- The paper introduces a comprehensive evaluation framework that decomposes agentic AI reliability into four distinct pillars: LLM, Memory, Tools, and Environment.
- The paper shows that traditional task completion metrics mask critical failures, such as sub-optimal memory recall and tool orchestration issues, with safety policy breaches.
- The paper demonstrates that pillar-specific evaluations and qualitative audits are essential for adaptive, risk-based monitoring of agentic AI systems in industrial CloudOps.
Assessment of Agentic AI Systems Beyond Task Completion
Introduction
The proliferation of agentic AI systems, which integrate LLMs with external tools, structured memory, and dynamic environments, introduces substantial complexity in evaluation relative to classical model-centric or deterministic software approaches. "Beyond Task Completion: An Assessment Framework for Evaluating Agentic AI Systems" (2512.12791) presents a rigorous, multi-faceted methodology to systematically analyze the operational reliability, behavioral alignment, and execution correctness of agent-based architectures in industrial CloudOps deployments. This work highlights the inadequacies of conventional task completion or tool invocation metrics, focusing instead on the runtime uncertainties and coordination failures that arise in complex, non-deterministic system integrations.
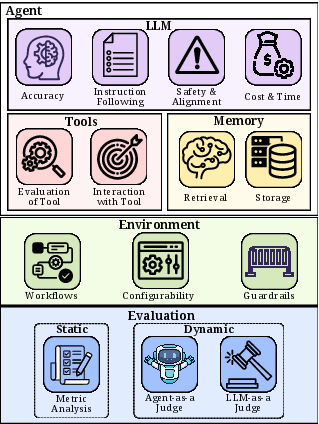
Figure 1: Agent Assessment Framework Overview, summarizing the four assessment pillars: LLM, Memory, Tools, and Environment.
Framework Architecture
The proposed Agent Assessment Framework delineates agent evaluation into four orthogonal pillars corresponding to primary uncertainty and failure modes: LLM (reasoning/retrieval), Memory (storage/retrieval), Tools (selection/orchestration), and Environment (workflows/guardrails). Each pillar is subject to static validation (property adherence, e.g., policy lookup pre-action), dynamic monitoring (runtime logs/traces for behavioral compliance), and judge-based qualitative assessment (LLM/Agent-as-Judge).
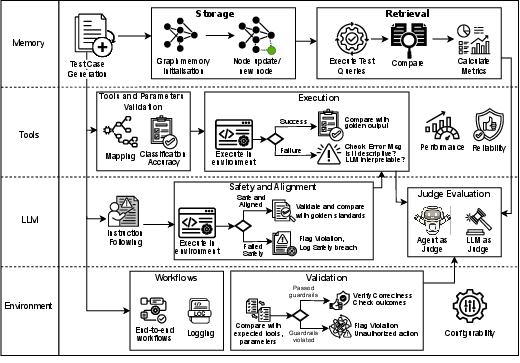
Figure 2: Detailed view of Agent Assessment Framework with modular metric definitions and assessment flows for each pillar.
Test cases, generated to cover both unit behaviors and cross-cutting operational flows, are automatically tailored per pillar, spanning instruction-following, safety, retrieval accuracy, tool sequencing, and environmental compliance. This enables controlled, reproducible experiments and direct attribution of behavioral failures.
Experimental Evaluation
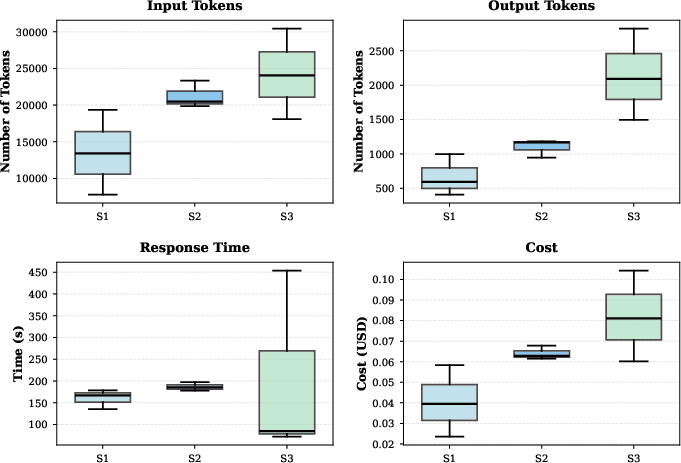
Validation is conducted within the MOYA agent framework, instrumented for CloudOps tasks (cost optimization, incident remediation, multi-agent RCA). The study contrasts baseline evaluations (task completion, tool usage ratios) against the pillar-specific framework. The framework surfaces substantive behavioral failures hidden by outcome-centric metrics: e.g., perfect tool sequencing with only 33% compliance to safety policies or extensive memory recall shortfalls in multi-hop/temporal queries.
Notable experimental findings include:
As for qualitative assessment protocols, LLM-as-Judge offers efficient, low-cost continuous evaluation ($14.7$\textrm{s}, $18$k tokens total per suite), while Agent-as-Judge underpins exhaustive pre-deployment audits (scaling to 62× execution time and 16× cost), with extensive capability and environment validation, surfacing subtle failures in reactive sequences and role handling.
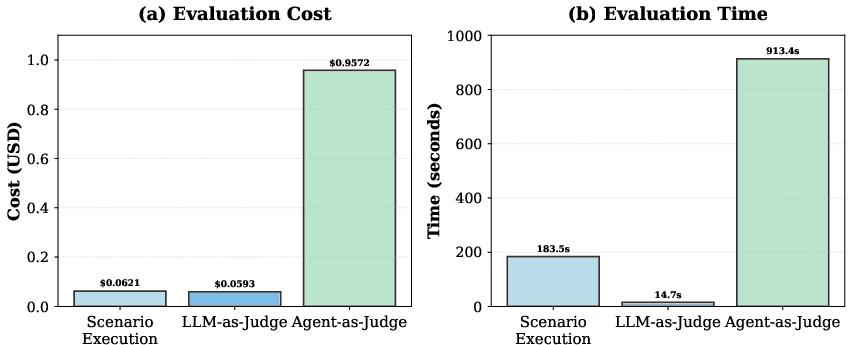
Figure 4: Evaluation overhead—time and cost comparison for LLM-as-Judge vs Agent-as-Judge protocols.
Theoretical and Practical Implications
This framework formally decomposes sources of runtime uncertainty and uncovers latent reliability and alignment failures that are inscrutable by summary metrics. Specifically,
- Task or outcome-based assessment is inadequate for production-grade deployments; agents can succeed in declared objectives while operationally violating critical policies, guardrails, or process flows, endangering safety and compliance.
- Tool orchestration and memory management are primary bottlenecks for agent reliability, advocating for design of defensive curriculum prompting and more advanced policy-abiding retrieval.
- The differentiation of qualitative (Judge-based) vs deterministic evaluations motivates risk-stratified, adaptive deployment policies, where continuous lightweight monitoring is augmented by episodic, intensive audits.
- The systematic ablation (pillar removal) study pinpoints major error sources for targeted improvements, directly informing tooling, orchestration, and context retention research priorities.
Limitations and Future Directions
While comprehensive in CloudOps, the presented framework's generalizability to domains involving creative synthesis, extended multi-turn planning, or high-dimensional real environments (e.g., robotics) is limited. Metrics focus primarily on memory/retrieval, tool orchestration, and environment guardrails; future measurement of observability granularity, recovery robustness, and concurrent decision making is required. Richer automated test generation from agent capability representations, and expansion to multimodal/multilingual agents, constitute important directions. Moreover, integrating the framework with online self-adaptive mechanisms may close the loop for continuous system improvement, leveraging pillar-based assessments to drive prompt and retrieval refinements.
Conclusion
"Beyond Task Completion: An Assessment Framework for Evaluating Agentic AI Systems" establishes a rigorous, multidimensional evaluation paradigm essential for reliable agentic AI deployment. The results confirm that agent performance, robustness, and safety cannot be assessed solely via outcome-based metrics; explicit, pillar-specific assessments are critical for surfacing and remediating complex, non-deterministic failures. This work provides a foundation for the next phase of agent system evaluation, emphasizing reproducibility, behavioral fidelity, and risk-aware assessment design.