Towards Higher Effective Rank in Parameter-efficient Fine-tuning using Khatri--Rao Product
Published 1 Aug 2025 in cs.LG, cs.CL, and cs.CV | (2508.00230v1)
Abstract: Parameter-efficient fine-tuning (PEFT) has become a standard approach for adapting large pre-trained models. Amongst PEFT methods, low-rank adaptation (LoRA) has achieved notable success. However, recent studies have highlighted its limitations compared against full-rank alternatives, particularly when applied to multimodal and LLMs. In this work, we present a quantitative comparison amongst full-rank and low-rank PEFT methods using a synthetic matrix approximation benchmark with controlled spectral properties. Our results confirm that LoRA struggles to approximate matrices with relatively flat spectrums or high frequency components -- signs of high effective ranks. To this end, we introduce KRAdapter, a novel PEFT algorithm that leverages the Khatri-Rao product to produce weight updates, which, by construction, tends to produce matrix product with a high effective rank. We demonstrate performance gains with KRAdapter on vision-LLMs up to 1B parameters and on LLMs up to 8B parameters, particularly on unseen common-sense reasoning tasks. In addition, KRAdapter maintains the memory and compute efficiency of LoRA, making it a practical and robust alternative to fine-tune billion-scale parameter models.
The paper introduces KRAdapter, a novel parameter-efficient fine-tuning method using the Khatri-Rao product to achieve full-rank weight updates and overcome limitations of LoRA.
It demonstrates that KRAdapter maintains computational efficiency while producing weight matrices with higher effective rank and improved generalization in both vision-language and language model tasks.
Empirical results show that KRAdapter outperforms existing methods in handling high-frequency components, OOD scenarios, and few-shot learning, providing robust model adaptation.
Khatri-Rao Adapters: Achieving High Effective Rank in Parameter-Efficient Fine-Tuning
Introduction
Parameter-efficient fine-tuning (PEFT) has become essential for adapting large pre-trained models in both vision and language domains. The dominant approach, Low-Rank Adaptation (LoRA), constrains weight updates to low-rank matrices, yielding substantial memory and compute savings. However, recent empirical and theoretical analyses reveal that LoRA's low-rank constraint can limit its ability to capture complex feature interactions, especially in multimodal and LLMs. This paper introduces KRAdapter, a novel PEFT method leveraging the Khatri-Rao product to construct full-rank weight updates with high effective rank, thereby overcoming the representational bottlenecks of LoRA and other PEFT alternatives.
Spectral Properties and Effective Rank in PEFT
The effective rank of a weight update matrix, defined as the entropy of its normalized singular value spectrum, is a critical indicator of its representational capacity. LoRA and its variants, while theoretically efficient, often produce matrices with rapidly decaying singular values, resulting in low effective rank and limited ability to model high-frequency or decorrelated features.
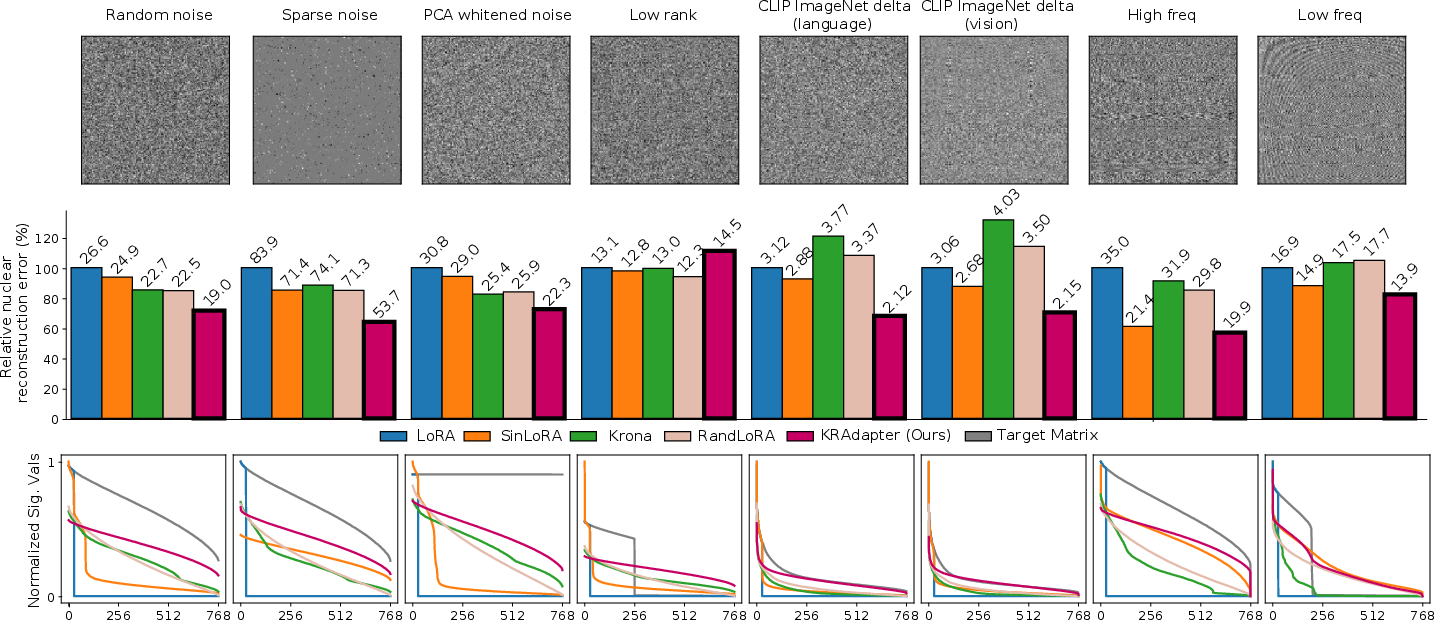
Figure 1: Visualization of the capacity of various PEFT methods to approximate the spectrum of different types of weight matrices. KRAdapter consistently achieves lower nuclear error and higher effective rank compared to LoRA and other full-rank alternatives.
KRAdapter, by construction, produces weight updates with a flatter singular value distribution and higher effective rank. This property is empirically validated across synthetic benchmarks and real-world fine-tuning scenarios, where KRAdapter outperforms LoRA, SinLoRA, RandLoRA, and Krona in approximating matrices with complex spectral characteristics.
Khatri-Rao Product Formulation and Parameter Efficiency
KRAdapter constructs the weight update ΔW for a linear layer as the Khatri-Rao product of two trainable matrices U∈Rk1×din and V∈Rk2×din, where k1k2=dout. The Khatri-Rao product, a column-wise Kronecker product, yields a matrix of size dout×din with full column rank almost surely when U and V are randomly initialized. The total number of trainable parameters is N=din(k1+k2), minimized when k1=k2=dout, matching the parameter efficiency of LoRA with typical rank settings.
KRAdapter maintains the computational and memory efficiency of LoRA, with negligible overhead in training time and VRAM usage. Initialization strategies (zero for U, Kaiming uniform for V) are empirically optimized for convergence.
Empirical Analysis: Matrix Approximation and Spectral Comparison
Controlled experiments on synthetic matrices with diverse spectral properties demonstrate that KRAdapter achieves lower mean squared error and nuclear norm reconstruction error than LoRA and other full-rank PEFT methods, except in strictly low-rank scenarios where LoRA is optimal. KRAdapter excels in approximating matrices with high-frequency components, decorrelated features, and realistic fine-tuned weight deltas from CLIP models.
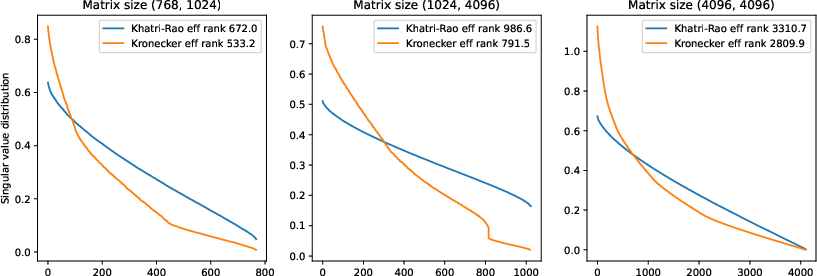
Figure 2: Comparison of singular value distribution and effective rank for Khatri-Rao vs. Kronecker product-based adapters. Khatri-Rao yields a smoother spectrum and higher effective rank for equivalent parameter budgets.
KRAdapter's superiority over Krona (Kronecker Adapters) is attributed to its more balanced singular value spectrum, as shown in direct SVD comparisons. This translates to improved generalization and robustness in downstream tasks.
Vision-Language and LLM Fine-Tuning
KRAdapter is evaluated on CLIP-based vision-LLMs (ViT-B/32, ViT-L/14, ViT-H/14) and LLMs (Llama3.1-8B, Qwen2.5-7B) across standard classification, VTAB1k, and commonsense reasoning benchmarks. In all cases, KRAdapter matches or exceeds the performance of LoRA and other full-rank PEFT methods, particularly in few-shot and out-of-distribution (OOD) settings.
KRAdapter consistently achieves higher effective rank in the attention layers post fine-tuning, as measured by the entropy of the singular value spectrum. This correlates with improved OOD generalization, as quantified by the rgen ratio (OOD/ID accuracy gain over zero-shot baseline).
Figure 3: Toy experiment visualizing the capacity of PEFT methods to reconstruct target matrices. KRAdapter achieves lower nuclear error across most matrix types, except for strictly low-rank targets.
Scaling Laws and Robustness
Ablation studies reveal that KRAdapter scales favorably with increased parameter budgets, maintaining or improving accuracy in larger models where LoRA and other full-rank methods saturate or degrade. KRAdapter's robustness to overfitting is evident in its stable performance across data regimes and model sizes.
Limitations
KRAdapter's minimum parameter count is higher than the most efficient LoRA configurations, making it less suitable for extreme resource-constrained scenarios. Its performance advantage diminishes when the target weight update is strictly low-rank, where LoRA remains optimal. In some in-distribution settings, RandLoRA may achieve marginally higher accuracy, but KRAdapter's generalization and training efficiency offset this minor delta.
Theoretical Implications and Future Directions
KRAdapter's full-rank guarantee and high effective rank construction provide a principled approach to overcoming the spectral limitations of low-rank PEFT. Theoretical analysis confirms that the Khatri-Rao product of random matrices achieves full column rank with high probability, enabling richer adaptation in high-dimensional parameter spaces.
Future work may explore low-rank approximations of the constituent matrices in KRAdapter to further reduce parameter count without sacrificing effective rank, though this may impact the full-rank guarantees. Extensions to other model architectures and modalities, as well as integration with spectral regularization techniques, are promising avenues.
Conclusion
KRAdapter represents a significant advance in parameter-efficient fine-tuning by leveraging the Khatri-Rao product to construct full-rank, high effective rank weight updates. It consistently outperforms LoRA and other PEFT methods in vision-language and LLM adaptation, especially in OOD and few-shot scenarios. KRAdapter maintains the computational efficiency of LoRA while providing superior representational capacity and generalization. The findings underscore the importance of spectral properties and effective rank in PEFT, guiding future research in scalable, robust model adaptation.