- The paper introduces a unified, regression-based framework that estimates an object's 6D pose, size, and dense shape from a single RGB-D image without relying on templates or CAD models.
- It leverages dense semantic features from a vision foundation model fused with segmented 3D point clouds, using a Transformer with Mixture-of-Experts to achieve real-time inference at 28 FPS.
- Experiments on synthetic and real-world datasets demonstrate state-of-the-art performance, robust generalization to unseen categories, and superior Chamfer-L1 shape reconstruction.
Category-Agnostic 6D Object Pose, Size, and Shape Estimation from a Single View
Introduction and Motivation
This work addresses the longstanding challenge of estimating an object's 6D pose, size, and shape from a single RGB-D image in a category-agnostic manner, without reliance on templates, CAD models, or category labels at inference. The proposed framework is motivated by the need for scalable, real-time, and generalizable solutions in robotics and embodied AI, where open-set environments and novel object categories are the norm. Prior approaches either depend on object-specific priors or suffer from limited generalization due to pose–shape entanglement and multi-stage pipelines. This paper introduces a unified, regression-based architecture that fuses dense 2D semantic features from vision foundation models with partial 3D point clouds, processed via a Transformer encoder augmented by a Mixture-of-Experts (MoE) module. The model jointly predicts 6D pose, size, and dense shape in a single forward pass, achieving real-time inference at 28 FPS.
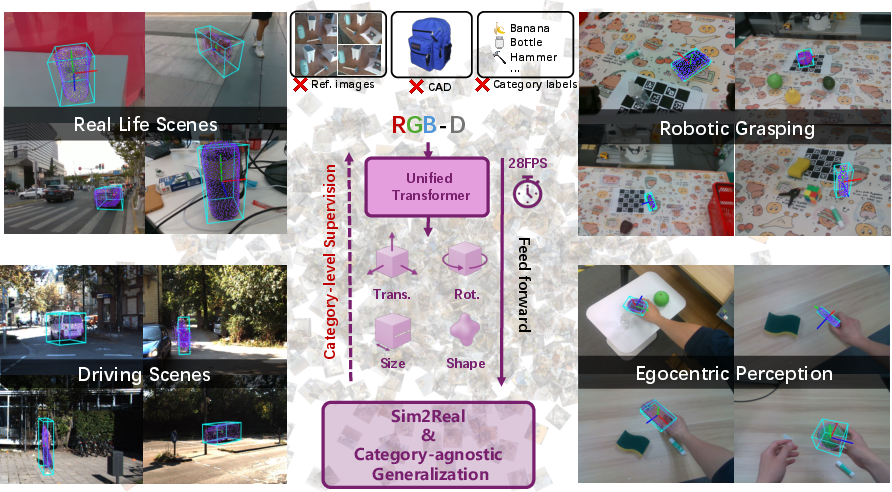
Figure 1: Results on diverse domain datasets using the end-to-end regression-based framework, demonstrating strong generalization to unseen object categories across multiple real-world domains.
Methodology
Feature Extraction and Fusion
The framework leverages RADIOv2.5, a vision foundation model, to extract dense, SE(3)-consistent semantic features from RGB input. These features are fused point-wise with 3D coordinates from the segmented point cloud, following DenseFusion principles. The fused representation is processed by a DGCNN encoder, yielding keypoint-aware object tokens.
Object tokens are passed through a stack of Transformer blocks, where standard feed-forward layers are replaced by MoE modules. Each MoE layer conditionally activates a subset of expert networks, enabling scalable specialization across diverse shape distributions. This design enhances modeling capacity and inference efficiency, supporting robust generalization to novel object categories.
Multi-Task Decoding Heads
The global object representation is decoded via parallel branches:
- Pose and Size Estimation: Direct regression of rotation (using a continuous 6D representation for stability), translation, and scale.
- Shape Reconstruction: Coarse shape prediction via MLP, followed by confidence-guided fusion with the input point cloud and local folding for dense reconstruction.
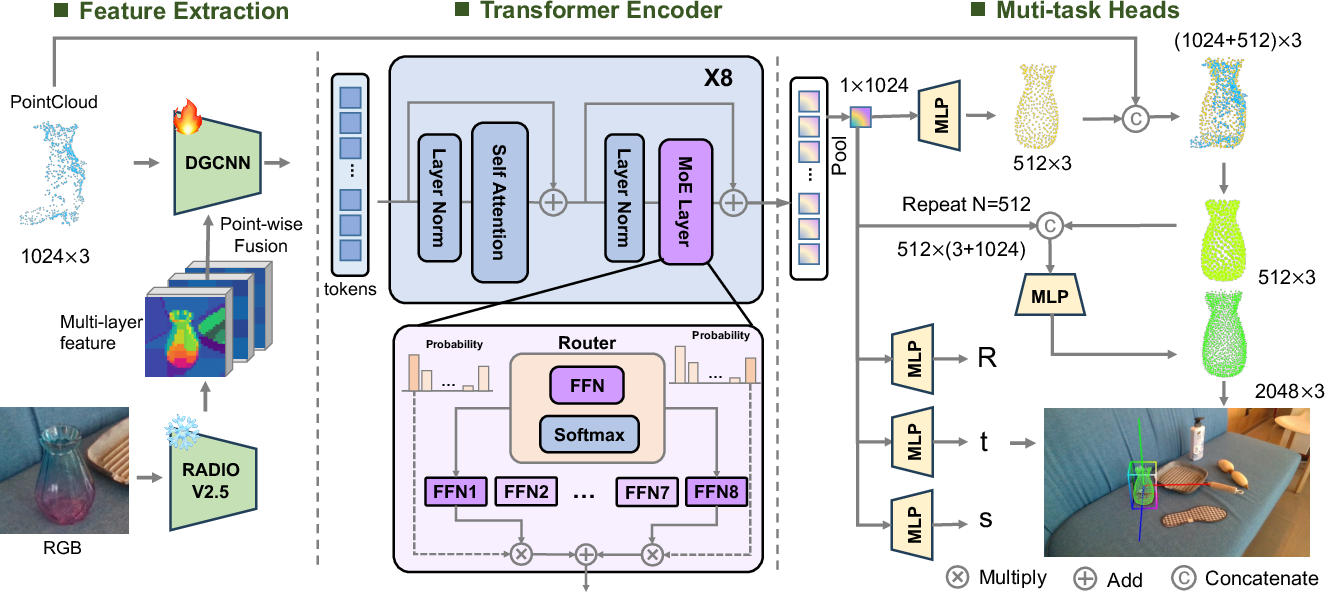
Figure 2: Framework overview, illustrating the fusion of cropped RGB image features and segmented point cloud, followed by DGCNN, Transformer+MoE, and parallel decoders for pose–size and shape.
Loss Functions
The training objective integrates:
- Chamfer Distance (L1) for coarse and dense shape reconstruction.
- Smooth L1 loss for pose and size regression, with symmetry-aware rotation loss to handle ambiguous ground truths.
- All loss coefficients are set to 1, yielding stable training without the need for manual balancing.
Experimental Results
Benchmarks and Metrics
The model is trained exclusively on synthetic SOPE data (149 categories) and evaluated on SOPE, ROPE, ObjaversePose, and HANDAL, spanning 300+ categories and synthetic-to-real transfer. Metrics include AUC of 3D bounding box IoU, VUS (joint rotation/translation thresholds), mean rotation/translation errors, and Chamfer-L1 for shape fidelity.
- SOPE (Synthetic, Seen Categories): Achieves 56.4 AUC@IoU25, outperforming GenPose++ (50.1), with lower mean rotation/translation errors and higher VUS.
- ROPE (Real, Seen Categories): 44.9 AUC@IoU25, surpassing all baselines, including reference-based methods.
- ObjaversePose (Synthetic, Unseen Categories): 42.2 AUC@IoU25 at 0% occlusion, nearly double GenPose++ (21.3), with robust performance under severe occlusion.
- HANDAL (Real, Unseen Categories): 33.0 AUC@IoU25, outperforming Any6D and GenPose++ in reference-free settings.
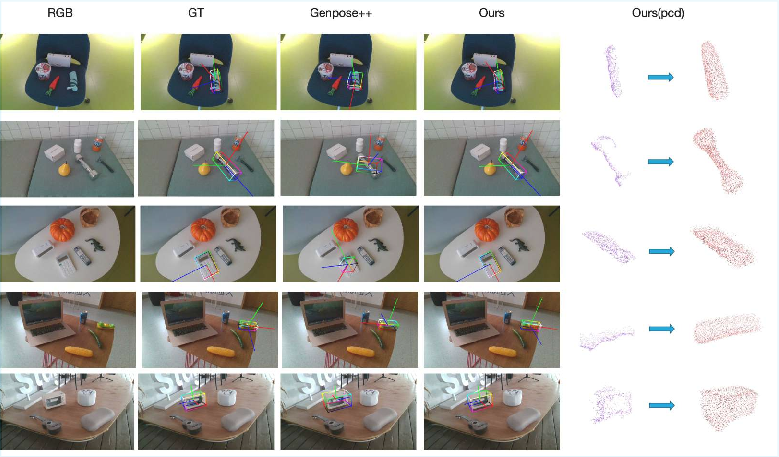
Figure 3: Qualitative results on ROPE, comparing input, ground-truth, GenPose++ predictions, and the proposed model’s outputs for pose and shape.
Shape Reconstruction
On SOPE, the model achieves a Chamfer-L1 error of 5.93×10⁻³, significantly lower than AdaPointr (24.41×10⁻³) and Pointr (29.87×10⁻³), demonstrating superior shape completion.
Ablation Studies
Implementation Details
- Backbone: Frozen RADIOv2.5-l for RGB features; DGCNN for point cloud encoding.
- Transformer: Geometry-aware attention in the initial layer; MoE with 2-in-8 expert activation for efficiency.
- Decoders: MLPs for pose, size, and shape; local folding for dense point cloud generation.
- Training: 50 epochs, batch size 128, AdamW optimizer, LambdaLR scheduler, AMP, and DDP on 4× RTX 4080 GPUs.
Practical and Theoretical Implications
The proposed framework demonstrates that category-agnostic, reference-free 6D estimation is feasible and effective, even when trained solely on synthetic data. The integration of foundation model features and MoE scaling enables strong generalization and real-time inference, making the approach suitable for deployment in robotics, AR, and embodied AI systems. The unified pipeline avoids error accumulation typical of multi-stage methods and supports robust shape completion under occlusion and domain shift.
Limitations and Future Directions
Performance is bounded by the diversity of training categories and may degrade on long-tail or atypical shapes. Fine-grained details and articulated/deformable objects are not fully addressed. Future work should focus on scaling to richer corpora (e.g., ObjaverseXL), advancing articulation/deformation modeling, and extending toward open-world, task-driven 6D understanding.
Conclusion
This paper presents a unified, category-agnostic framework for joint 6D pose, size, and shape estimation from a single RGB-D image, achieving state-of-the-art accuracy and strong generalization to unseen categories. The approach eliminates the need for templates, CAD models, or category labels at inference, supporting scalable and robust deployment in real-world applications. The results establish a new standard for open-set 6D understanding in robotics and embodied AI.
