mask erosion/dilation, IoU sweeps) and mask-free localization strategies remain open.
- Sensitivity to reference selection: guidelines and experiments on how the chosen single reference view (viewpoint, scale, lighting, background) affects success rates are missing. Automated reference selection or reference augmentation policies are unexplored.
- Viewpoint gap limits: while depth priors aim to expand the effective view space, the maximum tolerable reference–query pose gap (e.g., rotation/translation/scale differences) is not systematically characterized.
- Occlusion robustness: performance under varying levels/types of occlusion (self-occlusion vs. external, partial vs. heavy) is not studied. Active occlusion handling (e.g., occlusion-aware matching or completion) is an open problem.
- Symmetric object ambiguity: the method does not explicitly model or resolve pose ambiguities for symmetric objects. Strategies for symmetric-aware matching and hypothesis disambiguation are not explored.
- Camera intrinsics and cross-camera generalization: requirements for known/unknown intrinsics are not made explicit, and cross-device generalization of metric scale is untested. How well the metric depth scale transfers across cameras with different intrinsics/sensors is unclear.
- Cross-domain generalization: fine-tuning uses dataset-specific supervision; robustness to domain shifts (outdoor scenes, different materials, sensors, extreme lighting, motion blur, HDR, noise) is not evaluated.
- Transparent/reflective materials: despite improvements, performance on ClearPose remains modest. How to further handle non-Lambertian effects (e.g., refractive distortions) without violating the single-RGB constraint is open (e.g., polarization cues, learned refraction compensation).
- Depth label quality and sparsity: training on datasets with missing/invalid ground-truth depth (especially for transparent objects) is under-specified. Handling incomplete/noisy supervision (e.g., confidence-aware losses, masked losses) is not addressed.
- Depth uncertainty: predicted depth is treated deterministically. Uncertainty estimation and its use in matching/registration (e.g., uncertainty-weighted correspondence selection, robust solvers) is unexplored.
- Depth–RGB fusion design: the current additive latent fusion with a frozen
LoFTRmay be suboptimal. Alternatives (cross-attention between RGB/depth streams, learnable fusion, fine-tuning the matcher end-to-end, 3D positional encodings) are not investigated. - Pose solver sensitivity: reliance on
PointDSCis not compared to alternative estimators (e.g., TEASER++, robust PnP variants, generalized ICP). Sensitivity to outliers, correspondence density, and initializations remains unquantified. - Error propagation analysis: there is no end-to-end uncertainty/error budget tracing from segmentation → depth → matching → registration. Methods to detect/predict failure and calibrate confidence of the final pose are missing.
- Runtime and deployment metrics: while parameter/GFLOP counts are reported for matchers, full pipeline latency, throughput (FPS), and memory on representative CPUs/edge GPUs are absent. Power/latency trade-offs for real-time robotics use remain unknown.
- Absolute scale fidelity: translation accuracy hinges on metric depth scale. The relationship between depth scale errors and 6D translation errors (across distances and scenes) is not analyzed, nor are scale correction strategies (e.g., scene-level constraints) explored.
- Multi-object, cluttered scenes: beyond per-object ROI cropping, robustness to distractors, similar instances, and heavy clutter is not assessed. Failure modes due to background structures at similar depth are not quantified.
- Reference–query device mismatch: effects of capturing the reference with a different camera/device than the query (intrinsics/spectral response/noise characteristics) are unstudied.
- Training data efficiency: data–performance scaling is only partially explored. Minimal supervision needed for useful performance, and the role of self-/weak supervision or synthetic data for the token scaler remain open.
- Token-scaler design space: ablations focus on losses and a few FT paradigms; a broader study on where/how to insert scalers, model capacity, and alternative re-weighting architectures (e.g., low-rank adapters, gating) is missing.
- Failure in extreme darkness: the method fails when RGB contains little signal. Lightweight strategies for low-light robustness (e.g., denoising, exposure fusion, learned enhancement) are not investigated.
- Handling texture-less planar objects and repeated patterns: explicit stress tests for these challenging cases are absent; techniques like geometric priors or global shape constraints are not examined.
- Articulated and deformable objects: the approach targets rigid objects; extensions to articulated or deformable targets (and corresponding evaluation) are left open.
- Symmetry- and pose-consistent evaluation: while ADD(S) is reported, a deeper analysis of ambiguous-pose metrics and pose distributions for symmetric classes is missing.
- Reference-free or weakly supervised localization: integrating VLMs for localization is mentioned as future work, but no concrete pipeline or evaluation with noisy text prompts or open-vocabulary settings is provided.
- Scalability and memory for large catalogs: although per-object CAD is avoided, scalability to many concurrent objects/references and memory management for reference descriptors are not discussed.
- Robustness to mask–depth misalignment: potential misalignment between segmentation boundaries and depth discontinuities (and its impact on correspondence quality) is not analyzed; boundary-aware matching remains open.
- Choice of fusion stage(s): only one latent fusion strategy is evaluated; comparing early vs. mid vs. late fusion (and multi-stage fusion) for depth-aware matching is an open design question.
Collections
Sign up for free to add this paper to one or more collections.