- The paper introduces a probabilistic adaptation for VeRA, significantly enhancing model calibration and accuracy on benchmarks like VTAB-1k.
- The paper leverages multivariate normal distributions for stochastic sampling in each layer, effectively managing uncertainties during both training and inference.
- The paper demonstrates that PVeRA achieves robust out-of-distribution detection and uncertainty estimation with minimal computational overhead.
PVeRA: Probabilistic Vector-Based Random Matrix Adaptation
Introduction
The emergence of large foundation models has significantly advanced the capabilities of self-supervised learning (SSL) frameworks, enabling new frontiers in performance across diverse tasks. However, the computational expense and data requirements for fine-tuning such expansive models are prohibitive. The introduction of adapters offers a parameter-efficient solution, minimizing computational costs by attaching small trainable modules to frozen backbones. This paper presents PVeRA, a probabilistic variant of the VeRA adapter, leveraging probabilistic reformulations to enhance adaptability and manage input ambiguities.
Adapters, initially developed for NLP, have gained traction in adapting vision and multimodal models. LoRA, known for its low-rank adaptations, inspired subsequent methods like VeRA, which employ frozen random matrices for widespread sharing across layers. Unlike deterministic prior approaches, probabilistic deep learning introduces stochastic modeling in layers, as seen in variational autoencoders (VAEs). The probabilistic reformulation for adapters, although less explored, plays a crucial role in handling uncertainties.
Probabilistic Adaptation via PVeRA
The PVeRA adapter extends VeRA by incorporating a probabilistic dimension to the adaptation process. Standard low-rank adaptations, such as in LoRA, are modified to account for distributions of possible model adaptations rather than fixed vectors, introducing a probabilistic sampling mechanism. Each layer generates a multivariate normal distribution, allowing stochastic sampling during both training and inference stages, thereby capturing inherent model uncertainties.
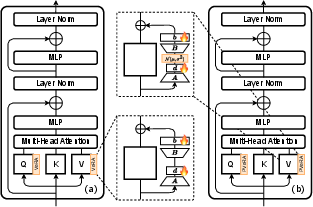
Figure 1: Representation of the VeRA and PVeRA architectures. (a) VeRA, (b) PVeRA: a probabilistic variation.
Experimental Evaluation
The PVeRA adapter's efficacy was assessed against its deterministic counterparts on the VTAB-1k benchmark, which evaluates parameter-efficient fine-tuning (PEFT) across diverse datasets. PVeRA demonstrated superior performance in terms of average accuracy, effectively maintaining well-calibrated outputs crucial for predicting confidence intervals and handling domain shifts. Its advantages manifest not solely in performance metrics but also in preserving the computational efficiency of VeRA's original design.
Results and Discussions
- Performance and Calibration: PVeRA not only excelled in achieving higher average accuracy but also outperformed conventional adapters in maintaining calibration, a critical aspect for real-world applications requiring reliable confidence measures.
- Computational Efficiency: While introducing only a marginal increase in computational requirements compared to VeRA, PVeRA benefits from its probabilistic nature without incurring additional inertia in inference time by merging weights.
- Uncertainty Estimation and Applications: The ability to sample adaptation weights probabilistically enables PVeRA to generate uncertainty estimates, facilitating applications in sensitive fields that demand robustness and dependability in predictions.
- Out-of-Distribution Detection and Latent Space Analysis: Analyzing the latent space adaptations enabled insights into PVeRA’s robust handling of distribution shifts, highlighting its potential for out-of-distribution detection and adaptive attention on significant image features.
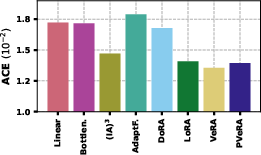
Figure 2: Average calibration performance of adapters. Average ACE across all datasets for all considered adapters. Lower is better.
Conclusion
PVeRA signifies a pivotal advancement in adapter methodologies, melding the robustness of probabilistic modeling with the versatility of low-rank adaptation strategies. Its utility spans enhanced calibration, adaptable uncertainty quantification, and computational parity with existing methods, positioning it as a versatile tool for diverse AI applications. Future explorations might extend PVeRA's framework beyond image classification to broader domains, accentuating its potential as a foundational AI adaptation tool.