InteractComp: Evaluating Search Agents With Ambiguous Queries
Abstract: Language agents have demonstrated remarkable potential in web search and information retrieval. However, these search agents assume user queries are complete and unambiguous, an assumption that diverges from reality where users begin with incomplete queries requiring clarification through interaction. Yet most agents lack interactive mechanisms during the search process, and existing benchmarks cannot assess this capability. To address this gap, we introduce InteractComp, a benchmark designed to evaluate whether search agents can recognize query ambiguity and actively interact to resolve it during search. Following the principle of easy to verify, interact to disambiguate, we construct 210 expert-curated questions across 9 domains through a target-distractor methodology that creates genuine ambiguity resolvable only through interaction. Evaluation of 17 models reveals striking failure: the best model achieves only 13.73% accuracy despite 71.50% with complete context, exposing systematic overconfidence rather than reasoning deficits. Forced interaction produces dramatic gains, demonstrating latent capability current strategies fail to engage. Longitudinal analysis shows interaction capabilities stagnated over 15 months while search performance improved seven-fold, revealing a critical blind spot. This stagnation, coupled with the immediate feedback inherent to search tasks, makes InteractComp a valuable resource for both evaluating and training interaction capabilities in search agents. The code is available at https://github.com/FoundationAgents/InteractComp.
First 10 authors:
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces InteractComp, a new test (called a “benchmark”) for checking how well AI search assistants handle unclear questions. In real life, people often start with vague requests—like “Tell me about Mercury” (Do you mean the planet or the element?). Good assistants should notice the ambiguity, ask smart follow‑up questions, and only then search and answer. InteractComp measures whether AI agents can recognize such confusion and actively interact (i.e., ask questions) to figure out what the user really wants.
What questions did the researchers ask?
The researchers focused on simple, practical questions you’d face while using an AI assistant:
- Can AI search agents tell when a question is ambiguous?
- Will they ask the user clarifying questions before searching and answering?
- Does interaction (asking follow‑ups) actually improve results?
- Are modern AI models getting better at interaction over time?
How did they test it?
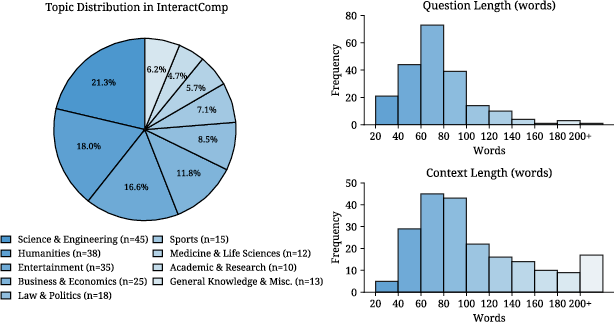
They built a carefully designed set of 210 questions across 9 topics (like science, sports, entertainment) in both English and Chinese. Each question was crafted to be short and easy to check once the right answer is found, but impossible to answer confidently without clarifying details.
Here’s how the benchmark works, explained with everyday ideas:
- Target–Distractor design: Each question describes features that fit both a lesser‑known correct answer (the “target”) and a more popular but wrong alternative (the “distractor”). This creates genuine confusion that simple web search cannot fix without asking for more details. Example: A question describes a team sport with fast flying objects and alternating offense/defense. If you only read that, you might guess “baseball,” but the real answer could be “Hornussen,” a Swiss sport with different equipment and rules. You’d need to ask follow‑up questions like “Is the object a ball or a puck?” to disambiguate.
- Simulated user: The agent can “interact” with a responder who answers only “yes,” “no,” or “I don’t know” based on hidden context. This mimics an actual conversation where the user supplies missing details when asked.
- Agent actions: The agent can 1) search the web, 2) interact (ask the simulated user clarifying questions), and 3) answer. The test checks whether the agent uses these wisely—especially interaction—to uncover what’s needed.
- Model setups: They compared three modes:
- Answer‑only (just guess from memory),
- Answer+Search (look things up but don’t interact), and
- Answer+Search+Interact (search and ask follow‑ups).
- They also tried a “forced interaction” version where the agent must ask questions before answering.
- Measurements: They tracked accuracy (how often the agent is correct), interaction behavior (how often and how much it asks), confidence calibration (does it know when it might be wrong), and cost (roughly how much it would cost to run).
What did they find?
The main results show a clear pattern: AI agents often fail not because they lack knowledge, but because they don’t ask for needed clarifications.
Here are the key findings:
- Very low accuracy without proper context: In the full interaction setting (where agents are allowed to ask questions but aren’t forced to), the best model got only about 13.73% correct. Many models were even lower (single digits).
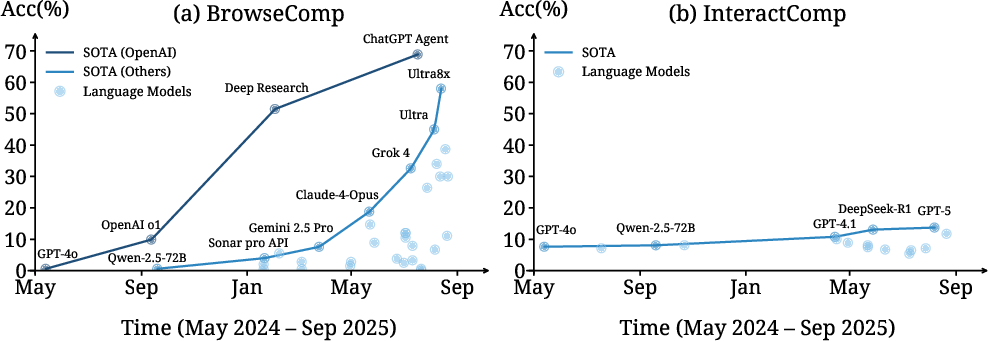
- High accuracy with complete context: If the agent is given all clarifying details upfront (no ambiguity), accuracy shoots up—to around 40–72% depending on the model (best case: 71.50%). This proves the questions are answerable and the models know enough—if they have the right information.
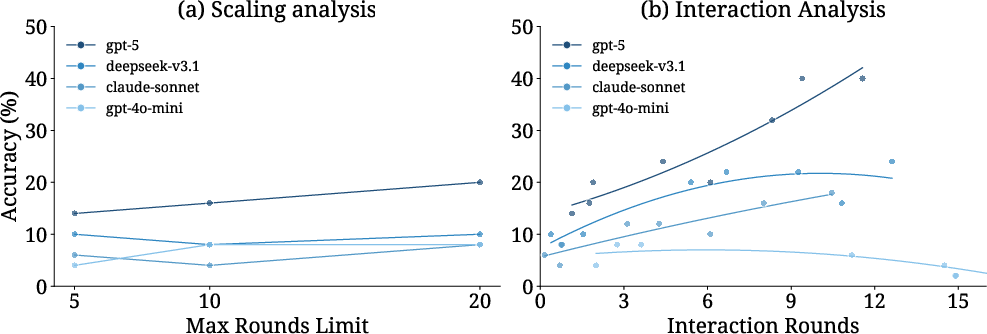
- Overconfidence is the core issue: Agents tend to guess instead of asking. Even when more conversation rounds are allowed (from 5 to 20), models barely increased their questioning, and accuracy improved only a little (e.g., ~14% to ~20%).
- Forced interaction helps a lot: When models are required to ask questions before answering, accuracy can jump sharply (e.g., up to ~40%). This shows the ability is “there” but isn’t being used unless pushed.
- Progress is lopsided over time: Over 15 months, models got much better at standard web search tasks with complete queries (seven‑fold improvement), but their interaction skill—handling ambiguous questions—did not improve (stuck around ~6–14%). This is a worrying gap.
Why is this important? Because in real life, users rarely give perfect, complete questions. If agents don’t ask, they waste time, fetch wrong information, and give wrong answers confidently.
What does this mean for the future?
InteractComp highlights a major blind spot in AI assistants: they’re good at searching and reasoning when the question is clear, but weak at recognizing uncertainty and asking for clarification. Fixing this could:
- Make assistants more trustworthy and efficient in real use.
- Reduce wrong answers and wasted computing costs.
- Encourage training methods (like reinforcement learning) that reward agents for smart, proactive interaction—asking the right questions at the right time.
In short, InteractComp gives researchers and builders a way to measure and improve the skill that matters most in everyday use: knowing when you don’t know, and asking to find out.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list synthesizes what remains missing, uncertain, or unexplored in the paper to guide future research:
- Dataset scale and coverage: With only 210 expert-curated instances across 9 domains, it is unclear how well findings generalize; larger, more diverse, and continuously updated sets are needed to assess robustness and scalability.
- Domain-level performance analysis: The paper reports topic distribution but does not analyze per-domain difficulty, failure modes, or whether ambiguity types differ systematically by domain (e.g., Science vs. Humanities).
- Cross-lingual evaluation: Although bilingual (139 English, 71 Chinese), the paper lacks a comparative analysis of interaction behavior and accuracy across languages, and does not control for model proficiency differences or culturally-specific distractors.
- Ambiguity taxonomy: The benchmark uses a target–distractor design but does not categorize ambiguity types (lexical, conceptual, entity-level, structural) or correlate these with model failures; actionable taxonomies could inform training and prompt design.
- Realism of the user simulation: The responder provides only “yes/no/I don’t know” based strictly on context; this excludes realistic behaviors (partial knowledge, misremembering, noisy or contradictory information, preferences), limiting ecological validity.
- Interaction modality constraints: The setup restricts clarifications to binary replies, preventing assessment of models’ ability to elicit and use rich, open-ended, or follow-up information; future versions should support free-text user responses.
- Grader reliability and bias: Correctness is adjudicated by GPT-4o; the paper does not report grader agreement with exact-match heuristics or human evaluators, leaving uncertainty about grading bias, reproducibility, and cross-model fairness.
- Confidence calibration methodology: The paper reports calibration error over five bins but does not detail how confidence is elicited (self-reported probabilities? textual heuristics?), nor validate the calibration metric against standardized methods.
- Temporal robustness of ambiguity: The verification checks only Google’s first five pages at construction time; answers may become trivially retrievable later due to web changes, raising concerns about benchmark stability and long-term validity.
- Single-search-engine dependence: Ambiguity verification relies on Google results; it remains unclear whether tasks are equally ambiguous across other search engines, geographies, or result personalization settings.
- Prompting and workflow sensitivity: Evaluation uses a ReAct-based agent; the paper does not ablate prompts, action schemas, or planner policies, leaving open whether failures are due to model capability vs. agent design choices.
- Question quality and utility: No analyses of the content, specificity, or utility of model-generated clarifying questions (e.g., redundancy, relevance, informativeness) are provided; this impedes targeted training of question-asking strategies.
- Forced-interaction side effects: While accuracy improves under forced interaction, the paper does not measure user cost (latency, cognitive burden), question quality degradation, or “gaming” via trivial questions—key for practical deployment.
- Overconfidence diagnosis: The claim that overconfidence is the primary bottleneck is plausible but not conclusively demonstrated; alternative hypotheses (poor ambiguity detection, weak query decomposition, retrieval constraints) require targeted experiments.
- Retrieval vs. interaction disentanglement: The search-only setting shows low gains, but the paper does not analyze retrieval quality (query formulation, click/browse strategies, source selection), which could confound interaction benefits.
- Reward design for RL: The paper posits “clean reward signals” from search outcomes but does not specify an RL environment, reward function, credit assignment across turns, or safety constraints; concrete RLVR protocols remain open.
- Generalization to multi-modal ambiguity: Tasks and interactions are text-centric; the benchmark does not test image-, table-, or video-based ambiguity common in web search, nor agents’ ability to request or process multi-modal clarifications.
- Answer-format constraints: Answers are short (1–2 words) and “easy to verify”; this may not reflect real-world search tasks requiring synthesis, aggregation, or long-form responses—raising questions about external validity.
- Human annotation rigor: The paper describes a two-stage verification but provides no inter-annotator agreement statistics, error rates, or adjudication protocols, leaving data quality and consistency unquantified.
- Cost and latency reporting: Costs are given in USD but lack breakdowns (token usage, tool calls, latency), hindering reproducibility and practical trade-off analyses of interaction-heavy strategies.
- Model comparability: Differences in provider APIs, rate limits, safety filters, and tool-use capabilities are not controlled, making it hard to attribute performance gaps to interaction competence rather than platform-specific factors.
- Robustness to future models: Ambiguity verification is tied to current model capabilities; the benchmark may become obsolete as models improve in retrieval or inference without interaction—necessitating dynamic revalidation protocols.
- Multiple plausible distractors: The target–distractor paradigm enforces uniqueness via context; in reality, ambiguous queries often admit many candidates; extending to multi-distractor or open-world settings remains unexplored.
- Error analysis granularity: The paper lacks qualitative breakdowns of failure cases (e.g., missed ambiguity detection, premature answering, irrelevant questioning), limiting actionable insights for model training.
- User-centric metrics: Beyond accuracy and calibration, the study does not measure user satisfaction, effort, or trust under different interaction policies—critical for applied search-agent deployment.
- Ethical and safety considerations: Encouraging aggressive interaction could increase data collection, privacy risks, or manipulation; the paper does not address safe interaction policies or guardrails in the proposed RL training.
- Benchmark naming and documentation clarity: The manuscript contains placeholder references to the benchmark name and missing appendix details; clearer documentation is needed for reproducibility and community adoption.
Practical Applications
Immediate Applications
Below are deployable applications that leverage the paper’s benchmark design, findings, and insights. They are grouped by audience and sector, and each item notes relevant tools/workflows and feasibility caveats.
Industry
- Search and research agents: “Clarify-before-Answer” policy
- Sectors: software, information services, enterprise search
- What: Add an ambiguity gate that requires at least one targeted clarifying question before finalizing answers when the agent detects multiple plausible interpretations (e.g., SERP ambiguity, multi-entity overlap).
- Tools/workflows: ReAct-based agent middleware; forced-interaction policy; Interaction Rate (IR) and Calibration Error (CE) monitors; guardrails to block answering until clarifiers are asked; prompt snippets that instantiate “Ask-to-Act” gating.
- Assumptions/dependencies: Requires ambiguity detection heuristics or a small classifier trained on InteractComp-like instances; latency/cost trade-offs; user tolerance for extra turns.
- Customer support triage bots that proactively disambiguate user intent
- Sectors: e-commerce, telco, SaaS
- What: Use target-distractor-style clarifiers (e.g., “Are you returning or exchanging?”) before routing or proposing resolutions, to reduce mis-triage and repeated contacts.
- Tools/workflows: Clarification Planner (CP) module; scripted yes/no clarifiers; KPI dashboards using CE and resolution accuracy.
- Assumptions/dependencies: Clear, verifiable resolution outcomes to close the loop; careful UX to avoid over-questioning.
- In-app shopping and booking assistants that ask for missing constraints
- Sectors: travel, retail, food delivery
- What: Disambiguate under-specified requests (e.g., “Washington” → DC vs. state; “running shoes” → size, terrain) before search and recommendations.
- Tools/workflows: Ambiguity detector using catalog metadata; minimal-question policies; “disambiguation wizard” UI components.
- Assumptions/dependencies: Catalog schemas that expose discriminative attributes; UX to balance friction.
- Code assistants that clarify requirements before scaffolding
- Sectors: software engineering
- What: Ask for framework versions, target platform, performance/security constraints when generating scaffolds or fixes.
- Tools/workflows: “Clarify-first” prompts; CI gates that reject PR-suggested changes if clarifiers not asked under ambiguity signals (e.g., multiple API versions detected).
- Assumptions/dependencies: Detection signals tuned to repo context; developer acceptance and time costs.
- Enterprise search with interactive disambiguation
- Sectors: knowledge management, legal, pharma R&D
- What: When multiple near-matching entities exist (e.g., similarly named compounds, matters, trials), pose 1–2 yes/no clarifiers to narrow retrieval.
- Tools/workflows: Index-side entity overlap signals; “2-question minimum” policy for high-ambiguity queries; IR/CE analytics in search telemetry.
- Assumptions/dependencies: Entity linking quality; privacy and compliance approvals for logging interactions.
Academia
- Evaluation harness for interactive search agents
- What: Use InteractComp to benchmark calibration, questioning behavior, and answer accuracy independently of general reasoning skill.
- Tools/workflows: Standardized IR/CE/accuracy reporting; ablations for answer-only vs search-only vs with-context; forced-interaction settings for probing latent capability.
- Assumptions/dependencies: Access to evaluated models and consistent graders.
- Dataset construction recipe for ambiguous tasks in new domains
- What: Apply the target-distractor methodology to build discipline-specific ambiguous benchmarks (e.g., clinical, legal, finance).
- Tools/workflows: Attribute overlap mining; shared vs distinctive feature curation; two-stage validation (web search check + model auto-check).
- Assumptions/dependencies: Domain experts for attribute curation; verifiable answers.
Policy and Governance
- Safety standard: mandatory clarification for high-risk, ambiguous queries
- Sectors: healthcare, finance, legal, critical infrastructure
- What: Establish procurement and compliance criteria requiring demonstrable clarification behavior under ambiguity (minimum clarifiers, calibrated confidence).
- Tools/workflows: “Interaction readiness” certificate scored on InteractComp-like suites; CE thresholds; audit logs of clarifying turns.
- Assumptions/dependencies: Domain-specific thresholds; regulator buy-in; privacy-preserving logging.
- Public-sector question-answering portals with ambiguity prompts
- Sectors: government services
- What: When citizen intent is under-specified (e.g., “license renewal”), ask clarifiers to route to the correct program.
- Tools/workflows: Form auto-completion with clarifier chips; yes/no/don’t-know responder templates to speed interactions.
- Assumptions/dependencies: Accessibility and multilingual requirements; content maintenance.
Daily Life
- Personal assistants that clarify underspecified requests
- Sectors: consumer productivity
- What: Agents proactively ask the fewest necessary questions for tasks like events, reminders, travel, or purchases.
- Tools/workflows: Minimal-question strategies; personal preference memory to reduce repeat questions; opt-out settings.
- Assumptions/dependencies: User tolerance and privacy; local preference storage.
- Household robotics and IoT voice interfaces that verify intent
- Sectors: robotics, smart home
- What: Before executing ambiguous commands (“clean the room”), confirm specifics (area, time, exclusions).
- Tools/workflows: Ask-to-Act gate in on-device NLU; 1–2-turn voice disambiguation.
- Assumptions/dependencies: On-device latency budgets; fallbacks for noisy environments.
Long-Term Applications
These opportunities require further research, scaling, or productization beyond the current benchmark and analyses.
Industry
- RL from verifiable search outcomes to train “uncertainty-aware” askers
- Sectors: software, enterprise search, assistants
- What: Use the clean reward signals inherent in search tasks (correctness of final answer, retrieval precision) to train policies that decide when and what to ask.
- Tools/workflows: RLVR pipelines; reward shaping for minimal clarifiers; counterfactual off-policy evaluation with forced-interaction logs.
- Assumptions/dependencies: Reliable verifiability at scale; safe exploration in production; compute budgets for RL.
- Clarification engine microservice for agent stacks
- Sectors: agent platforms, MLOps
- What: Provide an API that detects ambiguity, proposes ranked clarifying questions, and enforces ask-to-act policies across heterogeneous agents.
- Tools/workflows: Model-agnostic middleware; policy-as-code; enterprise telemetry for IR/CE/SLA.
- Assumptions/dependencies: Interoperability with agent frameworks; governance for cross-app logging.
- Adaptive questioning strategies optimized for UX and cost
- Sectors: consumer apps, enterprise UX
- What: Learn policies that balance answer accuracy gains vs user friction and token cost, adapting to user tolerance and context.
- Tools/workflows: Bandit optimization; user satisfaction modeling; cost-aware reward functions.
- Assumptions/dependencies: High-quality satisfaction signals; long-horizon A/B testing infrastructure.
Academia
- Domain-specific InteractComp variants with expert-grounded ambiguity
- Sectors: healthcare, law, finance, education
- What: Extend the target-distractor methodology with clinician/jurist/analyst curation for high-stakes disambiguation (e.g., near-synonym diagnoses, similarly named regulations, correlated tickers).
- Tools/workflows: Knowledge graphs to mine shared/distinctive attributes; adversarial distractor synthesis.
- Assumptions/dependencies: Ethical review; access to proprietary corpora; careful harm analysis.
- Mechanistic studies of overconfidence and question underuse
- What: Probe model internals to link calibration errors to interaction reluctance and discover representations predictive of “should ask vs answer.”
- Tools/workflows: Logit lens analyses; uncertainty estimation (ensemble, temperature scaling); causal interventions on prompting.
- Assumptions/dependencies: Model access; reproducibility across architectures.
Policy and Governance
- Certification for “interactive disambiguation competence” in AI systems
- Sectors: regulated industries
- What: Create standardized audits requiring evidence that systems identify ambiguity and request clarification before consequential actions.
- Tools/workflows: Sector-specific pass/fail thresholds; red-teaming with target-distractor probes; incident reporting tied to missed clarifications.
- Assumptions/dependencies: Industry consensus; mapping to existing AI risk frameworks.
- Regulation of auto-execution agents with ask-to-act mandates
- Sectors: fintech trading bots, clinical decision support, autonomous operations
- What: Require documented clarification steps before executing if confidence falls below thresholds or ambiguity signals fire.
- Tools/workflows: Policy engines; immutable logs for forensics; staged human-in-the-loop escalation.
- Assumptions/dependencies: Clear risk tiers; enforcement mechanisms.
Daily Life
- Socratic tutoring systems that teach and assess clarification skills
- Sectors: education
- What: Tutors that model and reward students’ clarification questions on under-specified problems, improving metacognition and problem-solving.
- Tools/workflows: Curricula built with target-distractor tasks; rubrics for question quality; longitudinal learning analytics.
- Assumptions/dependencies: Age-appropriate UX; alignment with standards.
- Human-robot teamwork with negotiated task clarification
- Sectors: manufacturing, logistics, eldercare
- What: Robots that detect ambiguous human instructions and engage in brief negotiation to lock task parameters before acting.
- Tools/workflows: Multimodal ambiguity detectors (language, gesture, environment); minimal-turn negotiation policies; safety interlocks.
- Assumptions/dependencies: Robust perception; latency constraints; safety certification.
- Personalized ambiguity profiles for assistants
- Sectors: consumer assistants, accessibility
- What: Assistants learn per-user thresholds—when to infer vs when to ask—reducing friction while avoiding costly mistakes.
- Tools/workflows: Preference learning; privacy-preserving on-device profiles; adaptive clarifier generation.
- Assumptions/dependencies: Opt-in data; privacy guarantees; drift handling.
Notes on feasibility across applications:
- The benchmark’s simulated yes/no responder generalizes best to tasks with verifiable outcomes; domains lacking crisp verification need proxy rewards or human review.
- Benefits depend on high-quality ambiguity detection; weak detectors lead to either over-questioning (user annoyance) or missed clarifications (errors).
- Forced-interaction strategies improve accuracy but increase cost/latency; adaptive policies and UX research are needed to balance trade-offs.
- Current dataset size (210 items) is sufficient for evaluation and small-scale training; large-scale domain variants will be needed for robust RL training and certification in specialized sectors.
- Bilingual coverage (EN/ZH) helps, but broader multilingual deployment requires additional datasets and localization.
Glossary
- Ablation study: A controlled analysis that isolates the effect of components or settings by comparing variants. "Ablation study comparing model performance under three evaluation settings:"
- Ambiguity resolution: The process of clarifying incomplete or multi-interpretation queries to determine the intended meaning. "fundamentally shifts focus from search complexity to ambiguity resolution."
- Answer-first approach: A data construction strategy that starts from known answers and works backward to formulate questions and contexts. "draws inspiration from BrowseComp's answer-first approach"
- Answer-only: An evaluation mode where models respond directly without using external evidence, search, or interaction. "answer-only (models respond without additional evidence)"
- Calibration error: A metric quantifying the mismatch between a model’s predicted confidence and actual accuracy. "Calibration Error (C.E.) measuring confidence calibration using 5 confidence bins"
- Clean reward signals: Objective feedback (e.g., correct/incorrect outcomes) that can be used directly for training without noisy or ambiguous supervision. "clean reward signals from search outcomes"
- Completeness Verification: A validation stage ensuring the question and context jointly identify a unique, correct answer and that the target satisfies all attributes. "Stage 1: Completeness Verification."
- Cross-validation: A consistency check across different subsets or validation steps used to detect construction or labeling errors. "cross-validation fails"
- Disambiguating context: Additional information that uniquely determines the intended target among plausible alternatives. "complete disambiguating context"
- Distractor: A similar, often more popular alternative entity intentionally used to induce ambiguity in a question. "the distractor (a popular alternative sharing attributes with the target)"
- Forced interaction: Protocols that require the agent to ask a minimum number of clarifying questions before responding. "Forced interaction produces dramatic gains"
- Gym environments: Simulated, instrumented settings for training and evaluating agents on user-centric tasks. "create gym environments for training agents on user-centric tasks"
- Interaction Necessity Validation: A verification stage confirming that the question cannot be confidently solved without interactive clarification. "Stage 2: Interaction Necessity Validation."
- Interaction-dependent queries: Questions whose correct resolution requires asking clarifying questions during the task. "ambiguous, interaction-dependent queries (InteractComp)"
- Interaction rate (IR): The percentage of available rounds in which the agent uses the interact action. "percentage of rounds where interact actions are used (IR)"
- Long-horizon capabilities: The ability of agents to plan and act effectively over many steps or extended sequences. "enhance long-horizon capabilities."
- Longitudinal analysis: A study of performance trends over time to understand progress or stagnation. "Longitudinal analysis shows interaction capabilities stagnated over 15 months"
- Open-weight models: Models whose parameters are publicly available for use and modification. "Models are grouped into open-weight and closed-weight categories for clarity."
- Proprietary models: Commercial, closed-source models maintained by organizations with restricted access to weights. "proprietary models (GPT-4o-mini, GPT-4o, GPT-4.1, GPT-5, OpenAI o3, Grok-4, Doubao-1.6, Claude-Sonnet-4, Claude-Opus-4, Claude-3.5-Sonnet)"
- ReAct framework: An agent architecture that synergizes reasoning (thought) and acting (tool use) in a loop. "We employ the ReAct framework \citep{yao2023react} as our base architecture"
- Reinforcement learning: A training paradigm where agents learn to act by receiving rewards from the environment. "Reinforcement learning approaches like R1-Searcher~\citep{song2025r1} and Search-R1~\citep{jin2025search}"
- Responder simulation: A method that uses a model to simulate a user who answers clarifying questions with constrained responses. "We implement responder simulation using GPT-4o (temperature=1.0) that provides structured feedback when agents employ the interact action."
- RLVR: Reinforcement Learning from Verifiable Rewards; training strategies that leverage objective, checkable outcomes. "well-suited for RLVR approaches to improve model interaction with humans."
- Search-only: An evaluation mode where models rely solely on retrieved information without interacting with users. "search-only (responses based solely on retrieved information)"
- Target-distractor methodology: A construction method pairing a lesser-known target with a popular similar entity and using only shared attributes to induce ambiguity. "through a target-distractor methodology that creates genuine ambiguity resolvable only through interaction."
- Temperature: A sampling parameter controlling randomness in generation; higher values yield more diverse outputs. "temperature=0.6, top_p=0.95."
- Tool-augmented benchmarks: Evaluations that require agents to use external tools (e.g., calculators, browsers) to solve tasks. "Tool-augmented benchmarks like GAIA~\citep{mialon2023gaia} and WebWatcher~\citep{geng2025webwatcher} additionally require agents to handle multimedia and perform computations."
- Top_p: A nucleus sampling parameter specifying the cumulative probability mass from which tokens are sampled. "top_p=0.95"
- Verifiable search tasks: Retrieval problems where correctness can be objectively checked against ground truth or authoritative sources. "lack grounding in verifiable search tasks."
- Web-scale search: Information retrieval across the entire internet, not limited to curated corpora. "Web-scale search benchmarks like BrowseComp~\citep{wei2025browsecomp} assess information gathering across the entire web"
- Workflow engineering: Designing structured, stepwise agent processes to improve performance and reliability. "through careful workflow engineering."
Collections
Sign up for free to add this paper to one or more collections.