- The paper introduces InfoMosaic-Bench, a benchmark that evaluates multi-source tool integration in LLM agents using a two-stage organizer–worker synthesis pipeline.
- It shows that while incorporating domain-specific tools can improve performance in structured tasks, reliance on web search alone leads to inconsistent reasoning and lower accuracy.
- Experimental results highlight key failure modes and the need for enhanced agentic planning, tool selection, and orchestration to meet high-stakes domain requirements.
Motivation and Problem Statement
The paper introduces InfoMosaic-Bench, a benchmark designed to rigorously evaluate the multi-source information-seeking capabilities of tool-augmented LLM agents. The motivation stems from two critical limitations in current agentic systems: (1) over-reliance on open-web search, which is noisy and insufficient for high-stakes, domain-specific reasoning, and (2) the lack of systematic evaluation for agents' ability to integrate heterogeneous, domain-specific tools. The emergence of the Model Context Protocol (MCP) ecosystem enables access to thousands of specialized tools, but the field lacks a principled benchmark to assess whether agents can effectively leverage and orchestrate these resources.
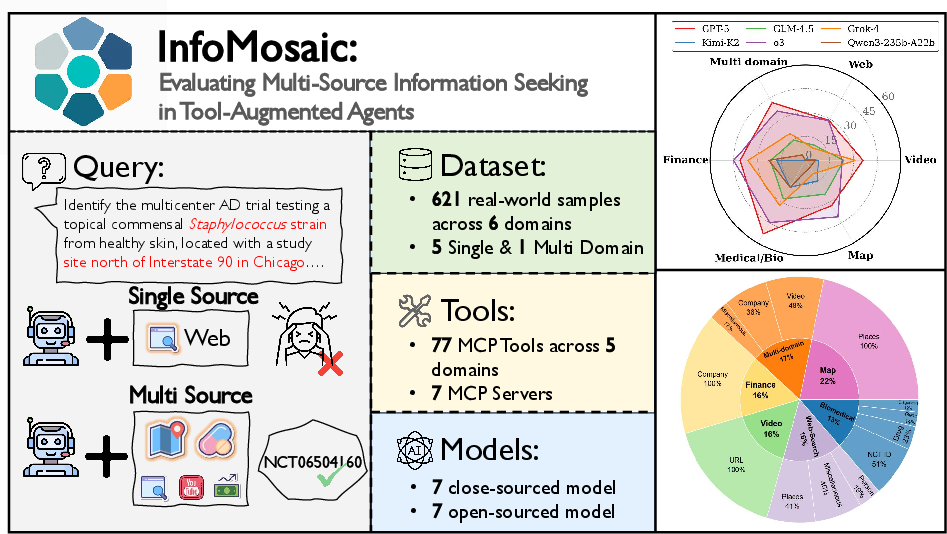
Figure 1: Overview of InfoMosaic-Bench, illustrating the necessity of multi-source tool use, dataset statistics, and domain-wise accuracy across models.
Benchmark Construction: InfoMosaic-Flow
The benchmark is constructed via InfoMosaic-Flow, a scalable agentic synthesis pipeline. The methodology employs an organizer–worker architecture: the organizer plans and decomposes tasks, while workers execute tool calls within specific domains. The pipeline proceeds in two stages:
- Stage 1: Information Seeking
The organizer generates multi-condition problems grounded in verified tool outputs, ensuring each task requires integration of evidence from multiple sources.
- Stage 2: Iterative Refinement
A refiner decomposes conditions and challenges a verifier (restricted to web search) to solve the task. Conditions are fuzzed and recomposed until the problem cannot be solved by web search alone, and no single condition suffices. This process eliminates trivial cases and enforces genuine multi-source reasoning.
Quality control combines automated filtering (tool-call thresholds, answer–evidence consistency, coherence checks) and manual annotation to ensure factual alignment, semantic coherence, and non-triviality.
Dataset Composition and Evaluation Protocols
InfoMosaic-Bench comprises 621 tasks across six domains: medical/biology, finance, maps, video, web, and multi-domain integration. Each task is paired with condition-level gold labels and tool-call traces, supporting both holistic and fine-grained evaluation. The benchmark leverages 77 MCP tools and evaluates 14 state-of-the-art LLM agents (7 closed-source, 7 open-source) using both strict accuracy and pass rate metrics.
Experimental Results and Analysis
Web Search Limitations
Experiments reveal that web search alone is insufficient for multi-source reasoning. The best closed-source model (GPT-5) achieves only 38.2% accuracy and 67.5% pass rate, with open-source models trailing by 15–20% in accuracy. Pass rates consistently exceed strict accuracy, indicating partial satisfaction of conditions but failure to integrate all evidence.
Domain Tool Utilization
Providing agents with domain-specific tools yields selective and inconsistent benefits. Gains are observed in map and video domains, where structured, exclusive signals are required, but performance degrades in medical, finance, and multi-domain settings. The bottleneck is not tool availability but agentic tool use—planning, selection, parameterization, and orchestration.
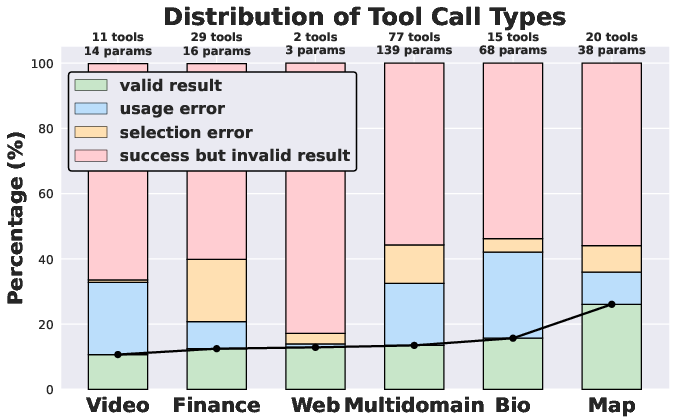
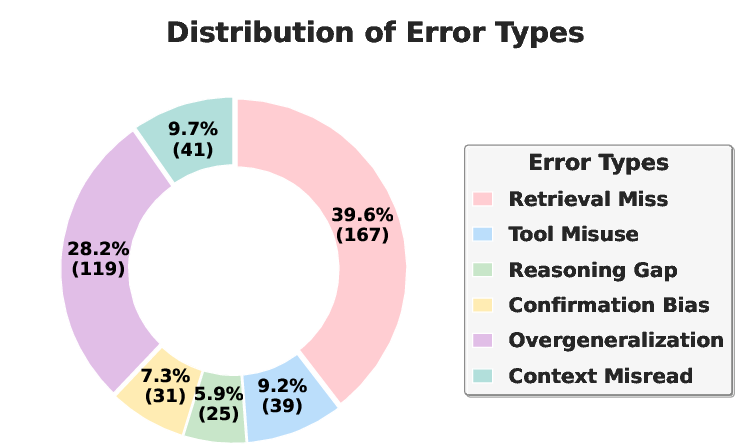
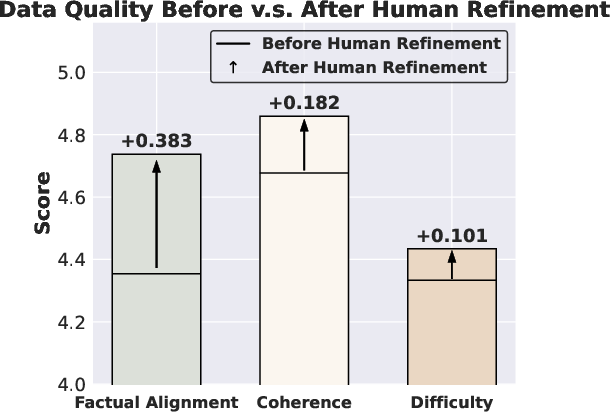
Figure 2: Distribution of tool-call result types in 6 domains, highlighting usage errors, selection errors, invalid, and valid results.
Performance (accuracy and pass rate) generally increases with the number of tool calls, plateauing after approximately eight calls. Excessive tool calls introduce redundancy and can reduce performance. Input token length grows with tool calls up to a model-specific turning point, beyond which additional calls add little context. This effective tool-usage limit correlates moderately with overall accuracy (R2=0.57).
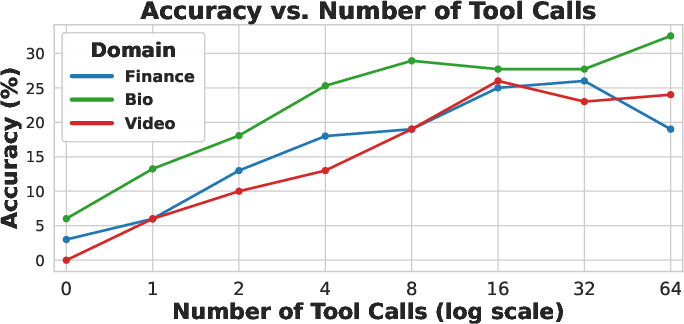
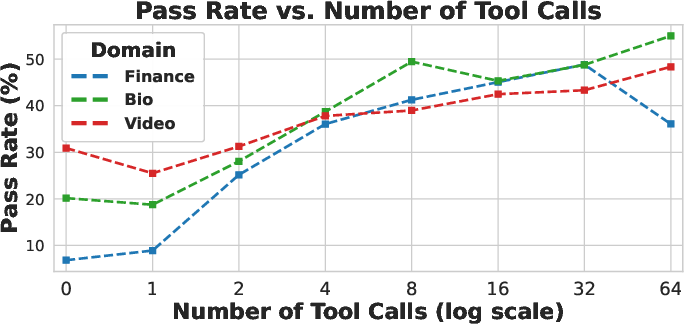
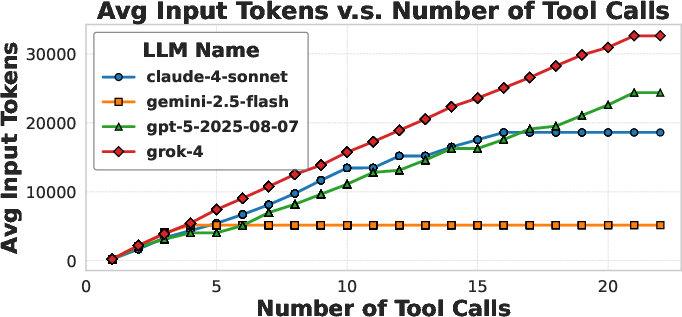
Figure 3: Relationship between performance and input length, showing accuracy and pass rate trends across domains and models as tool calls increase.
Failure Modes
Analysis of GPT-5's web-only failures identifies six primary causes: Retrieval Miss (39.6%), Overgeneralization (28.2%), Tool Misuse, Reasoning Gap, Confirmation Bias, and Context Misread. The majority of failures stem from retrieval and evidence selection, not final-step reasoning, underscoring the need for robust domain tool integration and search orchestration.
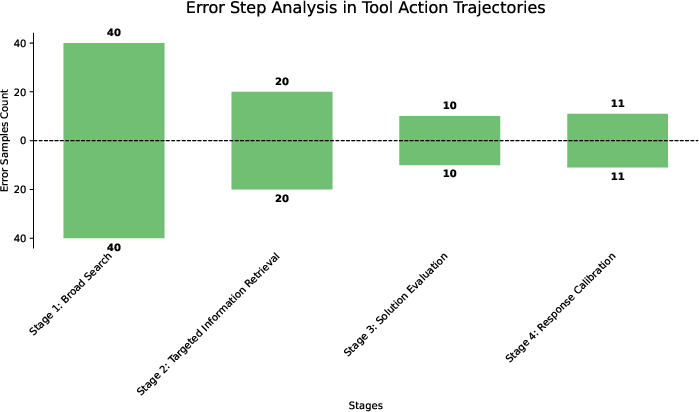
Figure 4: Distribution of agent errors across the segmented steps of the tool-calling trajectory, with error concentration in broad search phases.
Human Evaluation
A human paper confirms high factual alignment, coherence, and difficulty in the benchmark, with post-refinement improvements primarily in factual alignment. Annotator agreement is high (Cohen’s κ=0.92), validating the reliability of the synthesis and quality control pipeline.
Implications and Future Directions
InfoMosaic-Bench exposes a fundamental gap in current agentic systems: while LLMs excel at web search, they are unable to reliably exploit domain-specific tools or integrate heterogeneous sources for complex reasoning. The benchmark demonstrates that tool availability alone does not guarantee improved performance; agentic planning, tool selection, and orchestration remain open challenges. These findings have direct implications for deploying trustworthy agents in high-stakes domains such as medicine, finance, and scientific discovery.
The synthesis methodology (InfoMosaic-Flow) and benchmark design provide a robust testbed for future research on multi-source reasoning, tool orchestration, and agentic planning. Extensions to additional modalities (e.g., vision, interactive environments) and more sophisticated agent frameworks are natural next steps. Progress in these areas is a prerequisite for real-world deployment of reliable, auditable AI agents.
Conclusion
InfoMosaic-Bench establishes a rigorous standard for evaluating multi-source information seeking in tool-augmented agents. The benchmark and synthesis pipeline reveal that current LLM agents are disproportionately better at web search than at leveraging domain-specific tools, with strong numerical evidence that web search alone is insufficient for complex, domain-specific reasoning. The work provides a foundation for principled, auditable multi-tool information seeking and highlights the need for advances in agentic planning and tool orchestration to enable trustworthy AI in high-stakes applications.
